图像处理之《生成隐写流》论文阅读
一、文章摘要
生成隐写术(GS)是一种新的数据隐藏方式,其特点是直接从秘密数据生成隐写介质。现有的GS方法通常因性能差而受到批评。本文提出了一种新的基于流的GS方法——生成隐写流(GSF),该方法可以直接生成隐写图像而不需要封面图像。我们将隐写图像生成和秘密数据恢复过程作为一个可逆变换,在输入的秘密数据和生成的隐写图像之间建立可逆的双客观映射。在前向映射中,将秘密数据隐藏在Glow模型的输入潜变量中,生成隐写图像。通过反向映射,可以从生成的隐写图像中准确地提取隐藏数据。此外,我们提出了一种新的潜变量优化策略来提高隐写图像的保真度。实验结果表明,本文提出的GSF算法的性能远远优于SOTA算法。

二、提出的方法
拟建GSF的管道如图2所示,包括两个阶段:1.潜变量优化阶段;2.隐藏和提取秘密的阶段。在第一阶段,对潜变量Z进行优化,旨在提高生成的隐写图像的质量。如图2顶部所示,采用质量评估器对图像保真度进行评估,根据每个输入图像的保真度输出一个分数。将生成图像与真实图像之间的分数差(Diff)作为后向损失进行优化;在第二阶段,建立从输入秘密数据到输出隐写图像的可逆双射映射,通过该映射可以将秘密数据转换为隐写图像,反之亦然。数据隐藏过程如图2底部所示。首先,将第一阶段优化后的潜变量Z编码为二进制序列,并将每个序列中的一些可隐藏位替换为输入的秘密数据。其次,将这些修改后的序列转换为与Z中的张量具有相同大小的L个浮点张量,称为隐写潜变量Zs。最后,Zs被发送到一个预训练的Glow模型,用于生成隐写图像。相反,可以通过反转上述过程来检索隐藏的秘密数据。
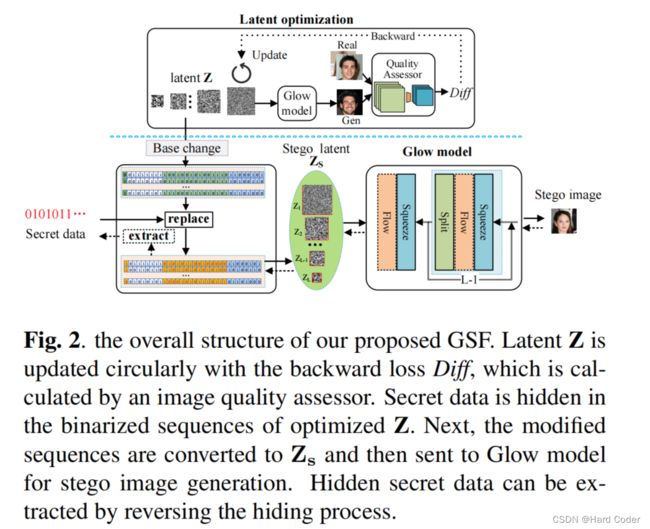
图2 我们建议的GSF的整体结构。潜变量Z与向后损失Diff循环更新,该Diff由图像质量评估器计算。将秘密数据隐藏在优化后的Z二值化序列中,然后将修改后的序列转换为Zs,然后发送给Glow模型进行隐写图像生成。隐藏的秘密数据可以通过反转隐藏过程来提取
2.1 模型训练
我们的方案建立在基于流的生成模型Glow[12]的基础上,通过该模型,输入潜变量Z和生成图像I几乎可以在没有信息损失的情况下相互转换,即Glow(I) = Z和Glow−1(Z) = I。Glow由一系列可逆函数Glow = f1×f2···×fn组成。Glow的变换可以表示为:I f1→h1 f2→h2···fn→Z;zf−1 n→hn−1···f−1 2→h1 f−1 1→I;这里,fi是可逆变换函数,hi是fi的输出。Glow由三种类型的模块组成,包括挤压模块、流动模块和分割模块。挤压模块用于特征映射的下采样,流模块用于特征处理。分割模块将图像特征沿通道侧分成两半,其中一半作为潜变量张量Zi输出,其大小为:

其中H/W为生成图像的高度/宽度,L为Zi的个数。然后,另一半功能循环到挤压模块中。在我们的方案中,将Z =∑Li=1Zi作为Glow的整体输入潜变量。Glow模型的损失函数定义为:

式中,log|det (dhi/dhi−1)|为雅可比矩阵行列式dhi/dhi−1的绝对值的对数。
2.2 潜变量优化策略
Glow的初始输入潜变量服从如下分布:Z ~ N(0;1) × δ,但只能生成低质量的图像。因此,我们提出了一种潜变量优化策略来提高生成图像的质量。所提出的策略如图2顶部所示,在算法1中进行了描述。我们不使用随机正态分布,而是用映射潜变量的平均值初始化Z,其中n个随机采样的真实图像In使用Glow模型转换为潜变量值,即Z = 1/n ∑Glow(In)。接下来,将初始化的Z与向后损失Diff循环更新,以进一步提高图像质量。

在该策略中,我们使用质量评估器(QA)来评估图像的保真度。使用预训练的分类器Resnet50[13]作为QA,对真实图像和Glow生成的图像进行训练。QA将为真实输入图像输出正分数,为生成图像输出负分数。Diff是QA输出的n张真实图像的平均得分与生成图像的得分之差,可以计算为:

式中,scoreireal为QA对第i张实数图像的输出得分,scoregen为生成图像的得分。每一步只生成一个图像。在每一步优化中,Z的更新如下:
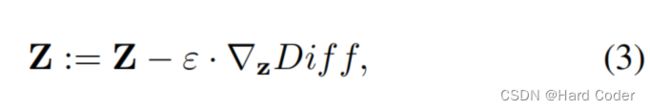
其中,ε为控制变化水平的超参数,∇zDiff为潜变量z的梯度。优化过程将继续进行,直到达到最大训练步长或Diff值低于阈值。
2.3 秘密隐藏与提取
秘密数据隐藏在优化后的潜变量二值化序列中,如图2和图3所示。采用IEEE 754标准进行基数变换,将Z的每个浮点数编码为32位二进制序列:
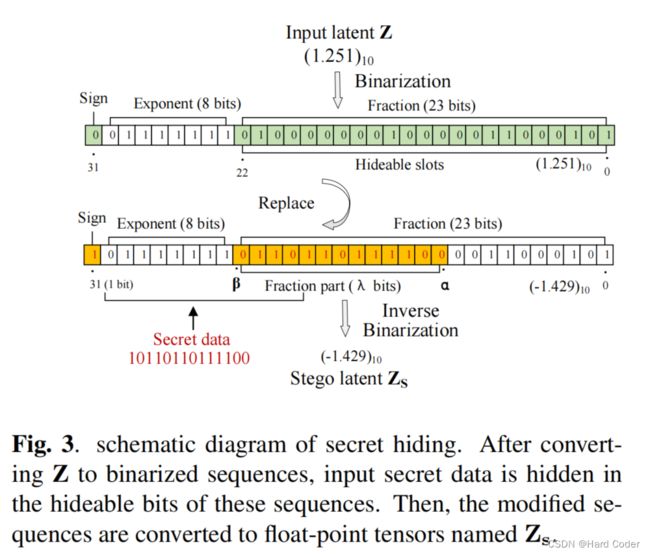
图3 秘密隐藏示意图。在将Z转换为二值化序列之后,输入的秘密数据隐藏在这些序列的可隐藏位中。然后,将修改后的序列转换为称为Zs的浮点张量

这里,(n)10表示十进制浮点数。sign是取值为0或1的符号位。(exponent)10表示十进制指数乘数,在我们的方案中通常等于125、126或127。(fraction)10表示浮点数的小数部分。然后,将sign位、(exponent)10和(fraction)10的值依次转换为二进制数,形成32位二进制序列。
详细的数据隐藏过程如图3所示。首先,使用公式4中定义的函数将Z的所有浮点数编码为32位二进制序列。除了对图像质量影响较大的指数位外,这些二值化序列的符号位和小数部分(第0 ~ 22位)可以用来隐藏秘密数据,称为可隐藏位。其中,只有分数部分的αth ~ βth(0≤α≤β≤22,[α: β])位进行数据隐藏。在我们的方案中,我们改变α的值来传递不同的秘密有效载荷,β固定为22。然后将包含秘密数据的修改序列再次转换为浮点数,然后重构为隐写潜变量z。
我们可以逆数据隐藏过程来提取秘密数据。首先,将接收到的隐写图像发送到Glow模型中,恢复隐写潜变量;然后,将恢复的隐写潜变量Z*s转换为二值序列。最后,可以从这些序列的Sign位和[α:β]位中检索隐藏的秘密数据。综上所述,秘密数据的隐藏和提取过程可以描述为:

式中,bin(·)表示将潜变量张量中的浮点数转换为二进制序列。Secret是输入的秘密数据,它隐藏在bin(Z)的Sign位和α - β位中,即[S,α:β]。Secret 是从bin(Zs)的相同位置检索到的提取的秘密数据。
三、实现细节
我们的方案是在带有4个Nvidia 1080Ti的CentOS 7上使用PyTorch实现的。CelebA[14]用于评估我们的模型的性能。Adam是优化器,学习率是1e-3。训练Glow模型生成L = 5的128×128图像。公式3中的参数“ε”设置为1e-3, 公式2中的n设置为3,算法1设置为3。算法1中的thresh设置为0.1,max-step设置为100。
在隐写术中,bpp是用来衡量隐写图像有效载荷的度量,bpp = len(Secret)/( H×W)。这里,bpp表示每个像素携带的秘密比特数(比特每像素),len(·)表示隐藏的秘密数据的长度,H/W为隐写图像的高度/宽度。Acc用于度量秘密数据的提取精度:Acc = secret∗⊙Secret/(len(secret));这里,secret∗和secret分别表示提取的和输入的秘密数据。⊙表示XNOR操作。隐写安全性用度量PE来评价,定义为:PE = minPFA 1/2 (PFA + PMD);其中,PFA和PMD分别为隐写图像的虚警率和漏检率。PE范围为[0,1.0], PE的最优值为0.5。此时,隐写分析器无法区分图像的来源,只能随机猜测。预训练的Resnet50作为质量评估器。它是在20k张CelebA的真实图像和20k张Glow的生成图像上进行训练的。原始未修改的Z生成的图像称为明文图像,其中没有隐藏秘密数据。隐写潜变量Zs生成的图像称为隐写图像,隐写图像中包含了秘密数据。
论文地址:Generative Steganographic Flow
没有公布源码