(2024,自级联扩散,关键点引导的噪声重新调度,时间感知特征上采样器)进行廉价的扩展:用于更高分辨率适应的自级联扩散模型
Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 相关工作
4. 自级联扩散模型
4.1. 问题阐述
4.2. 关键点引导的噪声重新调度
4.3. 时间感知特征上采样器
4.4. 分析与讨论
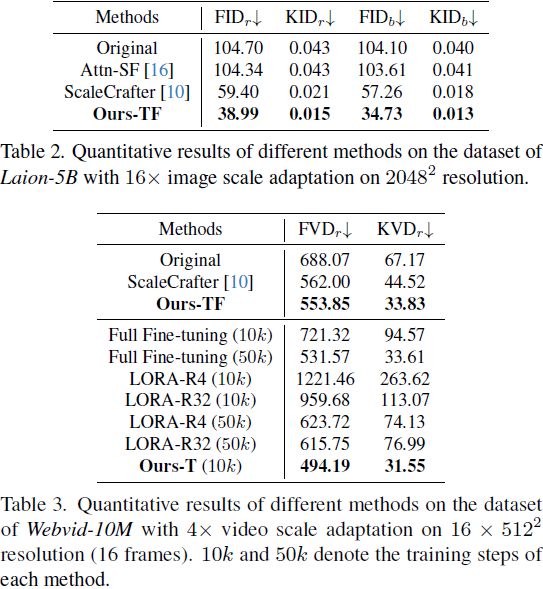
5. 实验
0. 摘要
扩散模型已被证明在图像和视频生成中非常有效;然而,在生成不同大小的图像时,它们仍然面临构图挑战,原因是单一尺度的训练数据。调整大型预训练扩散模型以满足更高分辨率的需求需要大量的计算和优化资源,然而实现与低分辨率模型相媲美的生成能力仍然是困难的。本文提出了一种新颖的自级联扩散模型(self-cascade diffusion model),利用从训练良好的低分辨率模型中获得的丰富知识,快速适应更高分辨率的图像和视频生成,采用无调整或廉价上采样器调整范例。通过集成一系列多尺度上采样模块,自级联扩散模型可以高效适应更高分辨率,保持原始构图和生成能力。我们进一步提出了一种基于关键点引导(Pivot-Guided)的噪声重新调度策略,加速推理过程并改善局部结构细节。与完全微调相比,我们的方法实现了 5 倍的训练加速,并且仅需要额外的 0.002M 调整参数。大量实验证明,我们的方法可以在仅微调 10k 步的情况下快速适应更高分辨率的图像和视频合成,几乎不需要额外的推理时间。
代码:https://github.com/GuoLanqing/Self-Cascade/
2. 相关工作
高分辨率合成和适应。尽管现有的稳定扩散合成方法取得了令人印象深刻的成果,但高分辨率图像生成仍然具有挑战性,并且需要大量的计算资源,主要是由于从更高维数据学习的复杂性。此外,由于收集大规模、高质量的图像和视频训练数据的实际困难,进一步限制了合成性能。为了应对这些挑战,先前的工作可以大致分为三种主要方法:
从头开始训练。这类工作可以进一步分为两类:级联模型 [7, 12, 13, 29] 和端到端模型 [3, 4, 14, 18]。级联扩散模型使用初始扩散模型生成低分辨率数据,然后通过一系列超分辨率扩散模型逐步上采样它。端到端方法学习一个扩散模型,并在一阶段直接生成高分辨率图像。然而,它们都需要顺序、分离的训练和大量高分辨率的训练数据。
微调。对于高分辨率适应,参数高效调整是一种直观的解决方案。DiffFit [34] 采用了一种定制的局部参数调整方法用于通用领域适应。郑等人 [37] 采用了 LORA [15] 作为额外的参数进行微调,但仍未专门设计用于尺度适应问题,仍然需要大量的微调步骤。
无需训练。最近,金等人 [16] 探索了一种变尺寸的无训练方法,但未解决高分辨率生成问题。ScaleCrafter [10] 采用了扩张卷积(dilated convolution)来扩大卷积层的感受野,以适应新的分辨率。然而,这些方法需要仔细调整,如扩张步幅和注入步幅,缺乏语义约束,并导致在各种对象生成尺度上产生伪影。
4. 自级联扩散模型
4.1. 问题阐述
给定一个预训练的稳定扩散(SD)模型,具有用于合成低分辨率图像(潜在代码)z ∈ R^d 的去噪器 ϵθ(·),我们的目标是以一种时间/资源和参数高效的方式,通过适应的模型 ˜ϵθ(·) 生成高分辨率图像 z^R ∈ R^(d_R)。为了实现这一目标,我们旨在重用来自训练良好的低分辨率模型的丰富知识,并仅在新尺度上学习低级别的细节。因此,我们构建了一个级联框架,包含原始尺度上的低分辨率模型和新尺度上的辅助模块。我们直观地定义了一个尺度分解,将整个尺度适应 R^d → R^(d_R) 分解为多个渐进适应过程,其中 d = d0 < d1 . . . < dR,其中 R = ⌈log4 d_R / d⌉。我们首先逐步合成低分辨率图像(潜在代码)z^(r−1),然后利用它作为关键点引导(pivot guidance),在下一阶段合成更高分辨率的结果 z_r,其中级联扩散模型的反向过程可以通过以下方式对每个 z_r 进行扩展
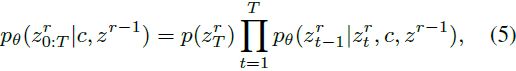
其中反向转移 pθ(zr t−1|zr t , c, zr−1) 不仅与去噪步骤 t 和文本嵌入 c 有关,还与在上一阶段生成的低分辨率潜在代码 z^(r−1) 有关。 先前的工作,如 [12]、LAVIE [32] 和 SHOW-1 [36],通过采用额外的超分辨率模型执行条件图像生成来解决这个问题,在这些方法中,他们将 z^(r−1) 和一个新的初始噪声图 z^r_T 串联作为输入到新的扩散去噪器。与它们不同,我们提出了一种自级联扩散模型,以循环重复使用低分辨率图像合成模型。
4.2. 关键点引导的噪声重新调度
根据第 4.1 节中解释的尺度分解,整个尺度适应过程将被解耦为多个中等适应,例如比前一阶段多 4× 像素。在 z^r 和 z^(r−1) 之间的信息容量差距不显著,尤其是在噪声存在的情况下(扩散的中间步骤)。因此,我们假设 p(z^r_K | z^(r−1)_0 ) 可以被视为 p(z^r_K | z^r) 的代理,用于手动设置当前适应阶段 R^(d_(r−1)) → R^(d_r) 的初始扩散状态,其中 K < T 是一个中间步骤。具体地,让 ϕr 表示一个确定性的调整插值函数(即双线性插值),用于从尺度 d^(r−1) 上采样到尺度 d_r。我们对上一阶段生成的低分辨率图像 z^(r−1)_0 进行上采样到 ϕr(z^(r−1)_0),以保持尺寸。然后我们可以通过 K 步扩散它,得到 z^(r−1)_K,并将其用于替代 z^r_K,如下所示:
![]()
将 z^r_K 视为当前阶段的初始状态,并从最后的 K → 0 步开始去噪,生成 z^r_0,这是当前阶段生成的更高分辨率图像。显然,这样的关键点引导策略可以扩展到所有解耦的尺度适应阶段。因此,使用关键点引导的噪声重新调度策略,生成分辨率为 d_R 的更高分辨率图像的整个合成过程可以说明如下:
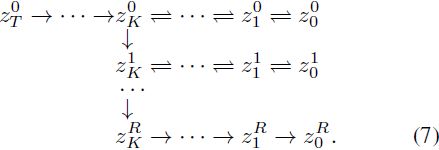
到目前为止,我们已经设计了一种免调节的自级联扩散模型,通过循环重复利用完全冻结的低分辨率模型,逐渐扩展模型的容量,以进行更高分辨率的适应,如图 2(a) 所示。
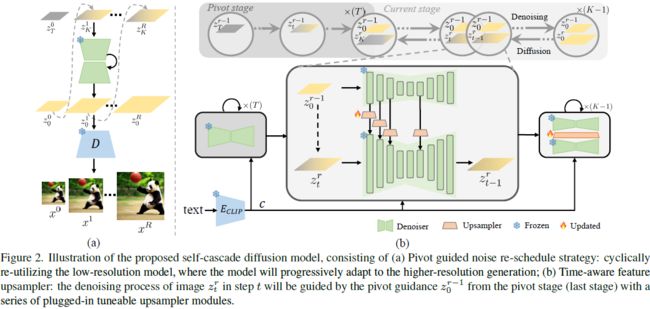
4.3. 时间感知特征上采样器
尽管建立在关键点引导的噪声重新调度(第 4.2 节)之上的免调谐自级联扩散模型可以实现一个可行的、无尺度的更高分辨率适应,但由于看不见的更高分辨率地面实况图像,它在合成性能方面存在局限,尤其是在详细的低级结构上。为了实现更实用和稳健的尺度适应性能,我们进一步引入了一种调谐自级联扩散模型,通过插入一个非常轻量级的时间感知特征上采样器,该上采样器可以插入任何基于扩散的合成方法,以实现更灵活的更高分辨率图像或视频适应,如图 2(b) 所示。
具体来说,给定步骤 t 中的去噪图像 z^r_t 和上一阶段的关键点引导 z^(r−1)_0,我们可以通过预训练的 UNet 去噪器 ϵθ 分别得到相应的中间多尺度特征组 h^r_t 和 h^(r−1)_0,如下所示:
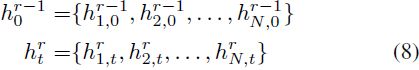
其中 N 代表每个特征组中的特征数量。受到最近的工作 [24] 的启发,该工作研究了 UNet 架构中各种组件对合成性能的影响,我们选择使用跳跃特征(skip features)作为一个特征组。这些特征对生成图像的质量几乎没有影响,同时仍然提供语义指导。我们定义了一系列时间感知特征上采样器 Φ = {ϕ1, ϕ2, . . . , ϕN},用于在每个相应的尺度上上采样和转换关键点特征。在扩散生成过程中,随着逐渐去除噪声,信噪比逐渐增加,焦点从高级语义逐渐转移到低级详细结构。因此,我们提出学习的上采样器变换应该适应不同的时间步骤。在每个尺度上,上采样后的特征 ϕ 与原始特征 h 相加:
![]()
优化细节。对于每个尺度适应 R^(d_(r−1)) → R^(d_r) 的训练迭代,我们首先随机采样一个步骤索引 t ∈ (0,K]。相应的优化过程可以定义为以下公式:
![]()
其中 θΦ 表示插入的上采样器的可训练参数,θ 表示预训练扩散去噪器的冻结参数。每个上采样器都是简单而轻量的,包括一个双线性上采样操作和两个残差块。在所有实验中,我们设置 N = 4,总共有 0.002M 可训练参数。因此,所提出的微调自级联扩散模型仅需要少量微调步骤(例如,10k)和少量的更高分辨率新数据的收集。
可扩展微调。值得注意的是,我们的自级联扩散模型可以无缝地扩展到新的更高分辨率合成,从而受益于在每个尺度适应阶段共享扩散模型的循环重复利用。例如,为尺度 R 适应的扩散模型 ˜ϵθ(·) 可以通过重新调整集成的特征上采样器模块,无需任何额外的参数,进一步适应先前未见的尺度 R′。

4.4. 分析与讨论
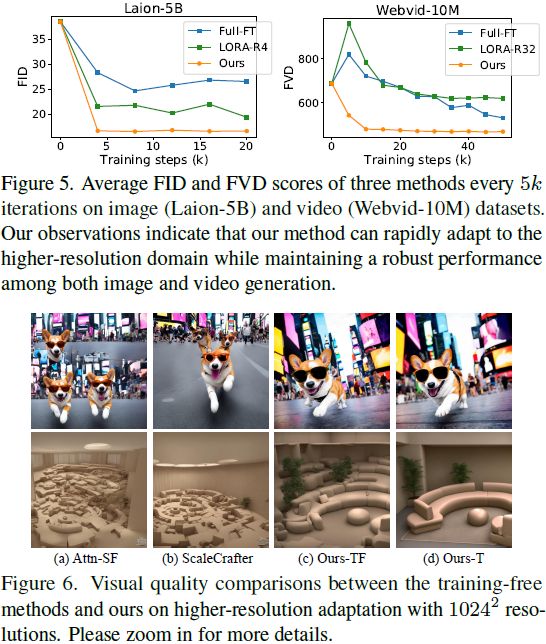
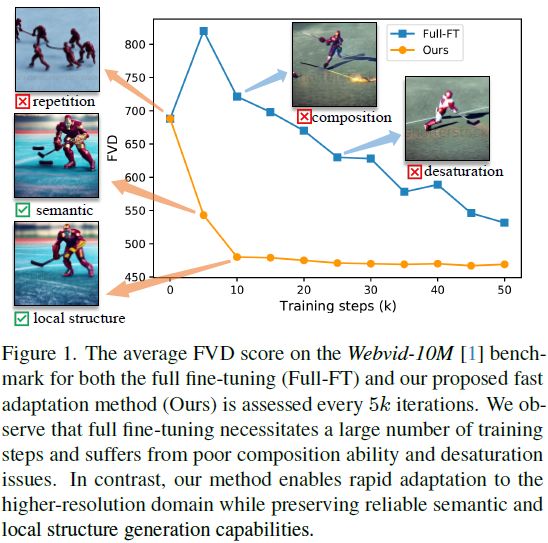
从先前对尺度适应的研究中汲取灵感 [10],我们发现直接将以 512^2 图像训练的 SD 2.1 模型应用于生成 1024^2 图像会导致问题,如对象重复和降低的组合能力(见图 1)。我们观察到,在适应的尺度不是很大时(例如,4× 更多的像素),生成图像的局部结构细节看起来合理且丰富,但缺乏平滑度。总体而言,适应更高分辨率的瓶颈在于语义组件和组合能力。幸运的是,原始预训练的低分辨率扩散模型可以生成可靠的低分辨率关键点,通过在更高分辨率的扩散采样过程中注入关键点语义特征,自然提供适当的语义引导。同时,在强烈的语义约束下,可以基于扩散模型本身学到的丰富纹理先验完成局部结构。
与用于高保真图像和视频生成的现有级联扩散框架 [12] 相比,我们的工作是第一个通过循环重复利用低分辨率预训练扩散模型进行自级联的研究,具有以下主要优势:
轻量级上采样器模块。传统的级联扩散模型包括多个扩散模型的流水线,用于生成分辨率逐渐增加的图像,从而导致模型参数数量的乘法增加。我们的模型建立在每个阶段共享的扩散模型之上,只使用非常轻量级的上采样器模块(即,0.002M 参数)进行调整。
最小的微调数据。先前的级联模型链需要顺序、单独的训练,每个模型都是从头开始训练,因此会带来显著的训练负担。我们的模型旨在使用少量高质量数据进行微调,快速将低分辨率合成模型调整到更高分辨率。
易于扩展。我们的模型具有适应新请求的更高分辨率的可扩展能力。这是通过重新调整集成的特征上采样模块而无需任何额外参数来实现的。相反,先前的级联模型需要为这样的调整训练额外的超分辨率模型。
局限性。我们提出的方法能够有效地适应更高分辨率的领域。然而,它仍然存在一些局限性。由于我们插入的插拔式上采样模块中的参数数量非常少,当有足够的训练数据时,我们的方法的性能存在上限,特别是当尺度差距太大时,例如高于 4k 分辨率的数据。在未来的工作中,我们将进一步探讨适应效率与泛化能力之间的平衡。
5. 实验
实验数据集和评估指标。我们选择 Laion-5B [23] 作为基准数据集,其中包含 50 亿个图像-标题对。我们从数据集中随机抽取 30k 张带有文本提示的图像,并使用 Inception Distance(FID)和 Kernel Inception Distance(KID)指标评估生成图像的质量和多样性,这些指标是在生成图像和真实图像之间测量的,分别表示为 FIDr 和 KIDr。
与先前的工作 [10] 一样,当推断分辨率高于 1024^2 时,我们采样 10k 张图像。为了确保图像预处理步骤的一致性,我们使用了 clean-fid 实现 [17]。由于预训练模型可以结合训练集中不存在的不同概念,我们还测量了在基础训练分辨率和推断分辨率下生成的样本之间的 FID 和 KID 指标,分别表示为 FIDb 和 KIDb。