跨模态行人重识别:Dynamic Dual-Attentive Aggregation Learningfor Visible-Infrared Person Re-Identification学习笔记
目录
摘要
方法
模态内加权聚合(IWPA)
跨模态图结构化注意力(CGSA)
Graph Construction
Graph Attention
动态对偶聚合学习
试验
论文链接:Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-Identification
摘要
通过挖掘 VI-ReID 的模态内部分级和跨模态图级上下文线索,提出了一种新颖的动态双注意聚合 (DDAG) 学习方法。提出了一个模态内加权部分注意模块,通过将领域知识强加于部分关系挖掘来提取有区别的部分聚合特征。为了增强对噪声样本的鲁棒性,引入了跨模态图结构化注意力,以加强具有跨两种模态的上下文关系的表示。开发了一种无参数动态对偶聚合学习策略,以渐进式联合训练的方式自适应地集成这两个组件。
 ( a) 来自SYSU-MM01数据集 [50] 的示例图像,由于数据注释/收集difficulty而具有高样本噪声。主要组成部分 :( b) 内部加权部分聚合 (IWPA),它通过挖掘每个模态中的上下文部分信息来学习歧视性部分聚合特征。(c) 跨模态结构化注意 (CGSA),它通过合并来自两种模式的邻域信息来增强表示。
( a) 来自SYSU-MM01数据集 [50] 的示例图像,由于数据注释/收集difficulty而具有高样本噪声。主要组成部分 :( b) 内部加权部分聚合 (IWPA),它通过挖掘每个模态中的上下文部分信息来学习歧视性部分聚合特征。(c) 跨模态结构化注意 (CGSA),它通过合并来自两种模式的邻域信息来增强表示。
方法
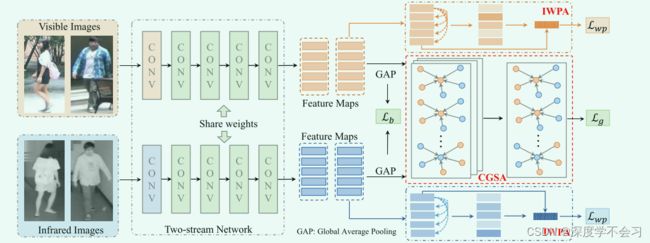
DDAG包括两个主要组件,模态内加权部分聚合 (IWPA) 和跨模态图结构化注意力 (CGSA)。我们的主要思想是在模态内部分级别和跨模态图级别挖掘上下文提示,以增强特征表示习。
IWPA旨在通过同时挖掘每个模态中身体部位之间的上下文关系并施加领域知识来处理模态差异,从而学习歧视性的部分聚合特征,自适应地分配不同身体部位的权重。此设计在计算上是有效的,因为学习了特定于模态的部分级别的注意力,而不是像素级别的注意力 ,并且它还导致了对背景杂波的更强的鲁棒性。我们进一步开发了具有加权零件聚集的残余BatchNorm连接,以减少嘈杂的身体部位的影响,并积极处理聚集特征中的部位差异。
CGSA 专注于通过结合两种模态的人物图像之间的关系来学习增强的节点特征表示。我们通过利用跨模态图中的上下文信息,通过多头注意力图方案为模态内和跨模态邻居分配自适应权重,消除了具有较大变化的样本的负面影响。通过挖掘两种模态的人物图像之间的图形关系来增强特征表示,该策略还减少了模态差异并平滑了训练过程。
此外,引入了一种无参数动态对偶聚合学习策略,以多任务端到端学习的方式动态聚合两个注意力模块,使复杂的双重注意力网络稳定收敛,同时加强每个注意力零件。
模态内加权聚合(IWPA)
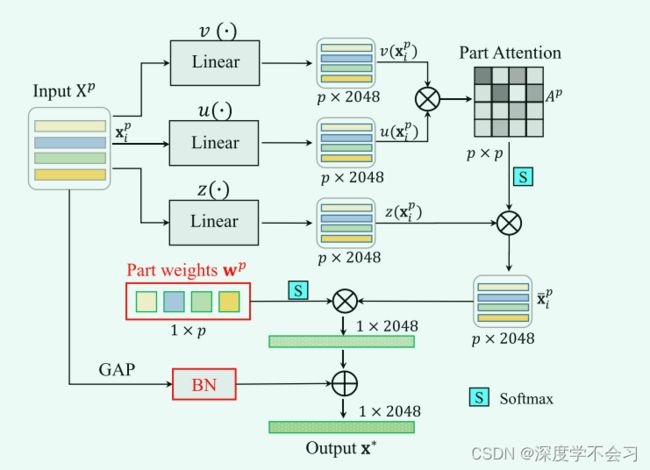
IWPA 模块是从网络的最后一个残差块中提取的特征图,从中提取注意力增强的部分特征。将最后一个卷积块的输出特征图表示为 {X = xk ∈ R(C×H×W)}K k=1,其中 C 表示通道维度(在实验中 C = 2048),H 和 W 表示特征图大小,K 代表批量大小。为了获得部分特征,使用区域池化策略将特征图直接划分为 p 个不重叠的部分。然后每个输入图像的部分特征由 Xp = {xpi ∈ R(C×1)}p(i=1) 表示。将每个部分输入三个 1 × 1 卷积层 u(·)、v(·) 和 z(·),基于模态部分的非局部注意力 αp i,j ∈ [0, 1](p×p)

f(xpi, xpj) 表示两部分特征之间的成对相似度。为了增强可辨别性,增加了一个指数函数来放大关系,从而扩大了部分注意力的差异:
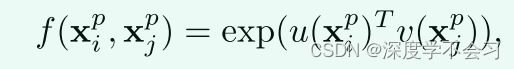
(pi) = Wuxpi 和 v(xpj ) = Wvxp (3) j 是两个具有卷积运算 u(·) 和 v(·) 的嵌入。 Wu和Wv 是u和v中对应的权重参数。使用指数函数,注意力计算可以将 1×2048 视为使用 softmax 函数的归一化。注意力图是 p×p 来捕获部分关系,这比像素级注意力 HW ×HW 小得多,使其更有效。同时,部分关系对人物图像中的噪声区域和局部杂波具有鲁棒性。
利用学习到的部分注意力,注意力增强的部分特征然后由嵌入部分特征 z(xp i ) 和计算的注意力 Ap 的内积表示,其公式为
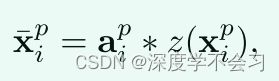
api ∈ Ap = {αp (4) i,j}p×p 是计算出来的部分注意力图。因此细化的部分特征考虑了不同身体部位之间的关系。然而简单的平均池化或部分特征的连接对于细粒度的人员 Re-ID 任务来说不够强大,并且可能会导致嘈杂的部分积累。同时,训练多个部分级别的分类器是低效的,为了解决这些问题,设计了一个残差 BatchNorm (RBN) 加权部分聚合策略。
残差BatchNorm加权部分聚合:
包括两个主要部分:首先,我们使用平均池化后的原始输入特征图 xo 的残差 BatchNorm 连接,残差学习策略可以训练非常深的神经网络并稳定训练过程。其次,我们使用注意力增强部分特征的可学习加权组合来制定有区别的部分聚合特征表示。
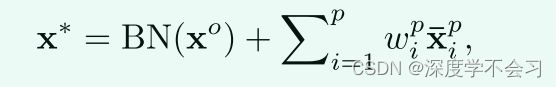
xo表示输入特征图 Xp 的全局自适应池化输出。 BN 表示批量归一化操作,wp = {wpi}pi=1表示处理模态差异的不同部分的可学习权重向量。
跨模态图结构化注意力(CGSA)
Graph Construction
在每个训练步骤中,我们采用身份平衡抽样策略进行训练 。具体来说,对于随机选择的 n 个不同身份中的每一个,随机采样 m 个可见图像和 m 个红外图像,从而在每个训练批次中产生 K = 2mn 个图像。用归一化邻接矩阵制定无向图 G
![]()
Ag0(i, j) = li ∗ lj (li 和 lj 是两个图节点对应的 one-hot 标签)。 IK 是一个单位矩阵,表示每个节点都连接到自己。通过在每个训练批次中的 one-hot 标签之间进行矩阵乘法,可以有效地计算图构造。
Graph Attention
这衡量了节点 i 对图中另一个节点 j 的重要性,跨越两种模式。我们用 Xo = {xok ∈ R(C×1)} K k=1 表示输入节点特征,它们是池化层的输出。然后计算图注意力系数 αg i,j ∈ [0, 1]K×K
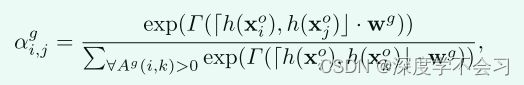
其中 Γ(·) 表示 LeakyRelu 操作。 [, ]是串联运算。 h(·) 是将输入节点特征维度 C 降低到 d 的变换矩阵,在我们的实验中 d 设置为 256。 wg ∈ R2d×1 表示一个可学习的权重向量,用于衡量不同特征维度在连接特征中的重要性]。设计充分利用了两种模式下所有图像之间的关系,使用相同身份的上下文信息加强了表示。
为了增强可辨别性和稳定图注意力学习,采用多头注意力技术[38],通过学习多个 hl(·) 和 wl,g (l = 1, 2···, L, L 是总数头)具有相同的结构并分别优化它们。在连接多个头部的输出之后,图结构的注意力增强特征然后表示为
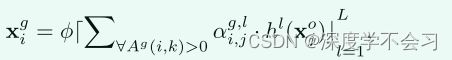
xgi对异常样本具有鲁棒性,其中 φ 是 ELU 激活函数。为了指导跨模态图结构化注意力学习,我们引入了另一个单头结构的图注意力层,其中最终输出节点特征由 Xg = {xg i } K k=1 表示。我们采用负对数似然 (NLL) 损失函数进行图注意力学习,公式如下
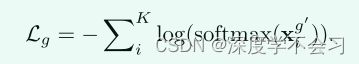
动态对偶聚合学习
引入了一种动态对偶聚合学习策略来自适应地集成上述两个组件。具体来说,将整个框架分解为两个不同的任务,实例级部分聚合特征学习 LP 和图级全局特征学习 Lg。实例级部分聚合特征学习 LP 是基线学习目标 Lb 和模态内加权部分注意力损失 Lwp 的组合,表示为
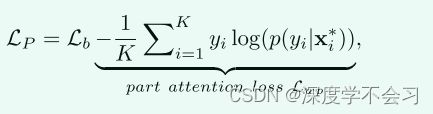
p(yi|x∗i ) 表示 x∗i 被正确分类为真实标签 yi 的概率。第二项表示实例级部分聚合特征学习,在每个模态中具有加权部分注意力。它是由聚合部分特征 x∗之上的身份损失制定的。
动态对偶聚合学习:
基本思想是实例级部分聚合特征学习 LP 作为主要损失,然后逐步添加图级全局特征学习损失 Lg 进行优化。这样做的主要原因是在早期使用 LP 更容易学习实例级特征表示。通过更好的学习网络,图级全局特征学习使用两种模式下的人物图像之间的关系来优化特征,表示为

其中 t 是 epoch 数,E(Lt−1P ) 表示前一个 epoch 的平均损失值。在这个动态更新框架中(如图 所示),图级全局损失 Lg 逐渐添加到整个学习过程中。这种策略与多任务学习中的梯度归一化具有相似的精神,但它没有引入任何额外的超参数调整。
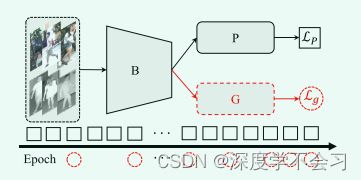
无参数动态对偶聚合学习的插图。我们将整个训练框架分解为两部分:实例级部分聚合特征学习 LP 和图级全局特征学习 Lg。将 LP 视为主要损失,并在整个训练过程中逐步添加 Lg。
试验

1)基线的有效性:使用共享卷积块获得了比双流网络更好的性能。
2) P 的有效性:模态内加权部分聚合显着提高了性能。该实验表明,学习部分级加权注意力特征有利于跨模态 Re-ID。
3) G 的有效性:当我们包含跨模态图结构化注意力 (B + G) 时,通过使用跨两种模态的人物图像之间的关系来减少模态差异来提高性能。
4)双重聚合的有效性:当使用动态双重聚合策略聚合两个注意力模块时,性能进一步提高,表明这两个注意力是互惠互利的。
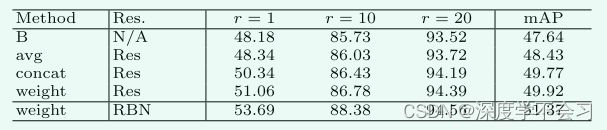
在 SYSUMM01 数据集(全搜索模式)上使用不同设计评估重新加权的部分注意力。 报告 r 准确度 (%) 和 mAP (%) 的排名。 (设置:基线 + 部分注意力。)

在SYSU-MM01数据集上评估图形注意(所有搜索模式)。Ng表示为图形构造选择的图像数。报告了r级精度(%)和mAP(%)。(设置:基线+图形注意。)

对等式中不同身体部位 p 的评估和等式中不同数量的图注意力头L。在 SYSU-MM01 数据集上,在具有挑战性的全搜索模式下。报告了 Rank-1 匹配准确度 (%) 和 mAP (%)。
较大的 p 捕获了更细粒度的部分特征并提高了性能。然而,当 p 太大时,性能会下降,因为小的身体部位不能包含足够的信息来进行局部注意力学习。如右图所示,较大的 L 提供更可靠的关系挖掘,从而不断提高性能。然而,它也大大增加了优化的难度,导致 L 太大时性能略有下降。