SpringBoot整合Elasticsearch详细教程从导入数据开始详细教学
SpringBoot整合Elasticsearch详细教程从导入数据开始详细教学
首先整个工作需要借助Kibana、Logstash工具请自行下载。
一、修改配置
1.先进入elasticsearch的config文件夹中,找到elasticsearch.yml配置文件进行如下修改
#集群名称
17 cluster.name: my-application
#节点名称
23 node.name: node-1
#将来访问elastic的话,都是通过API访问,在这我们要提供一个http主机地址,这里就是本机IP
55 network.host: 自己的IP地址
#默认端口
59 http.port: 9200
#指定集群节点列表
72 cluster.initial_master_nodes: ["node-1"]
末尾增加
#开启跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
#是否能成为master节点
node.master: true
#该节点能存储数据
node.data: true
输入elasticsearch.bat运行程序
2.进入kibana-7.6.2-windows-x86_64的config文件夹配置,修改kibana.yml配置文件
#第二行
server.port: 5601
#第七行
server.host: "192.168.2.171"
#第二十八行
elasticsearch.hosts: ["http://192.168.2.171:9200"]
输入kibana.bat运行
3.进入logstash-7.6.2文件中,在该文件夹下创建logstash.conf文件在文件中添加如下信息
input{
stdin {
}
jdbc {
#自己数据库的连接地址。注意:如果同步的数据库是8.x版本的,除了连接包要换成8.x的,logstash.conf中的驱动名得加上cj,连接数据库的url得加上字符编码、时区等参数
jdbc_connection_string => "jdbc:mysql://localhost:3306/test"
jdbc_user => "root"
jdbc_password => "root"
#驱动类
jdbc_driver_class => "com.mysql.jdbc.Driver"
codec => plain { charset => "UTF-8"}
#主键
tracking_column => "id"
#是否记录上次执行结果
record_last_run => "true"
#是否需要记录某个column 的值
use_column_value => "true"
#代表最后一次数据记录id的值存放的位置,必填不然启动报错
last_run_metadata_path => "D:\logstash-7.6.2\last_id.txt"
#是否清除 last_run_metadata_path 的记录
#如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => "false"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "100000"
#进行同步数据时,执行的SQL
statement => "select * from mall_order where id > :sql_last_value"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
#"*/2 * * * * *" 表示每两秒同步一次
schedule => "*/2 * * * * *"
#当前jdbc的类型,自定义,可以看做是当前jdbc的名字
type => "test"
}
}
filter{
}
output{
elasticsearch {
#自己的ip
hosts => "127.0.0.1:9200"
#索引名字ES中的概念
index => "test"
#文档类型
document_type => "test"
#文档id,唯一,避免数据重复
document_id => "%{id}"
}
stdout {
#以json格式查看数据同步情况,生产环节关闭,提升效率
codec => json_lines
}
}
因为配置同步数据时要用到数据库驱动,所以需要将数据库连接包放到D:\logstash-7.6.2\logstash-core\lib\jars文件夹下
进入D:\logstash-7.6.2\config文件夹,修改pipelines.yml文件,将9-15的注释打开

进入D:\logstash-7.6.2\bin文件夹,并通过dos打开该文件夹,在dos中通过以下指令执行数据同步
logstash.bat -f D:\logstash-7.6.2\logstash.conf
有时会报错错误如下:
[ERROR] 2024-02-01 21:10:38.307 [main] Logstash - java.lang.IllegalStateException: Logstash stopped processing because of an error: (EACCES) Permission denied - NUL
请在D:\logstash-7.6.2\config\jvm.options中添加以下JVM配置信息
-Djdk.io.File.enableADS=true
4、通过kibana查询数据就能看到数据已经同步到Kibana中
二、开始整合
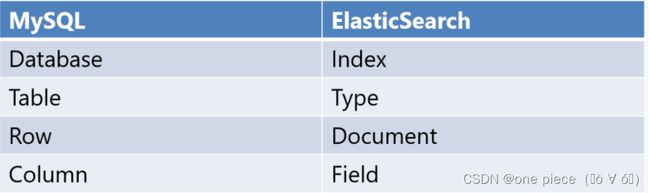
先见一下数据库和ES中的对应关系
1.导入依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
2.3.7.RELEASE
2.编写配置文件
spring:
elasticsearch:
rest:
uris: 192.168.16.56:9200
3.编写实体类
FieldType类型
| 类型 | 解释 |
|---|---|
| FieldType.Text | 当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合(termsAggregation除外)。 |
| FieldType.Keyword | keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。 |
| FieldType.Integer | 整数类型 |
@Data
//导入kinaba中的索引名
@Document(indexName = "test")
@Accessors(chain = true)
public class Test {
// 标识为数据库主键字段
@Id
// Elasticsearch 索引字段,名称为 "id",类型为 Keyword 类型
@Field(name = "id" , type = FieldType.Keyword)
private Integer id;
// Elasticsearch 索引字段,类型为 Text 类型,分析器设置为 "ik_max_word",搜索分析器设置为 "ik_smart" 、使用到了IK分词器,不需要则不写
// 用于存储类别名称
@Field(type = FieldType.Text , analyzer = "ik_max_word" , searchAnalyzer = "ik_smart")
private String name;
}
4.编写映射类
/**
* @Author: one piece
* @Description:
* @Date: 2024/1/17 10:33
*/
@Repository
//参数为实体类和主键类型
public interface TestMapper extends ElasticsearchRepository {
}
在测试类中编写测试代码:基础CRUD
| API | 解释 |
|---|---|
| findAll() | 查询所有 |
| findAll(pageable) | 分页查询 |
| findById | 以id查询,此id指的是elasticsearch数据库中的id,也就是数据的序号,不是数据的id |
| save(obj) | 插入数据 |
| deleteById(id) | 以id删除,此id为文档的id |
自定义查询
ElasticsearchRepository接口提供给我们的方法比较少,一般情况下很难满足我们的需求,但同时ElasticsearchRepository也为我们提供了自定义接口的方法,但是自定义的方法必须满足elasticsearch相关规范,如下表所示:
| 关键字 | 使用示例 | 等同于的ES查询 |
|---|---|---|
| And | findByNameAndPrice | {“bool” : {“must” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}} |
| Or | findByNameOrPrice | {“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}} |
| Is | findByName | {“bool” : {“must” : {“field” : {“name” : “?”}}}} |
| Not | findByNameNot | {“bool” : {“must_not” : {“field” : {“name” : “?”}}}} |
| Between | findByPriceBetween | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| LessThanEqual | findByPriceLessThan | {“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| GreaterThanEqual | findByPriceGreaterThan | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}} |
| Before | findByPriceBefore | {“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| After | findByPriceAfter | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}} |
| Like | findByNameLike | {“bool” : {“must” : {“field” : {“name” : {“query” : “? *”,”analyze_wildcard” : true}}}}} |
| StartingWith | findByNameStartingWith | {“bool” : {“must” : {“field” : {“name” : {“query” : “? *”,”analyze_wildcard” : true}}}}} |
| EndingWith | findByNameEndingWith | {“bool” : {“must” : {“field” : {“name” : {“query” : “*?”,”analyze_wildcard” : true}}}}} |
| Contains/Containing | findByNameContaining | {“bool” : {“must” : {“field” : {“name” : {“query” : “?”,”analyze_wildcard” : true}}}}} |
| In | findByNameIn(Collectionnames) | {“bool” : {“must” : {“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“name” : “?”}} ]}}}} |
| NotIn | findByNameNotIn(Collectionnames) | {“bool” : {“must_not” : {“bool” : {“should” : {“field” : {“name” : “?”}}}}}} |
| True | findByAvailableTrue | {“bool” : {“must” : {“field” : {“available” : true}}}} |
| False | findByAvailableFalse | {“bool” : {“must” : {“field” : {“available” : false}}}} |
| OrderBy | findByAvailableTrueOrderByNameDesc | {“sort” : [{ “name” : {“order” : “desc”} }],”bool” : {“must” : {“field” : {“available” : true}}}} |
自行在测试类注入Mapper编写测试及实现相关业务逻辑
IK分词器的使用只需要把文件放入ES文件的plugins文件夹中重启即可、不做详细教程重启时看到如下图则表示安装成功、注意版本必须和es匹配
![]()
如果对大家有帮助的话、请麻烦点点赞和关注哦!!!