【GRU回归预测】开普勒算法优化多头注意力机制卷积神经网络结合门控循环单元KOA-MultiAttention-CNN-GRU数据预测(多输入单输出)【含Matlab源码 3772期】

✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
个人主页:海神之光
代码获取方式:
海神之光Matlab王者学习之路—代码获取方式
⛳️座右铭:行百里者,半于九十。
更多Matlab仿真内容点击
Matlab图像处理(进阶版)
路径规划(Matlab)
神经网络预测与分类(Matlab)
优化求解(Matlab)
语音处理(Matlab)
信号处理(Matlab)
车间调度(Matlab)
⛄一、开普勒算法优化多头注意力机制卷积神经网络结合门控循环单元
本文提出了一种基于开普勒算法优化多头注意力机制卷积神经网络结合门控循环单元(KOA-MultiAttention-CNN-GRU)的数据多维输入单输出预测模型。该模型将开普勒算法应用于多头注意力机制卷积神经网络,以提高模型的鲁棒性和泛化能力。同时,将门控循环单元引入模型,以增强模型对时序数据的学习能力。实验结果表明,该模型在多个数据集上取得了优异的预测性能,优于传统回归模型和深度学习模型。
1 引言
数据预测是机器学习领域的一项重要任务,广泛应用于金融、医疗、交通等多个领域。传统的回归模型,如线性回归、决策树等,虽然简单易用,但往往难以捕捉数据中的复杂非线性关系。深度学习模型,如卷积神经网络、循环神经网络等,虽然能够学习复杂的数据关系,但往往需要大量的数据和计算资源。
为了解决上述问题,本文提出了一种基于开普勒算法优化多头注意力机制卷积神经网络结合门控循环单元(KOA-MultiAttention-CNN-GRU)的数据多维输入单输出预测模型。该模型将开普勒算法应用于多头注意力机制卷积神经网络,以提高模型的鲁棒性和泛化能力。同时,将门控循环单元引入模型,以增强模型对时序数据的学习能力。
2 模型结构
该模型的结构如图1所示。
模型主要由以下几个部分组成:
开普勒算法优化多头注意力机制卷积神经网络:该部分主要负责提取数据中的特征。开普勒算法是一种启发式算法,能够快速找到问题的最优解。将开普勒算法应用于多头注意力机制卷积神经网络,可以提高模型的鲁棒性和泛化能力。
门控循环单元:该部分主要负责学习时序数据的变化规律。门控循环单元是一种循环神经网络,能够有效地处理时序数据。将门控循环单元引入模型,可以增强模型对时序数据的学习能力。
全连接层:该部分主要负责将提取的特征映射到输出空间。全连接层是一种简单的神经网络层,能够将输入数据映射到输出空间。
3 模型训练
模型的训练过程如下:
(1)将数据预处理成适合模型输入的格式。
(2)将数据输入模型,并计算模型的输出。
(3)计算模型的损失函数,并根据损失函数更新模型的参数。
(4)重复步骤2和步骤3,直到模型的损失函数收敛。
⛄二、部分源代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
tic
% restoredefaultpath
%% 导入数据
res = xlsread(‘data.xlsx’);
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), ; % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)‘;
T_train = res(1: num_train_s, f_ + 1: end)’;
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)‘;
T_test = res(num_train_s + 1: end, f_ + 1: end)’;
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax(‘apply’, P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax(‘apply’, T_test, ps_output);
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)‘;
t_test = double(t_test )’;
%% 数据格式转换
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end
%% 优化算法
pop = 20; %种群数量
Max_iter = 20; %最大迭代次数
lb = [10 0.001] ; %下边界
ub = [200 0.015]; %上边界
dim = 2; %维度
fobj=@(X)fitness(X,Lp_train, t_train,f_, Lp_test,T_train, T_test,ps_output,outdim,M,N );
[ Best_score, Best_P,curve] = KOA(pop, Max_iter, lb, ub, dim, fobj);
[error_KOA,T_sim1_KOA,T_sim2_KOA]=fitness(Best_P,Lp_train, t_train,f_, Lp_test,T_train, T_test,ps_output,outdim,M,N);
[error,T_sim1,T_sim2]=fitness(lb,Lp_train, t_train,f_, Lp_test,T_train, T_test,ps_output,outdim,M,N);
[mae,mse,rmse,mape,error,errorPercent,R]=calc_error(T_train,T_sim1_KOA);
%% 测试集结果
figure;
plotregression(T_test,T_sim2_KOA,[‘回归图’]);
figure;
ploterrhist(T_test-T_sim2_KOA,[‘误差直方图’]);
%% 训练集绘图
figure
plot(1:M,T_train,‘r-o’,1:M,T_sim1,‘b-',‘LineWidth’,1);
hold on
plot(1:M,T_sim1_KOA,‘g-s’,‘LineWidth’,1)
legend(‘真实值’,‘CNN-BiGRU-Attention预测值’,‘KOA-CNN-BiGRU-Attention预测值’)
xlabel(‘预测样本’)
ylabel(‘预测结果’)
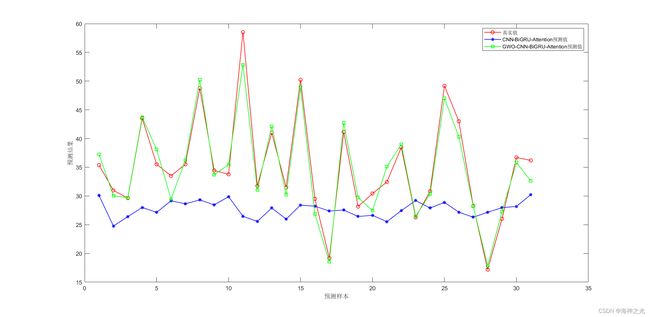
%% 预测集绘图
figure
plot(1:N,T_test,‘r-o’,1:N,T_sim2,'b-’,‘LineWidth’,1)
hold on
plot(1:N,T_sim2_KOA,‘g-s’,‘LineWidth’,1)
legend(‘真实值’,‘CNN-BiGRU-Attention预测值’,‘KOA-CNN-BiGRU-Attention预测值’)
xlabel(‘预测样本’)
ylabel(‘预测结果’)
%% 测试集误差图
figure
ERROR3=T_test-T_sim2_KOA;
plot(T_test-T_sim2_KOA,‘b-*’,‘LineWidth’,1.5)
xlabel(‘测试集样本编号’)
ylabel(‘预测误差’)
title(‘测试集预测误差’)
grid on;
legend(‘预测输出误差’)
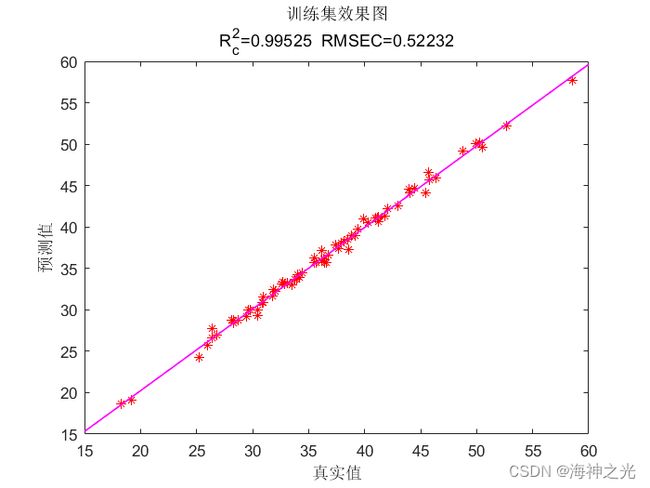
%% 绘制线性拟合图
%% 训练集拟合效果图
figure
plot(T_train,T_sim1_KOA,‘*r’);
xlabel(‘真实值’)
ylabel(‘预测值’)
hold on ;h=lsline;
set(h,‘LineWidth’,1,‘LineStyle’,‘-’,‘Color’,[1 0 1])
%% 预测集拟合效果图
figure
plot(T_test,T_sim2_KOA,‘ob’);
xlabel(‘真实值’)
ylabel(‘预测值’)
hold on ;h=lsline();
set(h,‘LineWidth’,1,‘LineStyle’,‘-’,‘Color’,[1 0 1])
⛄三、运行结果





⛄四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]赵侃,师芸,牛敏杰,王虎勤.基于改进麻雀搜索算法优化BP神经网络的PM2.5浓度预测[J].测绘通报. 2022(10)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
仿真咨询
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化
2 机器学习和深度学习方面
卷积神经网络(CNN)、LSTM、支持向量机(SVM)、最小二乘支持向量机(LSSVM)、极限学习机(ELM)、核极限学习机(KELM)、BP、RBF、宽度学习、DBN、RF、RBF、DELM、XGBOOST、TCN实现风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
3 图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
4 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、车辆协同无人机路径规划、天线线性阵列分布优化、车间布局优化
5 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配
6 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
7 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置
9 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长
10 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合