Hadoop-MapReduce-Yarn集群搭建
搭建的部署节点图如下:

hdfs和yarn是两个不同概念,两者搭建不会冲突。注意一点是DataNode和NodeManager必须要部署在同一台机器,它们的比例是1比1关系的。否则DataNode只能存储,不能做相应的计算处理。
通过官网搭建:hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html
主要涉及到两个配置文件: mapred-site.xml 、yarn-site.xml
一 、MapReduce on Yarn单节点搭建
修改hadoop目录下的etc/hadoop/mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
修改etc/hadoop/yarn-site.xml文件:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
yarn里面配置nodemanager的一个服务叫做mapreduce_shuffle,shuffle又叫”洗牌“,就像你打牌,把相同花色的牌放在一块。而在mapReduce中,reduce按分区号拉取map处理好的记录,相当于洗牌这一操作,把相同分区的放在一个reduce里。shuffle就是mapReduce中map到reduce之间集成的东西。为什么要在nodemanager配置mapReduce的shuffle呢,主要是要让nodemanager来协调shuffle从map拉取数据到reduce之间的一个过程。
上面配置好了之后,就可以直接使用下面命令启动yarn(单点的)
$ sbin/start-yarn.sh
使用下面命令停止yarn
$ sbin/stop-yarn.sh
这里配置的是单节点的yarn,并不是集群模式,不是HA高可用的,我们下面来配置HA模式,当然HA模式的配置要依赖上面两个配置文件的内容。
二、搭建高可用的yarn
yarn HA搭建官网地址:https://hadoop.apache.org/docs/r2.6.5/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
下面是yarn HA模式的架构图:
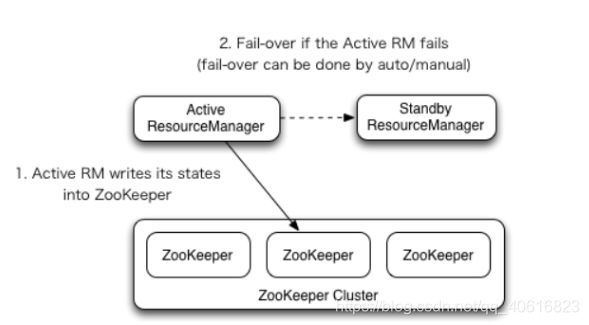
上图出现了2个ResourceManager,也是主备模式。可能你有个疑问,为什么yarn的ha不像hdfs中的HA模式,使用个新增角色ZKFC来协调主备切换呢?
其实在hadoop2.x中,yarn并不是像hdfs的ha一样新增角色来检测切换主备节点,而是直接在RM进程中增加了HA的模块。不过这个yarn的ha模块默认是关闭的,需要手动在配置文件开启。
yarn这样做有个好处,就是RM的状态很明确,要么就是活着,要么就是宕机,不会像hdfs中的一样,可能会存在一个中间态(当ZKFC宕机,而NN存活,此时要为这个NN做降级操作) 。
1、在配置文件配置yarn HA
在node1中,cd到$HADOOP_HOME/etc/hadoop目录下
[root@node1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@node1 hadoop]# vim mapred-site.xml
然后修改mapred-site.xml加入配置:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
然后修改yarn-site.xml
[root@node1 hadoop]# vim yarn-site.xml
加入下面的配置
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarncluster1value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node3value>
property>
yarn.resourcemanager.ha.enabled: 开启yarn的HA模式,默认是false
yarn.resourcemanager.zk-address : yarn的RM连接ZK的地址
yarn.resourcemanager.cluster-id: yarn的集群id,值可以自定义。因为ZK集群是可以被多个集群复用的,那么不同的集群在使用zk做分布式锁控制时,实际上会根据这个配置项里的值在zk生成一个目录,这样相同集群的机器就在这个目录上争抢创建锁,不会影响到其他的集群。
yarn.resourcemanager.ha.rm-ids: yarn中RM的主机逻辑名
yarn.resourcemanager.hostname.rm2 : yarn中RM主机逻辑名对应的具体物理主机配置。
至此yarn的HA就配置完成了。
分发上面的配置文件
[root@node1 hadoop]# scp mapred-site.xml yarn-site.xml node2:`pwd`
mapred-site.xml 100% 863 401.2KB/s 00:00
yarn-site.xml 100% 1416 453.9KB/s 00:00
[root@node1 hadoop]# scp mapred-site.xml yarn-site.xml node3:`pwd`
mapred-site.xml 100% 863 588.9KB/s 00:00
yarn-site.xml 100% 1416 1.4MB/s 00:00
注意yarn中的nodeManager实际上就在etc/hadoop目录的slaves文件下,和datanode一样,不用做修改。
[root@node1 hadoop]# vi slaves
node2
node3
2、启动yarn
[root@node1 hadoop]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/bigdata/hadoop-2.6.5/logs/yarn-root-resourcemanager-node1.out
node3: starting nodemanager, logging to /opt/bigdata/hadoop-2.6.5/logs/yarn-root-nodemanager-node3.out
node2: starting nodemanager, logging to /opt/bigdata/hadoop-2.6.5/logs/yarn-root-nodemanager-node2.out
实际上这个命令可以很好的为我们正确的在对应的机器上启动nodeManager,但是我们并没有正确的启动RM,你可以看到使用这条命令启动的RM是在node1上的,确切来讲,node1上也没有启动RM,因为node1启动RM的时候,会去查yarn-site.xml文件,发现RM并没有配置在node1这条机器上,故此会将启动的RM进程杀死,这条命令只是为我们正确的启动了NodeManager。
我们必须要使用手动的方式在node2、node3启动ResourceManager
[root@node2 ~]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/bigdata/hadoop-2.6.5/logs/yarn-root-resourcemanager-node2.out
启动了之后,可以在node1中使用zk观察到多了一个目录yarn-leader-election
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha]
我们进入到yarn-leader-election中,查看
[zk: localhost:2181(CONNECTED) 2] ls /yarn-leader-election
[yarncluster1]
发现就是我们在配置文件中yarn.resourcemanager.cluster-id指定的cluster-id。
[zk: localhost:2181(CONNECTED) 7] get /yarn-leader-election/yarncluster1/ActiveStandbyElectorLock
yarncluster1rm2
cZxid = 0xd00000011
ctime = Sat May 23 11:20:03 CST 2020
mZxid = 0xd00000011
mtime = Sat May 23 11:20:03 CST 2020
pZxid = 0xd00000011
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x2000038b7af0001
dataLength = 19
numChildren = 0
通过查看当前yarn集群哪个节点抢到了锁,发现yarncluster1rm2抢到了锁,其中rm2对应的物理节点是node3机器上的RM,故此node3的RM为master节点,node2中的是slaver
可以通过访问node2:8088 和node3:8088 更直观的看到RM运行状态及信息
当我们访问node2:8088 提示:
This is standby RM. Redirecting to the current active RM: http://node3:8088/
当我们访问node3:8088

就可以进入上面的图形界面监控了。注意,当我们点击About就可以看到这个RM节点的详细信息:

在这个界面的链接上,我们改下node2对应的主机地址,就可以看到node2节点的RM信息:

我们还可以点击Nodes,查看RM所管辖的NodeManager节点状态

以上NM都是使用的默认配置,以后需要做修改。
3、MapReduce WordCount实战
首先生成一个文件,里面行格式为hello hadoop $i
[root@node1 ~]# for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt;done
然后在hdfs中生成一个目录
[root@node1 ~]# hdfs dfs -mkdir -p /data/wc/input
然后上传这个data.txt
[root@node1 ~]# hdfs dfs -D dfs.blocksize=1048576 -put data.txt /data/wc/input
此时观测到hdfs中的集群是否存在这个文件
然后cd到下面的目录
[root@node1 mapreduce]# cd
/opt/bigdata/hadoop-2.6.5/share/hadoop/mapreduce
mapReduce的jar包都在这里。我们看下这个目录的官方提供的mapreduce的案例jar包大小
[root@node1 mapreduce]# ll -h hadoop-mapreduce-examples-2.6.5.jar
-rw-rw-r-- 1 god haizhang 286K Oct 3 2016 hadoop-mapreduce-examples-2.6.5.jar
发现总共大小是286KB,这里面肯定是个分布式程序,比我们期望的大小是不是小很多? 这是因为这个案例依赖的很多第三方jar包并不囊括在里面,因为它们已经在hadoop上的每个节点的这个目录下,都已经部署到这些需要依赖的第三方jar包了。故此这个案例的jar包只包含了计算业务逻辑(最终移动的是计算而不是数据,计算jar包小,才移动的快),当然可以很小。如果你还要将第三方jar包一起打包上传,那肯定会很大。
如何在hadoop启动上面官方提供的mapreduce计算程序呢?
可以使用hadoop jar命令,我们看下它的使用格式
[root@node1 mapreduce]# hadoop jar
RunJar jarFile [mainClass] args...
其中mainClass是jarFile里面主程序类,作为一个入口。而args则是传递给主程序类的参数,最常见的就是mapreduce输入(map读取数据文件)路径,输出(reduce输出的文件)路径。注意输出路径一定要是一个hdfs中没有的目录,否则命令启动将报错(为了数据安全,以免reduce输出结果覆盖已有的结果导致其他mapReduce程序报错)。
我们以官方提供的hadoop-mapreduce-examples-2.6.5.jar 中的wordcount应用案例,做一个单词统计的程序运行,来测试mapReduce的工作流程.
键入下面的命令启动mapReduce来运行wordcount计算程序
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output
注意,这里以/data/wc/input作为wordcount程序读取数据的路径,因为/data/wc/input是个目录,将会读取这个目录下的所有一级文件(不会读取这个目录的子目录里的文件)。
而/data/wc/output则为wordcount程序输出结果的目录,需要在hdfs中不存在!
执行命令后,可以看到任务的进展(Progress)以及状态(State)

任务执行完成后:
可以看到运行时的状态,包括:
- 运行的任务ID
- 启动这次计算任务的用户(User = root)
- 行计算程序的名称(Name=wordcount)
- 计算程序的类型(ApplicationType=MAPREDUCE ,未来也可能是Spark等)
- 默认的任务队列Queue
- 任务的启动时间(StarTime)
- 任务的终止时间(FinishTime)
- 任务状态(State)
- 任务最终的执行状态(FinalStatus=SUCCEEDED)

除此之外,命令行也为我们提供了这次任务运行的结果:
- 查看任务报告
[root@node2 bin]# yarn application -status application_1593950330559_0001
Application Report :
Application-Id : application_1593950330559_0001
Application-Name : mywordcount
Application-Type : MAPREDUCE
User : root
Queue : default
Start-Time : 1593951525053
Finish-Time : 1593951633293
Progress : 100%
State : FINISHED
Final-State : SUCCEEDED
Tracking-URL : http://node3:19888/jobhistory/job/job_1593950330559_0001
RPC Port : 38515
AM Host : node3
Aggregate Resource Allocation : 284829 MB-seconds, 161 vcore-seconds
Diagnostics :
查看mapreduce log日志
20/05/23 12:06:24 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
20/05/23 12:06:25 INFO input.FileInputFormat: Total input paths to process : 1
20/05/23 12:06:26 INFO mapreduce.JobSubmitter: number of splits:2
20/05/23 12:06:26 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1590204003504_0001
#yarn客户端向yarn集群提交了个计算任务,任务id为application_1590204003504_0001
20/05/23 12:06:27 INFO impl.YarnClientImpl: Submitted application application_1590204003504_0001
#可以根据http://node3:8088/proxy/application_1590204003504_0001/ 追溯这次任务执行流程
20/05/23 12:06:27 INFO mapreduce.Job: The url to track the job:
http://node3:8088/proxy/application_1590204003504_0001/
20/05/23 12:06:27 INFO mapreduce.Job: Running job: job_1590204003504_0001
20/05/23 12:06:44 INFO mapreduce.Job: Job job_1590204003504_0001 running in uber mode : false
# 这里是map在运行时和reduce运行时的进度,发现它们时串行执行的
20/05/23 12:06:44 INFO mapreduce.Job: map 0% reduce 0%
20/05/23 12:07:00 INFO mapreduce.Job: map 50% reduce 0%
20/05/23 12:07:04 INFO mapreduce.Job: map 100% reduce 0%
20/05/23 12:07:16 INFO mapreduce.Job: map 100% reduce 100%
#打印出了这次job任务的执行状态,成功执行。
20/05/23 12:07:16 INFO mapreduce.Job: Job job_1590204003504_0001 completed successfully
20/05/23 12:07:16 INFO mapreduce.Job: Counters: 49
#文件系统的使用情况
File System Counters
FILE: Number of bytes read=1188951
FILE: Number of bytes written=2707028
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1893199
HDFS: Number of bytes written=788922
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
# 任务运行情况
Job Counters
#使用了2个map程序运行计算分组
Launched map tasks=2
#使用了1个reduce进行分组数据统计
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=30383
Total time spent by all reduces in occupied slots (ms)=13508
Total time spent by all map tasks (ms)=30383
Total time spent by all reduce tasks (ms)=13508
Total vcore-milliseconds taken by all map tasks=30383
Total vcore-milliseconds taken by all reduce tasks=13508
Total megabyte-milliseconds taken by all map tasks=31112192
Total megabyte-milliseconds taken by all reduce tasks=13832192
# mapReduce框架的一些数据统计
Map-Reduce Framework
#map读取的记录条数
Map input records=100000
#map输出的记录条数
Map output records=300000
Map output bytes=3088895
Map output materialized bytes=1188957
Input split bytes=208
Combine input records=300000
Combine output records=100004
Reduce input groups=100002
Reduce shuffle bytes=1188957
Reduce input records=100004
Reduce output records=100002
Spilled Records=200008
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=2107
CPU time spent (ms)=6220
Physical memory (bytes) snapshot=698986496
Virtual memory (bytes) snapshot=6448164864
Total committed heap usage (bytes)=472907776
#mapReduce 拉取执行任务过程中的的异常信息
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1892991
File Output Format Counters
Bytes Written=788922
我们查看下mapReduce生成的结果文件
[root@node1 ~]# hdfs dfs -ls /data/wc/output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2020-05-23 12:07 /data/wc/output/_SUCCESS
-rw-r--r-- 2 root supergroup 788922 2020-05-23 12:07 /data/wc/output/part-r-00000
发现里面有两个文件,_SUCCESS文件是标志这次任务成功的。
其中part-r-00000 这个文件包含一个”r“ 表示reduce生成的输出文件,当然,也可以只有map输出的文件,如果最终只是map输出的话,这个r就会变成m(也即是part-m-00000)。后面的00000标志着这个是0号reduce输出的文件,如果存在两个reduce,就会分别为它们生成的文件生成对应的序号标志00000、000001 以此类推。
我们查看下/data/wc/output/part-r-00000 文件输出的部分结果:
99985 1
99986 1
99987 1
99988 1
99989 1
9999 1
99990 1
99991 1
99992 1
99993 1
99994 1
99995 1
99996 1
99997 1
99998 1
99999 1
hadoop 100000
hello 100000
源文件中hello 和hadoop是以一个空格隔开,总共有10w行,每行有1个唯一数字,上面的reduce统计结果计算准确。注意,之前我们上传data.txt文件时,是被hdfs以文件块切开两份,数据存储的时候是严格按照字节切分,末尾行和开投行可能出现不完整。但是计算层框架则将不完整的行重新组合成完成的行,再进行计算,往后会介绍如何实现的。
三、使用代码实战mapReduce案例
导入pom依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.5version>
dependency>
创建mapReduce启动类
package com.haizhang.hadoop.mapredcue;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class MyWordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration(true);
//获取Job实例,用于提交任务
Job job = Job.getInstance(conf);
//必写!这里会根据反射机制来得知你的这个jar包要如何找到入口类,写当前程序的启动类
job.setJarByClass(MyWordCount.class);
//随意写,这里标志任务的名称
job.setJobName("mywordcount");
/* 这两种填写map输入输出文件路径的方式已经淘汰,因为参数固定死只能传path
不方便于扩展
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
*/
//传入map的文件路径
Path in = new Path("/data/wc/input");
//可以接收多个Path路径,也就是map可以接收多个输入文件来源
TextInputFormat.addInputPath(job,in);
// TextInputFormat.addInputPath(job,in2);
Path out = new Path("/data/wc/output");
//注意mapReduce的输出,要求输出目录不存在任何数据,所以先检查是否存在目录,如果存在则递归删除即可。
FileSystem fs = out.getFileSystem(conf);
if(fs.exists(out)) fs.delete(out,true);
TextOutputFormat.setOutputPath(job,out);
//以下配置Map执行程序的逻辑的类
job.setMapperClass(MyMapper.class);
//这一要告知map输出给reduce的Key/Vlaue的类型,reduce需要用这个类型进行返程成具体的对象,然后再进行反序列化为该对象赋值
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//以下配置Reduce执行程序的逻辑类
job.setReducerClass(MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
}
}
还要创建MapReduce中的Map处理类
package com.haizhang.hadoop.mapredcue;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 这个Mapper就是wordCount的实现逻辑
*/
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
/**
* hadoop框架中,对我们平常用的变量都进行了封装,实现了自己的序列化接口,和比较器接口
* 比如 int--> IntWritable
* String -- > Text
* hadoop有自己一套可以序列化、反序列化的机制,我们可以自定义类型,不过要实现hadoop提供的
* 序列化接口(Writable)和比较器接口(Comparable) 也就是 WritableComparable接口。
**/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
*
* @param key 每行字符串自己第一个字节面向源文件的偏移量,假设文件如下“
* hello hadoop 1
* hello hadoop 2
* 则第一行的key为1,第二行的key为16(第一行字符串+空格+换行符+第二行的第一个h)
* @param value 每行数据
* @param context 上下文
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//StringTokenizer使用正则表达式,按照空格/制表符/换行符为分割符,匹配单词。比如hello hadoop 1 则调用
//itr.nextToken()先得到hello;再次调用 nextToken则得到hadoop 依次类推。
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
//设置当前匹配到的单词
word.set(itr.nextToken());
//往map输出文件写键值对key/value
context.write(word, one);
}
}
}
最后创建一个MapReduce中的Reduce处理类
package com.haizhang.hadoop.mapredcue;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//每组key统计的结果是IntWritable类型。表示单词对应的统计总数
private IntWritable result = new IntWritable();
/**
* reduce计算方法
* @param key map文件输出的Key,也就是分组key
* 例如reduce计算拉取的分组如下
* hello 1
* hello 1
* hello 1
* hello 1
* hello 1
* 则Key就是hello,以hello为分组
* @param values 每个分组所对应的value列表,如上的列子,values=[1,1,1,1,1] 当然values是个迭代器。
* @param context 上下文,做最终key/value对的记录输出
* @throws IOException
* @throws InterruptedException
*/
public void reduce(Text key, Iterable<IntWritable>values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
上面的注解已经写的很清楚了,这就实现了使用mapReduce进行wordCount计算的小列子。
当所有工作代码写完后,我们就可以使用mvn打jar包
E:\idea代码\hdfs>mvn clean install -Dmaven.test.skip=true
然后将jar上传到node1节点上。并使用下面的命令运行
[root@node1 ~]# hadoop jar hdfs-1.0-SNAPSHOT.jar com.haizhang.hadoop.mapredcue.MyWordCount
这里不需要附带输入文件输出文件的地址,因为程序jar已经写死了,当然我们可以修改jar,让它接收用户传入的地址
运行完成之后,同样可以用下面命令查看输出的结果是否和预期一样
[root@node1 ~]# hdfs dfs -ls /data/wc/output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2020-05-23 19:14 /data/wc/output/_SUCCESS
-rw-r--r-- 2 root supergroup 788922 2020-05-23 19:14 /data/wc/output/part-r-00000
[root@node1 ~]# date
Sat May 23 19:16:24 CST 2020
[root@node1 ~]# hdfs dfs -cat /data/wc/output/part-r-00000 | tail -10
99992 1
99993 1
99994 1
99995 1
99996 1
99997 1
99998 1
99999 1
hadoop 100000
hello 100000
经过校验,数据正确!