Gumbel-Softmax简介
一、Gumbel Softmax trick的使用场景
1. argmax简介
在NLP领域的强化学习或者对抗学习中,token的生成是离散的。比如,一个token的产生是一个大小为vocab size的one-hot向量。比如,对于character level的token: [ 1 , 0 , 0 , 0 , . . . , 0 ] [1, 0, 0, 0, ..., 0] [1,0,0,0,...,0]代表a, [ 0 , 1 , 0 , 0 , . . . , 0 ] [0, 1, 0, 0,..., 0] [0,1,0,0,...,0] 代表b。具体选择哪个token就根据输出的每个维度的大小,选择预测概率最大作为输出token,即 a r g m a x arg \ max arg max操作。
如图:
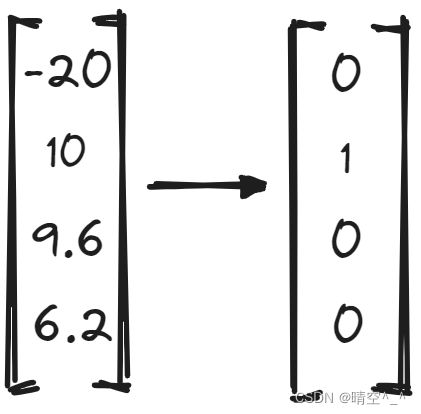
以四维向量 v v v为例,对其做argmax操作,得到的one-hot vector为 [ 0 , 1 , 0 , 0 ] [0, 1, 0, 0] [0,1,0,0]。虽然该方法可以得到正确的分类,但是显而易见,argmax是不可导的。
2. softmax简介
在一般的分类问题中,为了解决argmax不可导的问题,通常选择softmax方法,softmax即是argmax的光滑近似。这种方法通过把向量归一化,既可以计算梯度,同时值的大小还可以代表概率的含义。
如图:

在经过softmax后,既不会改变动作或者说类别的选取,同时softmax还倾向于让最大值的概率显著大于其他值(比如10和6.2在经过softmax后变成了0.59和0.01),这样更有利于将网络训练成一个one-hot形式。
但是,softmax还有一个问题,就是softmax后的向量并不能真正显示概率的含义。比如对于两个softmax后的向量 [ 0 , 0.59 , 0.39 , 0.01 ] [0, 0.59, 0.39, 0.01] [0,0.59,0.39,0.01]和 [ 0 , 0.99 , 0.01 , 0 ] [0, 0.99, 0.01, 0] [0,0.99,0.01,0],两者都是选择第二个分类,但是其在概率上的表示可谓是天差地别。
因此,我们需要一种算法,既可以选出动作,还要遵从概率的含义。这时,最直觉的办法就是根据概率采样,这既可以选出动作,又遵从概率的含义,但是,采样不能求导。
3. 为什么采样过程需要求导
对于一般的分类问题,我们只需计算最后一层的softmax,然后与标签(one-hot vector)求交叉熵损失就可以完成网络的训练,这种问题其实是不需要sample的。因为sample就是最终的目的,生成的one-hot就是最后要完成的任务,是固定的(即标签)。
但是对于另一些问题,sample只是中间的步骤,sample是不固定的(即没有具体的one-hot),是需要训练的,如VAE和GAN,这个时候sample变成了一种优化的任务,因此必须要保证其可导性。
二、Reparameterization Trick
我们知道,模型的训练图需要各处都能传回梯度进行训练,而采样这一操作会打破这一链条。采样的意义无非是引入随机性。既然这样,就把“随机性的引入”和“计算图的构建”这两个属性剥离开。Reparameterization Trick就是这个思路。
以离散情况为例:
假设从一个模型中得到一个概率分布 p p p,需要从p中得到一个具体的sample进行后面的计算。假设 p = [ 0.1 , 0.6 , 0.1 , 0.2 ] p=[0.1, 0.6, 0.1, 0.2] p=[0.1,0.6,0.1,0.2],分别对应四个不同的选择,现在需要按概率进行采样。直觉上来说,直接选择第二个就行了,但是真是这样吗。仔细想一下,我们现在是要训练模型,模型还没有训练好, p p p的输出分布也很不靠谱,没道理选最大的。因此,需要为sample引入随机性。sample过程引入随机性的意义就是“搜索”,让模型“搜索”所有可能的选择,然后根据loss回调参数,最终训练到合理的sample策略。
为了在采样的同时不破坏计算图的梯度传播,我们不直接在 p p p上进行随机操作,而是引入Gumbel分布,通过它来提供sample需要的随机性。
三、Gumble-Softmax Trick
1. Gumbel Max Trick
Gumbel Max提供了一种从类别分布中采用的算法。
设 z z z是一个分类变量,类概率为 π 1 , π 2 , . . . , π k \pi_1, \pi_2,...,\pi_k π1,π2,...,πk,从类别概率为 π \pi π的分布中提取样本 z z z,加上Gumbel噪声,可得:
z = a r g m a x i [ g i + l o g π i ] z=arg \ max_i[g_i + log \ \pi_i] z=arg maxi[gi+log πi]
其中, g g g是独立同分布的标准Gumbel分布的随机变量。标准Gumbel分布的CDF为 F ( x ) = e − e − x F(x)=e^{-e^{-x}} F(x)=e−e−x。
g i g_i gi通过Gumbel分布求逆从均匀分布中生成,即
g i = − l o g ( − l o g ( ϵ i ) ) , ϵ i ∼ U ( 0 , 1 ) g_i = -log(-log(\epsilon_i )), \ \epsilon_i \sim U(0, 1) gi=−log(−log(ϵi)), ϵi∼U(0,1)
数学上可以证明(网上很多,此处略),这个过程精确等价于依概率 π 1 , π 2 , . . . , π k \pi_1, \pi_2, ..., \pi_k π1,π2,...,πk采样一个类别。即,输出的 z i z_i zi的概率刚好是 π i \pi_i πi。由于现在的随机性已经转移到 U [ 0 , 1 ] U[0,1] U[0,1]上去了,并且 U [ 0 , 1 ] U[0, 1] U[0,1]无未知参数,因此Gumbel Max就是离散分布的一个重参数过程。
考虑到arg max是不可导的,我们这里仍需要argmax的光滑近似,softmax。
2. Gumbel Softmax Trick
y i = e x p ( ( l o g ( π i ) + g i ) / τ ) ∑ j = 1 k e x p ( ( l o g ( π j ) + g i ) / τ ) , f o r i = 1 , . . . , k y_i = \frac{exp((log(\pi_i) + g_i)/\tau )}{\sum^k_{j=1}exp((log(\pi_j) + g_i)/\tau)}, \ for \ i=1, ..., k yi=∑j=1kexp((log(πj)+gi)/τ)exp((log(πi)+gi)/τ), for i=1,...,k
其中,参数 τ > 0 \tau>0 τ>0称为退火参数,它越小结果就越接近one-hot形式(同时梯度消失越严重),越大就越接近均匀分布。
注意:Gumbel Softmax不是采样类别的等价形式,Gumbel Max才是。Gumbel Max可以看做Gumbel Softmax在 τ → 0 \tau \rightarrow 0 τ→0时的极限。因此在应用Gumbel Softmax时,可以先选择较大的 τ \tau τ,之后再慢慢退火到一个接近0的数。
引用:
漫谈重参数:从正态分布到Gumbel Softmax
Gumbel Softmax 是什么?
重参数化技巧