每日面经总结
1.说一下java的数据类型有哪些?
Java 的数据类型可以分为两大类:基本类型(Primitive Types)和引用类型(Reference Types)。下面是这两种类型的详细分类:
基本类型 (Primitive Types)
Java 中有 8 种基本类型,分为四类:
1. 整数型
- `byte`:8位,取值范围从 -128 到 127。
- `short`:16位,取值范围从 -32,768 到 32,767。
- `int`:32位,取值范围从 -2^31 到 2^31-1。
- `long`:64位,取值范围从 -2^63 到 2^63-1。
2. 浮点型
- `float`:32位,单精度浮点数。
- `double`:64位,双精度浮点数。
3. 字符型
- `char`:16位,用于表示单个字符(如 'A', '1', '中')。
4. 布尔型
- `boolean`:表示真(true)或假(false)。
引用类型 (Reference Types)
1. 类 (Class)
- 如 `String`, `Integer`, `Object` 等,包括用户自定义的类。
2. 接口 (Interface)
- 如 `List`, `Map`, `Serializable` 答等。
3. 数组 (Array)
- 可以是基本类型数组,如 `int[]`, `double[]`,也可以是引用类型数组,如 `String[]`, `Object[]`。
引用类型存储的是对象的引用(内存地址),而不是实际的对象本身。这与基本类型不同,基本类型直接存储值。引用类型的默认值是 `null`,而基本类型的默认值取决于具体类型(例如,`int` 的默认值是 `0`,`boolean` 的默认值是 `false`)。
2.List和Set的实现类有哪些?
在 Java 中,`List` 和 `Set` 是两种不同类型的集合,它们各自有多种实现类,每种实现类都有其特定的特性和用途。
List 实现类
`List` 接口的实现主要提供了有序的集合。常见的实现类包括:
1. ArrayList:
- 基于动态数组实现。
- 提供快速的随机访问和高效的遍历。
- 不是线程安全的。
- 当元素频繁添加或删除时,性能较低,因为这涉及到数组的复制和移动。
2. LinkedList:
- 基于双向链表实现。
- 优化了插入和删除操作。
- 随机访问较慢,但在列表中间添加或删除元素较快。
- 也可用作栈、队列或双端队列。
3. Vector:
- 类似于 `ArrayList`,但所有方法都是同步的,是线程安全的。
- 因为同步,通常比 `ArrayList` 慢。
- 有一个子类 `Stack`,实现了栈的数据结构。
4. CopyOnWriteArrayList:
- 线程安全的 `ArrayList` 变体。
- 每次修改时都会复制底层数组,适用于读多写少的并发场景。
Set 实现类
`Set` 接口的实现主要提供了不包含重复元素的集合。常见的实现类包括:
1. HashSet:
- 基于哈希表实现。
- 提供快速访问,确保元素唯一性。
- 元素没有顺序。
2. LinkedHashSet:
- 基于哈希表和链表实现。
- 维护了元素的插入顺序。
- 性能略低于 `HashSet`,但在迭代访问时效率高。
3. TreeSet:
- 基于红黑树实现。
- 元素按自然顺序或自定义比较器排序。
- 提供了有序集合的操作,但添加和查询的速度慢于 `HashSet`。
4. EnumSet:
- 专门为枚举类型设计的高效集合实现。
- 内部以位向量的形
式表示,非常紧凑和高效。
5. CopyOnWriteArraySet:
- 类似于 `CopyOnWriteArrayList`,是线程安全的。
- 每次修改时都会复制底层数组,适用于读多写少的并发场景。
- 内部实际使用 `CopyOnWriteArrayList` 进行数据存储。
3.HashMap线程安全么?为什么不安全?
HashMap在jdk1.7中会发生死循环的问题,1.7版本的的数据结构采用的是数组+链表,在插入数据的时候采用的是头插法,那么就在扩容的时候新数组链表的元素顺序发生改变
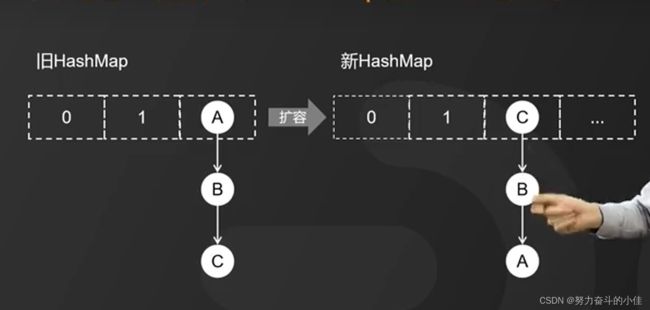
那么为什么会导致死锁问题的产生呢,分为三个步骤,第一就是加入现在有1线程T1和线程T2都准备向A节点插入数据,他们的下一个节点分别是T1.next和T2.next他们都指向B节点,第二步就是开始扩容,现在假设是T2的时间片用完了进入到休眠状态,而线程T1开始进行扩容动作,一直执行到扩容完成之后线程T2才被唤醒,以下是扩容之后的画面
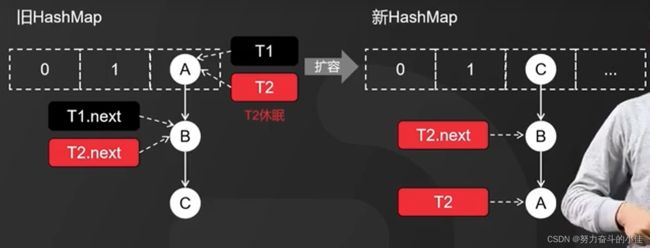
线程T1执行完扩容之后,线程T2的指向依然没有发生变化,此时又会执行回去,节点的顺序又变成回去了,造成了死循环。
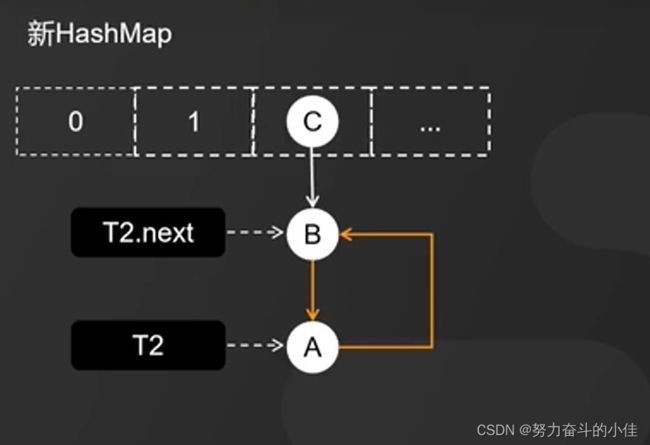
解决方案

小结

4.生产者消费者模型
生产者-消费者模型是一种常用的并发设计模式,用于处理在多线程环境下生产数据项和消费数据项的问题。这个模型通过解耦生产者和消费者的操作来提高程序的并发性能和复用性。在这个模型中,生产者负责生成数据,消费者负责处理数据。两者之间通常通过一个共享的缓冲区(如队列)进行通信。
主要组成部分
1. 生产者(Producer):
- 负责生产数据或工作项。
- 当缓冲区未满时,生产者可以将数据放入缓冲区;如果缓冲区已满,则需要等待,直到有空间可用。
2. 消费者(Consumer):
- 负责消费或处理数据。
- 当缓冲区不为空时,消费者可以从缓冲区取出数据进行处理;如果缓冲区为空,消费者需要等待,直到有数据可用。
3. 缓冲区(Buffer):
- 通常是一个有限大小的队列。
- 用于生产者存放生产的数据和消费者从中取出数据。
- 缓冲区的大小决定了可以在生产者和消费者之间暂存的数据量。
重要概念
- 线程同步:
- 由于生产者和消费者通常是并发运行的线程,因此需要通过线程同步机制来确保缓冲区的一致性和数据的完整性。
- 常用的同步机制包括互斥锁(mutexes)、信号量(semaphores)和条件变量(condition variables)。
- 阻塞和唤醒:
- 当生产者尝试向已满的缓冲区添加数据时,它可能会被阻塞(等待),直到消费者取出某些数据。
- 同样,如果消费者尝试从空的缓冲区取数据时,也会被阻塞,直到生产者放入新数据。
应用场景
生产者-消费者模型广泛应用于多线程和并发编程领域,特别是在需要平衡和协调不同速率处理任务的场景中。例如,在网络服务器中处理客户端请求、操作系统中的任务调度、数据库管理系统等。
优点
- 解耦生产者和消费者:
- 生产者不需要等待消费者处理完成即可继续生产,反之亦然。
- 提高并发性能:
- 通过并行化生产者和消费者的工作,可以提高整体的系统性能。
- 灵活的缓冲策略:
- 根据需求调整缓冲区大小,可以平衡和优化生产和消费的速率。
缺点
-复杂性增加:
- 实现正确的线程同步和通信机制增加了编程的复杂性。
- 资源管理:
- 需要妥善处理资源分配和缓冲区管理,避免死锁和资源浪费。
整体而言,生产者-消费者模型是一种有效的设计模式,可以提高程序的并发能力和响应速度,尤其适用于生产和消费速率不一致的场景。
public class ProAndConTest {
public static void main(String[] args) {
Buffer buffer = new Buffer();
Producer producer = new Producer(buffer);
Consumer consumer = new Consumer(buffer);
producer.start();
consumer.start();
}
}
//生产者
class Producer extends Thread{
private Buffer buffer;
public Producer(Buffer buffer){
this.buffer = buffer;
}
@Override
public void run(){
for(int i = 0; i<10; i++){
try {
buffer.add(i);
Thread.sleep((int)Math.random()*100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
//消费者
class Consumer extends Thread{
private Buffer buffer;
public Consumer(Buffer buffer){
this.buffer = buffer;
}
@Override
public void run(){
for(int i =0; i<10; i++){
try {
int val = buffer.poll();
System.out.println(val);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
//数据缓冲区
class Buffer{
Queue queue = new LinkedList<>();
private int size = 5;
//添加数据到缓冲区
public synchronized void add(int val) throws InterruptedException {
//如果生产者产出的数据大于缓冲区的临界值
if(queue.size()>size){
wait();//阻塞生产者,不让其继续生产
}
//否则添加到缓冲区
queue.add(val);
//通知消费者去消费
notify();
}
//在缓冲区取出数据
public synchronized int poll() throws InterruptedException {
//让消费者停止获取
if(queue.size() == 0 ){
wait();
}
Integer val = queue.poll();
notify();
return val;
}
}
5.Volitile关键字的作用有哪些?
`volatile` 是 Java 中的一个关键字,用于确保变量在多个线程中的可见性。当一个字段被声明为 `volatile`,编译器和运行时会注意到这个变量是共享的,因此不会将该变量的操作与其他内存操作一起重排序。这个关键字有以下几个主要作用:
1. 保证变量的可见性:
- 在多线程环境中,一个线程修改了一个共享变量的值,这个新值对其他线程立即可见。如果一个变量被声明为 `volatile`,则表示它可能被多个线程同时访问,但不会执行复合操作(如递增)。
volatile关键字修饰变量还可以对其进行停止变量优化

2. 防止指令重排序:
- 在编译和运行时,为了优化性能,编译器和处理器可能会改变程序中语句的顺序。`volatile` 变量的读写操作不会被重排序,这确保了程序按照代码的顺序执行。
测试预测情况:

给y添加修饰
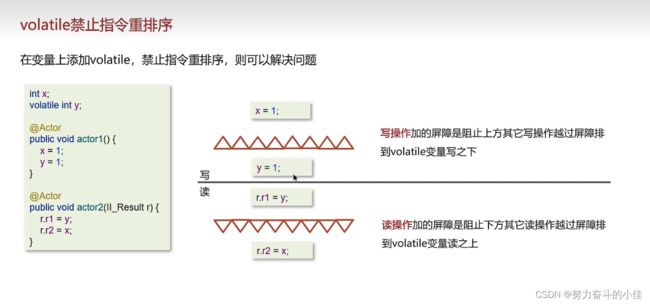
给x添加修饰

使用的小技巧

3. 轻量级的同步机制:
- 相比于 `synchronized` 关键字,`volatile` 是一种更轻量级的同步机制。它不会导致线程阻塞,因此在某些情况下能提供更好的性能。然而,它不解决原子性问题(比如递增操作)。
使用场景
- 状态标志:
- `volatile` 常用于标记线程的运行状态。例如,用一个 `volatile boolean running;` 来控制线程是否继续执行。
- 双重检查锁定(Double-Checked Locking):
- 在使用单例模式时,`volatile` 可以确保对象的唯一性和线程安全。
注意事项
- 不保证原子性:
- `volatile` 不能保证复合操作的原子性。例如,`volatile int i;` 中的 `i++` 操作不是原子的。
- 有限的使用场景:
- 由于 `volatile` 只解决可见性问题,所以它的使用场景有限。对于更复杂的并发控制,可能需要使用 `synchronized` 或 `java.util.concurrent` 包中的工具。
综上所述,`volatile` 关键字是处理多线程编程中变量可见性问题的一种有效工具,但在使用时需要正确理解其保证的可见性和不保证的原子性。
6.atomic包用过么?
Java 中的 `java.util.concurrent.atomic` 包提供了一系列的原子类,它们利用了底层的非阻塞算法来实现线程安全的操作。这些类对于实现并发编程中的无锁数据结构和算法特别有用。使用 `atomic` 包中的类可以在多线程环境中保证操作的原子性,无需使用 `synchronized` 关键字。
主要特性
1. 原子性操作:
- 这些类提供了原子性的操作,例如读取、写入、递增、递减和更新值等。这意味着这些操作在多线程环境中是线程安全的。
2. 非阻塞算法:
- `atomic` 包中的类通常使用高效的非阻塞算法,这些算法基于底层的硬件指令(如CAS,即比较并交换)实现。
3. 性能优势:
- 在高并发环境下,相比于使用锁(如 `synchronized` 或 `ReentrantLock`),原子类通常能提供更好的性能。
常用的原子类
- 基本类型:
- 如 `AtomicInteger`, `AtomicLong`, `AtomicBoolean` 等,用于原子性地操作单个变量。
- 数组类型:
- 如 `AtomicIntegerArray`, `AtomicLongArray`, `AtomicReferenceArray` 等,用于原子性地操作数组元素。
- 引用类型:
- 如 `AtomicReference`, `AtomicStampedReference`, `AtomicMarkableReference` 筀,用于原子性地操作对象引用。
- 复合变量类型:
- 如 `AtomicIntegerFieldUpdater`, `AtomicLongFieldUpdater`, `AtomicReferenceFieldUpdater` 等,用于原子性地更新对象的字段。
使用场景
- 计数器:
- 用于实现线程安全的计数器(如访问计数、完成任务的数量等)。
- 状态标志:
- 管理共享的布尔标志或状态值。
- 高效的数据结构:
- 实现无锁的数据结构,如无锁队列、无锁栈等。
- 复杂同步策略:
- 当需要精细控制复杂的同步策略时,原子类提供了比锁更细粒度的操作。
注意事项
- 原子类不能保证整体代码块的原子性**:
- 原子类仅保证单个变量操作的原子性。如果需要保证代码块的原子性,可能仍需要使用锁。
- 使用时的性能考虑:
- 尽管通常比锁更高效,但在某些情况下(如高竞争环境),原子类的性能可能会受到影响。
总的来说,`java.util.concurrent.atomic` 包提供的原子类是实现高效并发编程的重要工具,特别是在需要高并发和高性能的场景中。
7.在数据库中,我要线程安全的修改一个表里面的某一列数据我改怎么做?
在数据库中线程安全地修改表中的某一列数据,关键在于确保在执行修改操作时,不会有其他线程或进程对同一数据进行干扰。这通常通过事务和锁来实现。具体的做法会根据你使用的数据库系统(如MySQL, PostgreSQL, Oracle等)有所不同,但基本原则是类似的。以下是一些通用步骤:
1. 使用事务(Transaction):
- 事务是一组操作,要么全部成功,要么全部失败。它们提供了一种机制,通过它可以保证数据的完整性。
- 在开始修改操作之前,你需要开始一个新的事务。在大多数数据库中,可以使用`BEGIN TRANSACTION`或类似命令来开始事务。
2. 应用锁(Locking):
- 锁定是用来控制对数据库中数据的并发访问的机制。根据你的需要,可能会使用行级锁或表级锁。
- 行级锁可以锁定数据表中的特定行,而表级锁会锁定整个表。
- 在执行修改操作时,数据库通常会自动应用必要的锁。在某些情况下,你可能需要显式地指定锁类型。
3. 执行修改操作:
- 使用标准的SQL更新语句(如`UPDATE`)来修改数据。
4. 提交或回滚事务:
- 如果所有修改操作都成功,你需要提交事务,这将使修改永久生效。
- 如果在执行过程中遇到任何问题,你应该回滚事务,这将撤销所有未提交的修改。
5. 处理死锁:
- 在高并发环境中,可能会遇到死锁情况。大多数数据库系统能检测死锁,并自动回滚某些事务以解锁。
- 你的代码应该能够正确处理这些回滚情况。
6. 优化性能:
- 如果你的操作影响了大量行,可能需要考虑性能优化,如合理的索引、批量操作或调整隔离级别等。
举个例子,如果你在使用MySQL,你的操作可能看起来像这样:
```sql
START TRANSACTION; -- 开始事务
UPDATE your_table
SET your_column = 'new_value'
WHERE some_condition = true; -- 执行更新操作
COMMIT; -- 提交事务
在此过程中,如果`UPDATE`语句影响的行很多,数据库会自动管理所需的锁。一旦你提交事务,修改就会被保存。如果在事务中发生错误,你应该执行`ROLLBACK`命令来回滚事务。
8.联合索引是什么?什么是最左匹配原则
联合索引
联合索引,又称复合索引,是数据库索引的一种,它基于表中的多个列构建。在一个联合索引中,数据根据索引中的列顺序进行排序和存储。这意味着数据库可以利用这个索引来快速访问那些涉及这些列的查询。
例如,假设有一个联合索引基于两个列:`column1` 和 `column2`。这个索引首先会根据 `column1` 的值对数据进行排序,然后在 `column1` 的每个值内部,进一步根据 `column2` 的值进行排序。
最左匹配原则
最左匹配原则(也称为最左前缀原则)是指在使用联合索引进行查询时,查询条件从索引的最左边的列开始并且不跳过列。数据库在查找数据时会从索引的最左列开始,并按照索引中定义的顺序向右移动,直到遇到范围查询(比如`>`、`<`、`BETWEEN`、`LIKE`)就停止。
这个原则的一个关键点是查询必须使用到联合索引最左边的列。如果查询不涉及最左边的列,索引将不会被有效利用。例如,如果有一个基于 `column1`, `column2`, 和 `column3` 的联合索引,以下情况会发生:
- 查询涉及 `column1` 或 `column1` 和 `column2`,或所有三列,索引会被有效利用。
- 如果查询只涉及 `column2` 或只涉及 `column3`,联合索引将不会被使用,因为它们没有遵循最左匹配原则。
了解和利用最左匹配原则对于优化数据库查询性能非常重要,尤其是在处理大型数据集时。通过确保你的查询与联合索引的最左列对齐,可以大大提高查询效率。
9.写两个线程抢票代码,有没有什么其他方式保证线程安全?
编写两个线程抢票的代码涉及到线程安全问题,这通常意味着确保多个线程在访问和修改共享资源时不会引发竞态条件。在Java中,有多种方法可以实现线程安全,包括使用同步方法、同步块、锁机制、原子变量等。这里将提供一个简单的示例,使用同步方法来实现线程安全的抢票操作,并讨论其他一些线程安全的方法。
使用同步方法的抢票示例
以下是一个简单的Java示例,其中定义了一个Ticket类来表示票务,以及一个TicketBookingThread类,它是一个线程类,用于模拟用户抢票。
public class Ticket {
private int totalTickets;
public Ticket(int totalTickets) {
this.totalTickets = totalTickets;
}
// 同步方法确保线程安全
public synchronized boolean bookTicket(int numberOfTickets) {
if (this.totalTickets >= numberOfTickets) {
this.totalTickets -= numberOfTickets;
return true;
} else {
return false;
}
}
}
public class TicketBookingThread extends Thread {
private Ticket ticket;
private int numberOfTicketsToBook;
public TicketBookingThread(Ticket ticket, int numberOfTicketsToBook) {
this.ticket = ticket;
this.numberOfTicketsToBook = numberOfTicketsToBook;
}
public void run() {
boolean booked = ticket.bookTicket(numberOfTicketsToBook);
if (booked) {
System.out.println(Thread.currentThread().getName() + " booked " + numberOfTicketsToBook + " tickets.");
} else {
System.out.println(Thread.currentThread().getName() + " couldn't book tickets.");
}
}
public static void main(String[] args) {
Ticket ticket = new Ticket(10); // 假设有10张票
TicketBookingThread t1 = new TicketBookingThread(ticket, 5);
TicketBookingThread t2 = new TicketBookingThread(ticket, 6);
t1.start();
t2.start();
}
}
10.说一下如何去实现乐观锁CAS
乐观锁是一种在数据库管理和应用开发中常用的并发控制技术,用于处理多个事务尝试同时修改同一数据记录的情况。与悲观锁不同,乐观锁假设冲突发生的概率较低,因此在数据实际提交更新之前不会锁定资源。乐观锁通常通过“版本号”或“时间戳”机制来实现。
1. 版本号机制
1.数据库的设计:
在需要乐观锁控制的表中添加一个版本号字段(通常是整数类型,如version)。
2.读取数据的时候获取版本号
每次读取数据时,同时获取当前的版本号。
3.更新数据时检查版本号
提交更新请求时,将此版本号与数据库中当前的版本号进行比较。如果版本号一致,则进行更新操作,并将版本号加一;如果版本号不一致(说明数据在读取后和更新前被其他事务修改),则拒绝更新。
4.代码实现
UPDATE table_name
SET column1 = value1, version = version + 1
WHERE primary_key = some_value AND version = current_version;
如果更新影响的行数大于0,则更新成功;否则,更新失败,需要重新读取数据并重试更新操作。
2.时间戳机制
1.数据库的设计
在需要乐观锁控制的表中添加一个时间戳字段(如last_updated)。
2.读取数据的时候获取时间戳
每次读取数据时,同时获取当前的时间戳。
3.更新数据的时候检查时间戳
提交更新请求时,比较此时间戳与数据库中当前的时间戳。如果时间戳一致,则进行更新操作,并更新时间戳为当前时间;如果时间戳不一致,则拒绝更新。
4.代码实现
UPDATE table_name
SET column1 = value1, last_updated = NOW()
WHERE primary_key = some_value AND last_updated = current_timestamp;
类似于版本号机制,如果更新影响的行数大于0,则更新成功;否则,更新失败,需要重新读取数据并重试更新操作。
3.注意事项
- 使用乐观锁时,应确保应用程序逻辑能妥善处理更新失败的情况,例如通过重试机制或向用户显示冲突消息。
- 在选择版本号还是时间戳机制时,应考虑应用场景。版本号简单直观,易于管理;时间戳能提供更多关于记录修改时间的信息,但可能受服务器时间同步问题的影响。
乐观锁适用于读多写少的场景,能有效减少锁的开销,提高系统的并发能力
11.说一下CAS的底层原理
12.你的项目是怎么测试高并发的
13.合并一下三个有序数组
要合并三个有序数组,一种有效的方法是使用归并排序的思想。归并排序中的合并步骤可以被用来合并两个有序数组。基于这个方法,我们可以先合并前两个数组,然后将结果与第三个数组合并,最终得到一个完全合并且有序的数组。
public class MergeSortedArrays {
public static void main(String[] args) {
// 示例数组
int[] arr1 = {1, 4, 7};
int[] arr2 = {2, 5, 8};
int[] arr3 = {3, 6, 9};
// 合并数组
int[] mergedArray = mergeThreeSortedArrays(arr1, arr2, arr3);
// 打印结果
for (int num : mergedArray) {
System.out.print(num + " ");
}
}
// 合并三个有序数组
public static int[] mergeThreeSortedArrays(int[] arr1, int[] arr2, int[] arr3) {
// 首先合并前两个数组
int[] mergedFirstTwo = mergeTwoSortedArrays(arr1, arr2);
// 然后将结果与第三个数组合并
return mergeTwoSortedArrays(mergedFirstTwo, arr3);
}
// 合并两个有序数组
public static int[] mergeTwoSortedArrays(int[] arr1, int[] arr2) {
int[] result = new int[arr1.length + arr2.length];
int i = 0, j = 0, k = 0;
// 遍历两个数组,按顺序选择较小的元素添加到结果数组中
while (i < arr1.length && j < arr2.length) {
if (arr1[i] < arr2[j]) {
result[k++] = arr1[i++];
} else {
result[k++] = arr2[j++];
}
}
// 将剩余的元素添加到结果数组中
while (i < arr1.length) {
result[k++] = arr1[i++];
}
while (j < arr2.length) {
result[k++] = arr2[j++];
}
return result;
}
}
14.geo是怎么存储地理地址的
15.实现一个小顶堆,并且介绍一下他的数据结构是什么
1.特性
小顶堆(Min Heap)是一种特殊的完全二叉树,它满足两个主要特性:
- 结构性:小顶堆是一棵完全二叉树,这意味着除了最后一层外,每一层都被完全填满,并且最后一层的所有节点都尽可能地集中在左侧。
- 堆性质:在小顶堆中,每个节点的值都小于或等于其子节点的值。这意味着根节点的值是堆中最小的,因此也被称为最小堆。
2.数据结构表示
小顶堆通常使用数组来表示,不需要使用节点指针。堆中位置i的元素的父节点和子节点的位置可以通过简单的数学运算得到:
- 父节点的位置:
(i - 1) / 2(i是当前节点的位置,假设数组索引从0开始) - 左子节点的位置:
2 * i + 1 - 右子节点的位置:
2 * i + 2
3.基本操作
小顶堆支持的基本操作包括:
- 插入(Insert):将新元素添加到堆的末尾,然后通过“上浮”调整其位置,以保持堆的性质。
- 删除最小元素(Delete Min):移除并返回堆顶元素(即最小元素),然后将堆的最后一个元素移动到堆顶,通过“下沉”调整其位置,以保持堆的性质。
- 构建小顶堆(Build Min Heap):将一个无序数组转换成一个小顶堆。这通常通过从最后一个非叶子节点开始向前遍历,对每个节点执行“下沉”操作来实现。
- 减小键值(Decrease Key):减小某个节点的值,并通过“上浮”调整其位置,以保持堆的性质。
- 增加键值(Increase Key):增加某个节点的值,并通过“下沉”调整其位置,以保持堆的性质。
16.浮点型的存储方式,以及浮点型怎么表示数的
浮点数的存储方式是根据IEEE 754标准来实现的。这个标准定义了浮点数的存储格式和算术规范,确保了在不同的计算机和平台上对浮点数的处理具有一致性。IEEE 754标准主要定义了两种浮点数格式:单精度浮点数(32位)和双精度浮点数(64位)。
1.浮点数的组成
一个浮点数由三部分组成:
- 符号位(Sign bit):用一个位表示,0代表正数,1代表负数。
- 指数位(Exponent bits):用来表示数的范围。在32位单精度浮点数中,占用8位;在64位双精度浮点数中,占用11位。
- 尾数位(Mantissa or Significand bits):用来表示数的精度。在32位单精度浮点数中,占用23位;在64位双精度浮点数中,占用52位。
2.浮点数的表示
浮点数的表示基于科学记数法,形式为(−1)^8×1.m×2^e−偏移量,其中:
- s 是符号位。
- 1.m 是尾数部分,"1"是隐含的(对于规范化的数),"m"是尾数位直接提供的值。
- e 是指数的实际值,由指数位直接给出的值减去一个偏移量得到。对于32位单精度浮点数,偏移量为127;对于64位双精度浮点数,偏移量为1023。
3.例子
以32位单精度浮点数为例,考虑二进制表示为0 10000001 10100000000000000000000的浮点数:
- 符号位是
0,表示这是一个正数。 - 指数位是
10000001,转换为十进制是129,减去偏移量127,得到指数2。 - 尾数位是
10100000000000000000000,表示为1.101(隐含的1加上尾数部分),转换为十进制是1.625。 - 所以这个浮点数表示的值是1.625×22=6.51.625×22=6.5。
4.特殊值
IEEE 754标准还定义了一些特殊值:
- 正负零:+0 和 -0。
- 无穷大:正无穷大(+∞)和负无穷大(-∞),用于表示溢出的情况。
- NaN(Not a Number):用于表示无效的运算结果。
浮点数的这种表示方法允许在有限的位数内表示非常大或非常小的数,但也带来了精度损失和舍入误差的问题。