过一遍mysql(5)(第八篇:排序和分页(order by,limit);第九篇:分组查询(group by、having))
目录
第八篇:排序和分页(order by,limit)
排序查询(order by)
单字段排序:略
多字段排序:
按别名排序
按函数排序:
where之后进行排序
编辑
limit介绍
获取前n行记录
获取前n行记录
获取最大的一条记录
获取排名第n到m的记录
分页查询
避免踩坑
limit中不能使用表达式
limit后面的两个数字不能为负数
排序分页存在的坑
总结:
第九篇:分组查询(group by、having)
分组查询
聚合函数:
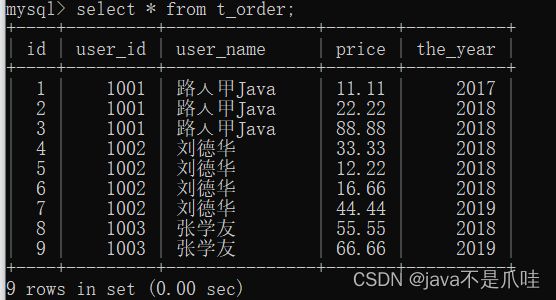
准备数据:
单字段分组
多字段分组
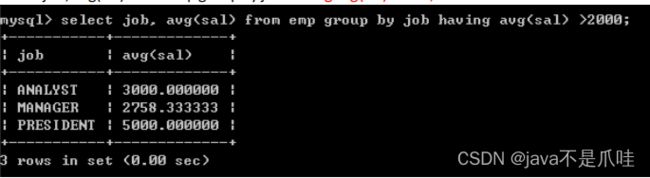
分组前筛选数据:
分组后筛选数据
where和having的区别
分组后排序
where&group by &order by&limit一起协作
mysql分组中的坑:
示例:
总结:
第八篇:排序和分页(order by,limit)
排序查询(order by)
单字段排序:略
多字段排序:
按别名排序
按函数排序:
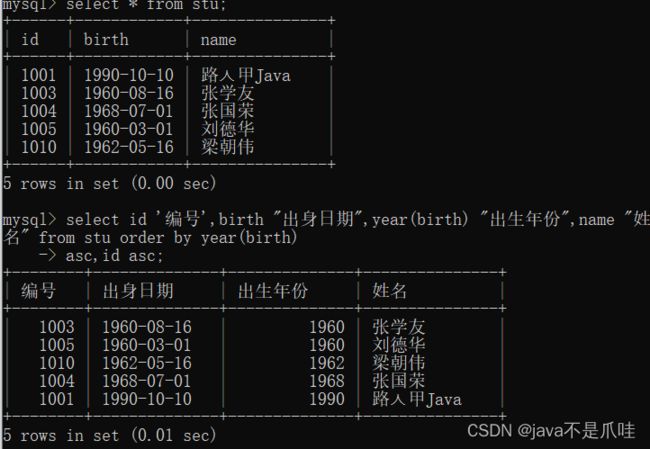
说明:
where之后进行排序

limit介绍
limit用来限制select查询返回的行数,常用于分页等操作
语法:
select 列 from 表 limit 【offset,】count;
说明:
获取前n行记录
select 列 from 表 limit 0,n;
或者
select 列 from 表 limit n;
示例:获取订单的前2条记录,如下:

获取前n行记录
select 列 from 表 limit 0,n;
或者
select 列 from 表 limit n;
获取最大的一条记录
获取排名第n到m的记录
我们需要先跳过n-1条记录,然后取m-n+1条记录,如下:
select 列 from 表 limit n-1,m-n+1;
分页查询
避免踩坑
limit中不能使用表达式
limit后面的两个数字不能为负数
排序分页存在的坑
总结:
- order by ...[asc|desc]用于对查询结果排序,asc:升序,desc:降序,asc|desc可以省略,默认为asc
- limit用来限制查询结果返回的行数,有2个参数(offset,count),offset:表示跳过多少行,count:表示跳过offset行之后取count行
- limit中offset可以省略,默认值为0
- limit中offset和count都必须大于等于0
- limit中offset和count的值不能用表达式
-
分页排序时,排序不要有⼆义性,⼆义性情况下可能会导致分页结果乱序,可以在后⾯追加⼀个主键排序
第九篇:分组查询(group by、having)
分组查询
聚合函数:
常见的聚合函数有哪些?
1、求个数/记录数/项目数等:count()
例如: 统计员工个数?
select count( ) from Company --包括空值
select count(*) from Company --不包括空值
2、求某一列平均数 :avg()
例如:求某个班平均成绩 ?求某个公司员工的平均工资?
select avg(score) from Scores ---平均成绩
select avg(salary) from Company --平均工资
注意:
若某行的score值为null时,计算平均值时会忽略带有null值得那一行。
如果想要把null当做0,那么可以使用IsNull函数把null转换成0,语法如下:
avg(IsNull(score,0)) as ’Average Score‘
3、求总和,总分等:sum() --必须为数字列
例如:求某个班的总成绩?求公司总薪资支出?
select sum(score) from Scores
select sum(salary) from Company
4、求最大值,最高分,最高工资等:max()
例如:求班里最高分,公司员工最高工资?
select max(Score) from Scores
select max(salary) from Company
5、求最小值,最低分,最低工资等:max()
例如:求班里最低分,公司员工最低工资?
select min(Score) from Scores
select min(salary) from Company
SQL中的聚合函数介绍
聚合函数怎么正确的使用?
1、 select 语句的选择列表(子查询或外部查询);
2、having 子句;
3、compute 或 compute by 子句中等;
注意: 在实际应用中,聚合函数常和分组函数group by结合使用,用来查询.where 子句的作用对象一般只是行,用来作为过滤数据的条件。
SQL中的聚合函数介绍
其他聚合函数(aggregate function)
6、 count_big()返回指定组中的项目数量。
与count()函数区别:count_big()返回bigint值,而count()返回的是int值。
数据类型详见:
SQL Server 数据类型的详细介绍及应用实例1
SQL Server 数据类型的详细介绍及应用实例2
SQL Server 数据类型的详细介绍及应用实例3
例如:
select count_big(prd_no) from sales
7、 grouping()产生一个附加的列。
当用cube或rollup运算符添加行时,输出值为1;
当所添加的行不是由cube或rollup产生时,输出值为0.
例如:
select prd_no,sum(qty),grouping(prd_no) from sales group by prd_no with rollup
8、binary_checksum() 返回对表中的行或表达式列表计算的二进制校验值,用于检测表中行的更改。
例如:
select prd_no,binary_checksum(qty) from sales group by prd_no
9、checksum_agg() 返回指定数据的校验值,空值被忽略。
例如:
select prd_no,checksum_agg(binary_checksum(*)) from sales group by prd_no
10、checksum() 返回在表的行上或在表达式列表上计算的校验值,用于生成哈希索引。
11、stdev()返回给定表达式中所有值的统计标准偏差。
例如:
select stdev(prd_no) from sales
12、stdevp() 返回给定表达式中的所有值的填充统计标准偏差。
例如:
select stdevp(prd_no) from sales
13、 var() 返回给定表达式中所有值的统计方差。
例如:
select var(prd_no) from sales
14、 varp()返回给定表达式中所有值的填充的统计方差。
例如:
select varp(prd_no) from sales
————————————————
版权声明:本文为CSDN博主「剑云锋」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40456829/article/details/83657396
- group by
- having
准备数据:
单字段分组
需求:查询每个用户下单数量,输出:用户id、下单数量,如下:
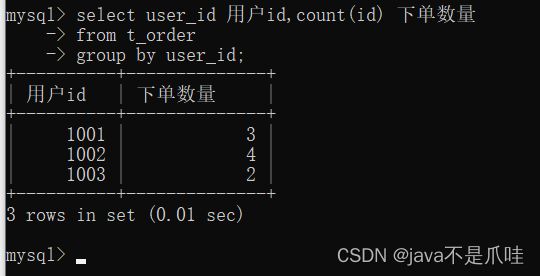
多字段分组
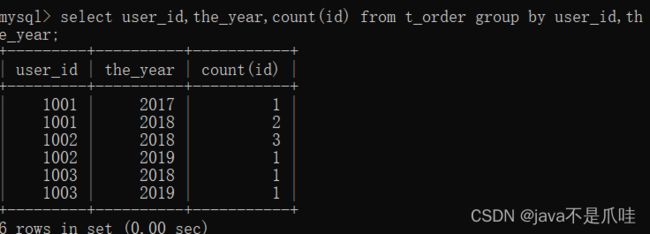
分组前筛选数据:
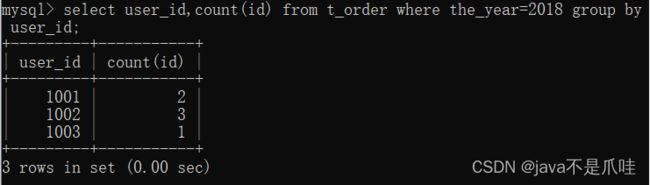
分组后筛选数据
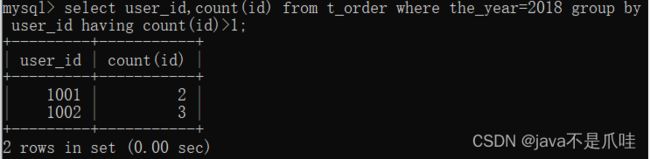

where和having的区别
where是在分组(聚合)前对记录进行筛选,而having是在分组结束后的结果里筛选,最后返回整个sql的查询结果。
分组后排序
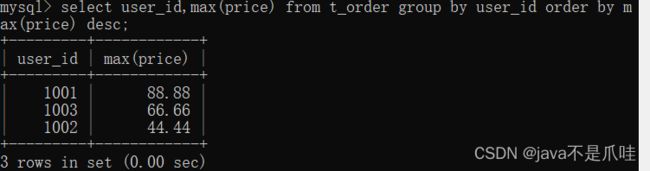
where&group by &order by&limit一起协作
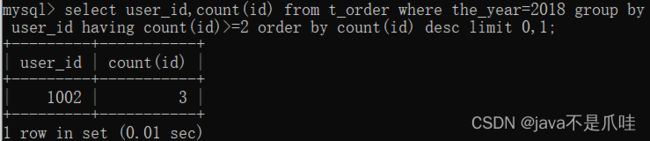
mysql分组中的坑:
示例:

 看⼀下上⾯的数据,第⼀条88.88的年份是2017年,我们再来看⼀下原始数据:
看⼀下上⾯的数据,第⼀条88.88的年份是2017年,我们再来看⼀下原始数据:
对⽐⼀下,userid=1001、price=88.88是第3条数据,即theyear是2018年,但是上⾯的分


总结:
1.在写分组查询的时候,最好按照标准的规范来写,select后⾯出现的列必须在group