最新模型VMamba:颠覆视觉Transformer,下一代主流Backbone?
论文标题:
VMamba: Visual State Space Model
论文作者:
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
1. 摘要
卷积神经网络(CNN)与视觉Transformer(ViT)是目前最流行的两种视觉表征基础模型。CNN在线性复杂度下,具有惊人的可扩展性。ViTs在性能方面超过了CNN,但是其具有平方复杂度。经深入分析,ViT具有更加强大性能的原因在于:它利用了全局的感受野和动态的权重分配方法。因此,一种既具有ViT全局感知优势,又具有高计算效率的框架需要被提出。受到状态空间模型启发,我们提出了视觉状态空间模型(VMamba),这个模型能够在不破坏全局感受野的前提下,达到线性的计算复杂度。为了解决模型中的方向敏感性问题,我们引入了交叉扫描模块(CSM)。该模块能够遍历图像空间域,将任意视觉图像转化成有序序列。实验结果表明,所提出的VMamba不仅能够在多种视觉感知任务中具有出色的性能,而且随着图像分辨率的增加,VMamba的优势更加明显。
2. 引言
视觉表征学习是计算机视觉领域中最基础的研究问题之一。从深度学习时代开始,视觉表征学习经历了很多重要突破。其中,CNN与ViT是两类基础的深度学习模型,它们在很多的视觉任务中都有应用。虽然这两类模型在视觉表征方面都取得了非常大的成功,但是总体来说ViT的性能相较于CNN来说更优。这是由于ViT具有全局的感受野以及注意力机制所带来的动态权重分配。
然而,注意力机制随着图像的大小具有平方的算法复杂度。这导致在解决下游稠密预测任务时,例如目标检测、语义分割等,算法具有较大的计算开销,。为了解决这个问题,很多提升注意力机制效率的方法被提出。这些方法虽然通过限制移动图像处理窗口的大小和步长提高了注意力的计算效率,但它们通常都会破坏全局感知的范围。这激励了我们去设计一种新的具有线性复杂度的视觉表征基础模型,同时保持全局感知和动态权重分配的优势。
受到最近提出的状态空间模型启发,我们引入了视觉状态空间模型(VMamba)来进行高效的视觉表征学习。VMamba降低注意力机制复杂度的概念来源于“具有选择性的扫描状态空间序列模型”(Selective Scan Space State Sequential Model ,S6)。S6原来应用于自然语言处理领域,与传统的注意力机制不同,S6使得在序列中的每一个元素能够与任意一个之前扫描过的样本交互。这样使得注意力机制的平方复杂度降低为线性。
然而,由于视觉数据的非因果特性,直接将S6方法应用于分块并展平的视觉图像上会导致全局感受野的损失。这是由于没有经过扫描的图像片间的注意力关联没有被估计。论文中将这一现象称为“方向敏感”问题。为了解决这一问题,论文提出了“交叉扫描模块”(Cross-Scan Module,CSM)。与传统按照行或列遍历的方式不同,CSM采用了“四向”扫描策略,即从图像的四角开始,曲折行进至对角(如下图所示)。这种策略保证了在特征图种的每个元素都能够融合其他位置和方向的元素。因此,这种策略可以使模型在拥有全局感知野的同时,具有线性的计算复杂度。
图1|Attention机制与所提出的CSM对比©️【深蓝AI】编译
论文在多种视觉任务上开展了详尽的实验来验证所提出VMama的有效性。如图2所示,在ImageNet-1K数据集上,相比于Resnet、ViT以及Swin模型,VMamba具有更强或者至少相当的性能。论文还针对下游稠密任务进行了实验,例如:VMambaTiny/Small/Base (分别有 22/44/75 M 参数)在COCO数据集上,使用MaskRCNN检测器达到了 46.5%/48.2%/48.5%的 mAP,并且在ADE20K数据集上使用UperNet达到了 47.3%/49.5%/50.0%的mIoU。这些结果表明了所提出的VMamba是一个性能很强的基础模型。进一步,当输入图像大小越来越大时,尽管ViT取得了更佳的性能,ViT的FLOP数目的增长速度显著高于CNN。而论文所提出的VMamba与ViT相比,在达到相当性能的同时,其FLOP数目增长更少,为近似线性增长。

图2|VMamba在ImageNet-1K上整体性能与其他主流算法模型的对比©️【深蓝AI】编译
本次工作的贡献点总结如下:
●VMamba,一种视觉状态空间模型,具有全局感受野与动态权重的视觉表征学习。
VMamba提供了一种视觉基础表征模型的选择,是CNN和ViT的扩展。●引入了交叉扫描模块(CSM),解决了1维序列扫描到2维图像扫描的迁移过度问题,扩展应用S6模型于视觉数据,并且不破坏全局感受野的特性。
●开展了多种视觉任务实验,包括图像分类、目标检测以及语义分割。实验结果表明了VMamba成为鲁棒视觉表征基础模型的巨大潜力。
3. 相关工作
深度神经网络不断推动这视觉感知研究的发展。其中有两个代表性的视觉基础模型,它们是CNN和ViT。近期,状态空间模型(State Space Models, SSMs)在长序列上提升计算效率的成功吸引了NLP和CV领域的广泛关注。此论文沿着这条路线并提出了VMamba,一种基于状态空间模型的视觉表征模型。VMamba的贡献在于提供了一种除了CNN和ViT之外的可用基础模型。
卷积神经网络(CNN) 是视觉感知领域里程碑式的模型。早期的CNN应用于一些基础的任务,了例如识别手写数字和文字分类。CNN最显著的特点在于卷积核的的设计,卷积核用于获取感受野内的视觉信息。随着GPU的发展以及大规模数据集的兴起,更深且更高效的网络模型被提出,增强了各种视觉任务的表现性能。除此之外,更加先进的卷积算子或者网络结构也被相继提出。
视觉Transformer(ViT) 是从NLP领域改进而来的。其成为了最有前景的视觉基础模型之一。早期的ViT模型一般需要大规模的数据集训练。后来,DeiT使用了模型训练中的技巧以解决优化过程中的问题,越来越多的研究在网络设计中引入了视觉感知的归纳偏置。例如,CV社区提出了多层级ViT来逐渐减少在Backbone中的特征分辨率。此外,其他研究提出把CNN中的一些优势融入进ViT中,例如将卷积算子引入ViT中,在网络结构中结合CNN和ViT模块。
状态空间模型(SSM) 是近期所提出的模型。深度学习引入了SSM作为状态空间转换的方式。受到连续控制系统中状态空间模型的启发,结合HiPPO初始化方法,LSSL模型展示了SSM在解决序列长期依赖问题上的潜力。然而,由于状态表示的计算开销和存储消耗过大,LSSL在实际问题中很难被应用。为了解决这个问题S4模型被提出将参数归一化为对角结构。自此之后,很多不同结构的状态空间模型被提出,例如复数对角结构,支持多输入多输出结构,选择性机制等。这些模型后来融合进了大规模的视觉表征模型。
这些模型主要聚焦于处理长序列与具有因果性的数据上,例如语言理解、像素级别的一维图像分类,很少有研究注意到视觉表征领域。
4. 方法
本项研究涉及的方法主要为VMamba涉及的基础概念和理论,包括状态空间模型、离散化过程以及选择性扫描机制。进而论文介绍了VMamba中的核心元素——二维状态空间模型。最后,论文展示了VMamba的整体架构。
4.1 基础概念
状态空间模型:
状态空间模型通常用来描述时变系统,其将系统输入 x ( t ) ∈ R L x(t) \in \mathbb{R}^L x(t)∈RL映射至系统响应 y ( t ) ∈ R L y(t) \in \mathbb{R}^L y(t)∈RL。数学上把状态空间模型描述为如下的微分方程形式:
h ′ ( t ) = A h ( t ) + B x ( t ) y ( t ) = C h ( t ) + D x ( t ) \begin{aligned} & h^{\prime}(t)=A h(t)+B x(t) \\ & y(t)=C h(t)+D x(t)\end{aligned} h′(t)=Ah(t)+Bx(t)y(t)=Ch(t)+Dx(t)
其中 A ∈ C N × N , B , C ∈ C N , D ∈ C 1 A \in \mathbb{C}^{N \times N}, B, C \in \mathbb{C}^N,D \in \mathbb{C}^1 A∈CN×N,B,C∈CN,D∈C1, N N N为状态空间的变量数目。
微分方程离散化:
对于深度学习来说,所需要的状态转移是离散而非连续的。因此,状态的离散化非常重要,在此我们考虑输入为 x k ∈ R L × D x_k \in \mathbb{R}^{L \times D} xk∈RL×D,这里指的是具有长度 L L L的 D D D维信号流。那么上述微分方程可以离散化为如下形式:
h k = A ˉ h k − 1 + B ˉ x k , y k = C ˉ h k + D ˉ x k , A ˉ = e Δ A , B ˉ = ( e Δ A − I ) A − 1 B , C ˉ = C \begin{aligned} h_k & =\bar{A} h_{k-1}+\bar{B} x_k, \\ y_k & =\bar{C} h_k+\bar{D} x_k, \\ \bar{A} & =e^{\Delta A}, \\ \bar{B} & =\left(e^{\Delta A}-I\right) A^{-1} B, \\ \bar{C} & =C\end{aligned} hkykAˉBˉCˉ=Aˉhk−1+Bˉxk,=Cˉhk+Dˉxk,=eΔA,=(eΔA−I)A−1B,=C
其中 B , C ∈ R D × N , Δ ∈ R D B, C \in \mathbb{R}^{D \times N}, \Delta \in \mathbb{R}^D B,C∈RD×N,Δ∈RD。实际上,对于 B ˉ \bar{B} Bˉ的计算在实际中通常利用一阶泰勒展开作线性逼近,可近似为如下形式:
B ˉ = ( e Δ A − I ) A − 1 B ≈ ( Δ A ) ( Δ A ) − 1 Δ B = Δ B \bar{B}=\left(e^{\Delta A}-I\right) A^{-1} B \approx(\Delta A)(\Delta A)^{-1} \Delta B=\Delta B Bˉ=(eΔA−I)A−1B≈(ΔA)(ΔA)−1ΔB=ΔB
选择性扫描机制:
S6方法中选择性扫描机制指的是在状态转移中的 B ∈ R B × L × N , C ∈ R B × L × N , Δ ∈ R B × L × D B \in \mathbb{R}^{B \times L \times N},C \in \mathbb{R}^{B \times L \times N},\Delta \in \mathbb{R}^{B \times L \times D} B∈RB×L×N,C∈RB×L×N,Δ∈RB×L×D都来自于输入数据 x ∈ R B × L × D x \in \mathbb{R}^{B \times L \times D} x∈RB×L×D。这表明了状态空间模型能够利用在输入数据中的上下文信息,保证在机制中的权重一直是动态的。
4.2 二维选择性扫描
在引言和相关工作中,论文已经介绍了S6方法在直接应用在二维图像上的问题——“方向敏感性”问题,会导致全局感受野的信息损失。为解决这一问题,论文提出了2D选择性扫描的方法。其提出的“四向”扫描流程非常直观,即分别从图像分片的左上向右下,左上向右下,左下向右上,右上向坐下四个方向进行扫描,如图1所示。扫描完成后,我们将“四向”扫描的结果进行序列化,接着使用状态空间模型进行选择性扫描,最后恢复融合成一张图像,流程如下图所示。
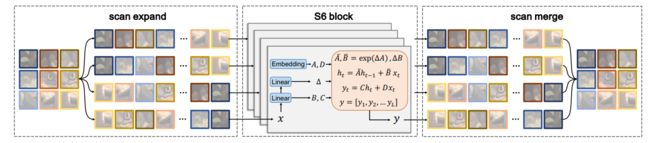
图3|二维选择性扫描机制SS2D的流程图©️【深蓝AI】编译
上面所介绍的二维选择性扫描,即CSM模块,就是VMamba中的核心模块。这个模块主要代替了Transformer中的注意力机制,在保留全局感知的情况下保持了线性的计算复杂度。
4.3 VMamba模型
VMamba的Tiny版本整体结构如下所示。其中最为核心的就是VSS Block模块。VSS Block模块所替换的就是Transformer中的Encoder模块。其最大的区别就在于将Attention替换成了SSD二维选择性扫描。

图4|VMamba-Tiny的网络结构示意图©️【深蓝AI】编译
具体的Tiny/Small/Base网络架构如下表所示:

表1|VMamba Tiny/Small/Base的具体网络架构设计、参数量以及FLOP数量©️【深蓝AI】编译
5. 实验验证
论文的实验主要针对视觉任务进行开展,分别在ImageNet-1K数据集上进行了图像分类任务,在COCO数据集上进行了目标检测任务,在ADE20K进行了语义分割任务。在此基础上进一步分析了VMamba的优势。
5.1 图像分类任务——ImageNet-1K
在图像分类任务中,VMamba从0开始训练了300个epoch,与其他模型结果对比如下表所示。对比CNN方法,VMamba的准确性更高;对比ViT方法,VMamba在达到更优或者相当的准度性上,所需要的FLOP数量显著减小;对比之前的状态空间模型工作,VMamba的准确性更高。

表2|VMamba 在图像分类任务上与其他算法模型的对比©️【深蓝AI】编译
5.2 目标检测任务——COCO
在图像训练任务中,VMamba在图像分类任务训练的基础上进行了12个和36个epoch的fine-tune。结果如下表所示。对比CNN方法,VMamba的性能更好;对比ViT方法,VMamba在达到更优或者相当的性能上,所需要的FLOP数量显著减小;对比之前的状态空间模型工作,VMamba的性能更好。

表3|VMamba 在目标检测任务上与其他算法模型的对比©️【深蓝AI】编译
5.3 语义分割任务——ADE20K
在语义分割任务中,VMamba在UperHead的预训练模型上进行了fine-tune。结果如下表所示。对比CNN方法,VMamba的性能更好;对比ViT方法,VMamba在达到更优或者相当的性能上,所需要的FLOP数量显著减小;对比之前的状态空间模型工作,VMamba的性能更好。

表4|VMamba 在语义分割任务上与其他算法模型的对比©️【深蓝AI】编译
5.4 实验结果分析
在感受野的有效面积上,如下图所示,VMamba是唯一一个在线性复杂度下可以实现全局感受野的模型。

图5|VMamba-Tiny 在有效感受野面积上与其他算法模型对比©️【深蓝AI】编译
如下图所示,随着图像分辨率的上升VMamba的性能相较于其他算法模型更优,且增加的FLOP数量更少,计算效率更高。

图6|随着图像分辨率的增大,VMamba 在性能和FLOP数量上与其他算法模型对比©️【深蓝AI】编译
6. 总结
此论文提出的VMamba主要将状态空间模型引入了图像处理中,在保持全局感受野的情况下,通过CSM的设计替代了Attention机制,降低计算复杂度至线性。实验结果也表明,VMamba有替代ViT成为下一个主流视觉表征模型Backbone的潜力。
编译|Frank
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。