Spark Scala大数据编程实例
一、Scala
1.1、Scala简介
Scala是一门现代的多范式编程语言,平滑地集成了面向对象和函数式语言的特性,旨在以简练、优雅的方式来表达常用编程模式。Scala的设计吸收借鉴了许多种编程语言的思想,只有很少量特点是Scala自己独有的。Scala语言的名称来自于“可伸展的语言”,从写个小脚本到建立个大系统的编程任务均可胜任。Scala运行于Java平台(JVM,Java 虚拟机)上,并兼容现有的Java程序,Scala代码可以调用Java方法,访问Java字段,继承Java类和实现Java接口。在面向对象方面,Scala是一门非常纯粹的面向对象编程语言,也就是说,在Scala中,每个值都是对象,每个操作都是方法调用。
1.2、Scala特点
Spark的设计目的之一就是使程序编写更快更容易,这也是Spark选择Scala的原因所在。总体而言,Scala具有以下突出的优点:
1、Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统;
2、Scala语法简洁,Scala表达能力强,一行代码抵得上多行Java代码,开发速度快,能提供优雅的API;
3、Scala兼容Java,可以访问庞大的Java类库,例如:操作mysql、redis、freemarker、activemq等等,运行速度快,且能融合到Hadoop生态圈中。
4、Scala可以开发大数据应用程序,例如: Spark程序、Flink程序等等...
1.3、Scala与Spark的关系
Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言,因此,若仅仅是编写Spark程序,并非一定要用Scala。Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),因此,在Spark Shell中可进行交互式编程(即表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改),这样可以在很大程度上提升开发效率。
1.4、Scala程序与Java程序对比
1.4.1、程序的执行流程对比
Java程序编译执行流程

Scala程序编译执行流程
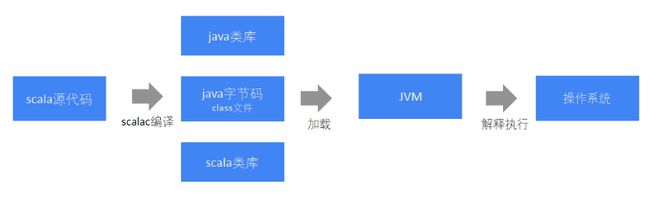
1.4.2、代码对比
需求:定义一个学生类, 属性为: 姓名和年龄, 然后在测试类中创建对象并测试。
Java代码:
//定义学生类
public class Student{
private String name; //姓名
private int age; //年龄
//空参和全参构造
public Student(){}
public Student(String name, int age){
this.name = name;
this.age = age;
}
//getXxx()和setXxx()方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//测试类
public class StudentDemo {
public static void main(String[] args) {
Student s1 = new Student("张三", 23); //创建Student类型的对象s1, 并赋值
System.out.println(s1); //打印对象, 查看结果.
}
}Scala代码:
case class Student(var name:String, var age:Int) //定义一个Student类
val s1 = Student("张三", 23) //创建Student类型的对象s1, 并赋值
println(s1)二、在CentOS7中安装Scala和Spark
2.1、准备工作
在下载安装Scala和Spark之前,需要在centos7中安装JDK和Hadoop,我参考的下面链接安装的,详细教程可以参考https://blog.csdn.net/m0_67393828/article/details/123773184
2.2、下载Scala和Spark
Scala下载网址:https://www.scala-lang.org/download/all.html(可以根据自己需要的版本自行安装,我安装的是2.12.8版本)

Spark下载网址:http://spark.apache.org/downloads.html

2.3、安装Scala和Spark
我是将scala和spark下载到本地电脑,用共享文件夹形式上传到虚拟机中,在虚拟机的home文件夹中提前建立好需要的文件夹,方便之后配置环境变量。

解压安装Scala
cd /mnt/hgfs # 进人共享文件夹
ls
cd /hadoop/scala/ # 共享文件夹的地址,根据实际情况
ls
sudo tar -zxvf scala-2.12.8.tgz -C /home/master/scala/ # 注意自己的scala版本和安装地址解压安装Spark
cd /mnt/hgfs # 进人共享文件夹
ls
cd /hadoop/spark/ # 共享文件夹的地址,根据实际情况
ls
sudo tar -zxvf spark-3.2.3-bin-hadoop3.2.tgz -C /home/master/spark/ # 注意自己的spark版本和安装地址2.4、配置环境变量
更改/etc/profile/文件
sudo vim /etc/profile/在文件下面加上
#scala
export SCALA_HOME=/home/master/scala/scala-2.12.8
export PATH=${SCALA_HOME}/bin:$PATH
#spark
export SPARK_HOME=/home/master/spark/spark-3.2.3-bin-hadoop3.2
export PATH=${SPARK_HOME}/bin:$PATH保存后重启环境并验证是否安装成功
source /etc/profile
scala -version若出版本号,则说明scala安装成功
进入到spark配置目录conf文件下,以spark为我们创建好的模板创建一个spark-env.h文件,命令是
cp spark-env.sh.template spark-env.sh
sudo vim spark-env.sh然后更改spark-env.sh文件输入
export SPARK_MASTER_IP=master # 目录根据自己的来,SPARK_MASTER_IP=自己的master名
export SCALA_HOME=/home/master/scala/scala-2.12.8
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/home/master/jdk/jdk1.8.0_361
export HADOOP_HOME=/home/master/hadoop/hadoop-3.2.4
export HADOOP_CONF_DIR=/home/master/hadoop/hadoop-3.2.4/etc/hadoop以spark为我们创建好的模板创建一个workers文件(好多教程写的是slaves,但spark之后的版本更换为workers),命令是
cp workers.template workers
sudo vim workers更改workers文件输入(根据自己的虚拟机名修改即可)
master
slave1
slave22.5、启动Spark集群
进入到spark的sbin目录下输入下面命令即可启动
./start-all.sh使用jps命令查看是否启动成功,有woker和master节点代表启动成功,如图:
master节点

slave1节点

slave2节点

三、运行实例代码
3.1、使用Scala解释器
在Shell命令提示符界面中输入“scala”命令后,会进入scala命令行提示符状态,可以使用命令“:quit”退出Scala解释器,如下图所示:

第一个Scala程序:HelloWorld
cd /home/master/scala/mycode
sudo vim test.scala
# 在文件中输入下面代码
object HelloWorld{
def main(args: Array[String]){
println("Hello,World!")
}
}
scalac test.scala #编译的时候使用的是Scala文件名称
scala -classpath . Helloworld #执行的时候使用的是HelloWorld对象名称注意,上面命令中一定要加入"-classpath .",否则会出现"No such file or class on classpath:HelloWorld"

3.2、Scala声明和变量
Scala有两种类型的变量:
·val:是不可变的,在声明时就必须被初始化,而且初始化以后就不能再赋值;
·var:是可变的,声明的时候需要进行初始化,初始化以后还可以再次对其赋值。
scala> val myStr = "Hello World!"
myStr: String = Hello World!
scala> val myStr2 : String = "Hello World!"
myStr2: String = Hello World!
scala> val myStr3 : java.lang.String = "Hello World!"
myStr3: String = Hello World!
scala> import java.lang._
import java.lang._
scala> println(myStr)
Hello World!
scala> myStr = "Hello Scala!"
:15: error: reassignment to val
myStr = "Hello Scala!"
^ 3.3、Scala常用数据类型
Scala与Java有着相同的数据类型,下表列出了Scala支持的数据类型:
数据类型 |
描述 |
Byte |
8位有符号补码整数。数值区间为 -128 到 127 |
Short |
16位有符号补码整数。数值区间为 -32768 到 32767 |
Int |
32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
Long |
64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
Float |
32 位, IEEE 754 标准的单精度浮点数 |
Double |
64 位 IEEE 754 标准的双精度浮点数 |
Char |
16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
String |
字符序列 |
Boolean |
true或false |
上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。
在Scala中,所有的值都有一个类型,包括数值和函数。如下图所示,说明了Scala的类型层次结构。

Any是Scala类层次结构的根,也被称为超类或顶级类。Scala执行环境中的每个类都直接或间接地从该类继承。该类中定义了一些通用的方法,列如equals()、hashCode()和toString()。Any有两个直接子类:AnyVal和AnyRef。
AnyVal表示值类型,有9种预定义的值类型,它们是非空的Double、Float、Long、Int、Short、Byte、Char、Unit和 Boolean。Unit是一个不包含任何信息的值类型,和Java语言中的Void等同,用作不返回任何结果的方法的结果类型。Unit 只有一个实例值,写成()。
AnyRef表示引用类型。所有非值类型都被定义为引用类型。Scala中的每个用户定义类型都是AnyRef的子类型。AnyRef对应于Java中的Java.lang.Object。
3.4、用Scala语言编写Spark独立应用程序
3.4.1、安装sbt
使用Scala语言编写的Spark程序,需要使用sbt进行编译打包。Spark中没有自带sbt,需要单独安装。可以到“http://www.scala-sbt.org”下载sbt安装文件sbt-1.3.8.tgz。
新建一个终端,在终端中执行如下命令:
$ sudo mkdir /usr/local/sbt # 创建安装目录
$ cd /munt/hgfs/ # 利用共享文件夹传输
$ cd /hadoop/sbt/ # 共享文件夹的地址,根据实际情况
$ sudo tar -zxvf ./sbt-1.3.8.tgz -C /usr/local
$ cd /usr/local/sbt
$ sudo chown -R master /usr/local/sbt # 此处的master为系统当前用户名
$ cp ./bin/sbt-launch.jar ./ #把bin目录下的sbt-launch.jar复制到sbt安装目录下接着在安装目录中使用下面命令创建一个shell脚本文件,用于启动sbt:
$ vim /usr/local/sbt/sbt该脚本文件中的代码如下:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -
XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"保存后,还需要为该Shell脚本文件增加可执行权限:
$ chmod u+x /usr/local/sbt/sbt然后,可以使用如下命令查看sbt版本信息:
$ cd /usr/local/sbt
$ ./sbt sbtVersion
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option
MaxPermSize=256M; support was removed in 8.0
[warn] No sbt.version set in project/build.properties, base directory:
/usr/local/sbt
[info] Set current project to sbt (in build file:/usr/local/sbt/)
[info] 1.3.83.4.2、编写Scala应用程序代码
在终端中执行如下命令创建一个文件夹sparkapp作为应用程序根目录:
$ cd ~ # 进入用户主文件夹
$ mkdir ./sparkapp # 创建应用程序根目录
$ mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构下面使用vim编辑器在“~/sparkapp/src/main/scala”下建立一个名为SimpleApp.scala的Scala代码文件,命令如下:
$ cd ~
$ vim ./sparkapp/src/main/scala/SimpleApp.scala在文件中输入下面代码:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your
system
val conf = new SparkConf().setAppName("Simple Application") # 生成配置的上下文信息,Simple Application为应用程序名
val sc = new SparkContext(conf) # 生成SparkContext对象
# 加载文本文件生成RDD文件,每一元素对应文件中的一行
val logData = sc.textFile(logFile, 2).cache()
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}3.4.3、用sbt打包Scala应用程序
SimpleApp.scala程序依赖于Spark API,因此,需要通过sbt进行编译打包。 首先,需要使用vim编辑器在“~/sparkapp”目录下新建文件simple.sbt,命令如下:
$ cd ~
$ vim ./sparkapp/simple.sbtsimple.sbt文件用于声明该独立应用程序的信息以及与 Spark的依赖关系,需要在simple.sbt文件中输入以下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"接下来,可以通过如下代码将整个应用程序打包成 JAR(首次运行时,sbt会自动下载相关的依赖包),并返回以下信息:
$ cd ~/sparkapp #一定把这个目录设置为当前目录
$ /usr/local/sbt/sbt package
[info] Set current project to Simple Project
[info] Updating {file:/home/hadoop/sparkapp/}sparkapp...
[info] Done updating.
[info] Compiling 1 Scala source to /home/hadoop/sparkapp/target/...
[info] Packaging /home/hadoop/sparkapp/target/scala-2.11/...
[info] Done packaging.
[success] Total time: 17 s, completed 2020-1-27 16:13:563.4.4、通过spark-submit运行程序
最后,可以将生成的JAR包通过spark-submit提交到Spark中运行,命令如下:
$/usr/local/spark/bin/spark-submit --class "SimpleApp"
~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"最终得到的结果如下:
Lines with a: 62, Lines with b: 31