【论文精读】 Vision Transformer(ViT)
摘要
验证了当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
架构
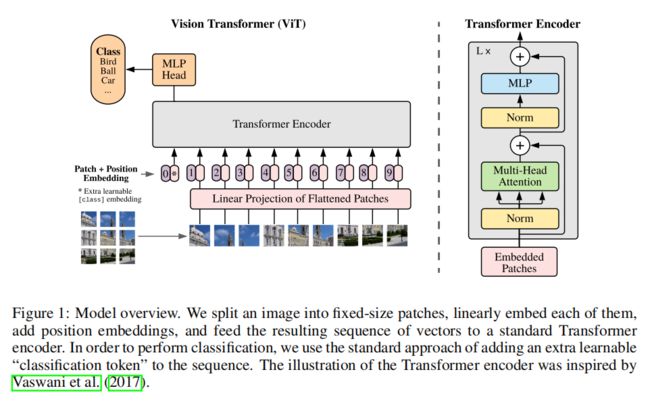
如上图,给定图像 x ∈ R H × W × C x \in \Reals^{H \times W \times C} x∈RH×W×C分割为2D patch序列 x p ∈ R N × ( P 2 ⋅ C ) x_p \in \Reals^{N \times (P^2 \cdot C)} xp∈RN×(P2⋅C),其中 ( H , W ) (H, W) (H,W)是原 始图像的分辨率, C C C是通道的数量, ( P , P ) (P, P) (P,P)为每个图像patch的分辨率, N = H W / P 2 N = HW/P^2 N=HW/P2是patch的数量,这作为Transformer的输入序列长度。后通过patch embedding将patch展平并通过线性投影映射到D维度 E ∈ R D × ( P 2 ⋅ C ) E \in \Reals^{D \times (P^2 \cdot C)} E∈RD×(P2⋅C)。
类似于BERT的[class]标记,在patch embedding序列前添加一个可学习的嵌 入 ( z 0 0 = x c l a s s ) (z^ 0_ 0 = x_{class}) (z00=xclass),其在Transformer编码器的输出序列位置为 ( z L 0 ) (z ^0_L ) (zL0),该输出通过分类头后得到图像表示 y y y。分类头在预训练时由MLP实现,在微调时由单一的线性层实现。
position embedding被添加到patch embedding中保留位置信息,使用标准的可学习的1D位置嵌入,得到的最终的embedding向量序列作为Transformer编码器的输入。
Transformer编码器由交替的多头自注意力(MSA)和MLP块组成。在每个块前都应用Layernorm(LN),在每个块之后应用残差连接。MLP包含两层线性层及非线性GELU激活函数。整体结构如下:
z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; … ; x p N E ] + E p o s , E ∈ R ( p 2 ⋅ C ) × D , E p o s ∈ R N + 1 × D z_0=[x_{class;x^1_pE;x^2_pE;\dots ;x^N_pE}]+E_{pos}, E \in \Reals^{(p^2 \cdot C)\times D},E_{pos} \in \Reals^{N+1}\times D z0=[xclass;xp1E;xp2E;…;xpNE]+Epos,E∈R(p2⋅C)×D,Epos∈RN+1×D
z ℓ ′ = M S A ( L N ( z ℓ − 1 ) ) + z ℓ − 1 , ℓ = 1 … L z'_{\ell}=MSA(LN(z_{\ell-1}))+z_{\ell-1}, \ell=1 \dots L zℓ′=MSA(LN(zℓ−1))+zℓ−1,ℓ=1…L
z ℓ = M L P ( L N ( z ℓ ′ ) ) + z ℓ ′ , ℓ = 1 … L z_{\ell}=MLP(LN(z'_{\ell}))+z'_{\ell}, \ell=1 \dots L zℓ=MLP(LN(zℓ′))+zℓ′,ℓ=1…L
y = L N ( z L 0 ) y=LN(z^0_L) y=LN(zL0)
归纳偏差
在cnn中,局部性、二维邻域结构和平移不变性被整合到整个模型的每一层中。在ViT中,只有MLP层具有局部性和平移不变性,而自注意力层是全局性的。二维邻域结构体现在模型开始时通过将图像切割成块,并在微调时调整不同分辨率图像的位置嵌入。除此之外,初始化时的位置嵌入不携带关于块的2D位置的信息,块之间的所有空间关系必须从头学习。
混合架构
作为原始图像块的替代方案,输入序列可以从CNN的特征图形成。在这个混合模型中,将patch embedding投影 E E E应用于从CNN特征图中提取的块。作为一个特例,patch的空间大小调整为 1 × 1 1 \times 1 1×1,这意味着输入序列是通过简单地展平特征映射的空间维度并投影到Transformer维度来获得的。分类输入嵌入和位置嵌入按上述方式添加。
实验
实验配置
数据集
使用ILSVRC-2012 ImageNet,ImageNet-21k、JFT-18k,实验消除了重复的预训练数据集数据。在这些数据集上训练的模型迁移到下列几个基准任务测试:ImageNet消除了重复数据后的验证标签,CIFAR-10/100,Oxford- iiit Pets, Oxford Flowers-102,还在19个任务的VTAB分类任务上进行了评估。
模型变体
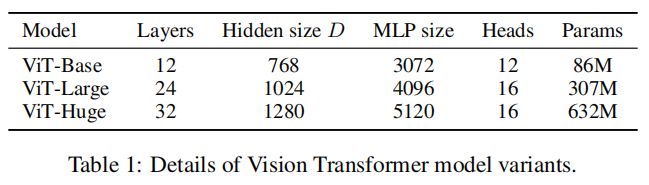
如上图,实验使用基于BERT的配置配置ViT。Base和Large 模型直接采用BERT,并添加了更大的Huge模型。 对于cnn,使用ResNet,并将Batch Normalization替换为Group Normalization。对于混合模型(Hybrid),将 cnn特征图输入ViT,其patch大小为一个像素。
训练和微调
对于训练,所有模型均使用 β 1 = 0.9 , β 2 = 0.999 β_1 = 0.9, β_2 = 0.999 β1=0.9,β2=0.999的Adam,batch size为4096,并应用0.1的权重衰减。训练使用的线性学习率warmup策略和衰减。微调阶段,优化函数采用SGD,batch size为512。
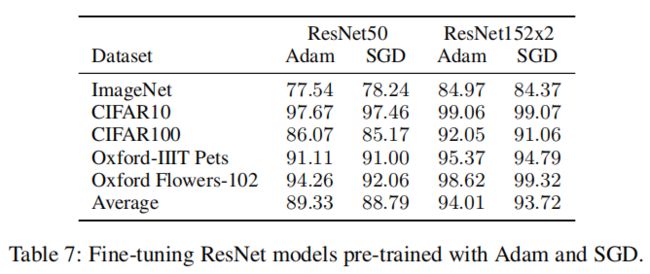
如上图所示,在同样配置下,Adam比ResNets的SGD工作得稍好,故实验采用Adam。

上图显示了微调过程中的学习率、warmup策略细节。
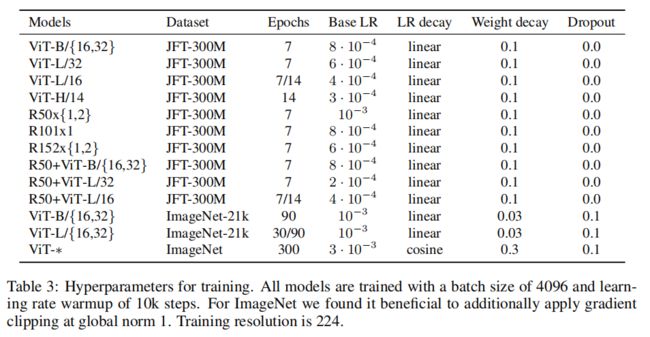
上图为更详细的训练配置。
对比实验
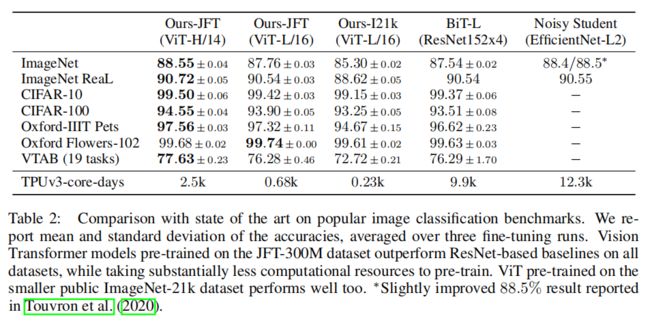
上图观察到在JFT数据集上预训练的ViT模型,迁移到下游任务后,表现要好于基于ResNet的BiT和基于EfficientNet的Noisy Student,且需要更少的预训练时间,更大的模型ViT-H/14进一步提高了性能。

上图更详细的显示了在ImageNet、ImageNet-21k或JFT300M上预训练时,Vision Transformer在各种数据集上的准确率。观察到算法性能由于其他框架。
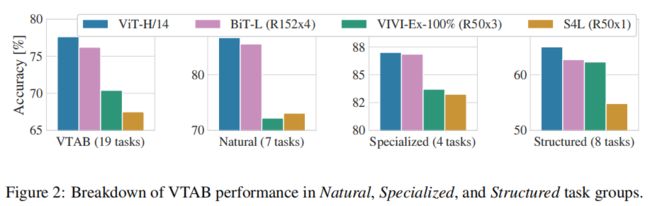
上图观察到在不同大小的数据集上预训练时,ViT性能超越CNN(BiT、VIVI、S4L(监督加半监督学习))。
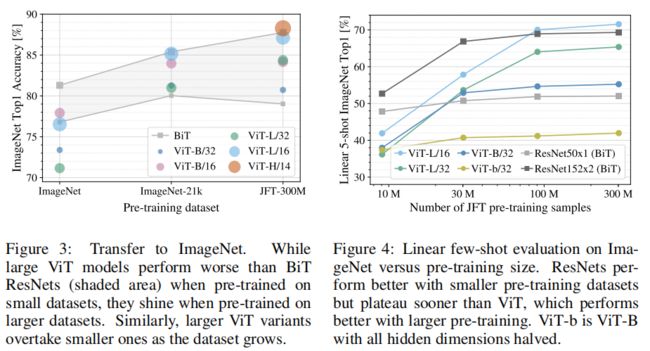
左图在更小的数据集上预训练(ImageNet),优化weight decay, dropout 和 label smoothing以提升模型性能。可以看到当在小数据集上预训练时(ImageNet-1k),ViT微调后的效果远远比不上ResNet;在中等数据集上预训练时(ImageNet-21K),两者效果相当;当在很大的数据集上(JFT-300M)预训练时,ViT的效果要更好。
右图在同一个数据集(JFT),分别抽取不同数量的数据(10M,30M,100M,300M),避免不同数据集之间的gap,同时不使用额外的正则,超参数相同。linear evaluation是指直接把预训练模型当做特征提取器,few-shot是在验证过程中,每一类只采样五张图片。 可以看到当数据集很小时,CNN预训练模型表现更好,证明了CNN归纳偏置的有效性,但是当数据集足够大时,归纳偏置和Transformer比较就失去了优势,甚至没有归纳偏置,直接从数据上学习模式会更有效。

上图显示了不同vit框架在每个VTAB-1k任务上获得的分数。
模型训练成本
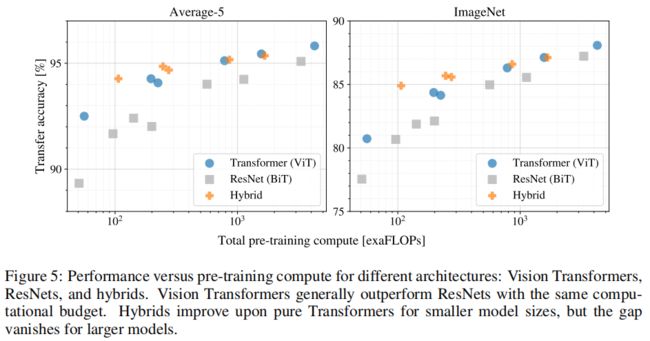
上图显示了不同架构的识别性能与预训练计算成本的比较,观察到Vision Transformers通常在相同的计算量下精度优于ResNets。混合模型在较小的模型尺寸上改进了纯transformer,但在较大的模型上精度差距消失了。
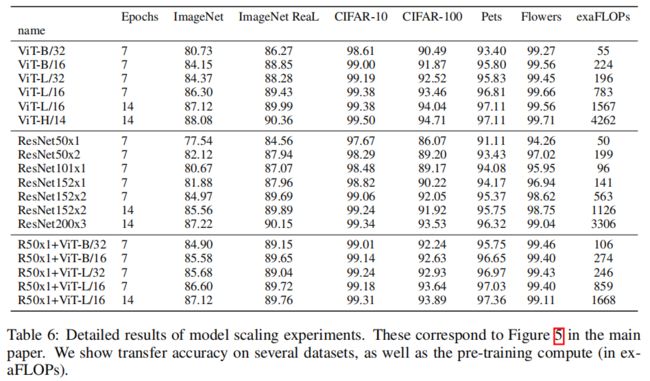
上图显示更详细的实验性能数据,包括ViT、ResNet和不同大小的混合模型的迁移性能,以及各自预训练的计算成本。
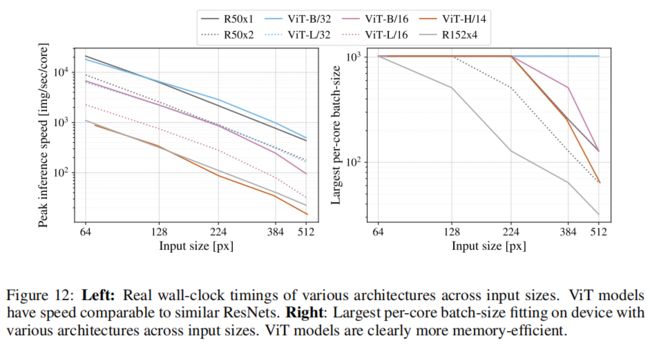
上图左显示了不同输入大小的各种体系结构的推理耗费时钟时间。观察到ViT模型的速度与类似的ResNets相当。
图右显示不同输入大小的架构下,不同batch size占用的内存最大核心数。ViT模型的内存效率显然更高。
可视化
上图显示了输出层特征叠加到输入图像的可视化,表现了模型对分类任务的关注范围。

上图左显示了ViT第一层将图像转patch embedding的滤波器的主成分。
在投影之后,将学习到的位置嵌入添加到块表示中。上图中表明模型通过位置嵌入的相似性对图像内的距离进行编码,即越近的块具有越相似的位置嵌入。此外,出现了行-列结构,同一行/列中的补丁具有相似的嵌入。
self-attention允许ViT整合整个图像的信息。图右显示了注意力权重在图像空间中的平均距离,类似于cnn中的感受野尺寸的实验。观察到一些深层网络的注意力头关注全局信息,浅层的注意力头更关注局部特征信息,这表明其可能具有与浅层卷积层类似的功能。注意距离随着网络深度的增加而增加,在全局范围内,该模型关注的是在语义上与分类相关的图像区域。

上图为更详细的用不同超参数训练的模型的位置嵌入。

上图显示了更详细的vit和混合模型的注意力权重在图像空间中的平均距离,即将query像素与所有其他像素之间的距离用注意力权重加权平均。
positional encoding

- No Pos Emb:不采用位置嵌入
- 1-D Pos Emb:例如3x3共9个patch,patch编码为1到9
- 2-D Pos Emb:patch编码为11,12,13,21,22,23,31,32,33,即同时考虑X和Y轴的信息,每个轴的编码维度是D/2
- Rel Pos Emb:考虑块之间的相对距离来嵌入空间信息,而不是它们的绝对位置。
实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,不使用位置编码,模型的性能损失也没有特别大。原因可能是ViT是作用在image patch上的,而不是image pixel,对网络来说这些patch之间的相对位置信息很容易理解,所以使用什么方式的位置编码影像都不大。
reference
Dosovitskiy, A. , Beyer, L. , Kolesnikov, A. , Weissenborn, D. , & Houlsby, N. . (2020). An image is worth 16x16 words: transformers for image recognition at scale.