01_02_mysql01_软件的安装与DQL-SELECT内容
概述
环境搭建
1卸载
1、停止服务
2、软件卸载(控制面板卸载)
3、残余删除
(1)服务目录:mysql服务的安装目录
(2)数据目录:默认在C:\ProgramData\MySQL
4、清理注册表(regedit)
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\Eventlog\Application\MySQL服务 目录删除
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\MySQL服务 目录删除
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\Eventlog\Application\MySQL服务 目录删除
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\MySQL服务 目录删除
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application\MySQL服务目录删除
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\MySQL服务删除
5、删除环境变量
2下载
官网:https://www.mysql.com
点击 MySQL Community(GPL) Downloads
点击 MySQL Community Server
在General Availability(GA) Releases中选择适合的版本
3安装
MySQL下载完成后,找到下载文件,双击进行安装,具体操作步骤如下。
步骤1:双击下载的mysql-installer-community-8.0.26.0.msi文件,打开安装向导。
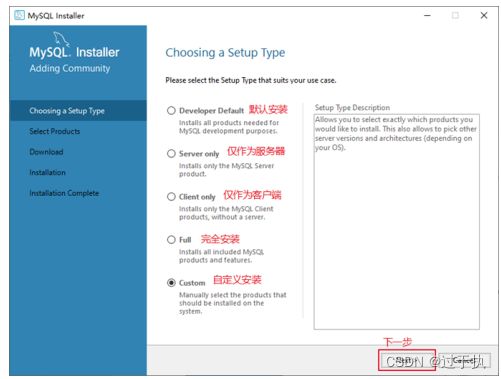
步骤2:打开“Choosing a Setup Type”(选择安装类型)窗口,在其中列出了5种安装类型,分别是Developer Default(默认安装类型)、Server only(仅作为服务器)、Client only(仅作为客户端)、Full(完全安装)、Custom(自定义安装)。这里选择“Custom(自定义安装)”类型按钮,单击“Next(下一步)”按钮。
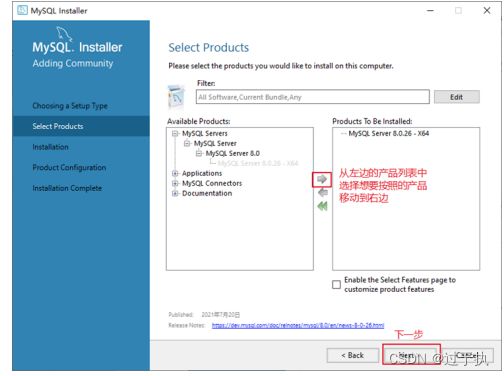
步骤3:打开“Select Products” (选择产品)窗口,可以定制需要安装的产品清单。例如,选择“MySQLServer 8.0.26-X64”后,单击“→”添加按钮,即可选择安装MySQL服务器,如图所示。采用通用的方法,可以添加其他你需要安装的产品。
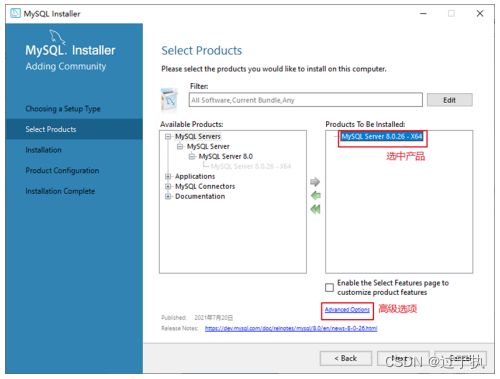
此时如果直接“Next”(下一步),则产品的安装路径是默认的。如果想要自定义安装目录,则可以选中对应的产品,然后在下面会出现“Advanced Options”(高级选项)的超链接。
单击“Advanced Options”(高级选项)则会弹出安装目录的选择窗口,如图所示,此时你可以分别设置MySQL的服务程序安装目录和数据存储目录。如果不设置,默认分别在C盘的Program Files目录和ProgramData目录(这是一个隐藏目录)。如果自定义安装目录,请避免“中文”目录。另外,建议服务目录和数据目录分开存放。
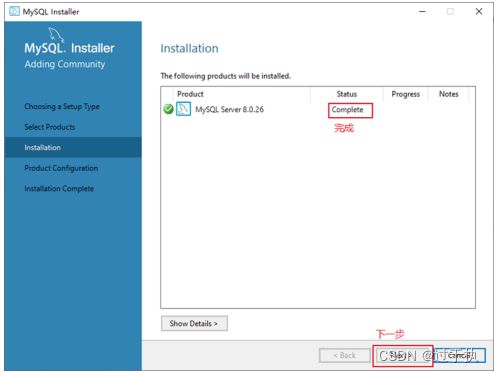
步骤4:在上一步选择好要安装的产品之后,单击“Next”(下一步)进入确认窗口,如图所示。单击“Execute”(执行)按钮开始安装。
步骤5:安装完成后在“Status”(状态)列表下将显示“Complete”(安装完成),如图所示。


4配置
步骤1:在上一个小节的最后一步,单击“Next”(下一步)按钮,就可以进入产品配置窗口。
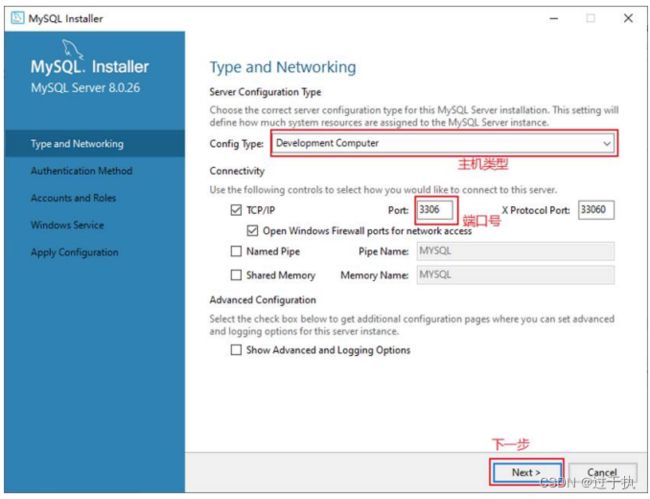
步骤2:单击“Next”(下一步)按钮,进入MySQL服务器类型配置窗口,如图所示。端口号一般选择默认端口号3306。
其中,“Config Type”选项用于设置服务器的类型。单击该选项右侧的下三角按钮,即可查看3个选项,如图所示。
- Development Machine(开发机器) :该选项代表典型个人用桌面工作站。此时机器上需要运行多个应用程序,那么MySQL服务器将占用最少的系统资源。
- Server Machine(服务器) :该选项代表服务器,MySQL服务器可以同其他服务器应用程序一起
运行,例如Web服务器等。MySQL服务器配置成适当比例的系统资源。- Dedicated Machine(专用服务器) :该选项代表只运行MySQL服务的服务器。MySQL服务器配置
成使用所有可用系统资源。步骤3:单击“Next”(下一步)按钮,打开设置授权方式窗口。其中,上面的选项是MySQL8.0提供的新的授权方式,采用SHA256基础的密码加密方法;下面的选项是传统授权方法(保留5.x版本兼容性)。
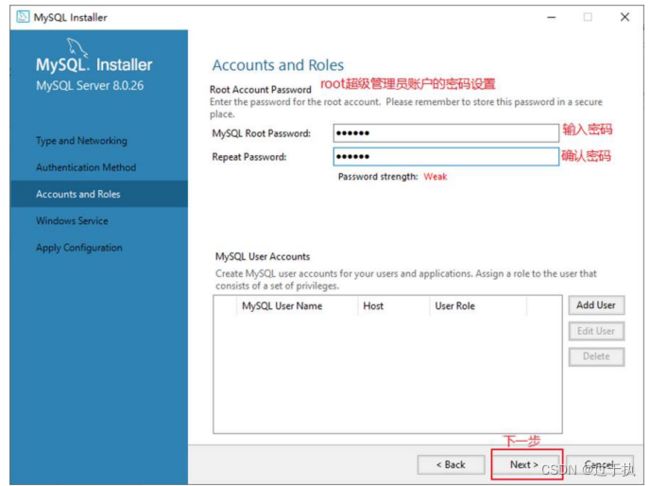
步骤4:单击“Next”(下一步)按钮,打开设置服务器root超级管理员的密码窗口,如图所示,需要输入两次同样的登录密码。也可以通过“Add User”添加其他用户,添加其他用户时,需要指定用户名、允许该用户名在哪台/哪些主机上登录,还可以指定用户角色等。此处暂不添加用户,用户管理在MySQL高级特性篇中讲解。
步骤5:单击“Next”(下一步)按钮,打开设置服务器名称窗口,如图所示。该服务名会出现在Windows服务列表中,也可以在命令行窗口中使用该服务名进行启动和停止服务。本书将服务名设置为“MySQL80”。如果希望开机自启动服务,也可以勾选“Start the MySQL Server at System Startup”选项(推荐)。
下面是选择以什么方式运行服务?可以选择“Standard System Account”(标准系统用户)或者“Custom User”(自定义用户)中的一个。这里推荐前者。
步骤6:单击“Next”(下一步)按钮,打开确认设置服务器窗口,单击“Execute”(执行)按钮。
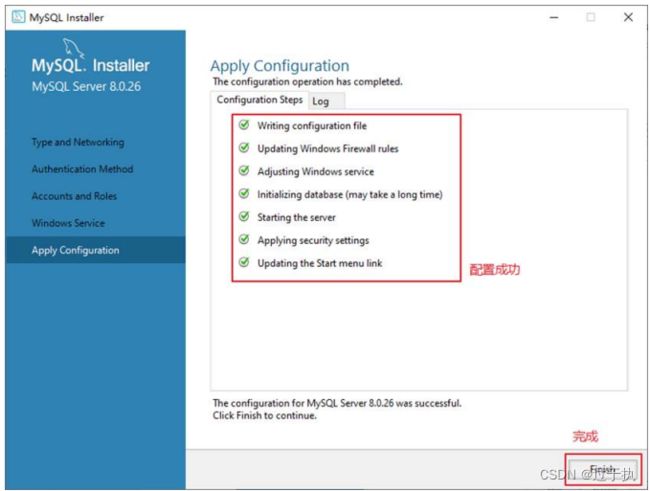
步骤7:完成配置,如图所示。单击“Finish”(完成)按钮,即可完成服务器的配置。
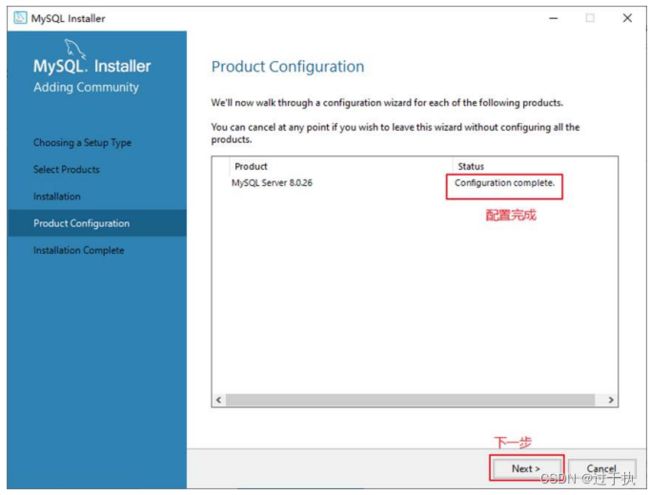
步骤8:如果还有其他产品需要配置,可以选择其他产品,然后继续配置。如果没有,直接选择“Next”(下一步),直接完成整个安装和配置过程。
步骤9:结束安装和配置。





基本的SELECT语句
SQL语言在功能上主要分为如下3大类:
- DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
- DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。SELECT是SQL语言的基础,最为重要。
- DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
还有单独将 COMMIT 、 ROLLBACK 取出来称为TCL (Transaction Control Language,事务控制语言)。
导入sql:
source 文件全路径
列的别名
- 紧跟列名,也可以在列名和别名之间加入关键字AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。AS 可以省略.
去除重复行
SELECT DISTINCT department_id,salary
FROM employees;
空值参与运算
- 所有运算符或列值遇到null值,运算的结果都为null
着重号
SELECT * FROM ORDER; -- 错误 --
SELECT * FROM `order`; -- 正确 --
显示表结构
- 使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees;
-- 或 --
DESC employees;
过滤数据
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
运算符
- +:只有加法作用,没有连接作用,可以转换成数值,则直接相加,如果无法转换,则+0处理
- / 或者 DIV:除结果为浮点数,分母为零时,结果为NULL
- % 或者 MOD:取模,结果正负与被模数符号一致
- <=>:安全等与,有NULL参与时:左右都是NULL为1,否则为0
- 最小最大值
LEAST(值1,值2,…,值n)。
GREATEST(值1,值2,…,值n)。 - LIKE运算符
“%”:匹配0个或多个字符。
“_”:只能匹配一个字符。
ESCAPE 指定转移符号SELECT job_id FROM jobs WHERE job_id LIKE ‘IT$_%‘ escape ‘$‘; - REGEXP运算符
(1)‘^’匹配以该字符后面的字符开头的字符串。
(2)‘$’匹配以该字符前面的字符结尾的字符串。
(3)‘.’匹配任何一个单字符。
(4)“[…]”匹配在方括号内的任何字符。例如,“[abc]”匹配“a”或“b”或“c”。为了命名字符的范围,使用一个‘-’。“[a-z]”匹配任何字母,而“[0-9]”匹配任何数字。
(5)‘’匹配零个或多个在它前面的字符。例如,“x”匹配任何数量的‘x’字符,“[0-9]”匹配任何数量的数字,而“”匹配任何数量的任何字符。
排序
- 没有指定排序操作,默认顺序按照添加时的顺序操作的
排序规则
使用 ORDER BY 子句排序
ASC(ascend): 升序
DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾。
默认升序
另外,列的别名只能在ORDER BY中使用,不能在WHERE等其他中使用(执行规则)
多级排序
ORDER BY '列1' DESC, '列2' ASC;
分页
规则
-
MySQL中使用 LIMIT 实现分页
LIMIT [位置偏移量,] 行数
第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是
1,以此类推);第二个参数“行数”指示返回的记录条数。--前10条记录: SELECT * FROM 表名 LIMIT 0,10; 或者 SELECT * FROM 表名 LIMIT 10; --第11至20条记录: SELECT * FROM 表名 LIMIT 10,10; --第21至30条记录: SELECT * FROM 表名 LIMIT 20,10;分页显式公式:(当前页数-1)*每页条数,每页条数
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize; -
注意:LIMIT 子句必须放在整个SELECT语句的最后!
-
使用 LIMIT 的好处:
约束返回结果的数量可以 减少数据表的网络传输量 ,也可以 提升查询效率 。如果我们知道返回结果只有1 条,就可以使用 LIMIT 1 ,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
-
MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT4,3;”返回的结果相同。
多表查询
从sql优化角度,在多表查询时,每个字段前都指明其所在的表
- 一旦为表起到别名,就必须用别名,不能在使用表名
等值连接与非等值连接
自连接与非自连接
内连接与外连接
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
- sql92(mysql不支持)
#左外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id = departments.department_id(+); #右外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id(+) = departments.department_id; - sql99
- 使用JOIN…ON子句创建连接的语法结构:
左外连接:SELECT table1.column, table2.column,table3.column FROM table1 JOIN table2 ON table1 和 table2 的连接条件 JOIN table3 ON table2 和 table3 的连接条件
右外连接:SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;#实现查询结果是B SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
UNION的使用
合并查询结果 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNIONALL关键字分隔。
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
7种JOIN的实现:

#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#左下图:满外连接
# 左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
自然连接
SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把自然连接理解为SQL92 中的等值连接。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行 等值连接 。
USING连接
当我们进行连接的时候,SQL99还支持使用 USING 指定数据表里的 同名字段 进行等值连接。但是只能配合JOIN一起使用。
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id);
你能看出与自然连接 NATURAL JOIN 不同的是,USING 指定了具体的相同的字段名称,你需要在 USING的括号 () 中填入要指定的同名字段。同时使用 JOIN…USING 可以简化 JOIN ON 的等值连接。它与下面的 SQL 查询结果是相同的:
SELECT employee_id,last_name,department_name
FROM employees e ,departments d
WHERE e.department_id = d.department_id;
单行函数
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2
… [ELSE resultn] END
CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN
值1 … [ELSE 值n] END
聚集函数
AVG和SUM函数
MIN和MAX函数
- 适用于数值类型、字符串类型、日期时间类型的字段
COUNT函数
问题:用count(),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
问题:能不能使用count(列名)替换count()?
不要使用 count(列名)来替代 count() , count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL
无关。
说明:count()会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
- AVG = SUM / COUNT
GROUP BY
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column]
SELECT中出现的非组函数的字段必须声明在GROUP BY中声明的字段可以不出现在SELECT中
WHERE必须要放在FROM下面
HAVING
行已经被分组。
使用了聚合函数。
满足HAVING 子句中条件的分组将被显示。
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
开发中的选择:
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
SELECT的执行过程
查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
执行顺序
编写顺序:
SELECT … FROM … WHERE … GROUP BY … HAVING … ORDER BY … LIMIT…
执行顺序:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1 ,就可以在此基础上再进行 WHERE 阶段 。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2 。
然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段 。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4 。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT阶段 。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1 和 vt5-2 。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段 ,得到虚拟表 vt6 。
最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段 ,得到最终的结果,对应的是虚拟表vt7 。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序