GptSoVits音频教程
这个号称5秒克隆,或者用1分钟音频训练10分钟就能达到原声效果。
5秒的号称,只要是,什么几秒的,大家可以完全不要想了,什么知更鸟,什么火山,包括本次的GptSoVits的效果肯定是不行的,数据太短效果不可能达到。所以这些都听不出来本人的声音。
新测试,拿35秒的高质量音频训练,效果确实还可以吊打目前世面一切中文训练的。
重点关注1分钟的音频训练10分钟,是否能赶超阿里的kantts。阿里1分钟音频训练10分钟出来,音色是比较像的,但是杂音和混响严重。这也是本文的目的。
由于是测试这里就不部署linux版本,直接用作者提供的整合包
资源位置(123网盘)
GPT-SoVITS官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘
环境:
win10,我显卡是3060ti(12g显存),装了nvida驱动。内存建议16G(2条8g才60块钱,很便宜,9成新)
1.安装
由于是整合包,解压就行,这里用7z解压,因为rar压缩包里面有2个7z的文件,是2个版本的。
2.数据集准备
2.1去混响
我是干净的人声,但是有空调声,我试一下这个功能

然后会自动弹出一个新页面,进行下图操作

然后点转换,等待每一条处理完成
完毕后,UVR5-WebUI(关闭这个页面,取消对钩就行)
2.2切分文件,降低显存,用于每条每条训练
我已经是切分过的了,就不用切分了,我以前写了个程序更方便切分
https://shiao.blog.csdn.net/article/details/133700129
2.3使用funAsr进行文本标注
这边是我以前写的单独做asr标注的,这个中文效果比openAi的whisper好。
中文语音标注工具FunASR(语音识别)-CSDN博客
本文中是用他集成好的asr,修改输入和输出

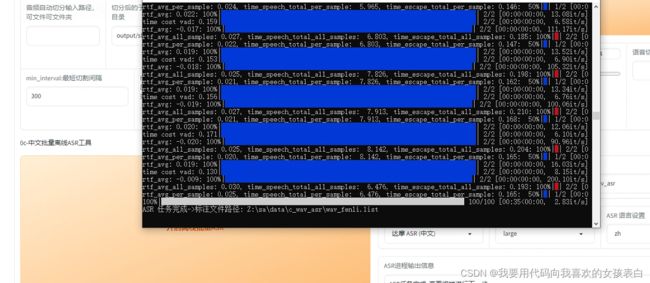
之后点击开启批量ASR,看黑窗口,他会去下载模型(第一次比较慢,请耐心等待)

成功后
2.4文本校对,就是用耳朵听,看看哪个地方不对

输入刚刚合成的【文件路径】,然后勾选启动打标WebUI
稍后会弹出新页面
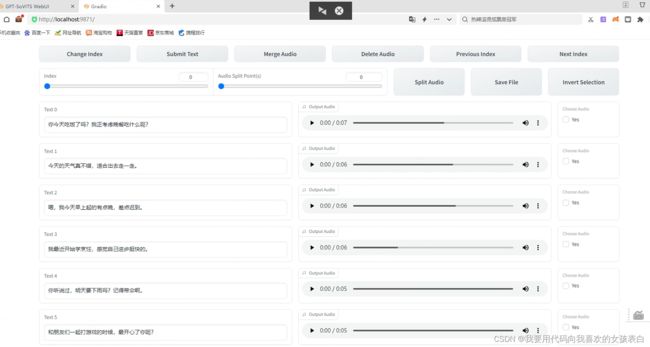
听声音,看哪个不对,就改掉。觉得声音完全不对的,可以勾选yes然后点deleteAudio按钮删除。
想听下一批点击next index。最后点击SaveFile。
3.训练
进入训练步骤
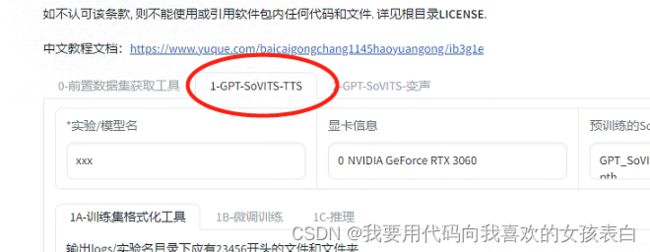
3.1执行特征提取
和sovits一样,推理的同样会默认保存在logs中
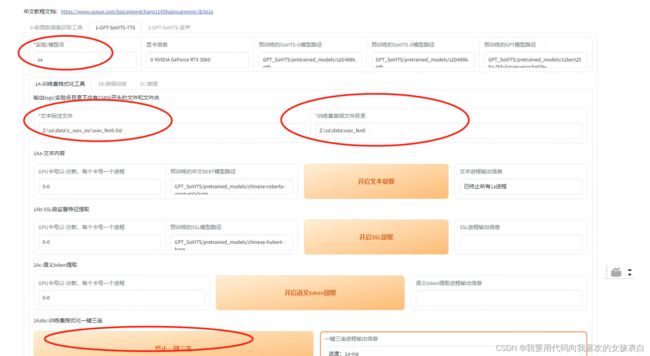
输入实验名,然后给定标注路径还有音频路径,点击一键三连开始训练。
3.2训练微调
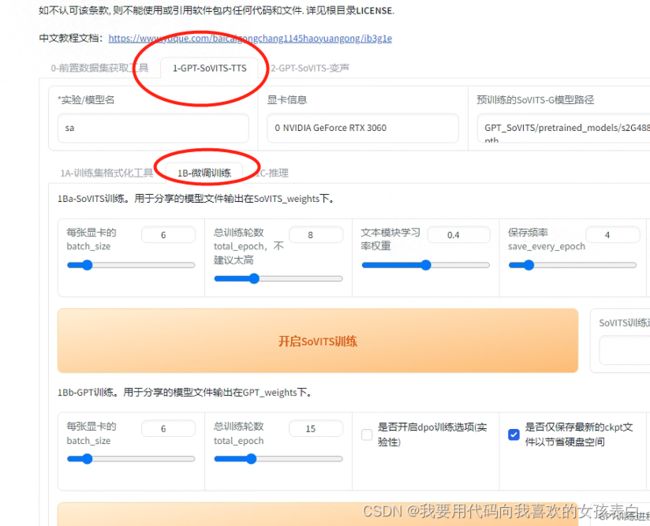
参数的话我显存12G,我就调高了一点,大家也可以用默认。
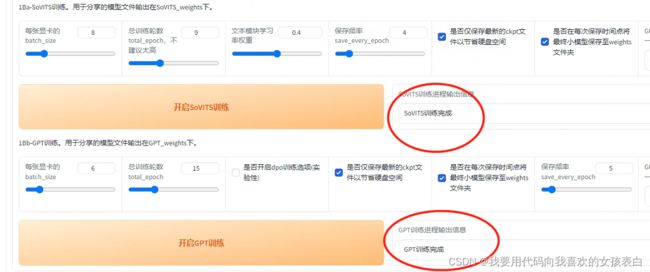
点击开始sovits训练,然后看窗口,没有报错就行。
训练完成后,然后,开始GPT训练,我GPU占用率百分之40。
4.推理
4.1推理模型配置
点击推理界面,先刷新模型,然后点击推理,然后打钩

打钩后,稍等一会儿就会弹出一个推理界面
4.2推理测试
刷新模型路径,上传语音,然后输入文本,点击合成语音
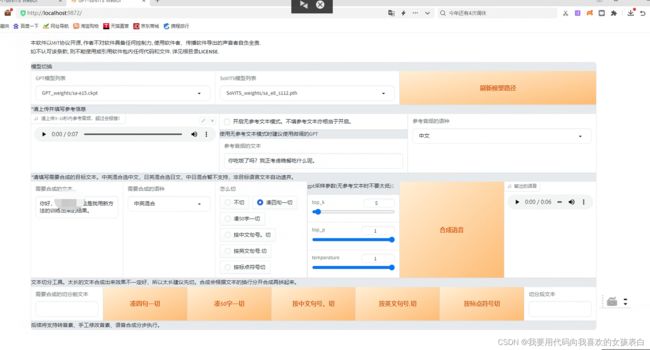

结果:
效果很不错,清晰度居然超过了kantts-sambert预训练16k。但是有个别吐字错误的情况。不过效果确实不错,我训练的数据是300句录音棚数据。
参考:
语音克隆神器GPT-SoVITS,只需一分钟素材训练模型,AI文字转语音效果堪比真人 | 科技与狠活
耗时两个月自主研发的低成本AI音色克隆软件,免费送给大家!【GPT-SoVITS】_哔哩哔哩_bilibili