自然语言处理中的embeddings
1. 背景
自2010年代初以来,嵌入一直是自然语言处理(NLP)的主流热词之一。将信息编码成低维向量表示,在现代机器学习算法中很容易集成,这在NLP的发展中起到了核心作用。嵌入技术最初集中在单词上,但很快就开始将注意力转移到其他形式上:从图结构,如知识库,到其他类型的文本内容,如句子和文档。
接下来,我们会从最初的one-hot开始,探索embddings在nlp领域的发展。
2. 概览
在embeddings技术出现以前,nlp领域应用较多的是以one-hot为主的简单representation。这类技术可以根据需要对单词索引处的value做不同的处理,比如直接用1表示,用词频(term frequency),TF-IDF(term frequency–inverse document frequency)等等,这样技术在nlp的发展历程中发挥了重大的作用,不过,其也有几方面的问题:
- 无法结合丰富的语义信息,对于相似的单词,比如“table”,“desk”,具有完全不同的表示,无法定义similarity概念。
- 这类表示的向量长度取决于字典的长度,对于一种语言来说,其常用词通常会有成百上千个,要想表示更具备通用性,那么字典的长度就会达到很大,带来的后果就是巨大的空间消耗与计算复杂度,这么长的特征也很难直接嵌入到其他的任务中。
这类问题随着以word2vec为代表的embeddings技术的出现而得到了改变,这类新技术引入了语义空间的概念,它们不同于one-hot类型的表示的地方在于,其建模是无序的,也就是说他们不再建模每个单词在词典中 的位置信息,而是直接针对该单词的语义进行建模,这时候也有位置的概念,不过位置的作用仅限于进行索引来获得单词的语义向量。
这就带来了很大的好处:
- 由于每个单词有自己的词义向量,因而可以很自然的引入similarity的概念,可以通过各种距离函数度量两个向量的相似度,从而判断单词的similarity。
- 语义向量可以大大缩短,不在局限于字典的长度,哪怕字典很大,也可以用一个低维的向量表示单词的语义向量。
虽然embeddings技术有非常大的优势,不过其也有一些局限之处,其中一个很大的限制就是词的动态属性,比如,mouse一词在不同的语境下可以代表老鼠,也可以代表鼠标,而语义向量在训练完成后便是静态的了。
当然,针对这类问题也有一些相关研究了,比如最新的语境化表示,目的是解决词嵌入的静态性质,让嵌入物根据它出现的上下文进行自我调整。与传统的单词嵌入不同,这些模型的输入不是孤立的单词,而是单词及其上下文。这类技术也处在蓬勃发展之中。
3. Word Embeddings
3.1 count-based模型
传统的构建VSM(vector space model)的方法主要是基于词频,因此,这种方法通常被称为基于计数的方法。广义上讲,基于计数的模型的总主题是基于词频构建矩阵。
这类模型可以分为如下三类:
-
Term-document
在这个矩阵中,行对应单词,列对应文档。每一个单元格表示特定词在特定文档中的频率,以衡量文档对的语义相似性。具有相似数字模式(相似列)的两个文档被认为是具有相似主题的文档。术语term-document模型是以document为中心的,因此,它通常用于文档检索、分类或类似的基于文档的目的。这种矩阵中,每一行的向量就对应着该单词的embedding
-
Word-context
与term-document矩阵侧重于文档表示不同,word-context矩阵旨在表示词。Deerwester等人[1990]首次提出使用这种矩阵来测量词的相似性。比较重要的是,他们将上下文的概念从文档扩展到了更灵活的定义,允许广泛的可能性,从相邻的词到词的窗口,到语法依赖性或词性偏好,再到整个文档。word-context矩阵是最广泛的建模形式,可以实现许多应用和任务,如词的相似度测量、词义辨别、语义角色标注和查询扩展。这类向量类似于term-document,不过其行是针对context的,这显然相比于term-document是一种更高阶的相似度。
-
Pair-pattern
在这个矩阵中,行对应词对,列是两者出现过的模式。Lin和Pantel[2001]用它来寻找模式的相似性,如 "X是Y的作者 "和 “Y是X写的”。该矩阵适用于测量关系相似性:成对词语之间语义关系的相似性,如 "linux:grep "和 “windows:findstr”。Lin和Pantel[2001]首次提出了扩展distributional hypothesis:与相似对(上下文)共同出现的模式往往具有相似的含义。
3.1.1 点阵互信息(POINTWISE MUTUAL INFORMATION)
原始频率不能提供可靠的关联度。像 "the "这样的stop word可以经常与一个特定的词共存,但这种共存不一定对应于语义关系,因为它不是辨别性的。比较理想的是,有一个能够结合共现的信息性的测量方法。正点互信息(Positive Pointwise Mutual Information,PPMI)就是这样一种测量方法。PMI通过两个词的单个频率来归一化两个词的共现的重要性。
其计算公式为:
P M I ( w 1 , w 2 ) = l o g 2 P ( w 1 , w 2 ) P ( w 1 ) P ( w 2 ) PMI(w_{1},w_{2}) = log_{2}\frac{P(w_{1},w_{2})}{P(w_{1})P(w_{2})} PMI(w1,w2)=log2P(w1)P(w2)P(w1,w2)
其中, P ( x ) P(x) P(x)是词x的词频,PMI会检查 w 1 w_{1} w1和 w 2 w_{2} w2的共现次数而不仅仅是他们单独的词频。stop word的P值较高,这导致整体PMI值降低。PMI值的范围可以从- inf到+ inf 。负值表示共同出现的可能性比偶然发生的可能性小。考虑到这些关联是基于高度稀疏的数据计算出来的,而且它们不容易被解释(很难定义两个词非常 "不相关 "是什么意思),我们通常会忽略负值,用0代替,因此,该方法被称为正PMI(PPMI)。
3.1.2 降维
word-context建模是计算基于计数的词表征的最广泛的方法。通常,取与目标词共存的词作为其上下文。因此,这个矩阵中的列数等于词汇中的词数(即语料库中唯一的词)。这个数字很容易达到几十万甚至几百万,这对计算和存储来说显然是个瓶颈。为了规避这个限制,通常会对VSM使用降维技术。
减少维度可以通过简单地放弃那些信息量较少或重要的上下文(即列)(例如,频繁的功能词)来获得。这可以使用特征选择技术来完成。但是,我们也可以通过合并或将多个列合并成较少的新列来重新划分维度,这可以通过奇异值分解(SVD)来实现。
3.2 预测模型(PREDICTIVE MODELS)
这种模型便是目前火热的深度学习模型的拿手好戏了。在过去的十年里,伴随着深度学习的发展,基于神经网络的表示方法(embeddings)几乎完全取代了传统的基于计数的模型,并在该领域占据了主导地位。这种模型的首要功臣便是Word2vec。
Word2vec是基于一个简单但有效的前馈神经架构,它以语言建模为目标进行训练。共有两种不同但相关的Word2vec模型。即连续词袋模型(continuous Bag-Of-Words(CBOW))和Skip-gram。CBOW模型的目的是利用周围的上下文来预测当前的单词,最小化以下损失函数:
E = − l o g ( p ( w t ⃗ ∣ W t ⃗ ) ) E = -log(p(\vec {w_{t}}|\vec {W_{t}})) E=−log(p(wt∣Wt))
其中, w t w_{t} wt是目标词, W t = w t − n , . . . , w t , w t + n W_{t} = w_{t-n},...,w_{t},w_{t+n} Wt=wt−n,...,wt,wt+n代表上下文中的单词序列。Skip-gram模型类似于CBOW模型,不过不同之处在于这个模型的目标是在给定目标词的情况下预测周围的单词,而不是直接预测该目标词本身。

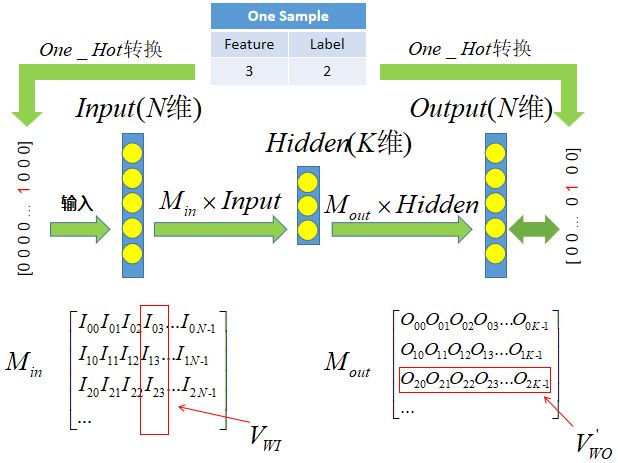
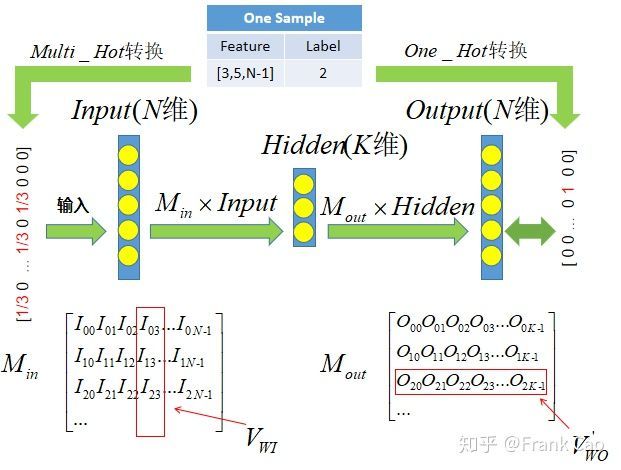
上图便是是Word2vec的CBOW和Skip-gram模型的总体架构简化图。该架构由输入层、隐藏层和输出层组成。输入层的长度为词典的大小,并将上下文编码为给定目标词的周围单词的one-hot向量表示组合(现在的实现中已经不这么做了,而是为每个word分配一个vector,用该vector代表该word的表示)。输出层具有与输入层相同的大小,在训练过程中为目标词的one-hot向量,通过soft Max处理后得到目标词的索引。
由于输出层的大小为字典的大小,而字典通常非常大,所以直接进行softmax的话会非常耗时,针对这个问题,word2vec使用了hierarchical softmax和负采样技术来优化训练。
除了word2vec,还有个很重要的词向量:GloVe(Global Vectors for Word Representation),它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。
GloVe通过如下三步实现:
-
根据语料库构建一个共现矩阵(Co-ocurrence Matrix) X X X,矩阵中的每个元素 X i j X_{ij} Xij代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数。直观上这个次数的最小单位应该是1,不过GloVe不这么认为,它根据这两个单词在上下文窗口中的距离 d d d,构造了一个衰减系数(decreasing weighting): d e c a y = 1 / d decay=1/d decay=1/d用于计算权重,所以距离越远的两个单词所占总计数(total count)的权重越小。
-
构建词向量和共现矩阵之间的近似关系:
w i T w ~ j + b i + b ~ j = l o g ( X i j ) w_{i}^{T}\tilde w_{j}+b_{i}+\tilde b_{j}=log(X_{ij}) wiTw~j<