Java new I/O(NIO)--non-blocking I/O初探
这篇博客翻译自如下的链接,如有纰漏还望指正。
non-block IO
NIO stands for non-blocking IO, 本文作者习惯使用new 代替non,本文依照原文进行翻译,力图完整。
写在开始之前
关于本教程
NIO接续原始的IO在JDK 1.4版本引入,NIO为标准的Java代码提供高速,面向块的IO操作。通过定义承载数据的类,并且以块的形式处理数据,NIO相较于原始IO利用操作系统底层优化的方式,不用使用原生代码。
在本教程,我们将从上层概念的东西到底层编程的细节覆盖NIO的几乎所有方面。除了学习IO的一些关键元素比如buffers和channels,你将有机会明白标准的IO是如何在更新的库里面工作的。并且你会学习到一些只能用NIO才能办到的事情,比如异步IO以及直接缓存(asynchronous IO and direct buffers.).
我们会通过示例代码,来说明NIO库不同方面。几乎所有的代码片段都是你可以再相关话题里面找到的,扩展的Java代码的一部分。随着代码片段的联系,我们鼓励你在自己的机器上下载,编译,运行这些代码。这样在你完成这个教程之后,手头就有完整的代码,可以作为你在NIO编码练习的出发点。
本教程是为所有想希望学习关于JDK1.4 NIO知识的程序员准备的。为了能更好的理解我们接下来讨论的话题,我们希望你有基本的Java编程相关的概念,比如类,继承,以及包的使用,如果对原始的IO(from the java.io.* package)有所了解也会有帮助。
虽然本教程确实需要对Java语言有一定的了解,但它并不需要大量实际的编程经验。除了解释与本教程相关的所有概念之外,我还保持了代码示例的简单和短小。我们的目标是为了解NIO提供一个简单的入口点,即使对于那些没有太多Java编程经验的人也是如此。
如何运行本教程代码
本教程提供的源代码包(相关主题中可用)包含本教程中使用的所有程序。每个程序由单个Java文件组成。每个文件都是通过名称来标识的,并且很容易与它所演示的编程概念相关。
本教程中的一些程序要求运行命令行参数。要从命令行运行一个程序,只需到可用的的命令行提示符工具即可。在Windows下,命令行提示符是“命令”或“command.com”程序。在UNIX下,任何shell都会这样做。(在windows下可以使用git for windows的版本)
你将需要安装JDK 1.4并在你的安装路径中完成本教程中的练习。如果你需要在安装和配置JDK 1.4上需要帮助,请参阅相关主题。
输入/输出:概念概略
NIO介绍
IO——或输入/输出——指的是计算机和人类世界之间的接口,或者是单个程序和计算机的其余部分之间的接口。它是任何计算机系统中非常重要的元素,大部分的输入输出实际上都是在操作系统中构建的。个人代码大部分工作通常是为了IO工作。
在Java编程中,直到最近,输入输出都是使用流的比喻进行的。所有的输入输出都被看作是单个字节的移动,一次一个字节的移动,通过一个叫做流的对象。流输入输出用于与外界联系。它也在内部使用,用于将对象转换成字节,然后返回到对象中。
NIO具有与原始的输入输出相同的角色和目的,但它使用了一个不同的比喻——块IO。正如你将在本教程中学习的那样,块IO可以比流输入输出效率高得多。
为什么使用NIO
创建NIO是为了让Java程序员能够实现高速IO,而无需编写自定义本机代码。 NIO将最耗时的IO活动(即填充缓冲区和排空缓冲区)移回到操作系统中,从而可以大大提高速度。
流vs块(Streams versus blocks)
原始IO库(在java.io. *中找到)和NIO之间最重要的区别在于如何打包和传输数据。如前所述,原始IO处理数据流,而NIO处理数据块。
面向流的IO系统一次处理一个字节的数据。输入流产生一个字节的数据,输出流消耗一个字节的数据。为流数据创建过滤器非常简单。可以将几个功能特定的过滤器连接在一起也是相对简单的,这样可以组成一个单独的、复杂的处理机制。然而另一方面,面向流的IO通常很慢。
面向块的IO系统处理块中的数据。每步操作会产生或消耗一块数据。按块处理数据比用(流)字节处理数据要快得多。但面向块的IO缺乏面向流IO的一些优雅和简单性。
集成IO(Integrated IO)
原始的IO包和NIO已经很好地集成在JDK 1.4中。 java.io. 已经以NIO为基础重新实现,所以它现在可以利用NIO的一些特性。例如,java.io. 包中的某些类包含以块的形式读写数据的方法,从而使很多面向数据流的系统中,数据的处理处读书读变的更快。
也可以使用NIO库来实现标准的IO功能。例如,你可以轻松使用块IO一次移动一个字节的数据。但正如你将看到的那样,NIO还提供了许多原始IO软件包所不具备的优势。
通道和缓冲区(Channels and buffers)
通道和缓冲区预览(Channels and buffers overview)
通道和缓冲区是NIO的中心对象,几乎用于每个IO操作。
通道类似于原始IO包中的流。所有去向别处(或来自任何地方)的数据都必须通过Channel对象。缓冲区本质上是一个容器对象。发送到channel的所有数据必须首先放入缓冲区;同样,从channel读取的任何数据都被读入缓冲区。
在本节中,你将学习如何使用NIO中的通道和缓冲区。
什么是缓冲区?
缓冲区是一个对象,它保存一些要写入或刚刚读取的数据。在NIO中添加Buffer对象是新库和原始IO之间最重要的差异之一。在面向流的IO中,你直接向Stream对象写入数据,并直接从Stream对象读取数据。
在NIO库中,所有数据都是用缓冲区处理的。读取数据时,将直接读入缓冲区。数据写入时,写入缓冲区。任何时候你访问NIO中的数据时,都会将其从缓冲区中取出。
缓冲区本质上是一个数组。通常,它是一个字节数组,但可以使用其他类型的数组。但是缓冲区不仅仅是一个数组。缓冲区提供对数据的结构化访问,并且还记录系统的读/写过程。
各种缓冲区
最常用的缓冲区是ByteBuffer。 ByteBuffer允许在其底层字节数组上进行get / set操作(即获取和设置字节)。
ByteBuffer不是NIO中唯一的缓冲区类型。实际上,每种基本Java类型都有一个缓冲区类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
每个Buffer类都是Buffer接口的一个实例。除ByteBuffer之外,都有完全相同的操作,仅在处理数据类型方面有所不同。由于ByteBuffer用于大多数标准IO操作,因此它除了具有所有共享缓冲区操作以外还有一些独特的操作。
你现在可能需要花点时间运行UseFloatBuffer.java,其中包含一个实例类型化缓冲区的小例子。
Channel是什么?
通道是一个对象,你可以从中读取数据并向其写入数据。比较NIO和原始IO,一个通道就像一个流。
如前所述,所有数据都是通过Buffer对象处理的。从不直接写一个字节到一个通道;而是写入包含一个或多个字节的缓冲区。同样,你不直接从一个通道读取一个字节;而是从通道读入缓冲区,然后从缓冲区获取字节。
channel的种类
通道与流是不同的,因为它是双向的。尽管数据流只能在一个方向上传输(数据流必须是InputStream或OutputStream的子类),但可以打开一个Channel来读取数据,写入数据或为两者兼而有之。
由于它们是双向的,因此通道比流处理更能反映底层操作系统的实际情况。特别是在UNIX模式中,底层操作系统通道是双向的。
从理论到实践:NIO的读写
NIO预览
读写是IO的基本过程。从通道读取很简单:我们只需创建一个缓冲区,然后让一个通道将读取数据写入到换从曲。写入也很简单:我们创建一个缓冲区,填充数据,然后请求一个通道把缓冲区中的数据写出。
在本节中,我们将学习一些关于在Java程序中读写数据的知识。我们将介绍NIO的主要组件(缓冲区,通道和一些相关方法),并了解它们如何在进行读取和写入上是如何交互的。在接下来的部分中,我们将更详细地研究这些组件并使用这些组件。
读取文件
对于我们的第一个练习,我们将从文件中读取一些数据。如果我们使用原始IO,我们只需创建一个FileInputStream并从中读取。然而,在NIO中,情况有点不同:我们首先从FileInputStream中获取Channel对象,然后使用该通道读取数据。
在NIO系统中执行读取操作时,都是从channel读取的,但不直接从channel读取。由于所有数据最终都驻留在缓冲区中,因此可以从通道读入缓冲区。
因此从一个文件读取涉及三个步骤:
- 从FileInputStream获取Channel;
- 创建缓冲区;
- 从通道读入缓冲区。
现在,让我们看看这是如何工作的。
简单三步
我们的第一步是获得一个渠道。我们从FileInputStream获得通道:
FileInputStream fin = new FileInputStream( "readandshow.txt" );
FileChannel fc = fin.getChannel();下一步是创建一个缓冲区:
ByteBuffer buffer = ByteBuffer.allocate( 1024 );最后,我们需要从通道读入缓冲区,如下所示:
fc.read( buffer );你会注意到,我们不需要告诉该通道需要多少读入到缓冲区。每个缓冲区都有一个复杂的内部记录系统,可以记录有多少数据被读取,以及有多少空间可以存储更多数据。我们将在缓冲区内部概述中详细讨论缓冲区记录系统。
写文件
在NIO中写入文件与读取文件类似。我们首先从FileOutputStream获取一个通道:
FileOutputStream fout = new FileOutputStream( "writesomebytes.txt" );
FileChannel fc = fout.getChannel();下一步是创建一个缓冲区并在其中放入一些数据 - 在这个示例中,数据将从一个名为message的数组中获取,该数组包含字符串“Some bytes”的ASCII字节。 (buffer.flip()和buffer.put()调用将在本教程稍后介绍。)
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
for (int i=0; i<message.length; ++i) {
buffer.put( message[i] );
}
buffer.flip();我们的最后一步是写入缓冲区到通道:
fc.write( buffer );我们再次注意到不需要告诉通道我们想写多少数据。缓冲区的内部记录系统会跟踪其包含的数据量以及需要写入多少数据。
同时读写
接下来将看到当我们将写入和读取结合起来时会发生什么。我们将以一个名为CopyFile.java的简单程序为基础,将所有数据从一个文件复制到另一个文件。 CopyFile.java执行三个基本操作:首先创建一个Buffer,然后将源文件中的数据读入该缓冲区,然后将缓冲区写入目标文件。程序重复 – 读,写,读,写 - 直到源文件处理完毕。
CopyFile程序将让你看到我们如何检查操作的状态,以及我们如何使用clear方法来重置缓冲区和flip方法并使其准备将新读取的数据写入另一个通道。
运行CopyFile示例
由于缓冲区跟踪自己的数据,因此CopyFile程序的内部循环非常简单,如下所示:
fcin.read( buffer );
fcout.write( buffer );第一行从输入通道fcin读取数据到缓冲区,第二行将数据写入输出通道fcout。
检查状态
我们的下一步是检查我们完成复制的时间。当没有更多的数据可以读取时我们就完成了,在read方法返回-1时表示数据读取操作完成,如下所示:
int r = fcin.read( buffer );
if (r==-1) {
break;
}重置缓冲区
最后,我们在从输入通道读入缓冲区之前调用clear方法。同样,我们在向输出通道写入缓冲区之前调用flip方法,如下所示:
buffer.clear();
int r = fcin.read( buffer );
if (r==-1) {
break;
}
buffer.flip();
fcout.write( buffer );clear方法重置缓冲区,使其准备好读取数据。 flip方法使缓冲区准备将新读取的数据写入另一个通道。
缓冲区内部
缓冲区内部概述
在本节中,我们将看看NIO中缓冲区的两个重要组成部分:状态变量和访问器方法。
状态变量是上一节提到的“内部记录制度”的关键。每次读/写操作时,缓冲区的状态都会改变。通过记录和跟踪这些更改,缓冲区可以在内部管理自己的资源。
当你从通道读取数据时,数据将被放置在缓冲区中。在某些情况下,可以将此缓冲区直接写入另一个通道,但通常需要查看数据本身。这可以通过使用访问器方法get完成。同样,当你想把原始数据放入缓冲区时,可以使用访问器方法put。
在本节中,你将学习NIO中的状态变量和访问器方法。将描述每个组件,然后你将有机会看到它的实际操作。虽然NIO的内部记录系统起初看起来很复杂,但你很快会发现大部分实际工作都已经为你完成了。之前可能习惯手动编码部分 – 使用字节数组和索引变量 - 在NIO内部会自动处理。
状态变量
可以使用三个值来指定任何给定时刻缓冲区的状态:
- position
- limit
- capacity
这三个变量一起跟踪缓冲区的状态和它所包含的数据。我们将详细检查每一个,并看看它们如何在典型的读/写(输入/输出)过程中工作的。为了举例方便,我们假设我们正在将数据从输入通道复制到输出通道。
Position
你会记得缓冲区真的只是一个数组的简单封装。从通道读取时,你将读取的数据放入底层数组中。position变量会记录你写入的数据量。更确切地说,它指定下一个字节将写入到数组的位置。因此,如果你已经将三个字节从一个通道读入缓冲区,那么该缓冲区的position将被设置为3,指向该数组的第四个元素。
同样,当写入通道时,你将从缓冲区获取数据。position值会跟踪你从缓冲区获得多少。更确切地说,它指定下一个字节将从哪个数组元素出现。因此,如果你已经从一个缓冲区写入了5个字节到一个通道,那么这个缓冲区的位置将被设置为5,指向该数组的第六个元素。
Limit
limit变量指定剩余的数据量(在从缓冲区写入通道的情况下)或剩余多少空间可以放入数据(在从通道读入缓冲区的情况下) 。
position总是小于或等于limit变量。
Capacity
缓冲区的capacity指定可以存储在其中的最大数据量。实际上,它指定了底层数组的大小 - 或者至少指定了我们允许使用的底层数组的大小。
limit永远不会超过capacity。
观察变量的变化
我们将从新创建的缓冲区开始。为了举例便利,我们假设我们的缓冲区总容量为8个字节。缓冲区的状态如下所示:
当前状态如下:

回想一下,limit永远不会大于capacity,并且在这种情况下,这两个值都被设置为8。我们将它们都指向数组的末端(如果存在槽8的情况下8槽位置) :
当前状态如下:

position设置为0.如果我们读取一些数据到缓冲区,下一个字节的读取将进入0号槽。如果我们从缓冲区写出,从缓冲区取得的下一个字节将从0号槽取出。状态如下:
当前状态如下:

首次读入
现在我们准备开始对我们新创建的缓冲区进行读/写操作。我们首先从我们的输入通道读取一些数据到缓冲区。第一次读取得到三个字节。这些被放入数组,从位置开始,该位置被设置为0。在读取之后,位置增加到3,如下所示:
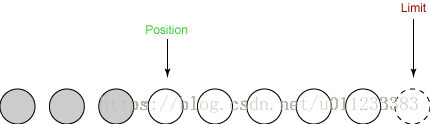
limit变量位置不变
第二次读入
对于我们的第二次读取,我们从输入通道再读取两个字节到我们的缓冲区。这两个字节存储在position指向的位置,position因此增加了两个:
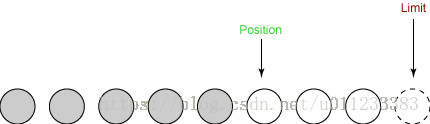
limit变量位置不变
翻转操作(The flip)
现在我们准备将数据写入输出通道。在我们做到这一点之前,我们必须调用flip方法。这个方法做了两件重要的事情:
- 将limit设置为当前position的值。
- 将position设置为0。
前一张图显示了翻转前的缓冲区。后边图是翻转后的缓冲区:

我们现在准备开始将数据从缓冲区写入通道。position 已被设置为0,这意味着我们获得的下一个字节将是第一个字节。这个限制已经被设置为旧的position,这意味着它只包含了我们之前读取的所有字节,而没有更多其他额外的信息。
第一次写出
在第一次写入时,我们从缓冲区中取出四个字节并将它们写入到输出通道。这将position移动到4,并保持limit不变,如下所示:

第二次写出
我们只剩下一个字节来写。当我们使用flip时,limit 设置为5,并且position不能超过limit。所以最后一次写出从缓冲区中取出一个字节并写入输出通道。position变成5,并保持limit 不变,如下所示:

清空操作(clear)
我们的最后一步是调用缓冲区的clear方法。该方法重置缓冲区以准备接收更多字节。清除两件至关重要的事情:
- 设置limit设置为capacity大小。
- 设置position 为0。
下图显示了clear被调用后缓冲区的状态:

缓冲区现在可以准备接收新的数据
访问器方法
到目前为止,我们只使用缓冲区将数据从一个通道移动到另一个通道。但是,你的程序经常需要直接处理数据。例如,你可能想要将用户数据保存到磁盘。在这种情况下,你必须将该数据直接放入缓冲区,然后使用通道将缓冲区写入磁盘。
或者,你可能需要从磁盘读取用户数据。在这种情况下,你可以将数据从通道读入缓冲区,然后使用缓冲区中的数据。
我们将通过使用ByteBuffer类的get和put方法详细了解直接访问缓冲区中的数据。
get方法
在ByteBuffer类里面,有四种get方法:
- byte get();
- ByteBuffer get( byte dst[] );
- ByteBuffer get( byte dst[], int offset, int length );
- byte get( int index );
第一种方法获取单个字节。第二个和第三个方法将一组字节读入一个数组中。第四种方法从缓冲区中的特定位置获取字节。返回ByteBuffer的方法只返回被调用者自己。
另外,我们说前三个get方法是相对方法,而最后一个是绝对方法。相对方法意味着get操作会对应修改limit和position的值– 具体地说,从当前位置读取字节,会在get之后增加position的值。另一方面,绝对方法忽略limit和position的值,并且不影响它们。实际上,它完全绕过缓冲区的记录方法。
上面显示的方法对应于ByteBuffer类。其他类具有等效的get方法,除了不处理字节外,它们处理的是适合该缓冲区类的类型。
put方法
在ByteBuffer类,有五种put方法:
- ByteBuffer put( byte b );
- ByteBuffer put( byte src[] );
- ByteBuffer put( byte src[], int offset, int length );
- ByteBuffer put( ByteBuffer src );
- ByteBuffer put( int index, byte b );
第一种方法存储一个字节。第二个和第三个方法从数组中写入一组字节。第四种方法将来自给定源ByteBuffer的数据复制到此ByteBuffer中。第五种方法将字节放入缓冲区的特定位置。返回ByteBuffer的方法只返回被调用者本身。
与get方法一样,我们将put方法描述为相对或绝对。前四种方法是相对的,而第五种方法是绝对的。
上面显示的方法对应于ByteBuffer类。其他类具有等效的put方法,除了不处理字节外,它们处理适合该缓冲区类的类型。
其他类型的get和put方法
除了前面介绍的get和put方法外,ByteBuffer还具有用于读写不同类型值的额外方法,如下所示:
- getByte()
- getChar()
- getShort()
- getInt()
- getLong()
- getFloat()
- getDouble()
- putByte()
- putChar()
- putShort()
- putInt()
- putLong()
- putFloat()
putDouble()
所有这些方法,都可以分成两类——相对的和绝对的。可以方便的用于读取格式化的二进制数据,比如读取图片文件的头部。
The buffer at work: An inner loop
下边的循环总结了使用buffer从输入通道到输出通道的代码样式。
while (true) {
buffer.clear();
int r = fcin.read( buffer );
if (r==-1) {
break;
}
buffer.flip();
fcout.write( buffer );
}read和write调用由于buffer的使用被大大简化,因为缓冲区处理了许多细节。 clear和flip方法用于在读和写之间切换缓冲区模式。
更多关于缓冲区
缓冲区概述
到目前为止,你已经了解了大部分你需要了解的缓冲区日常使用它们需要的知识。我们的示例并没有超出标准的读/写过程,你可以像在原始IO中轻松在NIO中实现。
在本节中,我们将介绍一些使用缓冲区的更复杂的方面,例如缓冲区分配,包装和切片。我们还将讨论NIO为Java平台带来的一些新功能。你将学习如何创建不同类型的缓冲区以满足不同的目标,例如保护数据免于修改的只读缓冲区和直接映射到底层OS缓冲区的直接缓冲区。我们将通过介绍在NIO中创建内存映射文件来结束该部分。
缓冲区分配和包装
在可以读取或写入之前,您必须有一个缓冲区。要创建缓冲区,必须先分配内存给它。我们使用allocate的静态方法分配一个缓冲区:
ByteBuffer buffer = ByteBuffer.allocate( 1024 );allocate方法分配一个指定大小的底层数组,并将其包装在一个缓冲区对象中 —示例中是一个ByteBuffer。
也可以将已经存在的数组转变成一个缓冲区,如下所示:
byte array[] = new byte[1024];
ByteBuffer buffer = ByteBuffer.wrap( array );在这种情况下,您已经使用wrap方法来围绕数组包装缓冲区。必须非常小心执行此类操作。完成之后,可以通过缓冲区直接访问基础数据。
缓冲切片
slice方法从现有缓冲区中创建一种子缓冲区。也就是说,它会创建一个新的缓冲区,与原始缓冲区的一部分共享其数据。
这可以用一个例子来解释。我们首先创建一个长度为10的ByteBuffer:
ByteBuffer buffer = ByteBuffer.allocate( 10 );我们用数据填充这个缓冲区,把第n个数字放在第n个插槽中:
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}You specify the start and end of the window by setting the position and limit values, and then call the Buffer’s slice() method:
现在我们将对缓冲区进行分片,以创建一个覆盖插槽3到6的子缓冲区。从某种意义上说,子缓冲区就像是一个到原始缓冲区的窗口。
通过设置position和limit 值来指定窗口的开始和结束,然后调用缓冲区的slice方法:
buffer.position( 3 );
buffer.limit( 7 );
ByteBuffer slice = buffer.slice();slice是缓冲区的子缓冲区。但是,子缓冲区和缓冲区共享相同的底层基础数组数据,我们将在下一节中看到。
缓冲区切片和数据共享
我们已经知道一个原始缓冲区的子缓冲区共享相同的底层是数组数据,让我们来看看这是什么意思:
我们遍历子缓冲区,并且修改每一个子缓冲区的元素,为每一个元素自乘11,这种改变意味着,如果一个元素是5,修改之后将变成55.
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get( i );
b *= 11;
slice.put( i, b );
}最后,让我们看看原始缓冲区的内容是什么
buffer.position( 0 );
buffer.limit( buffer.capacity() );
while (buffer.remaining()> 0) {
System.out.println( buffer.get() );
}最后的结果显示,只有出现在子缓冲区中的元素被修改了:
$ java SliceBuffer
0
1
2
33
44
55
66
7
8
9切片缓冲区非常适合抽象。你可以编写你的函数来处理整个缓冲区,如果你发现你想把这个过程应用到一个子缓冲区中,你可以把一个主缓冲区切片并传递给你的函数。这比自己编写函数使用额外的参数获取缓冲区的指定部分更容易。
只读缓冲区
只读缓冲区很简单——只能用来读取数据,不能写入。你可以通过调用buffer的asReadOnlyBuffer方法来将普通的缓冲区变成只读缓冲区,方法执行之后的结果是返回一个和原始缓冲区完全一样(共享数据),但是只读。
只读缓冲区对保护数据很有用。当你传递一个缓冲区到一个对象的的方法,你不可能知道那个方法是不是会修改缓冲区内的数据。创建一个只读的缓冲区能够保证缓冲区自己不会被修改。
不能讲一个只读缓冲区转变成一个可写的缓冲区。
直接和间接buffer
另外一种ByteBuffer的有用类型是直接buffer。直接buffer的内存分配是以一种特殊的方式分配能够加快IO速度。
实际上,直接buffer的定义是和具体实现相关的。Sun的文档有类似的直接buffer说明:
给定一个直接的字节缓冲区,Java虚拟机将尽最大努力直接对它执行本地I O操作。也就是说,它将尝试避免在每次调用某个底层操作系统的本地IO操作之前(或之后)将缓冲区内容复制到(或从)中间缓冲区。
你可以在示例程序FastCopyFile.java中看到直接缓冲区的运行情况,该程序是使用直接缓冲区提高速度的CopyFile.java版本。
还可以使用内存映射文件创建直接缓冲区。
内存映射文件IO(Memory-mapped file I/O)
内存映射文件IO是一种读取和写入文件数据的方法,比普通的基于流或通道的IO速度快得多。
内存映射文件IO是通过使文件中的数据奇迹般地显示为内存数组的内容来完成的。起初,这听起来像是将整个文件读入内存,但实际上并不是这样。通常,只有实际读取或写入的文件部分被引入或映射到内存中。
内存映射并不是很神奇,或者并不常见。现代操作系统通常通过将文件的一部分按需映射到内存的一部分来实现文件系统。如果在底层操作系统中这种特性可用,Java内存映射系统会提供对此特性的访使用。
尽管创建起来相当简单,但是写入内存映射文件可能会很危险。通过更改数组中单个元素的简单操作,可以直接修改磁盘上的文件。修改数据并将其保存到磁盘之间是不可分割的。
映射文件到内存
学习内存映射最简答的方式是通过例子。在下边的例子中,我们映射FileChannel(全部或者部分)到内存中。直接使用FileChannel.map()方法就能满足我们的要求。下边的代码,会映射文件的前1024个字节到内存中。
MappedByteBuffer mbb = fc.map( FileChannel.MapMode.READ_WRITE, 0, 1024 );map方法返回一个ByteBuffer的子类MappedByteBuffer。之后,可以像使用其他ByteBuffer一样使用这个新创建的buffer,操作系统会为我们做真正的映射。
散列和聚集(Scattering and gathering)
散列和聚集概略
scatter/gather IO是使用多个buffer存储数据的读写方法。
scatter读有点像channel读,只不过scatter将读取的数据存储一系列buffer的数组中而不是单个buffer。与此类似,gathering写写出一些列buffer数组中而不是单个buffer的数据。
scatter/gathering IO对分割数据流的到不同部分特别有帮助,可以通过这种策略实现复杂的数据格式。
scatter/gether IO
Channels可以选择性的实现两个新的接口:ScatteringByteChannel和GatheringByteChannel。ScatteringByteChannel类型的通道多了两种读方法:
- long read( ByteBuffer[] dsts );
- long read( ByteBuffer[] dsts, int offset, int length );
上述的read方法和标准的read方法差不多,只不过传入的形参从单个buffer变成了buffer数组。
在scatter的read方法中,通道会按照顺序填充每一个buffer。当填充玩一个buffer之后,开始填充下一个buffer,在某种意义上,数组的buffer被当成一个逻辑的大buffer。
scatter/gather的应用
scatter/gather IO对将一块数据分成多个部分很有帮助。比如,你可能需要写一个使用消息对象的网络应用,每个消息被分割成固定长度的头和固定长度的体。你可以创建一个恰好大小的buffer来存放头,然后另外一个恰好大小的buffer存放body。可以将两个buffer放到一个数组中,然后使用scatte读操作,该操作会自动将header和body存储到两个buffer中。
我们已经从buffer获得的便利也适用于缓冲区阵列。由于每个缓冲区都会记录多少空间以获取更多数据,因此散列读取会自动查找其中有空间的第一个缓冲区。在完成之后,它会移动到下一个。
Gathering写
gathering 写就像scatter读,只能用于写。它也有一些采用缓冲区数组的方法:
- long write( ByteBuffer[] srcs );
- long write( ByteBuffer[] srcs, int offset, int length );
gathering 写入对于从一组单独的缓冲区形成单个数据流非常有用。为了与上述消息示例保持一致,你可以使用gathering写入将网络消息的组件自动组装为单个数据流,以便通过网络进行传输。
可以在示例程序UseScatterGather.java中看到scatter/gathering操作。
文件加锁
文件加锁概述
要获取文件部分的锁定,可以在打开的FileChannel上调用lock方法。请注意,如果要获取排他锁,则意味着你想写入文件。
RandomAccessFile raf = new RandomAccessFile( "usefilelocks.txt", "rw" );
FileChannel fc = raf.getChannel();
FileLock lock = fc.lock( start, end, false );一旦获取锁之后,你可以在其上做任何你需要的敏感操作,然后释放获取的锁。
lock.release();释放锁之后,其他程序将有机会获取锁。
示例代码UseFileLocks.java,可以并发执行自身,这个程序会锁定一个文件三秒钟,然后释放,如果在同一时间多运行几个实例,你可以观察到一个一个的顺序获取锁。
文件锁定和可移植性
文件锁定可能是棘手的业务,特别是考虑到不同的操作系统实现锁定的方式不同。以下指南将帮助你尽可能保持代码的可移植性:
- Only use exclusive locks.
- Treat all locks as advisory.
网络和异步IO
网络和异步IO概略
网络是学习异步IO的最好的例子,也是对于任何使用Java语言进行输入/输出过程的人来说是必不可少的知识。 NIO中的网络与NIO中的其他操作没有多大区别 - 它依赖于通道和缓冲区,并且可以从通常的InputStream和OutputStream获取通道。
在本节中,我们将从异步IO的基本原理开始 - 它是什么以及不是什么 - 然后转向更加实际操作的过程示例。
异步IO
Asynchronous I/O is a method for reading and writing data without blocking. Normally, when your code makes a read() call, the code blocks until there is data to be read. Likewise, a write() call will block until the data can be written.
异步IO是一种无阻塞地读写数据的方法。通常传统行为,当你的代码进行read调用时,代码会阻塞直到有数据被读取。同样,write调用会阻塞,直到数据可以写入。
另一方面,异步IO调用不会阻塞。相反,你可以注册感兴趣的IO事件 - 可读数据的到来,新套接字连接等等 - 系统会告诉你何时发生此类事件。
异步IO的优点之一是它可以让您在同一时间从很多输入和输出进行IO操作。同步程序通常不得不求助于轮询,或创建许多线程来处理大量连接。使用异步IO,您可以在任意数量的通道上侦听IO事件,而无需轮询并且无需额外的线程。
我们将通过检查一个名为MultiPortEcho.java的示例程序来理解异步IO。这个程序就像传统的回显服务器一样,接受来自客户端的连接,然后发还他们发送的东西。除此之外,它具有可以同时监听多个端口的附加功能,并处理来自所有端口的连接。并且在单一的线程中完成。
Selectors
本节的讲解和MultiPortEcho.java源代码中的go方法相对应,首先可以看一下这部分代码以求得比较完整的了解。
异步IO中中心对象叫做Selector,它是你用来注册所有感兴趣IO事件的地方,另外它会告知你什么时候这些事件会发生。
那么,第一件事情我们需要做的是创建一个Selector:
Selector selector = Selector.open();接下来,我们将在各种通道对象上调用register方法,为了注册这些通道对象上感兴趣的IO事件,register方法的第一个参数是Selector。
打开一个ServerSocketChannel
为了接受连接,我们需要一个ServerSocketChannel对象。实际上,我们需要为每一个将要监听的端口都创建一个ServerSocketChannel,如下所述:
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking( false );
ServerSocket ss = ssc.socket();
InetSocketAddress address = new InetSocketAddress( ports[i] );
ss.bind( address );第一行代码创建了一个ServerSocketChannel, 最后三行绑定到给定的端口,代码第二行将ServerSocketChannel 设置为非阻塞。我们必须在每一个我们使用的socket通道上调用这个方法,否则异步IO不会工作。
Selection Keys
下一步注册新打开的ServerSocketChannels 到Selector上,我们使用ServerSocketChannels.register方法实现这个功能,如下所示:
SelectionKey key = ssc.register( selector, SelectionKey.OP_ACCEPT );register方法的第一个参数一定是Selector。第二个参数OP_ACCEPT表明我们希望监听accept事件——也就是当一个新的连接来临的时间。这个只是对ServerSocketChannel有效的事件。
注意register的返回值。SelectionKey代表了channel到Selector的注册。Selector是通过提供对应于事件的Selectionkey来告知你特定的时间进来了。SelectionKey也可以用来反注册channel。
内部循环
现在我们注册了一些IO事件,我们进入了主循环。几乎每个使用选择器的程序都会使用内部循环,就像这样:
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey key = (SelectionKey)it.next();
// ... deal with I/O event ...
}首先,我们调用Selector的select方法。此方法阻塞,直到至少有一个注册事件发生。当发生一个或多个事件时,select方法将返回发生的事件数量。
接下来,我们调用Selector的selectedKeys方法,该方法返回发生事件的SelectionKey对象的Set。
我们通过迭代SelectionKeys来处理事件,并依次处理每个事件。对于每个SelectionKey,你必须确定发生了哪些IO事件以及哪些IO对象受到该事件的影响。
监听新进入的连接
在执行我们的程序的这一点上,我们只注册了ServerSocketChannel,并且我们只注册它们以用于“接受”事件。为了确认这一点,我们在我们的SelectionKey上调用readyOps方法,并检查发生了什么样的事件:
if ((key.readyOps() & SelectionKey.OP_ACCEPT)
== SelectionKey.OP_ACCEPT) {
// Accept the new connection
// ...
}果然,readOps方法告诉我们这个事件是一个新的连接。
接受一个新的连接
因为我们知道有一个等待在这个服务器套接字的传入连接,所以我们可以安全地接受它;也就是说,不用担心accept操作会阻塞:
ServerSocketChannel ssc = (ServerSocketChannel)key.channel();
SocketChannel sc = ssc.accept();下一步是将新连接的SocketChannel配置为非阻塞。由于接受这个连接的目的是从套接字读取数据,所以我们还必须在我们的Selector中注册SocketChannel,如下所示:
sc.configureBlocking( false );
SelectionKey newKey = sc.register( selector, SelectionKey.OP_READ );请注意,我们已经注册了SocketChannel来读取,而不是接受新的连接,使用OP_READ参数到register函数。
移除已经处理的SelectionKey
在处理了SelectionKey之后,我们准备好返回到主循环。但首先我们必须从选定的键集中删除处理过的SelectionKey。如果我们不删除已处理的SelectionKey,它仍然会作为主集中的激活selectionKey呈现,这将导致我们尝试再次处理它。我们调用迭代器的remove方法来删除处理的SelectionKey:
it.remove();现在我们准备好返回主循环,并在我们的某个套接字上接收传入数据(或传入的I / O事件)。
Incoming I/O
当数据从某一个套接字进入,会触发I/O事件。这会导致对Selector.select的调用,就会在我们的代码的主循环中返回一个或者多个事件。这一次我们关心SelectionKey的OP_READ事件,代码如下:
} else if ((key.readyOps() & SelectionKey.OP_READ)
== SelectionKey.OP_READ) {
// Read the data
SocketChannel sc = (SocketChannel)key.channel();
// ...
}像之前一样,我们获取并处理发生IO事件的channel,在本例中,这是一个回显服务器,我们只是将读取的数据发送回去。可以查看MultiPortEcho.java的源代码。
Back to main loop
每次我们返回主循环时,我们都会在Selector上调用select方法,并且我们得到一组SelectionKey。每个键代表一个IO事件。我们处理事件,然后从集合中移除SelectionKey,然后回到主循环的顶部。
这个程序有点简单,因为它只是为了演示异步IO所涉及的技术。在实际的应用程序中,你需要通过从Selector中删除它们来处理关闭的channel。你可能会想要使用多个线程。这个程序可以使用一个线程,因为它只是一个演示程序,但是在现实世界中,创建一个线程池来处理IO事件处理的耗时部分可能更有意义。
字符集(Character sets)
字符集概略
根据Sun的文档,Charset是“16位Unicode字符序列和字节序列之间的命名映射”。实际上,Charset允许您以可移植的方式读写字符序列。
Java语言被定义为基于Unicode。然而,在实践中,许多人在假设单个字符在磁盘或网络流中被表示为单个字节的情况下编写程序。这种假设在很多情况下都有效,但并非全部,而且随着计算机变得更加适应Unicode,每天都变得不是如此。
在本节中,我们将看到如何使用字符集来处理符合现代文本格式的文本数据。我们在这里使用的示例程序非常简单;不过,它涉及使用Charset的所有关键方面:为给定的字符编码创建一个Charset,并使用该Charset对文本数据进行解码和编码。
Encoders/decoders
为了读写文本,我们将分别使用CharsetDecoder和CharsetEncoder。被称为编码器和解码器有一个很好的理由。一个字符不再代表一个特定的位模式,而是一个字符系统中的一个实体。因此,由实际位模式表示的字符因此必须以某种特定的编码来表示。
CharsetDecoder用于将逐位表示转换为实际的char值。同样,CharsetEncoder用于将字符转换回位。
接下来,我们将看看使用这些对象读取和写入数据的程序。
处理文本的正确方式
我们来看一个示例程序UseCharsets.java,这个代码很简单 – 从一个文件读取代码,然后写到另外一个文件。 将数据通过CharsetDecoder读入CharBuffer。与此类似,使用CharsetEncoder写出数据。
我们假设我们存储在磁盘上用的是ISO-8859-1 (Latin1)字符集 ————ASCII的标准扩展。虽然我们必须做好迎接Unicode的准备。但是我们也要意识到不同的文件可以存储为不同的格式,并且ASCII是最普通的一种。实际上,每一个java的实现都要求能够兼容如下的字符集:
- US-ASCII
- ISO-8859-1
- UTF-8
- UTF-16BE
- UTF-16LE
- UTF-16
示例代码
打开相应的文件读入到ByteBuffer类型的对象inputData中,我们的代码必须创建一个ISO-8859-1 (Latin1)编码集的实例:
Charset latin1 = Charset.forName( "ISO-8859-1" );然后,我们创建一个解码器(为了读)和一个编码器(为了写):
CharsetDecoder decoder = latin1.newDecoder();
CharsetEncoder encoder = latin1.newEncoder();为了将字节数据解码为一组字符,我们将ByteBuffer传递给CharsetDecoder,产生CharBuffer:
CharBuffer cb = decoder.decode( inputData );如果我们想要处理我们的字符,我们可以在程序中的这一点上做到。但我们只想把它原样写回,所以没有什么可做的。
要将数据写回,我们必须使用CharsetEncoder将其转换回字节:
ByteBuffer outputData = encoder.encode( cb );转换完成之后,我们可以把数据写出到文件。
总结
总结
正如你所看到的,NIO库中有很多功能。虽然一些新功能(例如文件锁定和字符集)提供了新功能,但其中许多功能均是在优化。
在基本层面上,我们使用原始的流导向的类也可以完成channel和buffer完成的功能。但是,channel和buffer允许以更快的速度完成相同的旧操作 - 事实上,接近系统所允许的最大值。
但是NIO最大的优势之一就是它提供了一种新的 - 而且非常需要的 - 用Java语言进行输入/输出的结构性比喻。除了像缓冲区,通道和异步I / O这样的新概念(和可实现)实体之外,有机会重新考虑Java程序中的I / O实现方式过程。通过这种方式,NIO为即使是最熟悉的I / O程序提供了新的生命,并使我们有机会以不同于以往的方式做得更好。
Downloadable resource
PDF of this content
Related topics
- Download nio-src.zip, the complete source for the examples in this
tutorial. - See the SDK Documentation for more information about installing and
configuring JDK 1.4. - The online API specification describes the classes and methods of
NIO, in the autodoc format that you know and love. - JSR 51 is the Java Community Process document that first specified
the new features of NIO. In fact, NIO, as implemented in JDK 1.4, is
a subset of the features described in this document. - John Zukowski has written some good articles about NIO for his Magic
with Merlin column: - ” The ins and outs of Merlin’s new I/O buffers ” ( developerWorks,
March 2003) is another look at buffer basics. - Get a little deeper into NIO with Aruna Kalagnanam and Balu G’s ”
Merlin brings nonblocking I/O to the Java platform ” (
developerWorks, March 2002). - Greg Travis examines NIO in his book, JDK 1.4 Tutorial (Manning
Publications, March 2002).
文章翻译完毕。