【论文精读】Swin Transformer
摘要
ViT的缺点:
- Transformer在语言处理中的基本元素是word token,其特点是语义信息比较密集。而ViT中token的尺度(scale)是固定的,且视觉token携带的语义信息比语言文字序列差,故认为不适合视觉应用
- 图像分辨率高,像素点多,如果采用ViT模型,自注意力的计算量会与像素的平方成正比,计算复杂度过高是导致ViT速度慢的主要原因
故本文做出改进:
- 基于滑动窗口机制,具有层级设计(下采样层)的Swin Transformer。滑窗操作包括对token不重叠的local window,和对token重叠的cross-windos
- 将注意力计算限制在一个小窗口中,一方面能引入CNN卷积操作的局部性,另一方面能大幅度节省计算量,它只和窗口数量成线性关系
- 通过下采样的层级设计,能够逐渐增大感受野,从而使得注意力机制也能够注意到全局的特征
框架
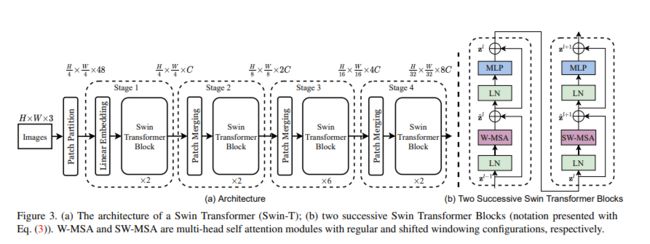
给定图像 x x x,首先通过Patch拆分(Patch Partition)模块将输入的 H × W × 3 H\times W \times3 H×W×3的RGB图像拆分为非重叠等尺寸的 N × ( P 2 × 3 ) N\times(P^2\times3) N×(P2×3)的patch。每个 P 2 × 3 P^2\times3 P2×3的patch都被视为一个patch token,共拆分出 N N N个(即Transformer的有效输入序列长度)。
具体地,令 P 2 = 4 × 4 P^2=4 \times 4 P2=4×4且通道数 C = 3 C=3 C=3,则各patch展平后的特征维度为 P × P × C = 4 × 4 × 3 = 48 P \times P \times C = 4 \times 4 \times 3 = 48 P×P×C=4×4×3=48,共有 N = H 4 × W 4 = H W 16 N = \frac H 4 \times \frac W 4 = \frac {HW} {16} N=4H×4W=16HW个patch tokens。换言之,每张 H × W × 3 H\times W \times3 H×W×3的图片被处理为了 H 4 × W 4 \frac H 4 \times \frac W 4 4H×4W个图片patches,每个patch被展平为48维的token向量(类似ViT的Flattened Patches),整体上是一个展平(flatten)的 N × ( P 2 × 3 ) = ( H 4 × W 4 ) × 48 N \times (P^2 \times 3) = (\frac H 4 \times \frac W 4) \times 48 N×(P2×3)=(4H×4W)×48的patch序列。
线性嵌入层(Linear Embedding)(即全连接层)会将此时维度为 ( H 4 × W 4 ) × 48 (\frac H 4 \times \frac W 4) \times 48 (4H×4W)×48的张量投影到任意维度 C C C,得到维度为 ( H 4 × W 4 ) × C (\frac H 4 \times \frac W 4) \times C (4H×4W)×C的Linear Embedding。
随后,这些经过Linear Embedding的patch tokens被馈入若干具有改进自注意力的Swin Transformer blocks。首个Swin Transformer block保持输入输出tokens数恒为 H 4 × W 4 × C \frac H 4 \times \frac W 4 \times C 4H×4W×C不变,且与线性嵌入层共同被指定为Stage 1(如图3的第一个虚线框所示)。
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,逐层扩大感受野。随着网络的加深,tokens数逐渐通过Patch合并层(Patch Meraging)被减少。首个Patch合并层拼接了每组 2 × 2 2 \times 2 2×2相邻patch,则patch token数变为原来的 1 4 \frac 1 4 41,即 H 8 × W 8 \frac H 8 \times \frac W 8 8H×8W,而patch token的维度扩大4倍,即 4 C 4C 4C。然后对 4 C 4C 4C维的patch拼接特征使用了一个线性层,将输出维度降为 2 C 2C 2C,得到维度为 ( H 8 × W 8 ) × 2 C (\frac H 8 \times \frac W 8) \times 2C (8H×8W)×2C的特征。然后使用Swin Transformer blocks进行特征转换,其分辨率保持 H 8 × W 8 × 2 C \frac H 8 \times \frac W 8 \times 2C 8H×8W×2C不变。首个Patch合并层和该特征转换Swin Transformer block 被指定为 Stage 2(如图3的第二个虚线框所示)。重复2次与Stage 2相同过程,则分别指定为Stage 3和 Stage 4(如图3的第三、四个虚线框所示),输出 分辨率 p a t c h t o k e n \frac {分辨率} {patch token} patchtoken分辨率数分别为 H 16 × W 16 × 4 C \frac H {16} \times \frac W {16} \times 4C 16H×16W×4C和 H 32 × W 32 × 8 C \frac H {32} \times \frac W {32} \times 8C 32H×32W×8C。每个 Stage 都会改变张量的维度,从而形成一种层次化的表征。(如下图)
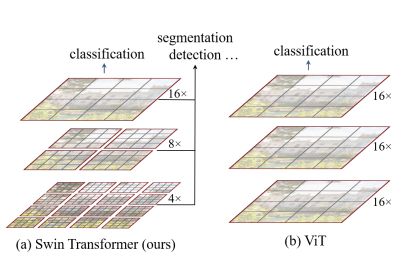
通过从小尺寸patch(灰色轮廓)开始,逐渐在更深的 Transformer 层中合并相邻patch,从而构造出一个层次化表示(hierarchical representation)。
线性计算复杂度通过在图像分区的非重叠窗口内,局部地计算自注意力来实现(红色轮廓),而非在整张图像的所有patch上进行。每个窗口中的patch数量是固定的,因此复杂度与图像大小成线性关系。
基于移位窗口的自注意力
O ( M H A ) \Omicron(MHA) O(MHA)的计算:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W o MultiHead(Q,K,V)=Concat(head_1,\dots,head_h)W^o MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
w h e r e h e a d i = A ( Q W i Q , K W i K , V W i V ) where \ \ head_i=A(QW_i^Q,KW_i^K,VW_i^V) where headi=A(QWiQ,KWiK,VWiV)
对于 multi-head attention,假设有h个 head,这里h是一个常数,对于每个 head,首先需要把三个矩阵分别映射到 d q d_q dq, d k d_k dk, d v d_v dv维度。考虑一种简化情况 d q = d k = d v = d h d_q=d_k=d_v= \frac d h dq=dk=dv=hd:
- 输入线性映射的复杂度: n × d n \times d n×d与 d × d h d \times \frac d h d×hd运算,忽略常系数,复杂度为 O ( n d 2 ) \Omicron(nd^2) O(nd2)
- Attention操作复杂度:主要在相似度计算及加权和的开销上, n × d h n \times \frac d h n×hd与 d h × n \frac d h \times n hd×n 运算,复杂度为 O ( n 2 d ) \Omicron(n^2d) O(n2d)
- 输出线性映射的复杂度:concat操作拼起来形成 n × d n \times d n×d的矩阵,然后经过输出线性映射,保证输入输出相同,所以是 n × d n \times d n×d与 d × d d \times d d×d计算,复杂度为 O ( n d 2 ) \Omicron(nd^2) O(nd2)
故MHA复杂度为 O ( n 2 d + n d 2 ) \Omicron(n^2d+nd^2) O(n2d+nd2) ,当 n > > d n>>d n>>d时, O ( M H A ) = O ( n 2 d ) \Omicron(MHA)=\Omicron(n^2d) O(MHA)=O(n2d),即 O ( M S A ) = O ( N 2 D ) \Omicron(MSA)=\Omicron(N^2D) O(MSA)=O(N2D)。标准的 Transformer 架构及其对图像分类的适应版本都执行全局自注意力,全局自注意力计算具有相对于 token 数的二次计算复杂度 O ( N 2 D ) O(N^2D) O(N2D),使之不适用于许多需大量 tokens 的密集预测,高分辨率图像表示等高计算量视觉问题。
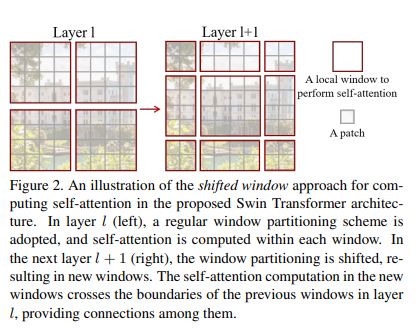
基于上述原因,提出非重叠的局部窗口中计算自注意力,取代全局自注意力。以不重叠的方式均匀地划分图像得到各个窗口(上图中的Layer1)。已知 D = 2 C D=2C D=2C,则设每个非重叠局部窗口都包含 N = M × M N=M \times M N=M×M个patch tokens,则对比基于具有 N = h × w N=h \times w N=h×w个 patch tokens 的图像窗口的MSA模块和基于非重叠局部窗口的 W-MSA 模块的计算复杂度分别是(参考 O ( M S A ) \Omicron(MSA) O(MSA)):
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C \varOmega(MSA)=4hwC^2+2(hw)^2C Ω(MSA)=4hwC2+2(hw)2C
Ω ( W – M S A ) = 4 h w C 2 + 2 M 2 h w C \varOmega(W\text{--}MSA)=4hwC^2+2M^2hwC Ω(W–MSA)=4hwC2+2M2hwC
MSA 关于 patch token 数 N = h × w N=h \times w N=h×w具有二次复杂度(共 h w hw hw个patch tokens,每个patch token在全局计算 h w hw hw次)。W-MSA 当M固定时(默认设为7)具有线性复杂度(共 h w hw hw个 patch tokens,每个 patch token 在各自的局部窗口内计算 M 2 M^2 M2次)。证明基于窗口的自注意力W_MSA比MSA具有更好的扩展性。
其次,引入连续块中的移位窗口划分方法(上图中的Layerl+1),该方法在连续 Swin Transformer blocks 中的两种划分/分区配置间交替。首个模块使用一个规则的窗口划分策略,从左上角像素开始,将8×8特征图均匀划分为2×2个大小为4×4的窗口(此时局部窗口尺寸为 M=4,如红色框所示)。下个模块采用自前一层移位的窗口配置,即令规则划分窗口向左上循环移位( ⌊ M 2 ⌋ \lfloor \frac M 2 \rfloor ⌊2M⌋, ⌊ M 2 ⌋ \lfloor \frac M 2 \rfloor ⌊2M⌋)个像素,如上图的红色框位置变化所示。移位窗口划分方法引入了先前层非重叠相邻窗口间的联系。

上述操作即两个Swin Transformer block,如上图,计算可表示为:
z ˆ l = W – M S A ( L N ( z l − 1 ) ) + z l − 1 \^{z}^l=W\text{--}MSA(LN(z^{l-1}))+z^{l-1} zˆl=W–MSA(LN(zl−1))+zl−1
z l = M L P ( L N ( z ˆ l ) ) + z ˆ l z^l=MLP(LN(\^{z}^{l}))+\^{z}^{l} zl=MLP(LN(zˆl))+zˆl
z ˆ l + 1 = S W – M S A ( L N ( z l ) ) + z l \^{z}^{l+1}=SW\text{--}MSA(LN(z^{l}))+z^{l} zˆl+1=SW–MSA(LN(zl))+zl
z l + 1 = M L P ( L N ( z ˆ l + 1 ) ) + z ˆ l + 1 z^{l+1}=MLP(LN(\^{z}^{l+1}))+\^{z}^{l+1} zl+1=MLP(LN(zˆl+1))+zˆl+1
每个Swin Transformer block由一个基于移位窗口的MSA模块构成,且后接一个夹有 GeLU 非线性在中间的2层 MLP。LayerNorm(LN)层被应用于每个MSA模块和每个MLP前,且一个残差连接被应用于每个模块后,即非重叠的局部窗口中计算自注意力,其以不重叠的方式均匀地划分图像得到各个窗口。
移位运算
从 ⌈ h M ⌉ \lceil \frac h M \rceil ⌈Mh⌉× ⌈ w M ⌉ \lceil \frac w M \rceil ⌈Mw⌉到 ( ⌈ h M ⌉ + 1 ) (\lceil \frac h M \rceil +1) (⌈Mh⌉+1)× ( ⌈ w M ⌉ + 1 ) (\lceil \frac w M \rceil +1) (⌈Mw⌉+1)会产生更多窗口,有些窗口尺寸将小于 M×M,故提出循环向左上方移位。移位后,批窗口由特征图中不相邻的子窗口组成,因此使用屏蔽机制将自注意计算限制在每个子窗口内。通过循环移位,批处理窗口的数仍与规则分区的窗口数相同(如规则划分时是4个窗口,向左上角循环移位后仍是4个窗口,如下图的 A,B,C,D 所示)。

经过了循环移位的方法,一个窗口包含来自不同窗口的内容。故采用 masked MSA 机制将自注意力计算限制在各子窗口内,最后通过逆循环移位方法将每个窗口的自注意力结果返回。
相对位置编码
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T / d + B ) V Attention(Q,K,V)=SoftMax(QK^T/\sqrt d +B)V Attention(Q,K,V)=SoftMax(QKT/d+B)V
计算Attention的Query和Key时,加入相对位置编码 B B B可改善性能。其中, Q , K , V ∈ R M 2 , d Q,K,V \in \R^{M^2,d} Q,K,V∈RM2,d分别为Query,Key和Value矩阵, d d d为Query/Key维度, M 2 M^2 M2为局部窗口内的patches数。因为沿各轴的相对位置均处于 [ − M + 1 , M − 1 ] \lbrack -M+1,M-1 \rbrack [−M+1,M−1]范围内,参数化一个更小尺寸的偏置矩阵 B ˆ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \^B \in \R^{(2M-1) \times(2M-1)} Bˆ∈R(2M−1)×(2M−1),且 B B B中的值均取自 B ˆ \^B Bˆ。
预训练中学习到的相对位置偏差也可以用来初始化一个模型,通过双三次插值进行不同窗口大小的微调。
体系结构变体
首先构建Swin-B作为基础模型,其具有与ViT-B/DeiT-B类似的模型大小和计算复杂度。其变体有Swin-T、Swin-S和Swin-L三个版本,相应大小和计算复杂度分别为Swin-B的0.25倍、0.5倍和2倍,其中Swin-T和Swin-S的复杂性类似于ResNet-50和ResNet-101。窗口大小默认设置为 M = 7 M = 7 M=7,每个头的query维度 d = 32 d = 32 d=32,每 个MLP的层扩展尺度为 α = 4 α = 4 α=4。详细超参数如下:
- S w i n T : C = 96 , l a y e r n u m b e r s = { 2 , 2 , 6 , 2 } Swin \\_T:C=96, \ layer \ numbers=\{2,2,6,2\} SwinT:C=96, layer numbers={2,2,6,2}
- S w i n S : C = 96 , l a y e r n u m b e r s = { 2 , 2 , 18 , 2 } Swin \\_S:C=96, \ layer \ numbers=\{2,2,18,2\} SwinS:C=96, layer numbers={2,2,18,2}
- S w i n B : C = 128 , l a y e r n u m b e r s = { 2 , 2 , 18 , 2 } Swin \\_B:C=128, \ layer \ numbers=\{2,2,18,2\} SwinB:C=128, layer numbers={2,2,18,2}
- S w i n L : C = 192 , l a y e r n u m b e r s = { 2 , 2 , 18 , 2 } Swin \\_L:C=192, \ layer \ numbers=\{2,2,18,2\} SwinL:C=192, layer numbers={2,2,18,2}
其中 C C C为第一阶段隐藏层的通道数。

详细的体系结构配置如上表。其中假设所有体系结构的输入图像大小为 224 × 224 224 × 224 224×224。 C o n c a t n × n Concat \ n × n Concat n×n表示在一个patch中拼接 n × n n × n n×n相邻特征,此操作对特征图进行 n n n倍的下采样。 96 − d 96-d 96−d表示输出维度为96的线性层。 w i n . s z . 7 × 7 win.sz.7 × 7 win.sz.7×7表示一个多头自注意力模块,窗口大小为7 × 7。
对比实验
ImageNet-1K图像分类
对于图像分类,在ImageNet-1K上对所提出的Swin Transformer进行了基准测试,采用两种训练设置:
- 常规ImageNet-1K监督训练。ImageNet-1K包含来自1000个类别的128万张训练图像和50K验证图像。采用AdamW优化器,使用余弦衰减学习率调度器和20epoch的linear warm-up。batch size为1024,初始学习率为0.001,权重衰减为0.05
- ImageNet-22K预训练,并在ImageNet-1K上进行微调。ImageNet-22K包含1420万张图像和22K个类别。采用AdamW优化器,该优化器使用线性衰减学习率调度器和5个epoch的linear warm-up。batch size为4096,初始学习率为0.001,权重衰减为0.01。在ImageNet-1K微调中,训练30个epoch的模型,batch size为1024,学习率为恒定10−5,权重衰减为10−8
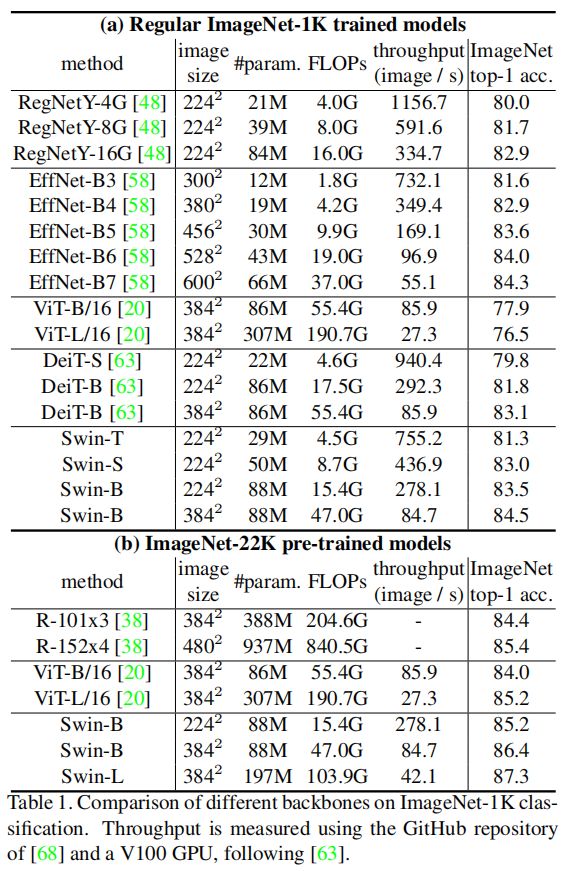
结果如上图。常规ImageNet-1K监督训练结果如图a,与最先进的transformer架构DeiT相比,使用 22 4 2 224^2 2242尺寸的输入时,Swin-T(81.3%)比DeiT-S(79.8%)高出1.5%,使用 22 4 2 / 38 4 2 224^ 2 /384 ^2 2242/3842尺寸输入时,Swin-B(83.3%/84.5%)比DeiT-B(81.8%/83.1%)分别高出1.5%/1.4%。 与最先进的卷积网络RegNet和EfficientNet 相比,Swin Transformer实现了稍好的速度-精度平衡。
ImageNet-22K预训练的结果如图b。对于Swin-B,ImageNet-22K预训练比ImageNet-1K从头训练带来了1.8%∼ 1.9%的收益。与ImageNet-22K预训练之前的最佳结果相比,所提出模型实现了更好的速度-精度平衡,Swin-B获得了86.4%的top-1精度,比ViT提高了2.4%,同时具有类似的推理吞吐量(84.7 vs. 85.9张图像/秒)和略低的FLOPs(47.0G vs. 55.4G)。Swin-L取得了87.3%的top-1准确率,比Swin-B模型提高了0.9%。
COCO目标检测
本实验在COCO2017上进行目标检测和实例分割实验,COCO2017包含118K训练图像、5K验证图像和20K测试图像。使用验证集进行消融研究,在测试集上进行系统级比较。
- 对于框架消融研究,采用MMDetection中四个典型的目标检测框架:Cascade Mask R-CNN、ATSS、RepPoints v2和Sparse RCNN。对于这四个框架使用相同的设置,多尺度训练(调整输入,使较短的边长 在480和800之间,而较长的边长 最长为1333),AdamW 优化器(初始学习率0.0001,权重衰减0.05,batch size为16),36个epoch。
- 对于系统级比较,采用HTC++框架,其中策略包括instaboost、更强的多尺度训练、72个epoch、soft-NMS并使用ImageNet-22K预训练模型初始化骨干网路。
在此基础上,将Swin Transformer与标准卷积网络(ResNe(X)t)和之前的Transformer网络(DeiT)进行了比较(在其他设置不变的情况下,只改变骨干网络即可进行比较)。
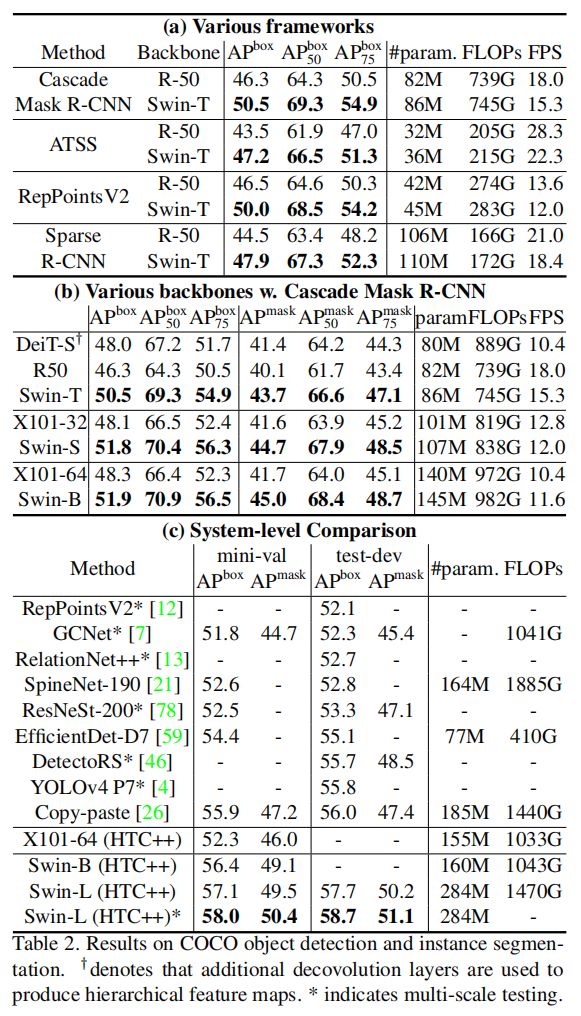
结果如上图。表a为Swin-T和ResNet-50在四个目标检测框架上的结果,Swin-T 比ResNet-50带来了+3.4∼4.2 box AP增益,但模型大小、FLOPs和延迟稍大。 表b使用Cascade Mask R-CNN比较了不同模型参数量下的Swin Transformer和ResNe(X)t,Swin-B实现了51.9boxAP和45.0maskAP的精度,比具有相似的模型大小、FLOPs和延迟的ResNeXt101- 64提升3.6boxAP和3.3maskAP。 表c中,在使用HTC++框架的X101-64的52.3boxAP和46.0maskAP的基线上,HTC++框架的Swin-B提高4.1boxAP和3.1maskAP。
推理速度角度看,相比于表b中使用Cascade Mask R-CNN框架的DeiT-S,Swin-T比DeiT-S在相似的模型大小(86M vs. 80M)下提升+2.5box AP和2.3 Mask AP,并且具有更高的推理速度(15.3 FPS vs. 10.4 FPS)。
表c将Swin Transfromer的最佳结果与以前最先进的模型进行了比较。Swin-L 在COCO test-dev上实现了58.7 box AP和51.1 mask AP,超过了之前的最佳模型Copy-paste2.7box AP和2.6 mask AP。
ADE20K语义分割
ADE20K是一个语义分割数据集,涵盖了150个语义类别,总共有25K张图像,其中20K用于训练,2K用于验证,另外3K用于测试。本实验使用MMSeg中的UperNet作为基础框架。
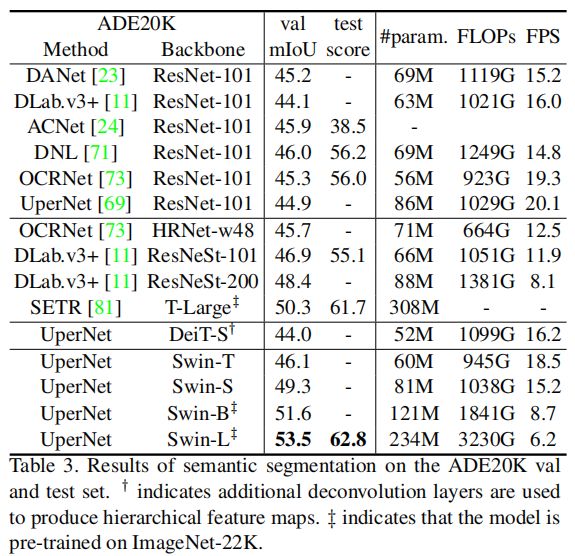
结果如上图。其中列出了不同Method/backbone的mIoU、模型大小(#param)、FLOPs和FPS。观察到,在计算开销相当的情况下,UperNet/Swin-S比UperNet/DeiT-S高出5.3mIoU。比UperNet/ResNet-101高4.4 mIoU,比DLab.v3+/ResNeSt-101高2.4 mIoU。
使用ImageNet- 22K预训练的Swin-L模型在val集上达到了53.5 mIoU,超过了之前的最佳模型SETR/T-Large 3.2 mIoU的50.3 mIoU。
消融实验
本实验使用ImageNet-1K图像分类、用于COCO目标检测的Cascade Mask R-CNN、以及用于ADE20K语义分割的UperNet消融Swin Transformer中的重要设计元素。
移动窗口

这三个任务上移位窗口的消融情况如上图表4。具有移位窗口划分的Swin-T在每个阶段都比基于单个窗口划分构建的对应方法性能更好,在ImageNet-1K上提高了1.1%的top-1精度,在COCO上提高了2.8 box AP和2.2 mask AP,在ADE20K上提高了2.8 mIoU。实验结果表明,利用移位窗口建立前几层窗口之间的连接是有效的。
相对位置偏差
上图表4也显示了不同位置嵌入方法的结果。相对于没有位置嵌入和绝对位置嵌入的情况,带有相对位置嵌入的Swin-T在ImageNet-1K上的top-1精度为+1.2%/+0.8%,在COCO上为+1.3/+1.5 box AP和+1.1/+1.3 mask AP,在ADE20K上为+2.3/+2.9 mIoU,表明了相对位置偏差的有效性。
不同的自注意力方法

上表为使用不同自注意力方法的速度比较。观察到循环移位窗口比naive滑动窗口在Swin-T、Swin-S和Swin-B上提升了13%、18%和18%的速度。 基于循环移位窗口的自注意力在四个网络阶段上分别比naive/kernel滑动窗口实现的自注意力快40.8 ×/2.5 ×,20.2 ×/2.5 ×,9.3 ×/2.1 ×和7.6 ×/1.8 ×,基于循环移位窗口的Swin Transformer分别比naive/kernel滑动窗口的Swin-T、Swin-S和Swin-B变体快4.1/1.5、4.0/1.5、3.6/1.5倍。
与最快的Transformer架构之一Performer相比,基于循环移位窗口的Swin Transformer稍快。
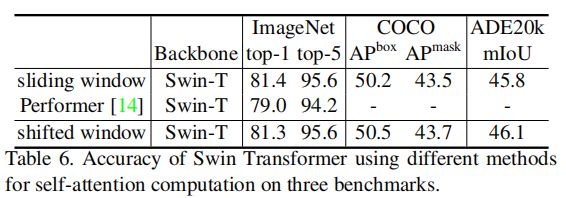
上表比较了几种注意力方法在三个任务上的准确性。观察到ImageNet-1K上基于循环位移窗口的 Swin-T比Performer提高2.3%的最高精度,和基于滑动窗口的方法精度类似。
更多实验
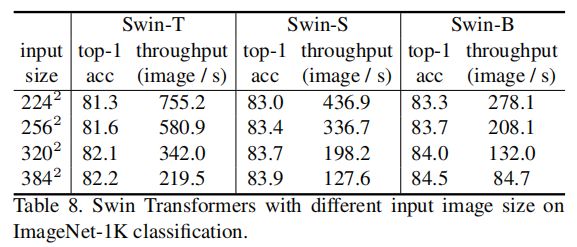
上表列出了从 22 4 2 224^2 2242到 38 4 2 384^2 3842不同输入图像大小的Swin transformer的性能。观察到较大的输入分辨率会带来更好的top-1精度,但推理速度会变慢。

上图在COCO目标检测上使用Cascade Mask R-CNN框架比较ResNe(X)t骨干使用 AdamW和SGD优化器的结果。虽然SGD被用作Cascade Mask R-CNN框架的默认优化器,但观察到用AdamW优化器替换它可以提高精度,特别是对于较小的backbone。因此,与所提出的Swin Transformer架构相比,本文将AdamW用于ResNe(X)t骨干的优化。
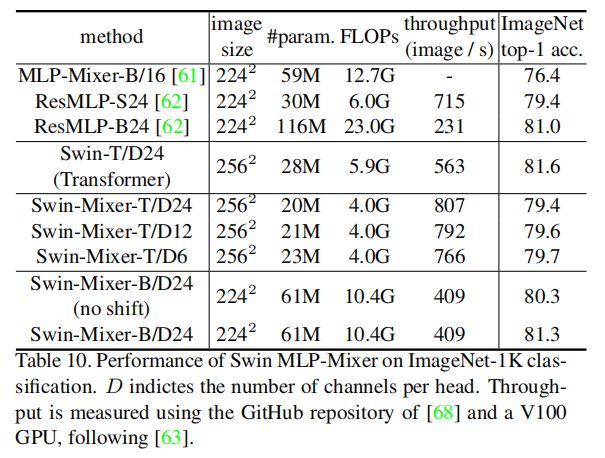
将所提出的分层设计和移位窗口方法应用于MLP-Mixer架构,称为Swin-Mixer。上表显示了Swin-Mixer与原始MLP-Mixer架构及ResMLP的性能比较。Swin-Mixer的性能明显优于MLP-Mixer(81.3% vs. 76.4%),计算预算略小(10.4G vs. 12.7G)。与ResMLP相比,还具有更好的速度和精度平衡。这些结果表明,分层设计和移动窗口方法具有通用性。
reference
Liu, Z. , Lin, Y. , Cao, Y. , Hu, H. , Wei, Y. , & Zhang, Z. , et al. (2021). Swin transformer: hierarchical vision transformer using shifted windows.