LLM | 一些开源的AI代码生成模型调研及总结【20240130更新】
本文主要介绍主流代码生成模型,总结了基于代码生成的开源大语言模型,按照时间顺序排列。
在了解代码大语言模型之前,需要了解代码相关子任务
- 代码生成
- 文本生成代码(Text to code):根据自然语言描述生成代码
- 重构代码(Refactoring code):在不改变其功能的情况下更改源代码的结构,通常是为了使其更加高效、可读且易于维护。
- 代码到代码的翻译(Code-to-code):将一种编程语言编写的代码转换为另一种同功能编程语言的过程。 此过程也称为代码转换、转译、代码迁移或源到源翻译。
概述
| Data |
Model |
Comment |
| 2020 |
CodeBERT |
Enhancing the capability of source code understanding and generation through pre-training and fine-tuning. |
| 2021 |
CodeX |
It designed to advance source code understanding and generation through pre-training on diverse programming tasks. |
| 2023 |
Codegen2 |
CodeGen2 supports code infilling and extends its compatibility to a wider range of programming languages. |
| 2023 |
Codet5+ |
The CodeT5+ demonstrates improved effectiveness in instruction fine-tuning to better align the model with natural language instructions. |
| 2023 |
StarCoder |
Capable of generating code snippets to implement a method or complete a line of code. |
| 2023.8.24 |
Code Llama |
Based on LLMA2 |
| 2023 |
DeepSeekCoder |
Based on CodeLlama |
- CodeBERT是在2020年提出的一个大型语言模型,旨在通过预训练和微调的方式,增强源代码理解和生成的能力。
- CodeX是在2021年推出的大型语言模型,通过在多样的编程任务上进行预训练,旨在提升源代码理解和生成的能力。
- CodeGen2可以进行infilling,并且支持更多的编程语言。这里的infilling应该是在插入代码的含义。
- CodeT5 + 在指令调优上的效果,以更好地使模型与自然语言指令保持一致。
- StarCoder是BigCode基于GitHub数据训练的一个代码补全大模型。可以实现一个方法或者补全一行代码。
2020.09.18_CodeBERT
论文地址:2002.08155.pdf (arxiv.org)
-
Dataset
- Stackdataset:Github code repositories(Python, Java,JavaScript, PHP, Ruby, and Go)
-
Model Arc
Natural Language(NL),Programming Language(PL)
Objective 1:Masked Language Modeling(MLM)
Objective 2:Replaced Token Detection(RTD)
CodeSearchNet
-
Code to NL
-
CodeSearch
-
2021_CodeX [未开源]
OpenAI → CodeX [paper]
Key features(model)
- Code-davinci-002 -> Max tokens 4000
- code-cushman-001->Max tokens 2048
Programming languages
- Python ,Javascript,Bash,c#...
Search Code Net
2022.02_AlphaCode
Transformer(seq2seq)
论文题目:Competition-Level Code Generation with AlphaCode
论文地址:2203.07814.pdf (arxiv.org)
代码地址:
Demo:AlphaCode (deepmind.com)

Demo
2022_Polyglot
论文题目:Polyglot: Large Language Models of Well-balanced Competence in Multi-languages
代码地址:EleutherAI/polyglot: Polyglot: Large Language Models of Well-balanced Competence in Multi-languages (github.com)
相关论文
论文题目:PolyLM: An Open Source Polyglot Large Language Model
论文地址:2307.06018.pdf (arxiv.org)
2023.01.27_PAL
论文题目:PAL: Program-aided Language Models
论文地址:[2211.10435] PAL: Program-aided Language Models (arxiv.org)
论文主要内容: 让Code LLM生成代码来解决一些NLP问题!!
摘要
大型语言模型 (LLM) 最近在测试时提供了一些示例(“小样本提示”),展示了执行算术和符号推理任务的令人印象深刻的能力。这种成功很大程度上可以归因于诸如“思维链”之类的提示方法,这些方法使用LLM来理解问题描述,将其分解为步骤,以及解决问题的每个步骤。虽然 LLM 似乎擅长这种逐步分解,但 LLM 经常在解决方案部分犯逻辑和算术错误,即使问题被正确分解。在本文中,我们提出了程序辅助语言模型(PAL):一种新颖的方法,它使用LLM来读取自然语言问题并生成程序作为中间推理步骤,但将求解步骤卸载到运行时,例如Python解释器。在PAL中,将自然语言问题分解为可运行的步骤仍然是LLM的唯一学习任务,而求解则委托给解释器。我们在 BIG-Bench Hard 和其他基准测试的 13 个数学、符号和算法推理任务中展示了神经 LLM 和符号解释器之间的这种协同作用。在所有这些自然语言推理任务中,使用 LLM 生成代码并使用 Python 解释器进行推理会产生比大型模型更准确的结果。例如,使用 Codex 的 PAL 在数学单词问题的 GSM8K 基准测试中实现了最先进的少样本精度,超过了使用思维链的 PaLM-540B,绝对是 15% 的 top-1。我们的代码和数据在此 http URL 上公开提供。
与使用自由格式文本的 CoT 不同,PAL 将解决方案步骤卸载到编程运行时,例如 python 解释器。

2023_Codegen2
Salesforce→ Codegen2 [paper]
2023_Codet5+
Salesforce→ Codet5+ [paper][code]
模型框架(Model Architecture)
方法(Method)
- Span Denoising
- Causal Language Modeling (CLM)
- Text-Code Contrastive Learning
- Text-Code Matching
- Text-Code Causal LM
2023_SELF-DEBUGGING
Google→ SELF-DEBUGGING
[paper]
2023_StarCoder
HuggingFace→ StarCoder [paper]
15.5B LLM for code with 8k context and trained only on permissive data in 80+ programming languages:
- Decoder-only Transformer with Fillin-the Middle,Multi-Query-Attention,and leaned absolute position embeddings.
Pretrainmodel Size : 64GB → BigCode OpenRAIL-M v1
VSCode Extension
2023.7.18_LLAMA2
Meta→ 2023_LLAMA2
2023.7_CodeGeeX2
2023.8.8_StableCode
Announcing StableCode — Stability AI
stabilityai/stablecode-instruct-alpha-3b · Hugging Face
Based on Bigcode,
Instruction and response
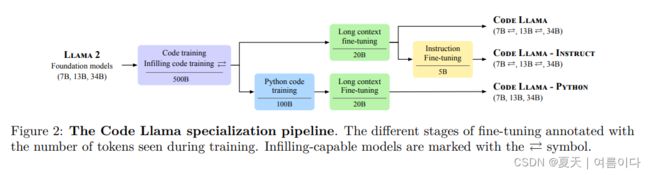
2023.8.24_Code Llama
论文题目:Code Llama: Open Foundation Models for Code
论文地址:[2308.12950] Code Llama: Open Foundation Models for Code (arxiv.org)
代码地址:GitHub - facebookresearch/codellama: Inference code for CodeLlama models
官方博客:Code Llama: Llama 2 learns to code (huggingface.co)
code llama就是在llama2模型的基础上,利用代码数据进行训练和微调,提高llama2在代码生成上的能力。
code llama提供了三种模型,每种模型包含7B,13B,34B三个尺寸,支持多种编程语言,如Python, C++, Java, PHP, Typescript (Javascript), C#, Bash等。
- Code Llama,代码生成的基础模型;
- Code Llama-Python,单独针对于python的模型;
- Code Llama-Instruct,根据人工指令微调的模型。
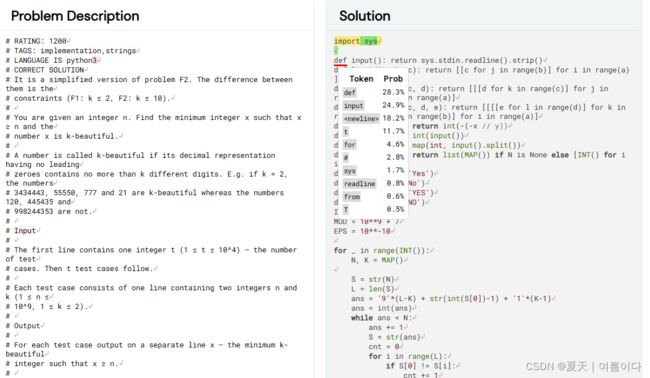
主要讲解论文对应段落
2.3.代码补全(Infilling)
代码补全就是根据代码的上下文预测代码缺失的部分,比如在IDE中,对鼠标位置的代码自动完成,文档自动生成等。
将训练的文本序列一部分移动到结尾,然后自回归重新排序进行训练。
参考【9】将文本分成
PSM:即prefix,suffix,middle的顺序,结构如下图:
![]()
SPM:即suffix,prefix,middle的顺序,如下
○Enc(prefix)○
训练时样本一半按PSM格式,一半按SPM格式。
2.4.微调长上下文(long context fine-tuning (LCFT))
从llama2的4096token输入改为16384token输入
为了将训练成本限制在微调,参考RoPE线性插值的思路,只不过这里没有采用插值,而是修改注意力的衰减周期。
2.5.策略微调(Instruction fine-tuning)
对于指令微调,最重要的还是构建更好的数据集。
- 专有数据集(Proprietary dataset)
- 指令数据集(self-instruct dataset)
2023.08.27_WizardCoder
Microsoft→WizardCoder [paper] [code]
代码地址:https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
Demo:WizardCoder-Python-34B-V1.0
-
WizardLM(WizardLM: An Instruction-following LLM Using Evol-Instruct)
-
Evol-Instruct
- Instruction Evolver :
- Instruction Eliminator
(Focuses on open-domain instruction data)
-
-
Fine-tune Starcoder-15B based on WizardLM
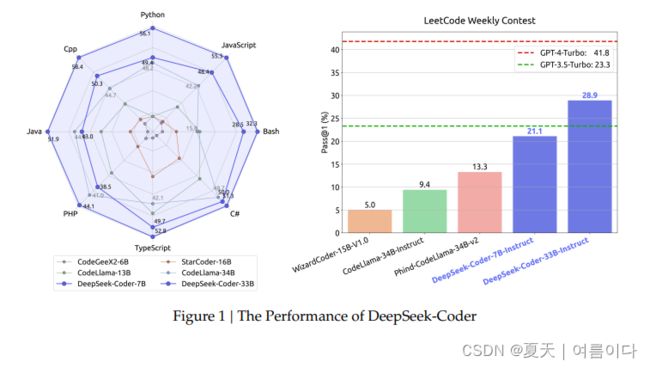
2024.1.25_DeepSeekCoder
论文:[2401.14196] DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence (arxiv.org)
Demo:DeepSeek Coder
DeepSeek-Coder是开源代码模型,大小从 1.3B 到 33B 不等,在 2 万亿个token上从头开始训练。这些模型在高质量的项目级代码语料库上进行了预训练,并采用具有 16K 窗口的填空任务来增强代码生成和填充。论文表明,DeepSeek-Coder 不仅在多个基准测试的开源代码模型中实现了最先进的性能,而且还超越了现有的闭源模型,如 Codex 和 GPT-3.5。
参考文献
【1】 【llm大语言模型】code llama详解与应用 - 知乎 (zhihu.com)
【2】浅谈LLM的长度外推 - 知乎 (zhihu.com)
【3】LLMs之Code:Code Llama的简介(衍生模型如Phind-CodeLlama/WizardCoder)、安装、使用方法之详细攻略-CSDN博客 【4】chinese-llama-plus-lora-13b - LLM Explorer (extractum.io)
【5】论文翻译PAL: Program-aided Language Models - 简书 (jianshu.com)
【6】大语言模型(LLM)论文调研整理3 - 知乎 (zhihu.com)
其他语言
【7】POLYGLOT-KO 다운로드 및 예제. KoAlpaca과 합작해 만든 LLM모델이라고 한다. | by Lyan | Medium
【8】 Big Code Models Leaderboard - a Hugging Face Space by bigcode
【9】2207.14255.pdf (arxiv.org)
【10】【llm大语言模型】一文看懂llama2(原理,模型,训练) - 知乎 (zhihu.com)