pyhanlp最全安装和使用教程
文章目录
-
-
-
- pyhanlp介绍
- pyhanlp安装
- 分词
- 关键词提取
- 文本摘要
- 依存句法分析
- 短语提取
- NER中国人名识别
- 音译名识别
- 简繁转换
- 拼音转换
- pyhanlp可视化
-
-
pyhanlp介绍
HanLP 是一个由中国开发者何晗(hankcs)于 2014 年开发的自然语言处理库,自发布之后,HanLP 不断更新迭代,进行了许多新功能和性能的优化,Github 上 Star 数量已超过 3w,其在主流自然语言工具包中非常受欢迎。
HanLP 具有丰富的功能,可以进行一系列文本分析任务,比如词法分析(分词、词性标注、命名实体识别)、句法分析、文本分类/聚类、信息抽取、语义分析等等。发展至今,HanLP 已经衍生出了 1.x和 2.x 两大版本。
本文pyhanlp版本:0.1.84
pyhanlp安装
直接使用pip install pyhanlp进行安装,安装后在第一次使用时,当运行from pyhanlp import *时,会下载hanlp的数据文件
分词
HanLP.segment 分词,把一句话分词很碎的词,有准的有不准的,但是这个方法是唯一一个能把词性输出的方法,关于词性可以做很多的延伸和拓展,比如分析一段话的精髓,就可以简单的用词性排除和词性组合法;
from pyhanlp import *
sentence = "异地贷款需要具备哪些条件"
# 返回一个列表,可以获取分词和它的词性
words = HanLP.segment(sentence)
for term in words:
print(term.word,term.nature)
异地 n
贷款 n
需要 v
具备 v
哪些 ry
条件 n
关键词提取
HanLP.extractKeyword 提取文章段落的关键词,会精准的提取出一些词语,但是在提取出词语的数量少会比 HanLP.segment少很多, 建议和 HanLP.extractSummary 组合使用
from pyhanlp import *
text = "3月4日,在北京2022年冬残奥会开幕式上,一本精致美观的手册出现在每位观众和嘉宾的手中,\
这是由北京印刷学院教授夏小奇带领团队设计的《北京2022年冬残奥会开幕式》手册,\
在色彩氛围、页码设计、纸张选用等方面都做了暖心设计。"
# 提取文本的两个关键词,返回列表
print(HanLP.extractKeyword(text, 2))
关键词数量可以指定,例如我们指定5个关键词。
print(HanLP.extractKeyword(text, 5))
[设计, 手册, 开幕式, 残奥会, 冬]
文本摘要
HanLP.extractSummary 提取段落的摘要,提取出该段落/文章的一些摘要信息,建议组合使用,比如 一个for循环 把每个摘要再次进行分词
from pyhanlp import *
text = "3月4日,在北京2022年冬残奥会开幕式上,一本精致美观的手册出现在每位观众和嘉宾的手中,\
这是由北京印刷学院教授夏小奇带领团队设计的《北京2022年冬残奥会开幕式》手册,\
在色彩氛围、页码设计、纸张选用等方面都做了暖心设计。"
# 提取文本中的2个关键句作为摘要,返回列表
print(HanLP.extractSummary(text,2))
[这是由北京印刷学院教授夏小奇带领团队设计的《北京2022年冬残奥会开幕式》手册, 在北京2022年冬残奥会开幕式上]
依存句法分析
from pyhanlp import *
print(HanLP.parseDependency("普京在会谈中强调,俄方将全面完成在乌克兰的行动。"))
1 普京 普京 nh nrf _ 3 主谓关系 _ _
2 在会谈中 在会谈中 i l _ 3 状中结构 _ _
3 强调 强调 v v _ 0 核心关系 _ _
4 , , wp w _ 3 标点符号 _ _
5 俄方 俄方 n n _ 11 主谓关系 _ _
6 将 将 d d _ 11 状中结构 _ _
7 全面完成 全面完成 i l _ 11 定中关系 _ _
8 在 在 p p _ 11 定中关系 _ _
9 乌克兰 乌克兰 ns ns _ 8 介宾关系 _ _
10 的 的 u u _ 8 右附加关系 _ _
11 行动 行动 v vn _ 3 动宾关系 _ _
12 。 。 wp w _ 3 标点符号 _ _
短语提取
HanLP.extractPhrase 分短语,把一句话分成几个短语,会带一些词语组合(联想),比如A+B组合成一个词,A+C又组合成了一个词
from pyhanlp import *
text = "全国上下共同努力,统筹疫情防控和经济社会发展,全年主要目标任务较好完成"
#抽取5个短语
phraseList = HanLP.extractPhrase(text, 5)
print(phraseList)
[全国上下共同努力, 疫情防控, 经济社会发展, 防控经济社会, 统筹疫情]
NER中国人名识别
from pyhanlp import *
NER=HanLP.newSegment().enableNameRecognize(True)
p_name=NER.seg('马云、汪洋、张朝阳的搜狗、韩寒的书')
print(p_name)
[马云/nr, 、/w, 汪洋/n, 、/w, 张朝阳/nr, 的/ude1, 搜狗/gi, 、/w, 韩寒/nr, 的/ude1, 书/n]
音译名识别
from pyhanlp import *
sentence = '微软的比尔盖茨、Facebook的扎克伯格跟桑德博格。'
person_ner = HanLP.newSegment().enableTranslatedNameRecognize(True)
p_name = person_ner.seg(sentence)
print(p_name)
[微软/ntc, 的/ude1, 比尔盖茨/nrf, 、/w, Facebook/nx, 的/ude1, 扎克伯格/nrf, 跟/p, 桑德博格/nrf, 。/w]
简繁转换
from pyhanlp import *
Jianti = HanLP.convertToSimplifiedChinese("我愛自然語言處理技術!")
Fanti = HanLP.convertToTraditionalChinese("我爱自然语言处理技术!")
print(Jianti)
print(Fanti)
我爱自然语言处理技术!
我愛自然語言處理技術!
拼音转换
from pyhanlp import *
s = '责任重于泰山'
pinyinList = HanLP.convertToPinyinList(s)
for pinyin in pinyinList:
print(pinyin.getPinyinWithoutTone(),pinyin.getTone(), pinyin, pinyin.getPinyinWithToneMark())
ze 2 ze2 zé
ren 4 ren4 rèn
zhong 4 zhong4 zhòng
yu 2 yu2 yú
tai 4 tai4 tài
shan 1 shan1 shān
pyhanlp可视化
python可视化可以做到词法分析、句法分析等功能的可视化。
hanlp serve
服务器已启动 http://localhost:8765
127.0.0.1 - - [19/Feb/2024 11:56:39] "GET / HTTP/1.1" 200 -
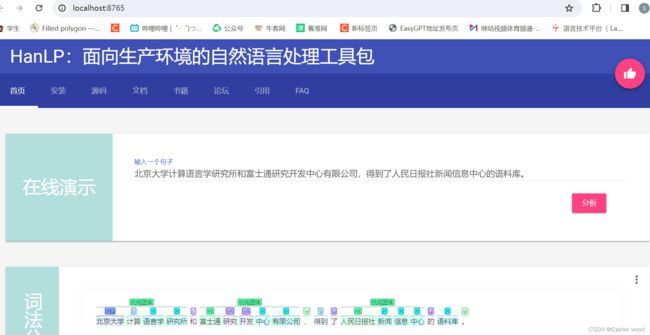
hanlp可视化网站:https://hanlp.hankcs.com/
