【Transformer养猪】Livestock Monitoring with Transformer
对牲畜行为的跟踪有助于在现代动物饲养场及早发现并预防传染病。除了经济收益,这将减少畜牧业中使用的抗生素数量,否则这些抗生素将进入人类的饮食,加剧抗生素耐药性的流行,这是导致死亡的主要原因。我们可以使用大多数现代农场都有的标准摄像机来监控牲畜。然而,大多数计算机视觉算法在这项任务中表现不佳,主要原因是:(i)农场饲养的动物看起来相同,缺乏任何明显的空间特征,(ii)现有的跟踪器都不能长时间保持健壮,(iii)现实世界的条件,如光照变化、频繁遮挡、摄像机角度变化,动物的大小使得模型难以一般化。鉴于这些挑战,我们开发了一个端到端行为监控系统,用于群养猪同时执行实例级别分割、跟踪、动作识别和再识别(STAR)任务。我们提出了STARFORMER,这是第一个端到端多对象牲畜监控框架,通过使用变压器架构学习分组猪的实例级嵌入。为了进行基准测试,我们提出了PIGTRACE数据集,该数据集由视频序列和实例级边界框组成,对真实室内养殖环境中的猪进行分割、跟踪和活动分类。通过对STAR任务进行同步优化,我们发现STARFORMER优于针对单个任务训练的流行基线模型。
原文:Livestock Monitoring with Transformer
https://arxiv.org/abs/2111.00801
提前说明一下,论文不是我写的,我只是翻译一下,不要问我要数据集了_(:з)∠)_
 STARFORMER
STARFORMER
贡献
- 大概是第一个使用Transformer提供一个单一的健壮的行为分析模型执行STAR任务,即分割(segmentation)、跟踪(tracking)、动作识别(action recognition)和再识别(re-identifification)。这种统一模型的优点是,多个任务的学习过程在构建图像/视频的鲁棒性和可泛化的低层次表示方面相互积极影响,从而减少了误差,其程度超过了单个任务的训练所能达到的程度。
- 提出了PIGTRACE,一个包含多个猪的30个视频的数据集,用于基准测试封闭环境下多目标跟踪和动作识别算法的性能。
PIGTRACE
来自真实动物农场的视频,以及详细的实例级遮罩和动作注释。该数据集中共有540帧。该数据集还包括所有注释,包括每只猪的Mask、视频中与每只猪关联的唯一ID以及猪猪正在执行的动作的标签。
- 来自欧洲五个不同农场的大约30个视频序列组成,每个视频大约5秒长,包括吃,喝,躺,站立和行走这些典型行为的视频。
- 有7个视频以每秒6帧(FPS)的速度进行标注,每个视频有30帧的标注(5×6=30)
- 另外23个视频以每秒3帧的速度进行标注,每个视频有15帧的标注(5×3=15)
- 提供代码,以方便在自定义模型上使用该数据集,以及用于评估指标的api。
 PIGTRACE
PIGTRACE
图中每一行对应一个来自不同场区的视频,每一列对应连续的注释帧。动物身上的数字是它们唯一的身份标识
颜色代表猪的行为:
- 绿色:吃
- 蓝色:喝
- 红色:攻击
- 橙色:行走/站立
- 黑色:不活跃
STARFORMER
STARFORMER是一种基于DETR扩展的多任务Transformer模型,用于对牲畜进行分割、跟踪、动作识别和再识别(STAR)
DETR引入了对象查询(object queries)的概念——使用固定数量的object queries作为可学习的positional embeddings,可以将这些embeddings提取为图像中可能的对象实例的表示。
基于此,STARFORMER扩展了DETR,使用固定数量的object queries作为可学习的individual embeddings,使其通过STAR多任务学习更能识别一个实例。
 四个头对应的四个损失分别是检测(D)、分割(S)、行为(A)(红:活动、黄:非活动)和时空对比损失
四个头对应的四个损失分别是检测(D)、分割(S)、行为(A)(红:活动、黄:非活动)和时空对比损失
(STC)。
上图表示了STARFORMER的架构,一个ResNet-101主干网络,后跟一个包含6个编码器-解码器层的标准Transformer,具有固定大小的位置编码(object queries)。基于对猪数量的先验知识,Transformer模块产生N个潜在编码,每个对应一个单独的猪。STARFORMER的关键思想是通过设计四个头来改善嵌入,每个头优化STAR任务的一个损失函数。
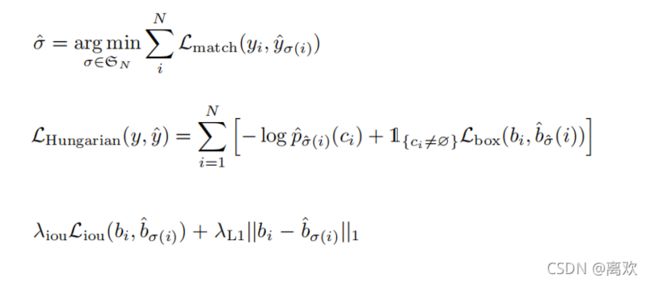
 帧中得到并输出的。其中
帧中得到并输出的。其中  为猪的序号,并设一帧中总共有
为猪的序号,并设一帧中总共有
 头猪。时空对比 损失定义为
头猪。时空对比 损失定义为
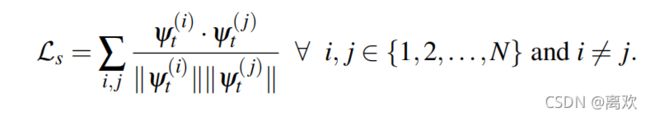
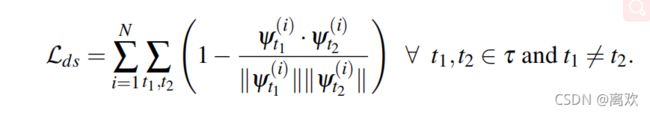
行为损失: 二元交叉熵损失,将每头猪分为两类,即活跃(站立)或不活跃(坐着)
实验
- 使用ResNet-101 dedr模型在COCO数据集上预训练作为骨干。
- 在280个与PIGTRACE同格式的视频上训练STARFORMER。
- 在训练过程中,通过解冻结编码器和解码器并学习新的object queries来重新训练。
- 所有实验都在8个V100 GPU上运行。
- 在一个由84个视频组成的验证集上评估STARFORMER在4个STAR任务上的性能。
- 在PIGTRACE上测试。
 实验涉及的三种数据集信息
实验涉及的三种数据集信息
基线与评价指标
分割:比较MaskR-CNN和DETR,其解码器和object queries是使用我们的训练数据集微调。注意,在评估STARFORMER和DETR时,我们将预测的数量(DETR是100)固定为该视频中猪的数量。这在畜牧业环境中可能是有益的,因为封闭环境中的动物数量在视频过程中将保持固定。这就限制了模型不允许过多或过少地预测嵌入的数量。我们报告了不同IoU阈值上的平均精度(mAP),从0.5到0.95(写成0.5:0.95),以及在0.5阈值上的平均精度(mAP)。
跟踪:利用分割模型得到的分割掩码进行时间匹配,实现多目标跟踪。猪的数量在整个视频中保持不变,我们利用这个约束条件,将预测的数量固定为视频中已知的猪的数量N。对于每个视频,我们只考虑所有对象查询中的前N个预测。同时还可以得到猪数量的初步估计。为了更好地分析跟踪模块的性能,我们使用了两种不同的匹配算法,并比较了每种算法的性能。以下是对它们的简要描述。
- Mask匹配:使用猪的分割掩码计算猪之间的相似度。
- Embedding匹配:使用余弦距离度量猪所对应的Embedding计算相似度。对于每只匹配的猪,欧氏空间中的距离应该小于R。
我们提出了约束多目标跟踪和分割精度(cMOTSA)作为评价有约束跟踪问题的指标。由于在整个视频中牲畜的固定计数的限制,将不会有假阴性(FN),因为现在在ground-truths和从prediction获得的各自实例之间存在1-1映射。我们希望这个评估指标能够准确地评估STARFORMER在学习每个猪实例的独特表示方面的能力。它被定义为真阳性TP(掩码IoU大于0.5的匹配实例对)与所有阳性预测(|TP| + |FP|)的比率。假阳性(FP)是掩码IoU小于或等于0.5的实例对。此外,我们还使用scMOTSA来评估跟踪性能,scMOTSA是cMOTSA的一个软变体,定义为scMOTSA = ![]() ,其中
,其中![]() 表示软真阳性。
表示软真阳性。
行为:与经过专门训练的ResNet-101激励模型(Ac-ResNet)进行比较来评估,该模型将每头猪分为两类——不活动(坐着)或活动(站着)。以AUC-ROC曲线下面积作为评价指标。
再识别:使用累积匹配特征(CMC)评分来比较STARFORMER和DETR之间的再识别。CMC-k,度,表示在排名前k的检索结果中出现正确匹配的概率。在我们的例子中,排名是通过计算不同帧猪之间的Embedding距离来完成的。如果前k个值中出现正确匹配,CMC top-k精度为1,否则为0。我们绘制了离散帧间间隔的CMC top-k精度,即进行重新识别的两帧之间的时间间隔。
结果
对于分割任务,除了下表所示以外,使用Swin - transformer骨干重新训练了STARFORMER,在PIGTRACE数据集上获得了0.76 mAP的结果。
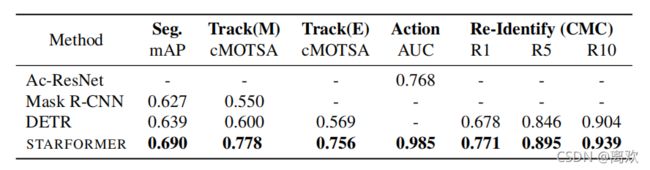 STARFORMER和基线模型在4个STAR任务上的性能得分。这里mAP的计算值为0.5:0.95。另外,Track(M)和Track(E)分别对应mask匹配和embeddings匹配, Action表示动作识别。
STARFORMER和基线模型在4个STAR任务上的性能得分。这里mAP的计算值为0.5:0.95。另外,Track(M)和Track(E)分别对应mask匹配和embeddings匹配, Action表示动作识别。
为了进一步理解拥有多个任务头的影响,我们还分析了从最初的STARFORMER模型中移除多个任务头中的一个的几个情况。
去除STC损失的头部,对分割性能没有不利影响,但跟踪性能降低约1%。分割不会有任何变化,因为在我们的例子中,STC损失主要关注的是时序信息,而分割在每一帧中处理彼此独立的对象。类似地,当移除动作分类损失时,跟踪性能将受到显著影响。
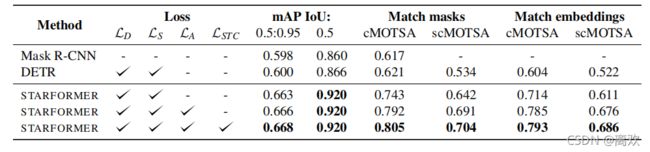 STARFORMER和其他用于分割和跟踪任务的基线模型的性能得分,在验证集上获得。
STARFORMER和其他用于分割和跟踪任务的基线模型的性能得分,在验证集上获得。
对于再识别任务DETR和STARFORMER在CMC-k上表现相当。然而,大的k值并不适合实际用途,在较低的k值下的性能更重要。对于较低的值,我们可以看到,对于所有帧间间隔的选择,DETR的性能都会显著下降。相反,当k值较低时,STARFORMER更稳定,下降很小。这意味着,对于长期跟踪,STARFORMER有望更可靠。
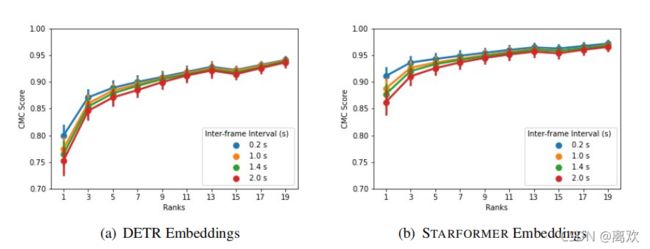 用于猪的再识别的CMC曲线。在这里,帧间间隔表示需要跳过的帧数,以测试重新识别的有效性。
用于猪的再识别的CMC曲线。在这里,帧间间隔表示需要跳过的帧数,以测试重新识别的有效性。