使用LORA微调RoBERTa
模型微调是指在一个已经训练好的模型的基础上,针对特定任务或者特定数据集进行再次训练以提高性能的过程。微调可以在使其适应特定任务时产生显着的结果。
RoBERTa(Robustly optimized BERT approach)是由Facebook AI提出的一种基于Transformer架构的预训练语言模型。它是对Google提出的BERT(Bidirectional Encoder Representations from Transformers)模型的改进和优化。
“Low-Rank Adaptation”(低秩自适应)是一种用于模型微调或迁移学习的技术。一般来说我们只是使用LORA来微调大语言模型,但是其实只要是使用了Transformers块的模型,LORA都可以进行微调,本文将介绍如何利用PEFT库,使用LORA提高微调过程的效率。
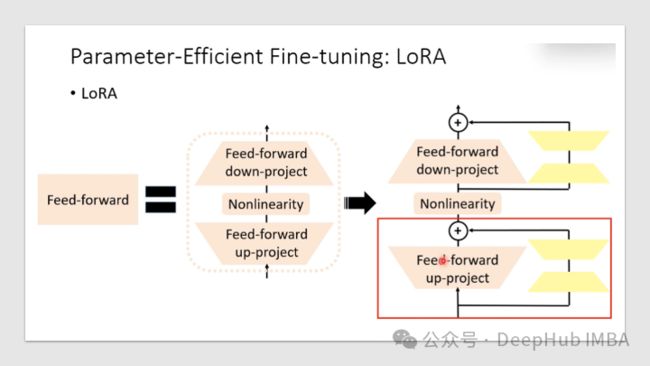
LORA可以大大减少了可训练参数的数量,节省了训练时间、存储和计算成本,并且可以与其他模型自适应技术(如前缀调优)一起使用,以进一步增强模型。
但是,LORA会引入额外的超参数调优层(特定于LORA的秩、alpha等)。并且在某些情况下,性能不如完全微调的模型最优,这个需要根据不同的需求来进行测试。
首先我们安装需要的包:
!pip install transformers datasets evaluate accelerate peft
数据预处理
import torch
from transformers import RobertaModel, RobertaTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
peft_model_name = 'roberta-base-peft'
modified_base = 'roberta-base-modified'
base_model = 'roberta-base'
dataset = load_dataset('ag_news')
tokenizer = RobertaTokenizer.from_pretrained(base_model)
def preprocess(examples):
tokenized = tokenizer(examples['text'], truncation=True, padding=True)
return tokenized
tokenized_dataset = dataset.map(preprocess, batched=True, remove_columns=["text"])
train_dataset=tokenized_dataset['train']
eval_dataset=tokenized_dataset['test'].shard(num_shards=2, index=0)
test_dataset=tokenized_dataset['test'].shard(num_shards=2, index=1)
# Extract the number of classess and their names
num_labels = dataset['train'].features['label'].num_classes
class_names = dataset["train"].features["label"].names
print(f"number of labels: {num_labels}")
print(f"the labels: {class_names}")
# Create an id2label mapping
# We will need this for our classifier.
id2label = {i: label for i, label in enumerate(class_names)}
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt")
训练
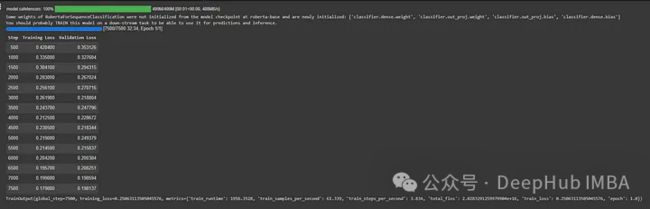
我们训练两个模型,一个使用LORA,另一个使用完整的微调流程。这里可以看到LORA的训练时间和训练参数的数量能减少多少
以下是使用完整微调
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='steps',
learning_rate=5e-5,
num_train_epochs=1,
per_device_train_batch_size=16,
)
然后进行训练:
def get_trainer(model):
return Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
full_finetuning_trainer = get_trainer(
AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label),
)
full_finetuning_trainer.train()
下面看看PEFT的LORA
model = AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label)
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
peft_model = get_peft_model(model, peft_config)
print('PEFT Model')
peft_model.print_trainable_parameters()
peft_lora_finetuning_trainer = get_trainer(peft_model)
peft_lora_finetuning_trainer.train()
peft_lora_finetuning_trainer.evaluate()
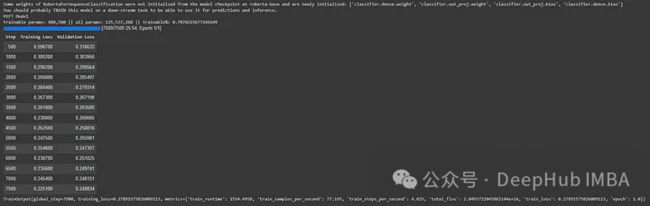
可以看到
模型参数总计:125,537,288,而LORA模型的训练参数为:888,580,我们只需要用LORA训练~0.70%的参数!这会大大减少内存的占用和训练时间。
在训练完成后,我们保存模型:
tokenizer.save_pretrained(modified_base)
peft_model.save_pretrained(peft_model_name)
最后测试我们的模型
from peft import AutoPeftModelForSequenceClassification
from transformers import AutoTokenizer
# LOAD the Saved PEFT model
inference_model = AutoPeftModelForSequenceClassification.from_pretrained(peft_model_name, id2label=id2label)
tokenizer = AutoTokenizer.from_pretrained(modified_base)
def classify(text):
inputs = tokenizer(text, truncation=True, padding=True, return_tensors="pt")
output = inference_model(**inputs)
prediction = output.logits.argmax(dim=-1).item()
print(f'\n Class: {prediction}, Label: {id2label[prediction]}, Text: {text}')
# return id2label[prediction]
classify( "Kederis proclaims innocence Olympic champion Kostas Kederis today left hospital ahead of his date with IOC inquisitors claiming his ...")
classify( "Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again.")

模型评估
我们还需要对PEFT模型的性能与完全微调的模型的性能进行对比,看看这种方式有没有性能的损失
from torch.utils.data import DataLoader
import evaluate
from tqdm import tqdm
metric = evaluate.load('accuracy')
def evaluate_model(inference_model, dataset):
eval_dataloader = DataLoader(dataset.rename_column("label", "labels"), batch_size=8, collate_fn=data_collator)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)
首先是没有进行微调的模型,也就是原始模型
evaluate_model(AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label), test_dataset)
![]()
accuracy: 0.24868421052631579‘
下面是LORA微调模型
evaluate_model(inference_model, test_dataset)

accuracy: 0.9278947368421052
最后是完全微调的模型:
evaluate_model(full_finetuning_trainer.model, test_dataset)

accuracy: 0.9460526315789474
总结
我们使用PEFT对RoBERTa模型进行了微调和评估,可以看到使用LORA进行微调可以大大减少训练的参数和时间,但是在准确性方面还是要比完整的微调要稍稍下降。
本文代码:
https://avoid.overfit.cn/post/26e401b70f9840dab185a6a83aac06b0
作者:Achilles Moraites