这次理解透彻了!用代码从零实现大模型的自注意力、多头注意力。。。
自注意力是 LLM 的一大核心组件。无论是去算法岗面试还是相关应用开发,理解自注意力非常重要。
近日,Ahead of AI 杂志运营者、机器学习和 AI 研究者 Sebastian Raschka 发布了一篇文章,介绍并用代码从头实现了 LLM 中的自注意力、多头注意力、交叉注意力和因果注意力。
这篇文章将介绍 Transformer 架构以及 GPT-4 和 Llama 等大型语言模型(LLM)中使用的自注意力机制。自注意力等相关机制是 LLM 的核心组件,因此如果想要理解 LLM,就需要理解它们。
不仅如此,这篇文章还会介绍如何使用 Python 和 PyTorch 从头开始编写它们的代码。在我看来,从头开始写算法、模型和技术的代码是一种非常棒的学习方式!
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
介绍自注意力
自注意力自在原始 Transformer 论文《Attention Is All You Need》中被提出以来,已经成为许多当前最佳的深度学习模型的一大基石,尤其是在自然语言处理(NLP)领域。由于自注意力已经无处不在,因此理解它是很重要的。
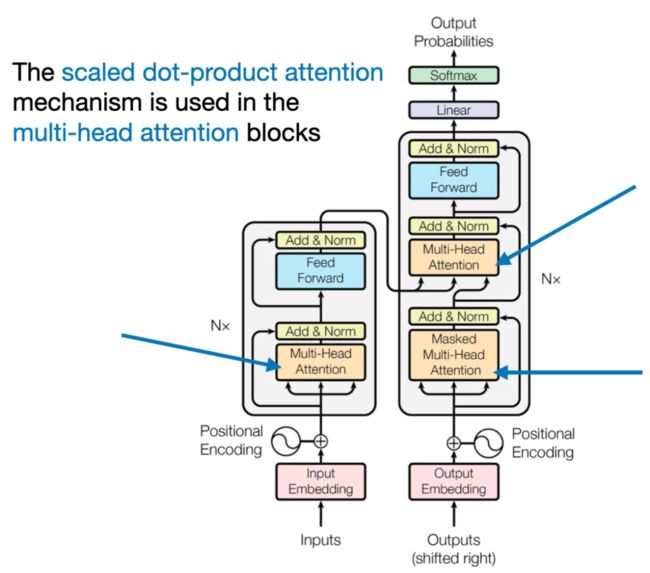
原始 Transformer 架构,来自论文 https://arxiv.org/abs/1706.03762
究其根源,深度学习中的「注意力(attention)」概念可以追溯到一种用于帮助循环神经网络(RNN)处理更长序列或句子的技术。举个例子,假如我们需要将一个句子从一种语言翻译到另一种语言。逐词翻译的操作方式通常不可行,因为这会忽略每种语言独有的复杂语法结构和习惯用语,从而导致出现不准确或无意义的翻译结果。
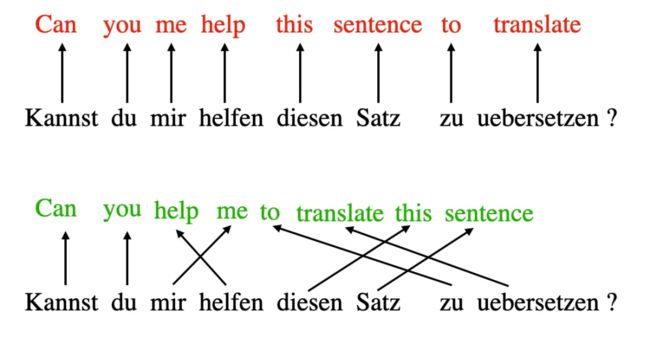
上图是不正确的逐词翻译,下图是正确的翻译结果
为了解决这个问题,研究者提出了注意力机制,让模型在每个时间步骤都能访问所有序列元素。其中的关键在于选择性,也就是确定在特定上下文中哪些词最重要。2017 年时,Transformer 架构引入了一种可以独立使用的自注意力机制,从而完全消除了对 RNN 的需求。
(由于本文的重点是自注意力的技术细节和代码实现,所以只会简单谈谈相关背景。)

来自论文《Attention is All You Need》的插图,展示了 making 这个词对其它词的依赖或关注程度,其中的颜色代表注意力权重的差异。
对于自注意力机制,我们可以这么看:通过纳入与输入上下文有关的信息来增强输入嵌入的信息内容。换句话说,自注意力机制让模型能够权衡输入序列中不同元素的重要性,并动态调整它们对输出的影响。这对语言处理任务来说尤其重要,因为在语言处理任务中,词的含义可能会根据句子或文档中的上下文而改变。
请注意,自注意力有很多变体。人们研究的一个重点是如何提高自注意力的效率。然而,大多数论文依然是实现《Attention Is All You Need》论文中提出的原始的缩放点积注意力机制(scaled-dot product attention mechanism),因为对于大多数训练大规模 Transformer 的公司来说,自注意力很少成为计算瓶颈。
因此,本文重点关注的也是原始的缩放点积注意力机制(称为自注意力),毕竟这是实践中最流行和使用范围最广泛的注意力机制。但是,如果你对其它类型的注意力机制感兴趣,可以参阅其它论文:
-
Efficient Transformers: A Survey:https://arxiv.org/abs/2009.06732
-
A Survey on Efficient Training of Transformers:https://arxiv.org/abs/2302.01107
-
FlashAttention:https://arxiv.org/abs/2205.14135
-
FlashAttention-v2:https://arxiv.org/abs/2307.08691
对输入句子进行嵌入操作
开始之前,我们先考虑以下输入句子:「Life is short, eat dessert first」。我们希望通过自注意力机制来处理它。类似于其它类型的用于处理文本的建模方法(比如使用循环神经网络或卷积神经网络),我们首先需要创建一个句子嵌入(embedding)。
为了简单起见,这里我们的词典 dc 仅包含输入句子中出现的词。在真实世界应用中,我们会考虑训练数据集中的所有词(词典的典型大小在 30k 到 50k 条目之间)。
输入:
sentence = 'Life is short, eat dessert first'
dc = {s:i for i,s
in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc)
输出:
{'Life': 0, 'dessert': 1, 'eat': 2, 'first': 3, 'is': 4, 'short': 5}
接下来,我们使用这个词典为每个词分配一个整数索引:
输入:
import torch
sentence_int = torch.tensor(
[dc[s] for s in sentence.replace(',', '').split()]
)
print(sentence_int)
输出:
tensor([0, 4, 5, 2, 1, 3])
现在,使用输入句子的整数向量表征,我们可以使用一个嵌入层来将输入编码成一个实数向量嵌入。这里,我们将使用一个微型的 3 维嵌入,这样一来每个输入词都可表示成一个 3 维向量。
请注意,嵌入的大小范围通常是从数百到数千维度。举个例子,Llama 2 的嵌入大小为 4096。这里之所以使用 3 维嵌入,是为了方便演示。这让我们可以方便地检视各个向量的细节。
由于这个句子包含 6 个词,因此最后会得到 6×3 维的嵌入:
输入:
vocab_size = 50_000
torch.manual_seed(123)
embed = torch.nn.Embedding(vocab_size, 3)
embedded_sentence = embed(sentence_int).detach()
print(embedded_sentence)
print(embedded_sentence.shape)
输出:
tensor([[ 0.3374, -0.1778, -0.3035],
[ 0.1794, 1.8951, 0.4954],
[ 0.2692, -0.0770, -1.0205],
[-0.2196, -0.3792, 0.7671],
[-0.5880, 0.3486, 0.6603],
[-1.1925, 0.6984, -1.4097]])
torch.Size([6, 3])
定义权重矩阵
现在开始讨论广被使用的自注意力机制,也称为缩放点积注意,这是 Transformer 架构不可或缺的组成部分。
自注意力使用了三个权重矩阵,分别记为 W_q、W_k 和 W_v;它们作为模型参数,会在训练过程中不断调整。这些矩阵的作用是将输入分别投射成序列的查询、键和值分量。
相应的查询、键和值序列可通过权重矩阵 W 和嵌入的输入 x 之间的矩阵乘法来获得:
-
查询序列:对于属于序列 1……T 的 i,有 q⁽ⁱ⁾=x⁽ⁱ⁾W_q
-
键序列:对于属于序列 1……T 的 i,有 k⁽ⁱ⁾=x⁽ⁱ⁾W_k
-
值序列:对于属于序列 1……T 的 i,有 v⁽ⁱ⁾=x⁽ⁱ⁾W_v
-
索引 i 是指输入序列中的 token 索引位置,其长度为 T。
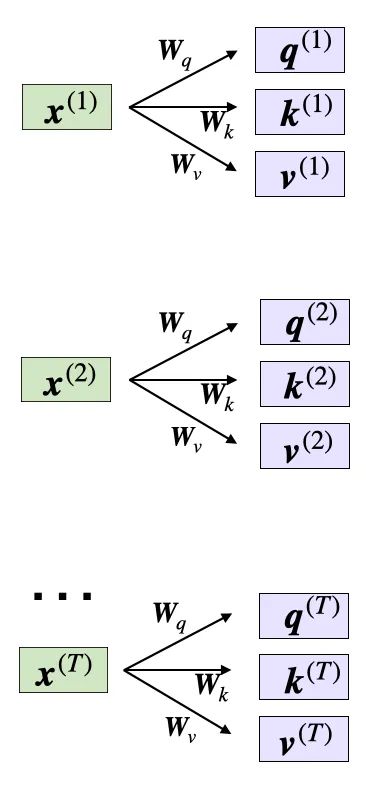
通过输入 x 和权重 W 计算查询、键和值向量
这里,q⁽ⁱ⁾ 和 k⁽ⁱ⁾ 都是维度为 d_k 的向量。投射矩阵 W_q 和 W_k 的形状为 d × d_k,而 W_v 的形状是 d × d_v。
(需要注意,d 表示每个词向量 x 的大小。)
由于我们要计算查询和键向量的点积,因此这两个向量的元素数量必须相同(d_q=d_k)。很多 LLM 也会使用同样大小的值向量,也即 d_q=d_k=d_v。但是,值向量 v⁽ⁱ⁾ 的元素数量可以是任意值,其决定了所得上下文向量的大小。
在接下来的代码中,我们将设定 d_q=d_k=2,而 d_v=4。投射矩阵的初始化如下:
输入:
torch.manual_seed(123)
d = embedded_sentence.shape[1]
d_q, d_k, d_v = 2, 2, 4
W_query = torch.nn.Parameter(torch.rand(d, d_q))
W_key = torch.nn.Parameter(torch.rand(d, d_k))
W_value = torch.nn.Parameter(torch.rand(d, d_v))
(类似于之前提到的词嵌入,实际应用中的维度 d_q、d_k、d_v 都大得多,这里使用小数值是为了方便演示。)
计算非归一化的注意力权重
现在假设我们想为第二个输入元素计算注意力向量 —— 也就是让第二个输入元素作为这里的查询:

对于接下来的章节,我们将重点关注第二个输入 x⁽²⁾。
写成代码就是这样:
输入:
x_2 = embedded_sentence[1]
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2.shape)
print(key_2.shape)
print(value_2.shape)
输出:
torch.Size([2])
torch.Size([2])
torch.Size([4])
然后我们可以推而广之,为所有输入计算剩余的键和值元素,因为下一步计算非归一化注意力权重时会用到它们:
输入:
keys = embedded_sentence @ W_key
values = embedded_sentence @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
输出:
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 4])
现在我们已经拥有了所有必需的键和值,可以继续下一步了,也就是计算非归一化注意力权重 ω,如下图所示:
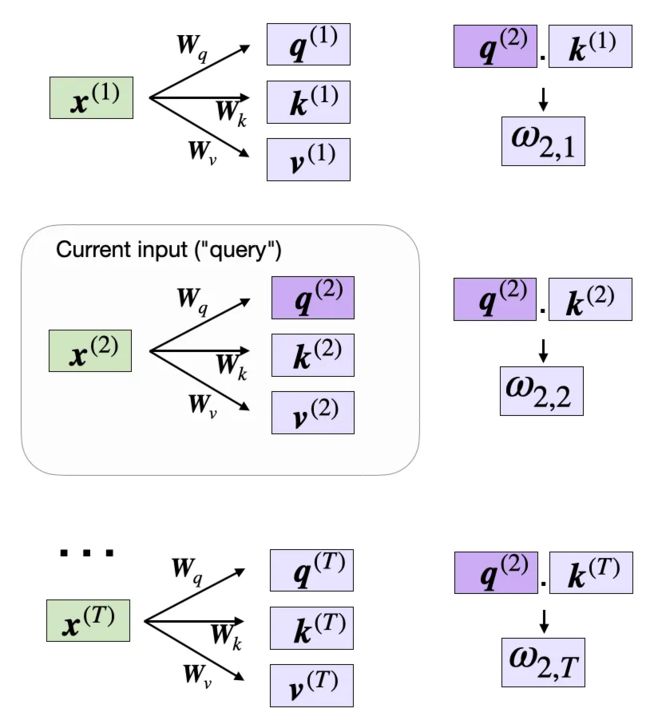
计算非归一化的注意力权重 ω
如上图所示,ω(i,j) 是查询和键序列之间的点积 ω(i,j) = q⁽ⁱ⁾ k⁽ʲ⁾。
举个例子,我们能以如下方式计算查询与第 5 个输入元素(索引位置为 4)之间的非归一化注意力矩阵:
输入:
omega_24 = query_2.dot(keys[4])
print(omega_24)
(注意,ω 是希腊字幕,在代码中的变量名是 omega。)
输出:
tensor(1.2903)
由于我们后面需要这些非归一化注意力权重 ω 来计算实际的注意力权重,因此这里就以上图所示的方式为所有输入 token 计算 ω 值。
输入:
omega_2 = query_2 @ keys.T
print(omega_2)
输出:
tensor([-0.6004, 3.4707, -1.5023, 0.4991, 1.2903, -1.3374])
计算注意力权重
自注意力的下一步是将非归一化的注意力权重 ω 归一化,从而得到归一化注意力权重 α(alpha);这会用到 softmax 函数。此外,在通过 softmax 函数进行归一化之前,还要使用 1/√{d_k} 对 ω 进行缩放,如下所示:
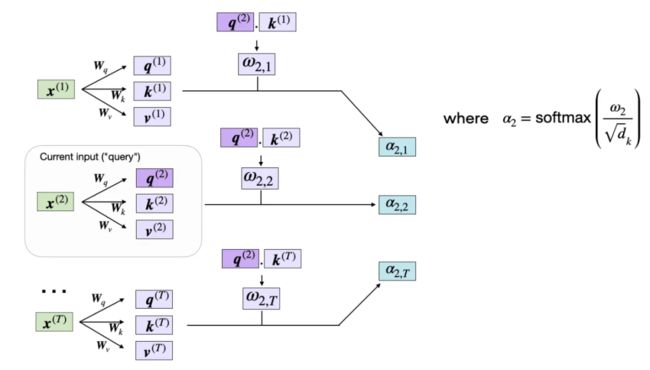
计算归一化注意力权重 α
按 d_k 进行缩放可确保权重向量的欧几里得长度都大致在同等尺度上。这有助于防止注意力权重变得太小或太大 —— 这可能导致数值不稳定或影响模型在训练期间收敛的能力
我们可以这样用代码实现注意力权重的计算:
输入:
import torch.nn.functional as F
attention_weights_2 = F.softmax(omega_2 / d_k**0.5, dim=0)
print(attention_weights_2)
输出:
tensor([0.0386, 0.6870, 0.0204, 0.0840, 0.1470, 0.0229])
最后一步是计算上下文向量 z⁽²⁾,即原始查询输入 x⁽²⁾ 经过注意力加权后的版本,其通过注意力权重将所有其它输入元素作为了上下文:
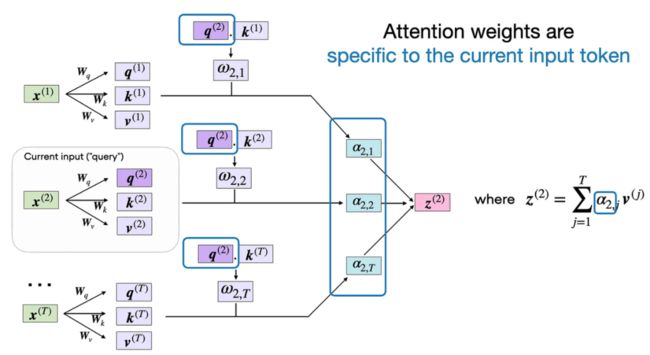
这个注意力权重特定于某一个输入元素,这里选择的是输入元素 x⁽²⁾。
代码是这样:
输入:
context_vector_2 = attention_weights_2 @ values
print(context_vector_2.shape)
print(context_vector_2)
输出:
torch.Size([4])
tensor([0.5313, 1.3607, 0.7891, 1.3110])
请注意,这个输出向量的维度(d_v=4)比输入向量(d=3)多,因为我们之前已经设定了 d_v > d。但是,d_v 的嵌入大小可以任意选择。
自注意力
现在,总结一下之前小节中自注意力机制的代码实现。我们可以将之前的代码总结成一个紧凑的 SelfAttention 类:
输入:
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # unnormalized attention weights
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
遵照 PyTorch 的惯例,上面的 SelfAttention 类会在 __init__ 方法中对自注意力参数进行初始化,然后通过 forward 方法为所有输入计算注意力权重和上下文向量。我们可以这样使用这个类:
输入:
torch.manual_seed(123)
# reduce d_out_v from 4 to 1, because we have 4 heads
d_in, d_out_kq, d_out_v = 3, 2, 4
sa = SelfAttention(d_in, d_out_kq, d_out_v)
print(sa(embedded_sentence))
输出:
tensor([[-0.1564, 0.1028, -0.0763, -0.0764],
[ 0.5313, 1.3607, 0.7891, 1.3110],
[-0.3542, -0.1234, -0.2627, -0.3706],
[ 0.0071, 0.3345, 0.0969, 0.1998],
[ 0.1008, 0.4780, 0.2021, 0.3674],
[-0.5296, -0.2799, -0.4107, -0.6006]], grad_fn=<MmBackward0>)
可以从第二行看到,其值与前一节中 context_vector_2 的值完全一样:tensor ([0.5313, 1.3607, 0.7891, 1.3110])。
多头注意力
如下图所示,可以看到 Transformer 使用了一种名为多头注意力的模块。

来自 Transformer 原始论文的多头注意力模块。
这种多头注意力与我们之前讨论的自注意力机制(缩放点积注意力)有何关联呢?
在缩放点积注意力中,要使用分别表示查询、键和值的三个矩阵来对输入序列执行变换。在讨论多头注意力时,这三个矩阵可被看作是单个注意力头。下图总结了之前讨论和实现过的单注意力头:

总结之前实现的自注意力机制。
顾名思义,多头注意力涉及到多个这样的头,每一个都由查询、键和值矩阵构成。这个概念类似于在卷积神经网络中使用多个核,通过多个输出通道产生特征图。
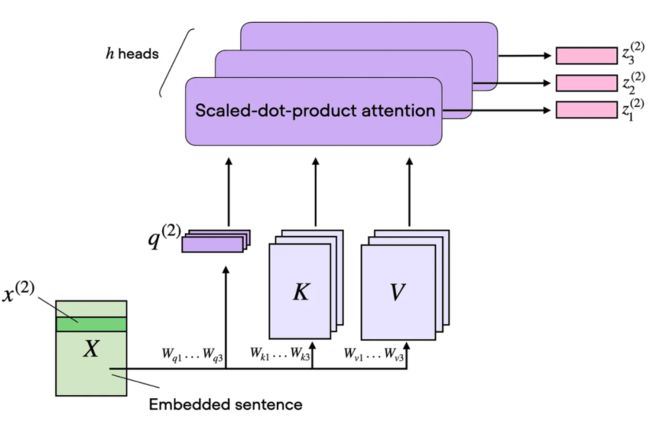
多头注意力:有多个头的自注意力。
为了用代码呈现,我们可以为之前的 SelfAttention 类写一个 MultiHeadAttentionWrapper 类:
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
d_* 参数与 SelfAttention 类中的一样 —— 这里仅有的新输入参数是注意力头的数量:
-
d_in:输入特征向量的维度
-
d_out_kq:查询和键输出的维度
-
d_out_v:值输出的维度
-
num_heads:注意力头的数量
我们使用这些输入参数将 SelfAttention 类初始化 num_heads 次,并且使用一个 PyTorch nn.ModuleList 来存储这些 SelfAttention 实例。
然后,其前向通过过程涉及到将每个 SelfAttention 头(存储在 self.heads 中)独立地用于输入 x。然后,沿最后的维度(dim=-1)将每个头的结果连接起来。下面来看实际操作!
为了说明简单,首先我们假设有输出维度为 1 的单个 SelfAttention 头。
输入:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 1
sa = SelfAttention(d_in, d_out_kq, d_out_v)
print(sa(embedded_sentence))
输出:
tensor([[-0.0185],
[ 0.4003],
[-0.1103],
[ 0.0668],
[ 0.1180],
[-0.1827]], grad_fn=<MmBackward0>)
现在,我们将其扩展到 4 个注意力头:
输入:
torch.manual_seed(123)
block_size = embedded_sentence.shape[1]
mha = MultiHeadAttentionWrapper(
d_in, d_out_kq, d_out_v, num_heads=4
)
context_vecs = mha(embedded_sentence)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
输出:
tensor([[-0.0185, 0.0170, 0.1999, -0.0860],
[ 0.4003, 1.7137, 1.3981, 1.0497],
[-0.1103, -0.1609, 0.0079, -0.2416],
[ 0.0668, 0.3534, 0.2322, 0.1008],
[ 0.1180, 0.6949, 0.3157, 0.2807],
[-0.1827, -0.2060, -0.2393, -0.3167]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([6, 4])
从上面的输出可以看到,单自注意力头的输出就是多头注意力输出的张量的第一列。
请注意这个多头注意力得到的是一个 6×4 维的张量:我们有 6 个输入 token 和 4 个自注意力头,其中每个自注意力头返回一个 1 维输出。之前的自注意力一节也得到了一个 6×4 维的张量。这是因为我们将输出维度设为了 4,而不是 1。既然我们可以就在 SelfAttention 类中调整输出嵌入的大小,那么我们为什么在实践时需要多个注意力头?
增加单自注意力头的输出维度和使用多个注意力头的区别在于模型处理和学习数据的方式。尽管这两种方法都能提升模型表征数据的不同特征或不同方面的能力,但它们的方式却有根本性的差异。
例如,多头注意力中的每个注意力头都可以学习关注输入序列的不同部分,捕获数据中的不同方面或关系。这种表征的多样性是多头注意力成功的关键。
多头注意力的效率也能更高,尤其是使用并行计算时。每个头都可以独立处理,这使得它们非常适合 GPU 或 TPU 等擅长并行处理的现代硬件加速器。
简而言之,使用多个注意力头不仅可以提高模型的能力,还可以增强其学习数据中各种特征和关系的能力。举个例子,7B 的 Llama 2 模型使用了 32 个注意力头。
交叉注意力
在上面编写的代码中,我们设定了 d_q = d_k = 2 和 d_v = 4。也就是说,查询和键序列使用了同样的维度。尽管值矩阵 W_v 的维度往往与查询和键矩阵一样(正如 PyTorch 中的 MultiHeadAttention 类),但值维度可以选取任意数值。
由于维度有时候是很难记的,所以这里我们总结一下之前的内容。如下图所示,其中总结了单个注意力头的各种张量大小。

另一个角度看之前实现的自注意力机制,这里关注的重点是矩阵维度
上图对应于 Transformer 中使用的自注意力机制。对于这种注意力机制,还有一点尚未讨论:交叉注意力。
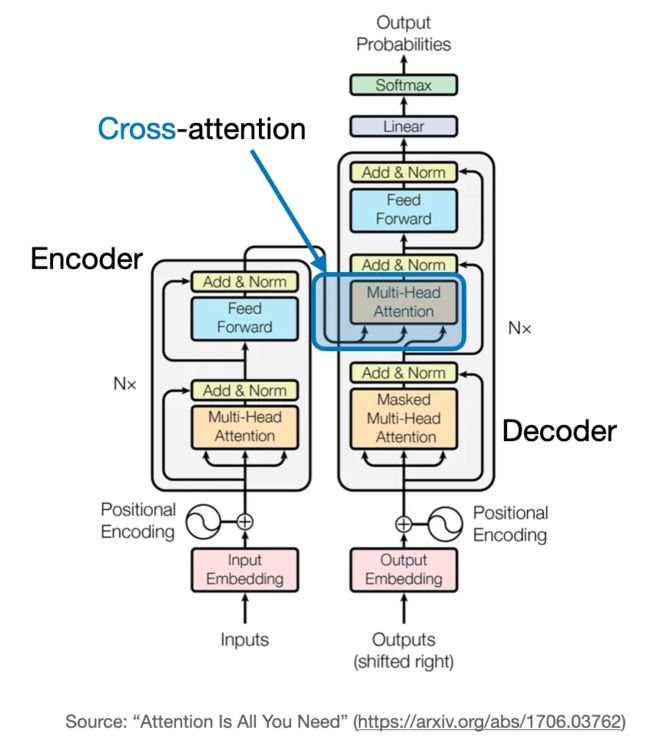
交叉注意力是什么,又与自注意力有何不同?
自注意力处理的是同一个输入序列。交叉注意力则会混合或组合两个不同的输入序列。对于上面的原始 Transformer 架构,也就是左侧由编码器模块返回的序列和右侧由解码器部分处理过的输入序列。
注意,在使用交叉注意力时,两个输入序列 x_1 和 x_2 的元素数量可以不同。但是,它们的嵌入维度必须一样。
下图展示了交叉注意力的概念。如果我们设 x_1 = x_2,则其就等价于自注意力。
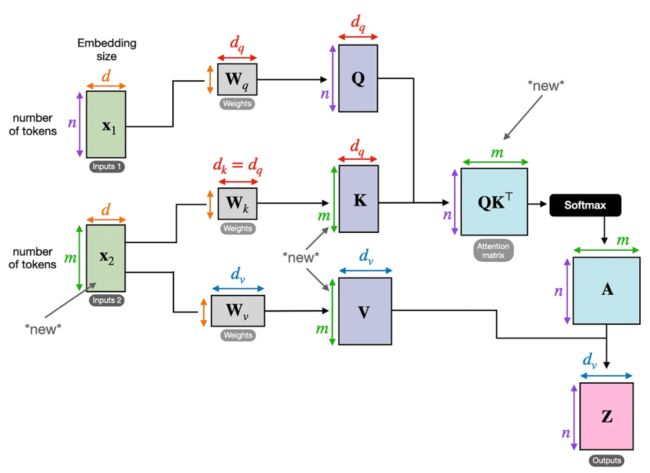
(请注意,查询通常来自解码器,键和值通常来自编码器。)
怎么写它的代码呢?我们可以把之前的 SelfAttention 类的代码拿过来改一下:
输入:
class CrossAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x_1, x_2): # x_2 is new
queries_1 = x_1 @ self.W_query
keys_2 = x_2 @ self.W_key # new
values_2 = x_2 @ self.W_value # new
attn_scores = queries_1 @ keys_2.T # new
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1)
context_vec = attn_weights @ values_2
return context_vec
CrossAttention 类和之前的 SelfAttention 类有如下区别:
-
forward 方法有两个不同输入:x_1 和 x_2。查询来自 x_1,而键和值来自 x_2。这意味着注意力机制在评估两个不同输入之间的互动。
-
注意力分数的计算方式是计算查询(来自 x_1)和键(来自 x_2)的点积。
-
类似于 SelfAttention,每个上下文向量都是值的加权和。然而,在 CrossAttention 中,这些值源自第二个输入(x_2),而权重基于 x_1 和 x_2 之间的交互。
来看看它的实际效果:
输入:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
crossattn = CrossAttention(d_in, d_out_kq, d_out_v)
first_input = embedded_sentence
second_input = torch.rand(8, d_in)
print("First input shape:", first_input.shape)
print("Second input shape:", second_input.shape)
输出:
First input shape: torch.Size([6, 3])
Second input shape: torch.Size([8, 3])
注意,在计算交叉注意力时,第一个输入和第二个输入的 token 数(这里为行数)不必相同。
输入:
context_vectors = crossattn(first_input, second_input)
print(context_vectors)
print("Output shape:", context_vectors.shape)
输出:
tensor([[0.4231, 0.8665, 0.6503, 1.0042],
[0.4874, 0.9718, 0.7359, 1.1353],
[0.4054, 0.8359, 0.6258, 0.9667],
[0.4357, 0.8886, 0.6678, 1.0311],
[0.4429, 0.9006, 0.6775, 1.0460],
[0.3860, 0.8021, 0.5985, 0.9250]], grad_fn=<MmBackward0>)
Output shape: torch.Size([6, 4])
上面我们谈的都是语言 Transformer。对于原始的 Transformer 架构,在执行语言翻译任务时(需要将输入句子转换成输出句子),交叉注意力很有用。其中输入句子可以表示成一个输入序列,翻译结果可以表示成另一个输入序列(这两个句子的词数可以不同)。
另一个使用了交叉注意力的常见模型是 Stable Diffusion。正如提出了 Stable Diffusion 模型的原论文《High-Resolution Image Synthesis with Latent Diffusion Models》中描述的那样,Stable Diffusion 在 U-Net 生成的图像和用于设定条件的文本 prompt 之间使用了交叉注意力。
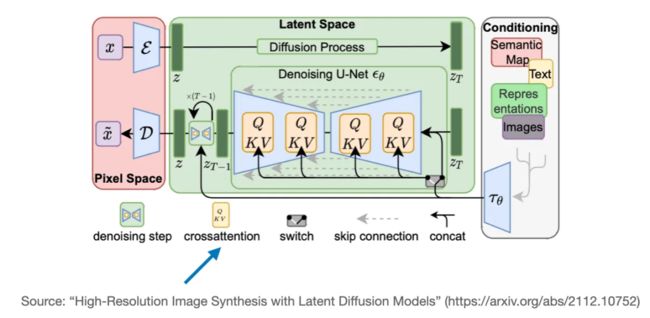
因果自注意力
这一节要做的是把之前讨论的自注意力机制改造成一种因果自注意力机制,尤其是对于用于生成文本的类 GPT(解码器式)LLM。这种因果自注意力机制也常被称为「掩码式自注意力(masked self-attention)」。在原始的 Transformer 架构中,其对应于「掩码多头注意力」模块 —— 简单起见,这一节只会讨论单注意力头,但这一概念也能泛化到多头注意力。

原始 Transformer 架构中的因果自注意力模块
因果自注意力能确保一个序列中某个特定位置的输出仅基于之前位置的已知输出,而不是未来位置的输出。简单来说,它能确保在预测每个新词时只会考虑之前的词。为了在类 GPT 的 LLM 中实现这种机制,对于每个被处理的 token,都要掩盖未来 token,即输入文本中出现在当前 token 之后的 token。
下图展示了将因果掩码用于注意力权重,以隐藏输入中的未来输入 token。

为了说明和实现因果自注意力,需要用到之前一节中未加权的注意力分数和注意力权重。首先,我们先简单回顾一下之前的注意力分数的计算:
输入:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
W_value = nn.Parameter(torch.rand(d_in, d_out_v))
x = embedded_sentence
keys = x @ W_key
queries = x @ W_query
values = x @ W_value
# attn_scores are the "omegas",
# the unnormalized attention weights
attn_scores = queries @ keys.T
print(attn_scores)
print(attn_scores.shape)
输出:
tensor([[ 0.0613, -0.3491, 0.1443, -0.0437, -0.1303, 0.1076],
[-0.6004, 3.4707, -1.5023, 0.4991, 1.2903, -1.3374],
[ 0.2432, -1.3934, 0.5869, -0.1851, -0.5191, 0.4730],
[-0.0794, 0.4487, -0.1807, 0.0518, 0.1677, -0.1197],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -0.2787],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MmBackward0>)
torch.Size([6, 6])
类似于前面的自注意力章节,对于那 6 个输入 token,上面的输出是一个 6×6 张量,其中包含这些成对的非归一化注意力权重(也称为注意力分数)。
然后,我们之前的做法是通过 softmax 函数计算缩放点积注意,如下所示:
输入:
attn_weights = torch.softmax(attn_scores / d_out_kq**0.5, dim=1)
print(attn_weights)
输出:
tensor([[0.1772, 0.1326, 0.1879, 0.1645, 0.1547, 0.1831],
[0.0386, 0.6870, 0.0204, 0.0840, 0.1470, 0.0229],
[0.1965, 0.0618, 0.2506, 0.1452, 0.1146, 0.2312],
[0.1505, 0.2187, 0.1401, 0.1651, 0.1793, 0.1463],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.1231],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)
上面的 6×6 输出就代表了注意力权重,前面的注意力章节也计算了它。
现在,在类似 GPT 的 LLM 中,我们训练模型从左至右一次阅读和生成一个 token(词)。如果我们的训练文本样本是「Life is short eat desert first」,我们有以下设置,其中箭头右侧的词的上下文向量应该只包含其自身和前面的词:
-
“Life” → “is”
-
“Life is” → “short”
-
“Life is short” → “eat”
-
“Life is short eat” → “desert”
-
“Life is short eat desert” → “first”
为了实现上述设置,最简单的方法是在注意力权重矩阵的对角线之上使用一个掩码,从而掩蔽掉所有未来 token,如下图所示。如此一来,在构建上下文向量(在输入上的注意力加权和)时,就不会把「未来的」词包含进来。
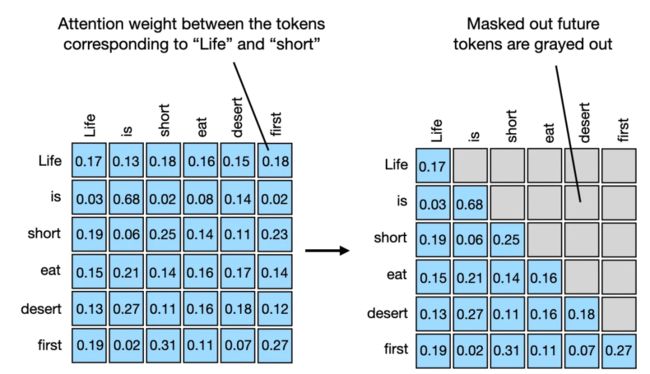
对角线之上的注意力权重应当被遮掩住
写代码时可以使用 PyTorch 的 tril 函数,这个函数最初是设计用来创建 1 和 0 的掩码:
输入:
block_size = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(block_size, block_size))
print(mask_simple)
输出:
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])
接下来,我们可以将注意力权重与这个掩码相乘,从而将对角线之上的所有注意力权重归零:
输入:
masked_simple = attn_weights*mask_simple
print(masked_simple)
输出:
tensor([[0.1772, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0386, 0.6870, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1965, 0.0618, 0.2506, 0.0000, 0.0000, 0.0000],
[0.1505, 0.2187, 0.1401, 0.1651, 0.0000, 0.0000],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<MulBackward0>)
尽管上面确实是一种掩蔽未来词的方法,但也请注意,每一行的注意力权重之和不再是 1 了。为了缓解这一问题,我们可以再次对每行进行归一化,使得它们的和为 1(这是注意力权重的标准惯例):
输入:
row_sums = masked_simple.sum(dim=1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)
输出:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<DivBackward0>)
可以看到,现在每行的注意力权重之和为 1。
相较于不对神经网络的注意力权重执行归一化,进行归一化(Transformer 模型就会这样做)有两大好处。第一,和为 1 的归一化注意力权重就像是一个概率分布。这让我们可以更轻松地根据比例解释模型对输入中各个部分的关注程度。第二,通过将注意力权重之和限定为 1,有助于控制权重和梯度的范围,从而提升训练动态。
无需重新归一化的更高效掩码方法
在上面的因果自注意力代码中,我们首先是计算注意力分数,然后计算注意力权重,再遮掩住对角线之上的注意力权重,最后对注意力权重再次归一化。这个过程可以总结成下图:

之前实现的因果自注意力流程
但其实还有另一种替代方法可以达成同样的结果。这种方法是把注意力分数中对角线之上的值替换成负无穷大,之后再将这些值输入 softmax 函数来计算注意力权重。这个过程可以总结成下图:

一种实现因果自注意力的更高效的替代方法
我们可以使用 PyTorch 编写其代码,首先是掩蔽对角线之上的注意力分数:
输入:
mask = torch.triu(torch.ones(block_size, block_size), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
print(masked)
上面的代码首先是创建一个掩码,其中对角线之下是 0,对角线之上是 1。这里,torch.triu 的作用是保留矩阵的主对角线及之上的元素,将对角线之下的元素归零,因此可以保留上三角的部分。相比之下,torch.tril 则是保留主对角线及之下的元素。
然后,masked_fill 方法则是将通过正掩码值(1)后的对角线及之上的元素替换成 -torch.inf,得到的结果如下:
输出:
tensor([[ 0.0613, -inf, -inf, -inf, -inf, -inf],
[-0.6004, 3.4707, -inf, -inf, -inf, -inf],
[ 0.2432, -1.3934, 0.5869, -inf, -inf, -inf],
[-0.0794, 0.4487, -0.1807, 0.0518, -inf, -inf],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -inf],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MaskedFillBackward0>)
然后,只需和之前一样使用 softmax 函数,就能得到归一化的掩码注意力权重。
输入:
attn_weights = torch.softmax(masked / d_out_kq**0.5, dim=1)
print(attn_weights)
输出:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)
为什么可以这样操作?最后一步使用的 softmax 函数可将输入值转换成一个概率分布。当输入中有 -inf 时,softmax 会把它们视为零概率。这是因为 e^(-inf) 接近于 0,因此这些位置不会影响到输出的概率。
总结
本文通过逐步编程的方式探索了自注意力的内部工作方式。然后以此为基础,我们介绍了多头注意力,这是大型语言 Transformer 的一个基础组件。
然后我们写了交叉注意力代码,这是自注意力的一种变体,在处理两个不同的序列时尤其有效。最后是因果自注意力,这是 GPT 和 Llama 等解码器式 LLM 的一个关键组件,可帮助它们生成连贯一致且符合上下文的序列。
通过从头编写这些复杂机制的代码,希望能帮助你更好地理解 Transformer 和 LLM 中的自注意力机制的内部工作方式。