Vision Transformer及其变体(自用)
0 回顾Transformer
0.1 encoder
-
在正式开始ViT之前,先来复习一遍transformer的核心机制
-
相关的文章有很多,我选了一遍最通俗易懂的放在这:Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
-
所谓注意力机制,就是Attention = ∑similarity(Query, Key)* Value,Q可以理解为单词在当前的表示,K为单词的标签,V为单词的实际表示
-
自注意力机制的运行过程
- 从每个编码器输入向量生成三个向量,即查询向量(query-vec)、键向量(key-vec)、值向量(value-vec),生成方法就是输入序列的每个向量分别乘以训练出来的权重矩阵,各自创建一个查询向量、一个键向量和一个值向量。
- 通过每个向量的query和所有向量的key的乘积,计算attention分值。这个分决定着编码该向量时(某个固定位置时),应该对其他位置上的单词各自给予多少关注度。(所以,attention分数也是向量)
- 接下来,是把attention分数除以key向量维数的平方根(使梯度更稳定),再softmax(归一化),得到的分数决定着编码该向量时(某个固定位置时),应该对包括它自己的其他位置上的单词各自给予多少关注度。(softmax也是向量,维度与attention分数相同)
- 最后,将softmax的各个维度上的值乘以各自对应的value向量,再求和
-
而所谓多头注意力,就是指权重矩阵不止一组,而是很多组,每组对应一个注意力头。它们表示了关注点的不同,总有一个头的关注点在我们想关注的地方。
-
当然,最后还会把所有头拼接起来,乘一个联合训练的大矩阵,得到融合了所有头的信息的矩阵,将其送往前馈神经网络(两个线性变换+一个激活函数)。
0.2 decoder
-
decoder带有两个注意力层。一个是带掩码(mask)的多头注意力层,只允许关注已输出位置的信息(未输出位置的信息在softmax之前被置为负数,之后变为0,相当于屏蔽了未输出位置)。说白了,答案不能一下子全都告诉你,不然你就抄袭了。所以是你每进行一次,就把答案漏出来一点,直到把答案全都露出来。
-
另一个是Encoder-Decoder Attention,Q来源于上一个的Decoder输出,K,V均来自Encoder最后一层的的输出。也就是说,将翻译出来的词当作Q,原句里的词当作K,V,计算的是你好与“hello,world”的相似度。
-
需要注意的是,因为当时resnet已经出了,所以encoder和decoder都有残差连接+归一化的结构,最后跟一个全连接层和softmax层。
1 Vision Transformer
- ViT的出现证明了,不止CNN可以处理图像分类任务,单纯的transformer架构也同样可以
- 所以2021-2022这一区间,在3D检测领域的多数模型选择拥抱了transformer
1.1 简介
- 将图像拆分为patches,并提供这些patches的线性embedding序列作为transformer的输入
- 采用有监督的方式对模型进行训练
- transformer很吃数据量,在百万甚至千万级别以上的数据集训练下,ViT的训练效果才会超过传统CNN。
- 数据集的数量决定着模型的泛化性
1.2 相关工作
- Transformer: 用于机器翻译的方法,被广泛用于NLP领域
- BERT: 使用去噪自我监督的训练前任务
- 局部多头点积自我注意块: 只在每个查询像素的局部社区中应用自注意力,可以完全取代卷积
- 稀疏Transformer: 采用了对全局自关注的可扩展近似,以便适用于图像
- 在不同大小的块中应用: 在极端情况下,只沿着个别轴线应用
- iGPT: 无监督的方式,在降低图像分辨率和色彩空间后将Transformers应用于图像像素
1.3 方法
1.3.1 ViT的过程
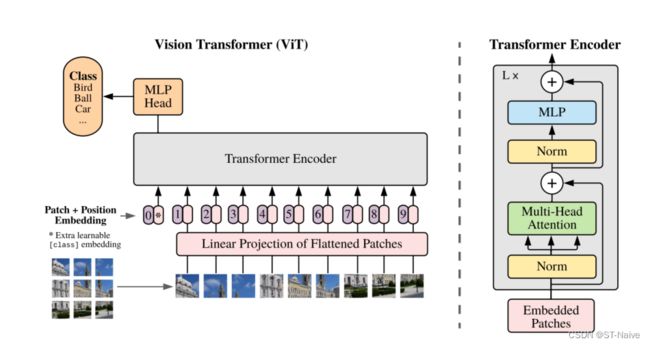
-
将图形转化为序列化数据
- 以ViT-B/16为例,首先输入一张224×224×3的图片,将其按照16×16的patch划分,得到196个patch
- 将每个patch线性映射到一维向量中,形成一个长度为16×16×3=768的一维向量
- 最后将这196个patch重组,得到一个196×768的二维矩阵
- 不过实际操作其实就是用一个核为16,步长为16的卷积来实现
-
位置信息的嵌入
- 与transformer中的Positional Encoding类似,我们需要给每个patch标注位置信息
- 对于Position Embedding作者也有做一系列对比试验,在源码中默认使用的是1D Pos. Emb(一个可训练的参数),对比不使用Position Embedding准确率提升了大概3个点,和
2D Pos. Emb.比起来没太大差别。
-
图像信息的嵌入
- 除了图像的位置信息,图像信息也会被加入其中,经过Linear Projection of Flattened Patches得到一个token向量
- 另外,原作者参考bert,在序列的最前面加上了一个class token。该token属于可训练参数,与其他token的格式相同,专门用于分类。
- 所以,最后输入进的shape为197×768
-
transformer encoder详解
-
内部结构其实很简单,就是将encoder block重复堆叠L次
-

-
layer norm—对每个token做归一化处理
-
Multi-Head Attention—多头注意力机制,前面复习过
-
dropout—原论文是dropout,不过droppath效果更好
-
MLP—全连接+GELU激活函数+Dropout
-
-
MLP Head
- 由于我们最后需要的仅仅只是分类信息,所以需要一个全连接层把class token提取出来。这个全连接层就是MLP Head
1.3.2 分辨率调整
- 问题:当处理更高分辨率的图像时,patch数增加,位置发生变化,预训练的position embeding无法发挥作用
- 解决方法:根据预训练的position embeding在原始图像的位置进行二维插值
1.4 总结
- 与当时的SOTA相比,ViT的计算量无疑是更小的,且在大数据集的加持下精度更高
- 作者还尝试了根CNN结合的方式,不过后续还会介绍,这里就先不提了
- 另外,模仿BERT,似乎自监督训练也可作为一个发展方向
- 总的来说,ViT开创了图像分割重组为序列的新模式,且潜力巨大
2 DeiT
2.1 知识蒸馏
- 这个概念其实并不新奇,早在2015年便被提出,并应用到其他一些算法当中(比如说上一篇的yolov6)
- Knowledge Distillation,简称KD,顾名思义,就是将已经训练好的模型包含的知识(Knowledge),蒸馏(Distill)提取到另一个模型里面去
- 简而言之,就是模型压缩的一种方法,是一种基于“教师-学生网络思想”的训练方法
2.1.1 理论基础
- 一些名词
- Teacher:大而笨重的模型
- Student:小而紧凑的模型
- transfer set:用于小模型训练的数据,也是获得Teacher模型soft target输出的输入数据集
- hard target:样本原始标签
- soft target:Teacher模型输出的预测结果
- temperature:softmax函数中的超参数
- knowledge:可以理解为从输入向量到输出向量学习到的映射
- Logits:各个类别的分值汇总,在softmax后为概率分布
- 学习模式
- 需要注意的是,这里蒸馏的目的是小网络的概率分布趋近于大网络,而非单纯的正确率趋近于大网络
- 换句话说,小网络最后的输出,不只是正确率趋近于大网络,而是输出的概率分布,即softmax(Logits)也要趋同
2.1.2 分类
- 知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向
- 目标蒸馏
- 使用大网络softmax层输出的类别的概率分布来作为“Soft-target” ,辅助Hard-target(标签)训练小网络
- 这是因为,在Soft-target的概率分布中,也包含着teacher模型归纳推理的信息
- 具体表现就是,使用 Soft-target 训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少
- 温度:对softmax函数引入温度变量后,负标签携带的信息被放大,有利于模型更加关注负标签
- 当T=1时,就是标准的softmax,随着T增大,分布熵随之拉大,分布更加平缓
- 高温蒸馏过程的目标函数由distill loss(对应Soft-target)和Student loss(对应Hard-target)加权得到
- 特征蒸馏
- 它不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征
- 第一阶段:首先选择待蒸馏的中间层(即Teacher的Hint layer和Student的Guided layer)。由于两者的输出尺寸可能不同,因此,在Guided layer后另外接一层卷积层,使得输出尺寸与Teacher的Hint layer匹配。接着通过知识蒸馏的方式训练Student网络的Guided layer,使得Student网络的中间层学习Teacher的Hint layer的输出。
- 第二阶段: 在训练好Guided layer之后,将当前的参数作为网络的初始参数,利用知识蒸馏的方式训练Student网络的所有层参数,使Student学习Teacher的输出。
2.2 DeiT模型
- 其实非常简单,光看图就能看得很明白
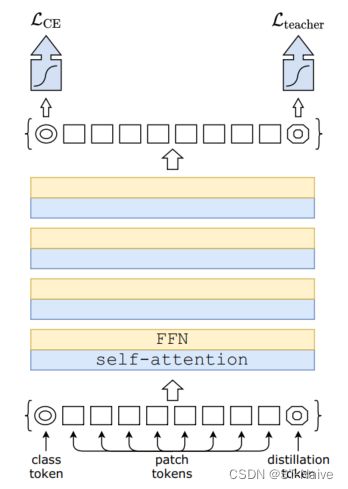
- 这里面的class token和distillation token其实就是学生和老师两部分,前者对应Hard-target,后者对应Soft-target
- 当然,这里面的蒸馏还分为了软蒸馏和硬蒸馏
- 硬蒸馏就是真实标签与老师的软标签各占一半的权重,然后计算loss
- 软蒸馏则是利用了分歧最小化(Kullback-Leibler散度损失),并引入了温度
2.3 总结
- 本来以为会很难,但实际的内容就这么一点点【乐】
- DeiT最大的贡献是减少了对数据的需求量,仅使用ImageNet(ViT的数据量要多得多), 在 53 hours train,20 hours finetune 的前提下达到了在当时 84.2% top-1的准确性,又快又准了属于是。
- 但这只是针对数据要求的改进,关于ViT的改进思路不止这一种,比如说针对计算量大而改进的Twins和Swin Transformer
3 swin transformer
3.1 简介
-
当前存在的问题
- 与语言不同,固定尺度的token并不适用于视觉元素
- 对于高分辨率图像,预测密集,计算复杂度过高
-
解决方案
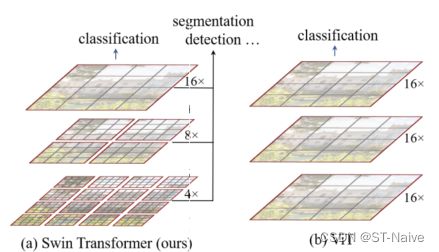
- 采用层次化(hierarchical)特征图,即从小尺寸patch开始,逐渐在更深的层中合并相邻patch,如下图:
-
通过构建层次化结构,使得相关算法得以引入(如FPN、U-Net等),同时解决了密集预测的问题
-
SwinT的另一个关键元素,在于对窗口(window)的设计。在下采样的过程中,把它们划分成若干个window,而多头自注意力机制只针对window,即q、k、v只在局部窗口共享,而非全图
3.2 框架
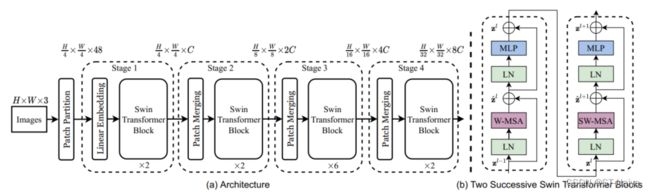
- 算法步骤
- Patch Partition模块主要负责分块,将每张图分为H/4 × W/4块,每块是4×4的图像,展平后再乘通道数即为48。可见其二维矩阵的生成方法与ViT无异,只不过切的块更小了(VIT是16×16)
- Linear Embedding(全连接嵌入)则会将原张量投射到任意维度,即H/4 × W/4 × C
- 不过从源码上看,前两步合在一起就是一个卷积层
- 接下来是4个stage,即4个swin transformer叠加。有意思的是,这里面的swin模块有两种结构,W-MSA和SW-MSA,且二者成对地交替使用,所以stage是偶数
- Patch Merging代表下采样,除了第一个stage外,每过一个stage都要下采样
- 最后还会跟一个归一化+全局池化+全连接,一套丝滑小连招输出结果(图里没写,代码里有)
3.3 Swin Transformer Block
-
带窗的多头自注意力(W-MSA)与不带窗的(MSA)计算量差了很多,因为MSA每次算attention时要把全局的都带上,而W-MSA就只带了窗内的哥们一起玩。具体公式如下:
-

-
哈哈,从这里也能看出,面对高分辨率图像,还是CNN管用。怪不得那篇论文叫做《attention is all you need》,合着就只有attention是need的,其他的都可以不要是吧?
-
其实目前来看,似乎CNN+ViT才是正解。先由CNN浅层提取特征,再交给ViT做后处理
-
另外还有一个Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,如下图所示
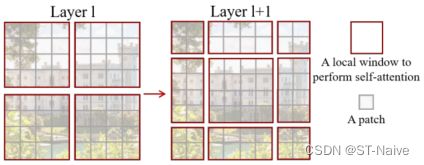
- 与普通的滑动窗口相比,SW打破了窗口之间的界限,解决了不同窗口之间信息交互的问题
- 另外,这里还涉及到了一个循环移位的方法
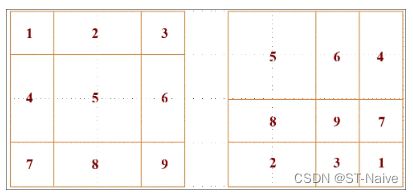
- 那么移位之后,如何解决原本不相邻的两个窗之间的交互问题呢?这里又用到了mask机制。
- 具体来说,如果相互交互的patch属于同一个区域,那么就可以正常交互,如果不是同一个区域,那么他们交互之后就需要加上一个很大的负值,这样通过softmax层之后本来不能交互的那个像素就变成0了。
3.4 Patch Merging
- 下采样的过程根yolov2里提取细粒度特征的形式很类似

- 也就是说,并不是简单的1切4,而是从每个里面都各取一块,组成一个大的
- 这里其实就是CNN里提高感受野的方法了,维度减半,通道加倍
3.5 总结
- 跟PVT(Pyramid Vision Transformer)类似,SwinT同样引入了金字塔结构,并引入了窗的结构。
- 在SwinT的基础上,同样有很多改进型,比如说将相对位置编码改为绝对位置编码的twins,这里就不详细说了。
4 MobileViT
4.1 MobileViT v1
-
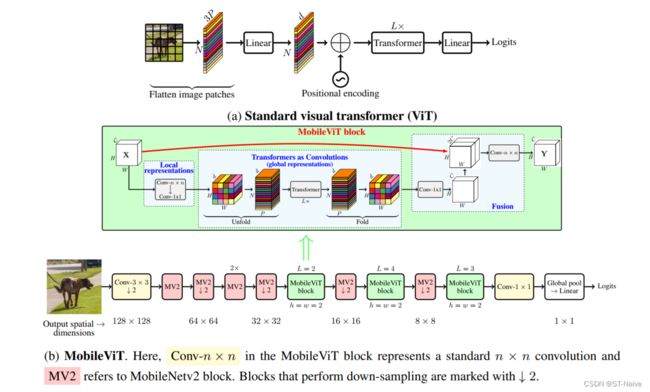
首先还是大致看一下总体的框架
-
从框架不难发现,它主要是由普通卷积,MV2,MobileViT block以及全局池化和全连接层组成
4.1.1 MV2
- 所谓MV2,指的是步长为1的MobileNetV2
- MobileNetV2 = 深度可分离卷积+先升维+倒残差+低维不使用ReLU

-
深度可分离卷积
- 包含两个过程,分别是逐通道卷积(Depthwise Conv)和逐点卷积(Pointwise Conv)
- 逐通道卷积:每个通道都只能被一个卷积核卷积(特征图通道数与输入通道数一致)
- 逐点卷积:将上一步的map在深度方向上进行加权组合,生成新的特征图。这与常规的卷积类似
-
在深度可分离卷积的基础上,先升维,再降维
4.1.2 MobileViT block
-
先将特征图输入卷积核大小为n×n的卷积层进行局部特征的提取,然后过一个1×1的卷积调整通道数
-
那好了,该如何理解unfold与fold呢?我把图放上来,你立马就能懂了
-
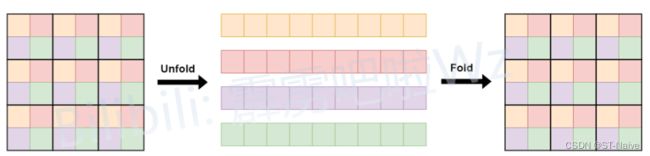
-
哈哈,没错,又是熟悉的味道,还是先取上下左右,各取各的,然后每种颜色之间做attention
-
没错,就是这么简单的一个操作,把计算量给拉下来了
-
考虑到这是2022年的文章,已经出现了SwinT,所以并没什么新奇之处
4.2 MobileViT v3
-
唉?你问我为啥没有v2。。。因为太无聊了,直接跳过了
-
总结:MobileNet V3 = MobileNet v2 + SE结构 + hard-swish activation +网络结构头尾微调
4.2.1 简介
-
主要工作
- MobileNet V3通过结合NetAdapt算法辅助的硬件NAS和新颖的架构来优化到移动端的CPU上
- 本文创建了两个新的MobileNet模型,应用于对象检测和语义分割的任务
- MobileNetV3-Large
- MobileNetV3-Small
- 分割任务中提出了一种高效的轻量级空间金字塔池化策略Lite Reduced ASPP
- 与MobileNetV2相比,MobileNetV3准确率更高,速度更快
-
相关工作
- 基于轻量化网络设计: 比如 MobileNet 系列,ShuffleNet系列,Xception等,使用Group卷积,1*1 卷积等技术减少网络计算量的同时,尽可能的保证网络的精度。
- 模型剪枝: 大网络往往存在一定的冗余,通过减去冗余部分,减少网络计算量。
- 量化: 利用 TensorRT 量化,一般在 GPU 上可以提速几倍
- 知识蒸馏: 利用大模型(teacher model)来帮助小模型(student model)学习,提高 student model的精度。
4.2.2 端到端的架构
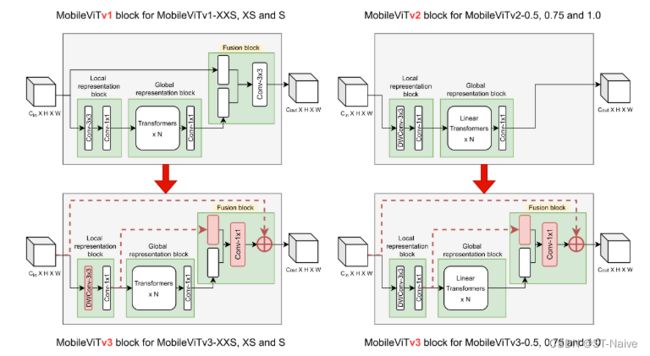
-
MobileViTV3模块
- 在融合块中用1x1卷积层替换3x3卷积层
- 融合局部和全局特征,独立于特征图中的其他位置,以简化融合块的学习任务
- 消除MobileViTv1架构扩展中的主要限制之一,避免了缩放时参数和FLOP的大幅增加
- 局部和全局特征融合
- 将局部表征模块和全局表征模块
- 局部表征模块特征与全局表征模块特征更紧密相关
- 局部表征块的输出通道略高于输入端的通道
- 融合输入端特征
- 输入特征被添加到融合块中的1x1卷积层的输出
- 启发:ResNet和DenseNet等模型中的剩余连接已被证明有助于优化架构中的更深层
- 局部表征块中使用深度卷积层
- 方法: 局部表征块中的3x3卷积层被深度3x3卷积层替换
- 目的: 进一步减少参数
- 在融合块中用1x1卷积层替换3x3卷积层
-
模型构建块
-
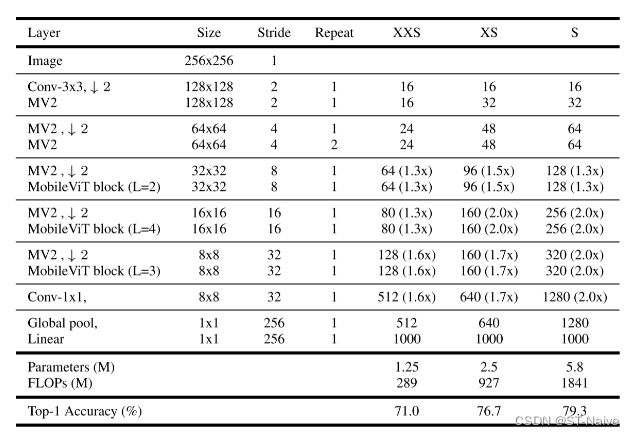
-
允许通过增加层的宽度(通道数量)来扩展MobileViTv 3架构。表中为MobileViTv 3-S、XS和XXS架构,其每层中具有输出通道、缩放因子、参数和FLOP
-
4.2.3 模型表现
- 200万参数下的模型:MobileViTv 3-XXS和MobileViTv 3 -0.5的性能优于其他MobileViT变体
- 2-4百万参数之间的模型:MobileViTv 3-XS和MobileViTv 3 -0.75的性能优于该系列的所有型号
- 4-8百万参数之间的模型:MobileViTv 3-S在此参数范围内达到最高精度
- 超过800万个参数的模型:MobileViTv 3-S参数量小,精确度高
5 DETR
5.1 整体框架
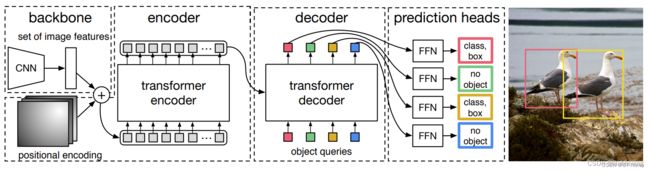
5.1.1 resnet50
-
detr的主干网络使用的是我们熟悉的resnet系列,之前没有系统讲过,正好借此机会复习一下
-
Conv Block
-
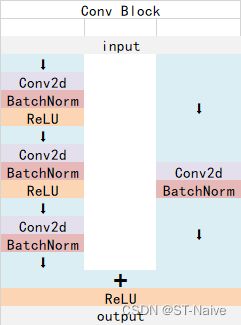
-
如图所示,conv block的残差边存在卷积,可以用来调整输出的大小
-
也就是说,conv block的输入输出不同,可以改变网络维度,但不能串联
-
-
Identity Block
-
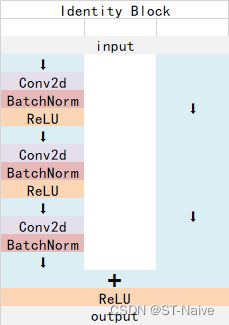
-
残差变不带conv,输入输出相同,主要起加深网络的作用,可串联
-
-
resnet50总体结构
-
input(3,800,800) zeropad Conv2d stride=2(64,400,400) BatchNorm ReLU MaxPool stride=2(64,200,200) Conv Block(256,200,200) Identity Block(256,200,200) Identity Block(256,200,200) Conv Block stride=2(512,100,100) Identity Block(512,100,100) Identity Block(512,100,100) Identity Block(512,100,100) Conv Block stride=2(1024,50,50) Identity Block(1024,50,50) Identity Block(1024,50,50) Identity Block(1024,50,50) Identity Block(1024,50,50) Identity Block(1024,50,50) Conv Block stride=2(2048,25,25) Identity Block(2048,25,25) Identity Block(2048,25,25)
-
5.1.2 encoder
- 其实DETR并没有采用ViT的结构,它只不过把neck部分换成了transformer
- 位置编码
- 框架中的positional encoding,其实就是position embedding的思想,为所有特征添加位置信息,使得网络具有区分不同区域的能力
- 输入序列
- 由于我们最终输出的是25×25×2048,通道数过多,所以要先用1×1的conv将通道维度压缩成256,再对高宽维度进行平铺
- 压缩后得到batch × 625 × 256
- 所以,这里面encoder的实际作用,其实是对特征序列的加强,而后面的decoder则是扮演分类器的角色
5.1.3 decoder
- 那么,如何对特征序列进行分类呢?需要用到object queries,一个特殊的可学习的查询向量
- 实际操作就是,先通过Embedding类创建一个query_embed,作为decoder的positional encodeing
- 而查询向量本身长度固定,即输入decoder的为l × batch × 256
- 网络内部部分与transformer大致相同,输出序列同样为l × batch × 256
5.1.4 预测头
- 源码里最后的预测头其实就两个,一个负责输出分类信息,另一个负责回归框信息
- 其中,分类信息有class+1个,因为要包含背景
- 回归框的话用到的是MLP(全连接神经网络/多层感知机),下面着重讲一下这个东西
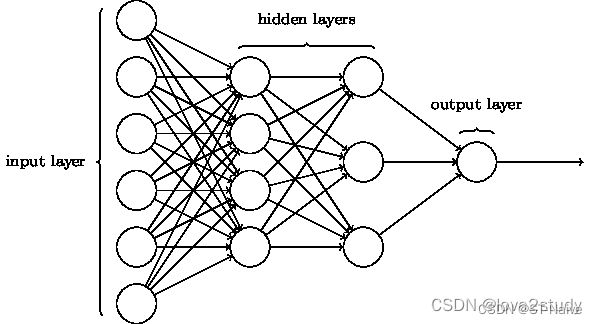
- MLP属于前馈神经网络的一种,由输入层、隐藏层和输出层组成
- 从源码上看,这三层网络全部为全连接层,中间会有激活函数
- MLP最后返回的是中心点坐标以及宽高,所以后面还需要一个解码过程,把值一一取出来
- 从这以点上看,DETR的预测头其实是基于point的
5.2 训练策略
- 正样本的匹配过程
- 这里用到的匹配算法叫做匈牙利算法。由于分类的预测结果需要匹配,n个真实框要去匹配n个预测结果,所以需要算法找寻最合适的n值
- 实际做法就是构建一个l×gt的cost矩阵,其中l为预测结果数,gt是真实框数。该矩阵可分为三部分:
- 计算分类成本。获得预测结果中,该真实框类别对应的预测值,如果预测值越大代表这个预测框预测的越准确,它的成本就越低。
- 计算预测框和真实框之间的L1成本。获得预测结果中,预测框的坐标,将预测框的坐标和真实框的坐标做一个l1距离,预测的越准,它的成本就越低。
- 计算预测框和真实框之间的IOU成本。获得预测结果中,预测框的坐标,将预测框的坐标和真实框的坐标做一个IOU距离,预测的越准,它的成本就越低。
- loss计算
- Reg部分,由第2部分可知道每个真实框对应的预测框,获取到每个真实框对应的预测框后,利用预测框和真实框计算l1的损失和giou损失。
- Cls部分,由第2部分可知道每个真实框对应的预测框,获取到每个真实框对应的预测框后,取出该预测框的种类预测结果,根据真实框的种类计算交叉熵损失。没有匹配上真实框的预测框作为背景。
写在后面
- 其实本来就单纯想看看transformer的,没想到看了一堆东西
- 3D目标检测里,21-22年用transformer当backbone的有很多,看一看其实还是有好处的
- 感觉毕设如果还是要做故障诊断的话,可以先去借鉴一下多模态的处理方法,主干就选CNN+ViT
- 算了,多余的话就不说了,要去看R-CNN和centerpoint了