(2023|CVPR,Spider GAN 及其级联,SID)Spider GAN:利用友好邻居加速 GAN 训练
Spider GAN: Leveraging Friendly Neighbors to Accelerate GAN Training
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. Spider GAN
2.1. 我们的贡献
2.2. 相关工作
3. 友好邻里在哪里?
3.1. SID
4. 实验
5. 级联 Spider GAN
0. 摘要
稳定地训练生成对抗网络(GAN)是一项具有挑战性的任务。在 GAN 中,生成器将通常服从高斯分布的噪声向量转换为逼真的数据,如图像。在本文中,我们提出了一种新颖的方法,用图像作为输入来训练 GAN,但不强制执行任何成对约束。其直觉是图像比噪音更有结构,生成器可以利用这一点来学习更强大的转换。通过识别密切相关的数据集或目标分布的 “友好邻域” 来使该过程更加高效,这启发了 Spider GAN。为了定义通过数据集之间的接近性来利用友好邻域,我们提出了一种新的度量称为有符号 Inception 距离(signed inception distance,SID),灵感来自多谐核(polyharmonic kernel)。我们展示了 Spider GAN 导致更快的收敛,因为生成器甚至可以发现看似不相关的数据集之间的对应关系,例如在 Tiny-ImageNet 和 CelebA faces 之间。此外,我们展示了级联 Spider GAN,其中来自预训练 GAN 生成器的输出分布被用作后续网络的输入。有效地以级联的方式将一个分布传输到另一个,直到学到目标 - 这是一种新的迁移学习方式。我们展示了 Spider 方法在 DCGAN、conditional GAN、PGGAN、StyleGAN2 和 StyleGAN3 上的有效性。所提出的方法在高分辨率小数据集(如 MetFaces、Ukiyo-E Faces 和 AFHQ-Cats)上相较于其基线对照,在五分之一的训练迭代次数内实现了最先进的 Fréchet Inception 距离(FID)值。
基于 DCGAN 的代码:https://github.com/DarthSid95/SpiderDCGAN
基于 StyleGAN 的代码:https://github.com/DarthSid95/SpiderStyleGAN
基于 Clean-FID 的 SID 的一种实现框架:https://github.com/DarthSid95/clean-sid
2. Spider GAN
我们提出了 Spider GAN 的构想,灵感来自数据的低维不连续流形结构 [12, 31–33]。Spider GAN位于传统 GAN 和图像翻译 GAN 之间的交叉点。与优化潜在参数先验相反,我们假设为生成器提供与图像源数据集密切相关的数据集(被称为友好邻域,导致被称为 Spider GAN 的名字)将导致 GAN 的卓越收敛。与图像翻译任务不同,Spider GAN 生成器对单个输入图像特征不可知,并允许发现从源分布到目标的映射中的隐含结构。图 1 描述了 Spider GAN 的设计理念与传统 GAN 训练方法的对比。
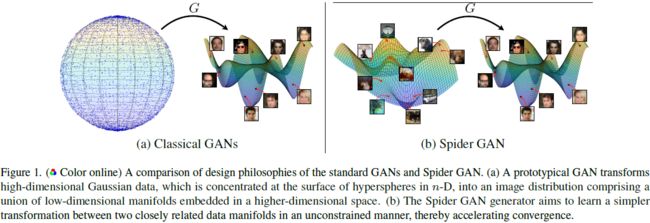
选择输入数据集会影响生成器学习稳定和准确映射的能力。直观地说,如果 GAN 必须被训练以学习街景房屋号码(street view house numbers,SVHN)[34] 的分布,那么 MNIST [35] 数据集对于输入空间的初始化就比标准密度如均匀或高斯更好。众所周知,对于给定的均值和方差,高斯具有最大熵,而对于给定的支持(比如,在重新归一化图像时为 [-1; 1]),均匀分布具有最大熵 [36]。然而,图像数据集具有高度结构化的特性,熵较低 [37]。因此,可以将使用 GAN 进行图像的生成建模解释为有效的熵最小化。 我们认为选择与目标结构更接近的低熵输入分布将导致更高效的生成器转换,从而加速训练过程。现有的图像翻译方法旨在保持语义信息,例如将 MNIST 数据集中数字 “2” 的特定实例翻译成 SVHN 风格。然而,Spider GAN 的构想既不强制也不需要这样的约束。相反,它允许在源数据集中使用隐含结构来高效地学习目标。例如,由于结构相似性,Fashion-MNIST [38] 中的裤子类完全可以映射到 MNIST 中的数字 “1”。因此,Spider GAN 的范围远比图像翻译广泛。
2.1. 我们的贡献
在第 3 节中,我们讨论了 Spider GAN 的中心关注点: 定义什么构成了友好邻里。初步实验表明,虽然 Fréchet inception distance(FID)[39] 和 kernel inception distance (KID) [40] 能够捕捉视觉相似性,但它们无法量化底层流形中样本的多样性。因此,我们提出了一种新的距离度量来评估 GAN 的输入,这一度量受静电势场和目标数据样本(带正电荷)与生成器样本(带负电荷)之间的电中和的启发 [41,42],名为 signed inception distance(SID)。
2.2. 相关工作
思想上,级联 Spider GAN 生成器的理念与 GAN 的迁移学习中的输入优化并行进行,例如 Mine GAN [60],其中实施了挖掘网络,非线性地转换 GAN 的输入分布,以更好地学习目标样本。Kerras 等人 [53] 表明,迁移学习提高了 GAN 在小数据集上的性能,并经验性地观察到,将从在视觉上多样的数据上训练的模型的权重转移至目标模型导致了更好的性能。
3. 友好邻里在哪里?
我们现在考虑在 Spider GAN 中用于识别友好邻里/源数据集的各种数据集之间的距离度量。虽然最直接的方法是比较流形的内在维度,但这些方法要么计算密集 [61],要么不随样本大小扩展 [56, 58]。我们观察到,通过这种方法检测到的友好邻居在实验中没有很好地相关,因此,我们将有关这些方法的讨论推迟到附录 A。
基于 Wang 等人 [62] 提倡的方法,用于识别用于迁移学习的预训练 GAN 网络,我们最初考虑使用 FID 和 KID 来识别友好邻居。我们使用 FID 来测量源(生成器输入)和目标数据分布之间的距离。具有较低 FID 的源更接近目标,并将作为生成器的更好输入。
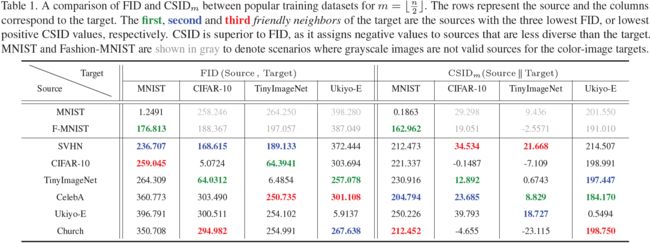
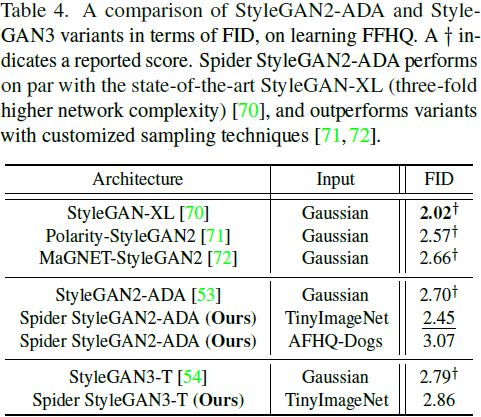
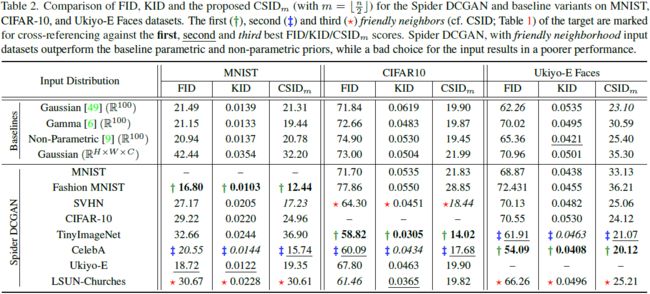
表 1 的前四列显示了我们在本文中考虑的标准数据集之间的 FID 分数。目标数据集的 first(绿),second(蓝) 和 third(红) 个友好邻居(颜色编码)是具有最低三个 FID 的源数据集。
从表 1 中观察到,一个限制是数据集自身的 FID 并不总是为零,这对于距离度量来说是违反直觉的。在 CIFAR-10 或 Tiny-ImageNet 等情况下,这表明数据集的可变性,而在 Ukiyo-E Faces 中,这是由于数据样本有限的可用性,这已被证明对 FID 估计产生负面影响 [40, 63]。FID 满足互易性,即它将数据集标识为相互靠近,例如 CIFAR-10 和 Tiny-ImageNet。然而,使用 FID 来识别友好邻居进行 Spider GAN 训练的初步实验表明,数据集之间的相对多样性未被捕捉到。在给定源的情况下,学习较不多样的目标分布更容易(参见第 4 节和附录 D.2)。这些问题类似于 Kerras 等人在权重转移背景下 [53] 所做的观察。这可以通过一个例子来理解 - 拟合具有 10 个模式的多模态目标高斯分布将比具有 5 个模式的源分布更容易。
3.1. SID
考虑到上述 FID 的限制,我们提出一种用于测量两个分布之间接近程度的新型有符号距离(signed distance)。这个距离是 “有符号的”,因为它还可以取负值。此外,它不是对称的。由于它是根据从分布中抽取的样本来表达的,所以这个距离的计算也是实用的。该提议的距离灵感来自 GAN 的改进的 precision-recall 分数 [64] 以及 Coulomb GANs [41] 和 Poly-LSGAN [42] 中的电势场解释。考虑从分布 μ_p 和 μ_q 抽取的样本批次,分别表示为
![]()
![]()
给定一个测试向量 x ∈ R^n,考虑 Coulomb GAN 鉴别器 [41]:
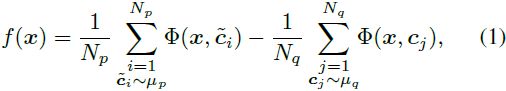
其中 Φ 是 polyharmonic 核 [42, 65]:

并且 k_(m,n) 是一个正常数,根据阶数 m 和维度 n 给定。更高阶的泛化使我们在计算中更具灵活性和数值稳定性。我们使用 m = ⌊n/2⌋ 作为一个稳定的选择,关于选择 m 的消融研究在附录 B.4 中给出。
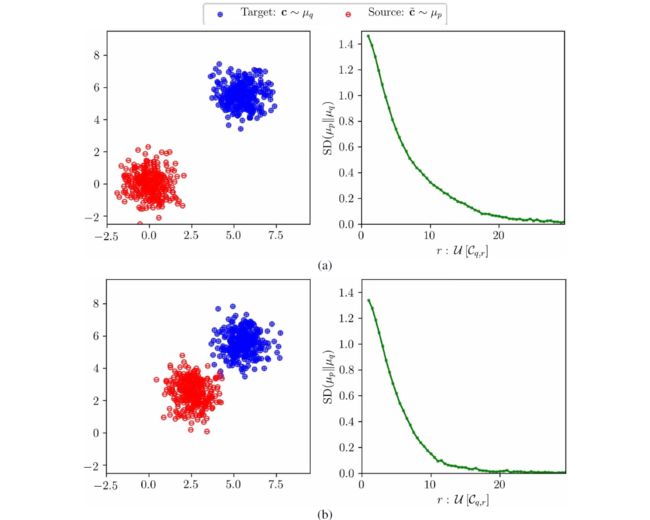
从电荷静电学的角度来看,对于 μ_p = p_g 和 μ_q = p_d,方程 (1) 中的 f(x) 将目标数据视为负电荷,将生成器样本视为正电荷。 μ_p 在逼近/匹配 μ_q 的质量可以通过计算目标 μ_q 周围任选体积上净电荷对测试电荷 x 的影响来衡量。考虑以 μ_q 为中心、边长为 r 的超立方体 C_(q,r),其中包含测试电荷
![]()
为了分析 C_(q,r) 中目标和生成样本的平均行为,我们在 C_(q,r) 内均匀抽取 x。为简单起见,我们取 N_p = N_q = N。我们现在定义从 μ_q 到 μ_p 的有符号距离为 f(x) 的负数,由在 C_(q,r) 上均匀采样的点的和给出,即 SD_(m,r)(μ_p||μ_q),
![]()
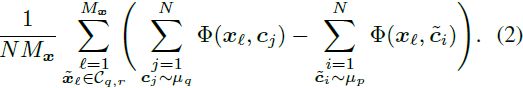
类似于改进的精度和召回(improved precision and recall,IPR)度量,SD_(m,r)(μ_p||μ_q) 是非对称的,即 SD_(m,r)(μ_p||μ_q) ≠ SD_(m,r)(μ_q||μ_p)。当 SD_(m,r)(μ_p||μ_q) < 0 时,平均而言,从 μ_q 中抽取的样本相对于从 μ_p 中抽取的样本更分散,反之亦然。当 μ_p = μ_q 时,有 SD_(m,r)(μ_p||μ_q) ≈ 0。
在实践中,类似于标准 GAN 度量,可以通过在由预训练的 InceptionV3 [66] 网络映射 φ(c) 学到的图像的特征空间上评估度量来使 SD 的计算在更高分辨率的图像上变得实用和高效。这导致了 SD_(m,r)(μ_p||μ_q),如下:
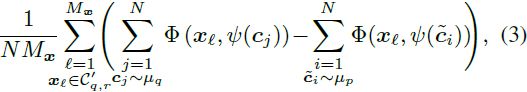
其中 C'_(q,r) 表示以变换后的分布 φ(μ_q) 为中心的边长为 r 的超立方体。首先,我们找到 σ_q = max{diag(Σ_q)},其中 Σ_q 是 D_q 中样本的协方差矩阵。我们将超立方体 C'_(q,r) 定义为沿每个维度具有边长 r = μ_q,并以 μ_q 的均值为中心。为了比较两个数据集,我们绘制 SD_(m,r)(μ_p||μ_q) 作为 r 的函数,其中 r 在 [σ_q; 100σ_q] 变化的步长为 0.5。
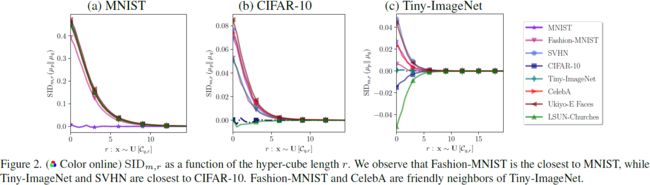
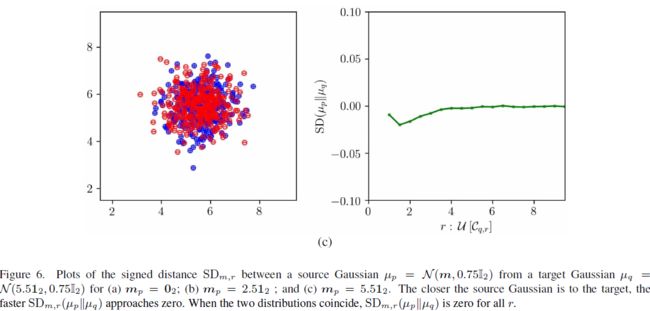
对于一些代表性的目标数据集,SID 的比较图在图 2 中给出。我们观察到,当两个数据集密切相关时,即使对于小的 r,SID 也接近零。比目标数据集多样性较低的数据集具有负的 SID,反之亦然。为了将 SID 量化为单一数字(类似于 FID 和 KID),我们考虑在所有半径 r 上累积的 SID(简称 CSID)给定为:
![]()
表 1 的最后四列呈现了对于不同考虑的数据集的 m = ⌊n/2⌋ 的 CSID。我们观察到当源数据比目标数据更多样化时,CSID 与 FID 高度相关,而当源数据缺乏多样性时,它能够找出 FID 无法找到的源数据。这些结果在跨数据集进行迁移学习时验证了经验上观察到的紧密关系 [53]。关于 SID 的额外实验和消融研究在附录 A 和 B 中给出。
选择最友好的邻居:虽然各种比较数据集的方法通常提出不同的友好邻居,但我们观察到总体趋势在这些度量中是一致的。例如,Tiny-ImageNet 和 CelebA 一直是多个数据集的友好邻居。我们在第 4 节和第 5 节中展示,选择这些数据集作为输入确实改善了 GAN 训练算法。无论是提出的 SID还是基准的 FID/KID 度量,它们都是相对的,因为它们只能衡量提供的候选数据集之间的接近程度。结合领域意识有助于选择适当的输入数据集,可以在其中比较 SID。例如,所有的度量标识Fashion-MNIST 作为与彩色图像目标友好的邻居,尽管如预期的那样,在实践中性能不佳(参见第 4 节)。因此,在识别彩色图像数据集的友好邻居时,可以舍弃 MNIST 和 Fashion-MNIST。虽然 SID 在识别较少多样性的源数据集方面优于 FID 和 KID,但在所有现实世界场景中,没有一种单一方法总能找到最佳数据集。一种实用的策略是在目标和在视觉/结构上相似的数据集之间计算各种相似性度量,并通过投票来确定最接近的数据集。
4. 实验

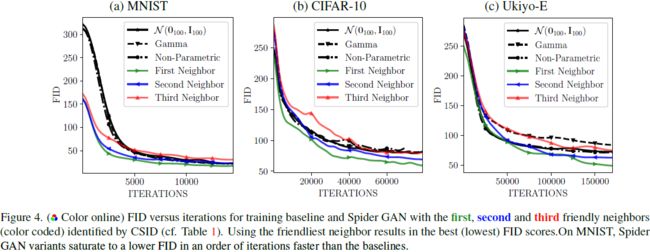
5. 级联 Spider GAN
在第 4 节中使用的 DCGAN 架构在生成高分辨率图像方面不具有良好的可扩展性。虽然使用图像数据集进行训练已经被证明可以提高生成图像的质量,但这种改进伴随着额外的内存需求。标准 GAN 的推断需要纯粹从随机数生成器中抽取的输入,而 Spider DCGAN 需要存储额外的数据集作为输入。为了克服这个限制,我们提出了一种新颖的级联方法,其中公开可用的预训练生成器的输出分布被用作后续 Spider GAN 阶段的输入分布。其好处有四点:首先,内存需求显著降低(大致降低一个或两个数量级),因为只需要存储输入阶段生成器网络的权重。其次,克服了输入分布中有限随机性的问题,因为可以抽取无数独特的输入样本。第三,网络可以在不同的架构和风格之间级联,例如,可以使用一个在 CIFAR-10 上训练的 BigGAN 来训练一个在 ImageNet 上的 Spider StyleGAN 网络,反之亦然。基本上,没有一个预训练的 GAN 被遗漏。最后,级联的 Spider GAN 可以与现有的迁移学习方法结合使用,进一步提高小数据集上生成器的性能 [53]。