AllenAI 开源了关于大模型的所有细节!数据、代码、参数、训练过程,完全复现
开篇:OLMo的诞生与开放模型的重要性
在人工智能领域,语言模型(LMs)的发展一直是推动自然语言处理(NLP)技术进步的核心力量。随着商业价值的增长,强大的语言模型逐渐被封闭在专有接口之后,它们的训练数据、架构和开发细节往往不为人知。然而,这些细节对于科学研究至关重要,它们不仅关系到模型的偏见和潜在风险,也是理解和改进模型性能的关键。
鉴于此,我们介绍OLMo:一个真正开放的、最先进的语言模型及其构建和研究语言模型科学的框架。OLMo的发布不同于以往的努力,它不仅仅提供了模型权重和推理代码,而且包括了训练数据、训练和评估代码,甚至是训练过程中的中间模型检查点和日志。我们希望这一举措能够赋能开放研究社区,激发新一波创新浪潮。
论文标题:
OLMo : Accelerating the Science of Language Models
论文链接:
https://arxiv.org/pdf/2402.00838.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
OLMo模型框架全景
OLMo模型的构成与架构
OLMo模型采用基于Vaswani等人(2017 年)的纯解码器transformer架构,并提供了1B和7B两种规模的变体(表1)。该架构在标准transformer的基础上进行了多项改进,包括去除所有偏置项、使用非参数化层归一化、SwiGLU激活函数、旋转位置嵌入(RoPE)以及修改后的BPE基础词汇表。这些改进使得OLMo在结构上更为高效,并在性能上与其他类似规模的模型相比具有竞争力(表2)。


Dolma预训练数据集的构建与特点
Dolma预训练数据集是一个多源、多样化的语料库,包含3T token,来自7种不同的公开数据源(表3)。数据集的构建过程包括语言过滤、质量过滤、内容过滤、去重、多源混合和词汇化等步骤。Dolma的设计原则、构建细节和内容摘要在其报告中有详细说明,旨在支持对语言模型预训练的开放研究。

评估框架的设计与实施
OLMo的评估框架包括在线评估和离线评估两个阶段。在线评估用于模型设计决策,而离线评估则用于评估模型检查点。使用Catwalk框架进行下游评估和基于困惑度的内在语言模型评估。此外,OLMo-7B是最大的LM,进行了明确的去污染处理,以确保在困惑度评估中不会低估模型的外部拟合能力。
OLMo模型的创新之处
架构改进与性能对比
OLMo模型在架构上的主要创新包括去除偏置项、采用非参数化层归一化、SwiGLU激活函数、旋转位置嵌入(RoPE)和特殊的词汇表设计。这些改进使得OLMo在性能上与其他类似规模的模型相比具有竞争力。
预训练数据集Dolma的开放性与多样性
Dolma数据集的开放性和多样性为语言模型预训练研究提供了重要支持。它由多个公开数据源组成,经过严格的筛选和处理,以确保数据质量和多样性。
评估工具的全面性与透明度
OLMo的评估工具包括Catwalk和Paloma,它们提供了广泛的数据集和任务格式,使得模型评估更加全面和透明。此外,OLMo-7B的去污染处理确保了评估结果的准确性,避免了因数据泄露导致的困惑度低估问题。
OLMo模型的训练过程
分布式训练框架的应用
OLMo模型的训练采用了分布式训练框架,以提高训练效率和缩短训练时间。具体来说,使用了ZeRO优化器策略和PyTorch的FSDP(Fully Sharded Data Parallel)框架,这些技术通过在多个GPU之间分片模型权重及其对应的优化器状态,有效减少了内存消耗。在7B规模的模型上,这使得每个GPU能够处理4096 token的微批量大小。
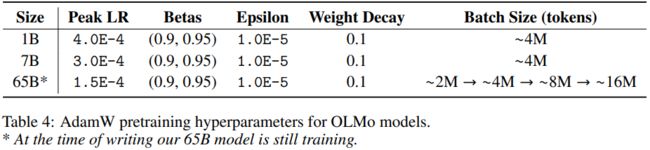
优化器设置与超参数选择
在优化器的选择上,OLMo模型使用了AdamW优化器,并对其超参数进行了精心调整(表4)。训练过程中,学习率在5000步(约21B token)内预热,之后线性衰减至峰值学习率的十分之一。此外,为了避免训练过程中的梯度爆炸,还引入了梯度裁剪,确保参数梯度的总L2范数不超过1.0。表5则比较了OLMo模型的优化器设置与其他同样使用AdamW的模型优化器设置。

数据准备与硬件配置
OLMo模型的训练数据来自于Dolma数据集,这是一个多源、多样性的语料库,包含了3T token,覆盖了5B文档。在数据准备阶段,每个文档后都添加了特殊的EOS token,并将连续的2048 token组成训练实例。为了确保训练的一致性,每次训练运行时都以相同的方式打乱训练实例的次序。
在硬件配置方面,OLMo模型在两种不同的集群上进行了训练,以验证代码库在NVIDIA和AMD GPU上的性能。这两个集群分别是LUMI超级计算机和MosaicML提供的集群。尽管在批量大小上有细微差别,但两次运行在2T token的评估套件上显示出几乎相同的性能。
OLMo模型的评估结果
下游任务评估:OLMo-7B的零样本性能
在下游任务的评估中,OLMo-7B模型在Catwalk框架下进行了零样本性能评估。评估套件包括9个核心任务,OLMo-7B在2个结束任务上超越了所有其他公开可用的模型,并在8/9个结束任务上保持在前三名(表6)。这表明OLMo-7B在下游任务的性能上具有竞争力(图1)。


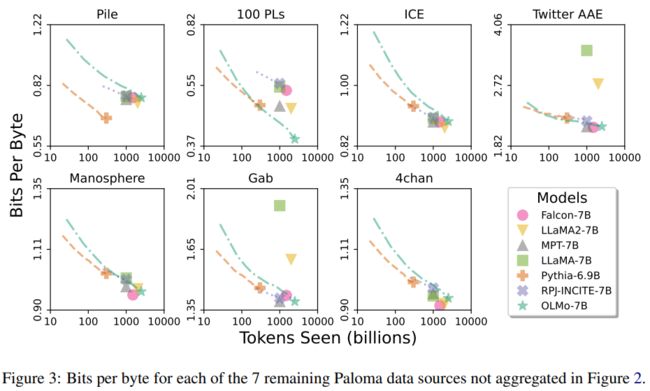
语言建模内在评估:OLMo-7B的困惑度表现
在内在语言建模评估中,使用了Paloma基准测试来衡量OLMo-7B模型对语言分布的拟合程度(图2、3)。Paloma包含585个不同的文本域,从《纽约时报》到Reddit上的r/depression等。OLMo-7B是经过明确去污染处理的最大型语言模型,以确保评估数据不会因为预训练数据的泄露而低估困惑度。

模型性能的进一步分析与讨论
OLMo-7B模型的性能不仅在最终模型上进行了比较,还包括了中间检查点,这允许与其他发布检查点的模型进行更丰富的比较。此外,还对模型的能耗和碳足迹进行了评估,以估算在训练过程中消耗的总能量和释放的碳排放量。这些评估结果有助于了解开发最先进模型的真实成本,并为未来的可持续人工智能发展提供洞见。
能源消耗与碳足迹:OLMo模型训练的环境影响
在人工智能领域,模型训练的能源消耗和碳足迹问题日益受到关注。OLMo模型的训练过程也不例外。为了估算OLMo模型训练过程中的总能源消耗和碳排放,研究者们采取了一系列的测量和计算方法(表7)。首先,通过每25毫秒测量单个节点的功耗,计算整个训练过程的平均功耗,并乘以节点总数。然后,考虑到数据中心的能效,将得到的总功耗乘以功率使用效率(PUE)因子,这里假设为1.1,代表了能效较高的数据中心通常有10%的能源消耗开销。

据估算,OLMo的7B模型训练消耗了239兆瓦时(MWh)的能源。为了计算碳排放量,研究者们将总功耗乘以碳强度因子,即每千瓦时排放的二氧化碳公斤数。其中,使用A100-40GB GPU在澳大利亚训练的模型,假设了一个0.610的碳强度因子,这是2022年澳大利亚的国家平均值。而在LUMI超级计算机上训练的模型使用的是100%可再生、碳中和能源,因此假设碳强度因子为0。根据这些计算,预估OLMo模型训练的总碳排放量为69.78吨二氧化碳当量(tCO2eq)。
研究者们希望通过公开发布OLMo模型,可以减少未来的碳排放,因为这允许其他人避免从头开始训练模型的需要,并且提供了开发最先进模型的真实成本见解。需要注意的是,这些估算值应被视为下限,因为它们没有包括其他排放源,如硬件和数据中心基础设施的制造、运输和处置过程中的固有排放,以及使用、反弹效应或其他环境影响,如水消耗或采矿等。
发布的工具与数据集
训练与建模代码
OLMo项目发布了完整的训练和建模代码,使研究者能够复现模型训练过程,或者在此基础上进行进一步的研究和开发。这些代码托管在GitHub上,可以通过相关链接访问。
预训练模型权重与中间检查点
除了最终的模型权重,OLMo项目还发布了500多个训练过程中的中间检查点,这些检查点以1000步为间隔保存,可通过HuggingFace平台获取。这为研究者提供了丰富的资源,以探索模型在不同训练阶段的性能变化。
预训练数据集Dolma与数据集构建工具
OLMo使用了Dolma数据集进行预训练,这是一个多源、多样化的语料库,包含了3万亿个token,来自7种不同的数据源。项目不仅发布了数据集本身,还提供了构建数据集的工具,以及WIMBD工具,用于数据集分析。
评估代码与Catwalk工具
为了评估模型性能,OLMo项目发布了评估代码和Catwalk工具。Catwalk是一个公开可用的评估工具,提供了多种数据集和任务格式,用于下游评估以及基于困惑度的内在语言模型评估。这些工具的发布,使得研究者可以在固定的评估管道中对模型进行比较和分析。
通过这些工具和数据集的发布,OLMo项目旨在鼓励开放研究,并减少学术界和实践者们重复而代价高昂的努力。所有代码和权重都在Apache 2.0许可下发布,以提供给用户在使用这些资源和工件时的灵活性。
开放许可与未来工作
Apache 2.0许可证的选择与意义
Apache 2.0许可证是一个自由和宽松的许可证,它允许用户自由地使用、修改和分发软件,同时保留了对原始作者的归属。选择Apache 2.0许可证对于OLMo项目具有重要的意义,因为它不仅促进了科学发展,还赋予了科学界更大的灵活性来使用这些资源和工件。与其他组织使用的许可证相比,Apache 2.0没有限制模型输出用于训练人工智能或机器学习系统,也没有限制商业用途。这种开放性的选择反映了OLMo团队对于推动开放科学研究的承诺,以及对于促进科学进步和工程进步的希望。
OLMo模型未来的发展方向
OLMo模型的未来发展方向包括计划发布更大的模型、指令调整模型以及更多模态和变体。这些计划的发布将有助于研究目前尚不甚了解的模型方面,例如预训练数据与模型能力之间的关系、设计和超参数选择的影响,以及各种优化方法对模型训练的影响。此外,OLMo团队还将分享在此规模训练语言模型的经验教训和重要细节。通过这些努力,OLMo项目旨在不断支持和扩展OLMo及其框架,并继续推动开放语言模型的边界,以赋能开放研究社区并激发创新的新浪潮。
结论:OLMo对开放科学研究的贡献与展望
OLMo作为一个真正开放的语言模型和框架,其首次发布标志着开放科学研究的一个重要里程碑。与之前的工作相比,OLMo不仅仅发布了模型权重和推理代码,还包括了训练数据、训练和评估代码。这种全面的开放性将极大地赋能和加强开放研究社区,为未来的创新提供了新的动力。OLMo的发布旨在催化对这些模型的科学研究,包括它们的优势和弱点,以及它们的偏见和风险。
未来,OLMo团队计划继续支持和扩展OLMo及其框架,推动开放语言模型的界限,引入不同的模型尺寸、模态、数据集、安全措施和评估。通过这些持续的努力,OLMo项目不仅为科学界提供了一个强大的研究工具,还为理解和改进语言模型的科学和工程进步做出了贡献。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。

