[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation
论文网址:https://arxiv.org/abs/2205.12465
论文代码:https://github.com/Wayfear/FBNETGEN
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
1. 省流版
1.1. 心得
1.2. 论文总结图
2. 论文逐段精读
2.1. Abstract
2.2. Introduction
2.3. FBNetGen
2.3.1. Overview
2.3.2. Time-series Encoder
2.3.3. Graph Generator
2.3.4. Graph Predictor
2.3.5. End-to-end Training
2.4. Experiments
2.4.1. Experimental Settings
2.4.2. Performance Comparison and Ablation Studies
2.4.3. Interpretability Analysis
2.5. Conclusion
2.6. Appendix A. Background and Related Work
2.6.1. fMRI-based Brain Network Analysis
2.6.2. Graph Neural Networks
2.7. Appendix B. Experimental Settings
2.7.1. Dataset
2.7.2. Metrics
2.7.3. Implementation details
2.7.4. Computation complexity
2.8. Appendix C. The Design of Two Encoders
2.9. Appendix D. Influence of Hyper-parameters
2.10. Appendix E. Influence of Pooling Strategies
2.11. Appendix F. Training Curves of FBNetGen Variants
2.12. Appendix G. Abbreviations of Neural Systems
2.13. Appendix H. Difference Score T of Functional Modules
2.13.1. The Definition of Difference Score T
2.13.2. Difference Score T of Functional Modules on Learnable Graph and Pearson Graph
3. Reference List
1. 省流版
1.1. 心得
(1)⭐“增加窗口大小和嵌入大小并不一定会提高FBNetGen的整体性能,说明FBNetGen的性能是稳定的”。哈哈哈哈哈哈
(2)⭐在2.13.2. 中,感觉皮尔逊和他们的方式都没有完美契合医学。在文中作者也是说别人的其实没太真正契合。真的吗,好奇怪,我怎么看别人的论文夸夸夸都说自己的显著区间和医学一样。
1.2. 论文总结图
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第1张图片](http://img.e-com-net.com/image/info8/9240456f9e2647c69a77ca3a13e6caa7.jpg)
2. 论文逐段精读
2.1. Abstract
①There are noise, unknown of prediction task and incompatible with GNN in traditional brain network(传统的功能性脑网络是啥?和GNN不兼容?不知道下游预测任务?有噪音?)
②They provide feature extraction of ROI, brain network generation and prediction by brain network
2.2. Introduction
①Researchers only know the difference between sexes, but can not explain the reason
②Brain network only based on correlation matrices will lack time series. Moreover, most of the GNN is incompatible with brain network with positive and negative edges(emm...这个不兼容会不会有点夸张了?虽然说确实是个小问题)
③They put forward an end-to-end differentiable pipeline from BOLD signal series to clinical predictions, which includes a) a time-series encoder for reducing the dimension and noise of original data, b) a graph generator from encoded features, c) a GNN predictor based on generated network
④FBNetGen performs good in sex prediction in Adolescent Brain Cognitive Development (ABCD) and PNC
2.3. FBNetGen
2.3.1. Overview
①The overall framework of FBNetGen:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第2张图片](http://img.e-com-net.com/image/info8/7d381ca31fea4d4489bc6008dc32c0b9.jpg)
②The input of FBNetGen is ![]() , where
, where  is the number of samples,
is the number of samples,  denotes the number of ROIs and
denotes the number of ROIs and 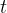 denotes time series.
denotes time series. ![]() is an individual.
is an individual.
③The final output is the prediction label ![]() , where
, where ![]() is the class set
is the class set
④Apply functional brain network ![]()
2.3.2. Time-series Encoder
①As traditional encoding methods, ICA and PCA ignore the time series
②Pearson correlation contains negtive weight in edges
③They apply 1D-CNN and bi-GRU in encoding and note the expression of encoder as:
![]()
2.3.3. Graph Generator
①⭐Different from original Pearson correlation, they design ![]() ,
, ![]() to eliminate negative edges
to eliminate negative edges
②The over lengthy of gradient feedback in deep learning will hinder the performance
③They designed 3 regularizers, group intra loss, group inter loss and sparsity loss.
④Group intra loss: ⭐designed for minimize the differences between the same group. It integrates samples with the same label as a group, namely  denotes the class,
denotes the class, ![]() denotes the samples with the same label
denotes the samples with the same label  . Then mean
. Then mean ![]() and variance
and variance ![]() can be calculated by:
can be calculated by:
![]()
and then the group intra loss is:
![]()
⑤Group inter loss: ⭐designed for maxmize the differences between different groups. The loss can be calculated by:
⑥Sparsity loss: there are some large values calculated by the two losses above, then they proposed sparsity loss to reduce the deviation:
![]()
skewed adj. 歪斜的;曲解的 substantiate vt. 证实;使实体化
2.3.4. Graph Predictor
①The node feature ![]() is the time series
is the time series
②The uppdate function is ![]() and
and ![]()
③The final classification is ![]()
2.3.5. End-to-end Training
①The overall loss is ![]() , where
, where  denotes the supervised cross-entropy loss, and
denotes the supervised cross-entropy loss, and  ,
,  ,
,  are hyper-parameters
are hyper-parameters
2.4. Experiments
2.4.1. Experimental Settings
(1)Philadelphia Neuroimaging Cohort (PNC) dataset
①Samples: 503 subjects with 289 (57.46%) female
②Atlas: 264 ROIs (Power et al., 2011)
(2)Adolescent Brain Cognitive Development Study (ABCD) dataset
①Samples: 7901 with 3961 (50.1%)
②Atlas: HCP 360 ROIs
(3)Metrics
①AUROC
②Accuracy
③The results all take from the mean value of 5 runs
2.4.2. Performance Comparison and Ablation Studies
①They compared their model with four types of models: time-series encoding only, traditional models, another generators and another deep models.
②Table of comparison:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第3张图片](http://img.e-com-net.com/image/info8/55b7631443734d1cb708a92a6bbc271d.jpg)
③Ablation study of each loss:

2.4.3. Interpretability Analysis
①Heatmap of their matrices and matrices of Pearson correlation:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第4张图片](http://img.e-com-net.com/image/info8/c356761fc23a47e7abd9532e5f4cb418.jpg)
②The significance level in their functional matrices is close to biological research
③They adopt t-test to test the significance level and verify the results of thier model matches the biological research more
2.5. Conclusion
They proposed a taskk-aware GNN-based framework, FBNetGen
2.6. Appendix A. Background and Related Work
2.6.1. fMRI-based Brain Network Analysis
①Introduce functional connectivity (FC) in neuroscience and prove its effectiveness and importance
2.6.2. Graph Neural Networks
①Briefly introduce various GNN
②Most of GNNs require distinct graph structures and node features, which are not suitable in brain network
2.7. Appendix B. Experimental Settings
2.7.1. Dataset
(1)PNC
①10 functional modules are divided in 264 ROIs
②Preprocessing: despiking, slice timing correction, motion correction, registration to MNI 2mm standard space, normalization to percent signal change, removal of linear trend, regressing out CSF, WM, and 6 movement parameters, bandpass filtering (0.009{0.08), and spatial smoothing with a 6mm FWHM Gaussian kernel
③Time points: 120
(2)ABCD
①Time points: choose the samples which time points more than 512 and only adopt the first 512 steps (selecting)
②Functional module: 6
2.7.2. Metrics
①Due to the balanced across classes characters of PNC and ABCD, AUROC is a fair metric for them
2.7.3. Implementation details
①The number of conv layers in 1D-CNN: 3
②The number of conv layers in GRU: 4
③Adopting grid search in hyper-parameters
④Parameters in 1D-CNN:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第5张图片](http://img.e-com-net.com/image/info8/3f8889e9af1e46f4a8bfd996b67abc01.jpg)
⑤Hyper-parameters in loss: ![]()
⑥Training set: 70%, validation set: 10%, test set: 20%
⑦Learning rate: 
⑧Weight decay:
⑨Batch size: 16
⑩Epochs: 500
2.7.4. Computation complexity
①Computation complexity of feature encoder: ![]()
②Computation complexity of graph generator: ![]()
③Computation complexity of graph predictor: ![]()
where  denotes the layer of feature encoder, denotes the number of ROIs, denotes the length of time-series
denotes the layer of feature encoder, denotes the number of ROIs, denotes the length of time-series
④The overall cc: ![]()
2.8. Appendix C. The Design of Two Encoders
①The specific process of encoder in 1D-CNN:
![]()
where ![]() , the kernal size in
, the kernal size in ![]() is the window size
is the window size 
②The conv layers in bi-GRU:
![]()
where ![]() represents splitting input sequence
represents splitting input sequence  into
into  segments of length . Then followed by a MLP layer:
segments of length . Then followed by a MLP layer:
![]()
2.9. Appendix D. Influence of Hyper-parameters
①They discuss two hyper-parameters with the greatest influences, the window length and embedding size 
②Figures of hyper parameters varying:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第6张图片](http://img.e-com-net.com/image/info8/6847aaa8d19f424c89103a818fa34aaf.jpg)
2.10. Appendix E. Influence of Pooling Strategies
①Ablation of pooling strategies:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第7张图片](http://img.e-com-net.com/image/info8/e3ce29d5d2e34f71b0fd1fd3fcd6d518.jpg)
2.11. Appendix F. Training Curves of FBNetGen Variants
②Ablation of loss function in training curves:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第8张图片](http://img.e-com-net.com/image/info8/08fba88197614b7c8b12258265ce6dd1.jpg)
2.12. Appendix G. Abbreviations of Neural Systems
①On PNC, SH (Somatomotor Hand), SM (Somatomotor Mouth), Sub (Subcortical), Vis (Visual), Aud (Auditory), CO (Cingulo-opercular), Sal (Salience), DMN (Default mode), FP
(Fronto-parietal), VA (Ventral attention), DA (Dorsal attention), MR (Memory retrieval),
②On ABCD, SM(Somatomotor), DMN (Default mode), VS (Ventral salience), CE (Central
executive), DS (Dorsal salience), Vis (Visual). In ABCD, SM (Somatomotor Mouth), DMN
(Default mode), VS (Ventral salience), CE (Central executive), DS (Dorsal salience), Vis
(Visual).
2.13. Appendix H. Difference Score T of Functional Modules
2.13.1. The Definition of Difference Score T
①"The difference score ![]() of each predefined functional module
of each predefined functional module  is calculated as:
is calculated as:
![]()
where ![]() denotes the set containing all indexes of nodes belonging to the module " (呃呃怎么催生出一种割裂感,这是什么玩意儿,然后这个字符1又是什么为啥没有解释)
denotes the set containing all indexes of nodes belonging to the module " (呃呃怎么催生出一种割裂感,这是什么玩意儿,然后这个字符1又是什么为啥没有解释)
2.13.2. Difference Score T of Functional Modules on Learnable Graph and Pearson Graph
①The significance level of each functional module in PNC, while the bold words are significant modules in neurobiological findings:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第9张图片](http://img.e-com-net.com/image/info8/ec3c3f772b814ba2a77b52d029aed962.jpg)
②The significance level of each functional module in ABCD:
![[论文精读]FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation_第10张图片](http://img.e-com-net.com/image/info8/0e8674f3e6a9422fbb489fd7272474f5.jpg)
3. Reference List
Kan X. et al. (2022) 'FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation', MIDL. doi: https://doi.org/10.48550/arXiv.2205.12465
Power J. et al. (2011) 'Functional Network Organization of the Human Brain', Neuron, 72, pp. 665-678.