Google DeepMind最新研究,将视觉语言大模型作为强化学习的全新奖励来源

论文题目:Vision-Language Models as a Source of Rewards
论文链接:https://arxiv.org/abs/2312.09187
在大型语言模型(LLM)不断发展的进程中,强化学习扮演了重要的角色,ChatGPT就是在GPT-3.5的基础上经过人类反馈的强化学习算法微调得到。而对于强化学习本身而言,如何使其优化算法在各种丰富的开放环境中更好的完成目标是目前研究的主要热点。其中的一个关键限制因素就是需要设计适合多种场景的奖励函数。
本文介绍一篇来自Google DeepMind的研究论文,本文探索了使用现成的视觉语言模型(vision-language models,VLM)作为强化学习奖励来源的可行性。具体来说,本文作者选取了CLIP系列模型来对各种不同的语言建模任务进行侧重于视觉模态的奖励,并将其训练各种RL智能体。作者在两个不同的视觉领域中对这种奖励方法进行了实验,实验结果表明,VLM模型生成的奖励质量会随着视觉编码器参数规模的增加而提高。
01. 引言
强化学习(RL)领域的一些里程碑工作很多都发生在奖励函数可以明确定义的领域,例如在一些游戏领域和模拟环境中。这种场景中的奖励功能包括:游戏获胜/失败、游戏得分的变化、基础状态的变化等。随着强化学习的不断发展,研究者们开始对强化学习的通用性提出了更高的要求,例如将其应用到现实世界中,因为在模拟环境中,我们很容易根据模拟对象的状态变化来计算奖励。而在现实世界中,奖励必须根据实际的观察来得到。此外,针对不同目标来设计奖励函数也是一个相当繁重的工作,这也导致了很多RL算法无法泛化到通用领域中。
为了解决这些问题,本文作者提议使用一些视觉语言模型(VLM)作为RL模型在视觉环境中的奖励函数,由于VLM通常在配对的图像和文本数据集上进行了预训练,具有开箱即用的视觉检测、分类和问答能力,因此本文提出了一种从预训练CLIP图像和语言嵌入中提取多模态稀疏二元奖励的方法,该方法可以训练各种智能体在Playhouse[1]和 AndroidEnv[2]视觉环境中实现各种语言目标,同时无需针对特定环境对模型进行微调。
02. 本文方法

03. 实验效果
本文的实验设置类似于标准的在线强化学习设置,agent通过与环境的试错交互来最大化奖励,唯一的区别在于,本文的agent不使用真实奖励或手工设计的奖励函数进行优化,而是根据VLM模型生成的奖励进行训练,为了综合评价本文方法的性能,作者在实验中分别展示了VLM奖励(本文称之为内在奖励)和真实奖励得到的性能。
本文在两个视觉环境中进行了实验,如下图所示:
(1)Playhouse,这是一个基于Unity的模拟环境,可以在程序生成的房间中以第一人称视角行动。在Playhouse环境中,作者设计了寻找、举起、拾取并放置这三种难度递增的任务。
(2)AndroidEnv,这是一个基于Android操作系统的开源环境,允许智能体通过在实时模拟的Android设备上进行触摸屏手势交互。在AndroidEnv环境中,作者设计了两种任务,其一是打开常用应用程序,例如Gmail、Google Sheets、Chrome等,其二是打开一些不太知名的APP。
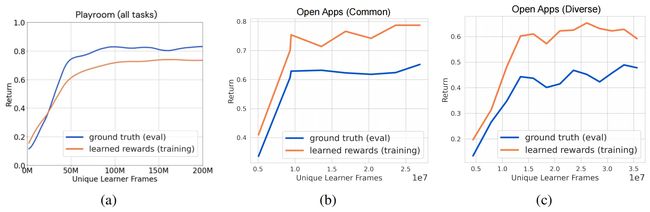
作者在训练过程中记录了agent获得的奖励值变化情况,下图展示了本文方法在不同实验环境中的真实奖励和VLM奖励的变化曲线,由于VLM奖励的记录并不精确,因而其与真实奖励之间存在系统性差距,但是从下图中可以看出,模型在训练期间学习到的VLM奖励与真实奖励之间存在很强的相关性。
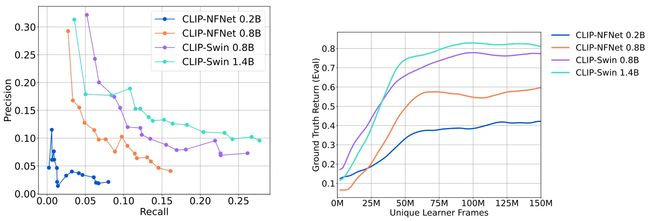
此外,本文作者还对VLM奖励方法的扩展性进行了深入探索,下图中展示了模型在Playhouse环境中评估VLM奖励相对于真实二进制奖励的准确性情况,图中左侧展示了,随着用于奖励模型的VLM参数规模的增加(从200M参数到1.4B参数),模型的精确度-召回率曲线得到了明显的改善。图中右侧表示当使用不同backbone的VLM进行训练时,模型仍然能够获得较为准确的奖励信号。
04. 总结
本文介绍了一种将现成的视觉语言模型(VLMs)作为强化学习奖励函数的框架,例如将多模态对齐CLIP模型的文本编码器和视觉编码器部署在强化学习模型中,而无需再特定领域的数据集上进行微调。通过对此类VLM在RL过程中的性能分析,作者发现,VLM模型生成的奖励质量会随着视觉编码器参数规模的增加而提高。这些结果表明,如果社区进一步发展出更大规模,更佳性能的视觉语言大模型,那我们训练更加通用的强化学习智能体的难度也会大大降低。
参考
[1] DeepMind Interactive Agents Team, Josh Abramson, Arun Ahuja, Arthur Brussee, and Rui Zhu. Creating multimodal interactive agents with imitation and self-supervised learning, 2022.
[2] Daniel Toyama, Philippe Hamel, Anita Gergely, Gheorghe Comanici, Amelia Glaese, Zafarali Ahmed, Tyler Jackson, Shibl Mourad, and Doina Precup. Androidenv: A reinforcement learning platform for android. arXiv preprint arXiv:2105.13231, 2021.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区