学内核之十一:ARM64屏障指令使用指南
关于屏障指令,主要是与乱序有关。特别是在内核开发中,这是一个非常重要的主题。屏障由乱序引起,乱序则是由优化引起。
自从摩尔定律不断被逼近极限,半导体的优化不再单纯通过提升频率来实现。多核心、并发执行变成了主流的优化思路。
让代码并发,有多种方案。一种是代码编写者。通过将代码之间的逻辑关系梳理,让代码做到并发执行。分而治之就是这种思路的典型代表。
写代码时就考虑并发,更多是上层的逻辑和数据依赖的解除。因为软件的复杂性,编写者水平的差异等,这种方法更多是在较高的层次发挥作用。工业实践中,很少考虑微观层面的依赖关系。比如变量之间的前后优化关系,这方面很琐碎,小范围很难起到明显的优化效果。我们还是将代码看成顺序执行来理解和实现业务逻辑。
真正让这种微观层面的优化发挥效果的是编译器的优化。最直观的,这是一种全量的处理,所有被编译的源代码都会被统一处理,因此可以积少成多,达到整体的优化效果。另外,工具处理也明显提升了效率。
为了并发,编译器的优化中有一项策略是乱序。编译器会根据数据的依赖关系,结合硬件架构的缓存特性,对代码进行重排。重排后的代码,并不改变工作逻辑,但是会提升执行效率。举个我们了解的统筹数学方面的例子来类比。假设我们要完成两件事,烧水和炒菜。我们可以先烧水后炒菜,也可以先炒菜后烧水,其实还可以打乱这个顺序,比如烧水的时候,完成切菜的准备工作。这样总体来看,还是正常完成了烧水和炒菜这两件事,但是穿插的做法,因为并行,提升了效率,减少了总的时间花费。
事物都有两面性,编译器的优化带来性能提升的同时,可能还会引入问题。比如内核中,有些指令虽然没有依赖关系,但是却有顺序要求,比如切换任务时候,编译器看到的可能是一堆无关指令的执行,但是实际上,这些指令的作用内在的要求顺序不能变,否则结果就是非预期的。这时候,可能就需要代码编写者明确告诉编译器,这个地方不要做乱序优化。这种操作,一般称为屏障。就是加一个障碍,要求其前后指令的顺序在编译过程中,不要被打乱。
到这里,我们由优化说到了乱序,由乱序说到了屏障。不过我们今天的主角是下面将要讲的屏障。
上面说的乱序是编译乱序。除了编译乱序,还有执行乱序。执行乱序发生在CPU执行指令的过程中。执行乱序的部分原因同编译乱序是类似的。CPU可能先执行当前指令之后的指令,比如因为多核心间cache同步的原因,当前指令的执行需要等待,此时就可以先执行后面的指令,等同步完成,再一起生效。另外,为了提升效率,CPU可能预执行一部分指令,因为内部的执行机构存在多个。这样也可以提升效率。对于这种预执行,可能会预判失败,特别是分支预测时。但是,如果预测成功,则会明显提升效率。
这里,我们只是讲述了一个总体的大概过程,要了解这其中的细节,就需要深入理解代码执行和CPU实现了。
可以看到,执行乱序也是优化的一部分。既然执行存在乱序,那么这种乱序,有没有可能如编译乱序那样,产生问题呢?这就涉及到CPU的一致性了。正常情况来讲,乱序执行只是在最终结果产生之前乱序,真正输出结果的时候,CPU还是按照设计逻辑顺序输出的。也就是乱序执行过程,大部分是CPU内部缓存了指令的执行结果。所以,普通代码的乱序不会产生问题。既然这样说了,那就是留了口子,乱序执行还是有问题存在的。对于强一致性的CPU架构,在部分场景下,CPU并不会乱序,而对于弱一致性的CPU,像ARM,则在很多情况下都存在乱序。比如ARM对读写的各种情况,R-R/R-W/W-R/W-W都可能存在乱序。这样一来,对程序设计者,就有更高的要求。但是,归根结底,无论是强一致性还是弱一致性,代码设计者都要时时有乱序的意识,来规避乱序可能带来的问题。
我们举个例子来看看。考虑这样一种场景,CPU核心先向某个内存地址写入数据,然后通知某个外设到这个地址去读取数据。这个外设比如是DMA。显然,这个操作顺序是要被保证的,如果CPU先执行通知DMA,再写数据,那么DMA拿到的就不是正确数据。
既然执行乱序也可能引入问题(其实是很容易引入问题),那么该如何应对呢?这就需要今天我们要讨论的主角----屏障指令登场了。另外,说明的是,下面的内容参考自宋宝华老师的直播课。
这里,屏障指令的目的不变,仍然是限制乱序,也就是限制CPU执行时不要乱序执行。不过,不同于编译屏障,执行屏障指令,可以在不同层面展开。CPU提供了不同的指令来达成目标。这些指令内容包括了dmb/dsb/isb/ldar/star,参数包括了ish/ishld/ishst/osh/oshld/oshst/sy/ld/st。二者结合,产生了很多的组合,这些组合都属于屏障指令,它们之间有什么区别呢?这就是今天我们要重点说明的。理解这些,对理解内核中的屏障指令,有很大的帮助。
我们先来看看上面的命令。在ARM手册中,有如下的相关说明:




关于参数部分,ARM手册中有相关说明如下:

所谓组合,就是二者结合起来。如下面的例子

采用了 DMB + ISHLD
关于上述屏障指令的执行,宋宝华老师总结了三个要素,分别是:
1 谁和谁之间
2 在什么地方
3 在什么方向
下面,我们一个一个来看。
关于谁和谁的问题,是由指令本身解决的。DMB是内存屏障,也就是规范的内存的访问顺序。DSB是内存和其他部件的,比如和系统寄存器。ISB是流水指令的。比如tlb更新后,需要执行ISB,因为物理地址和虚拟地址的对应改变了,CPU内部流水线没有执行的指令不适合再执行,执行ISB可以清空流水线。
关于什么地方、什么方向的问题,是在参数部分解决的。对于“地方”,如上图所示,手册提到了inner、outer和full system三个域。分别对应了参数的ish、osh和sy/ld/st。对于inner来讲,就是CPU内部执行同一份代码的部件之间的关系。比如各个核心之间。Outer则是CPU核心和其他外部部件,比如DMA、GPU之间。而full system则是不同的CPU子系统之间,比如CPU中的实时核心系统和非实时核心系统之间。
关于方向,有读-读、读-写、写-写以及任意,也就是无论任何方向。分别对应了参数里的LD、ST等。
综合起来,就是谁和谁之间,在什么地方,什么方向要进行屏障处理。比如上面例子中的DMB ISHLD,就是在inner里,内存之间,读-读和读-写时,需要进行屏障。
这里,还有一个没有提到,就是LDAR和STLR。这是一个单方向的屏障指令,效果如手册中的下图所示:
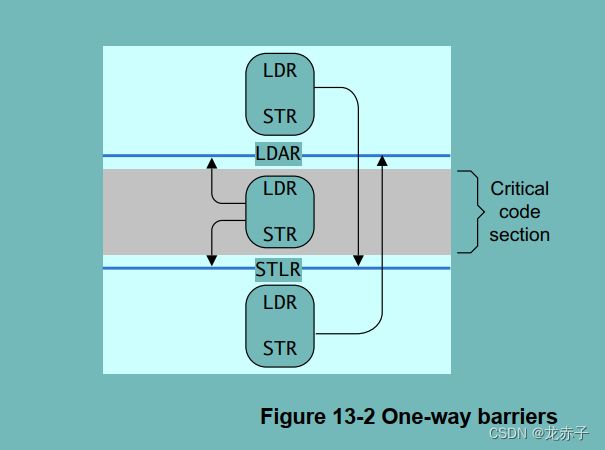
从上图可以看出,这两个指令就像是一个水阀门。LDAR是开口向下的阀门效果:
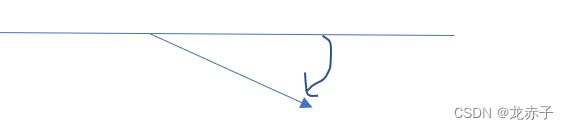
上面的指令可以穿过,但是下面的指令则不行。
而STLR则是开口向上的阀门:

下面的指令可以穿过,但是上面的指令则不行。
如上图所示,当把两个指令放在一起,那么中间的指令既不能向下穿过,也不能向上穿过,自然就限制在这两条指令之间,从而形成一个关键区,类似加锁的效果。
到这里,我们介绍了多个屏障指令。可能有读者就要问了,不就是限制CPU不要乱序执行吗,为啥要这么多的指令。这还是跟效率有关。我们当然可以只提供一个指令,适应所有情况,但是,这必然就会出现杀鸡使用宰牛刀的情况。设想一个工程任务的有限无环图。从开始到结束,中间经过多个节点,每个节点代表一个里程点。一些里程点之间可能存在前后依赖关系。我们可以精细调整依赖关系,从而得到一个最短的工期路径,也可以采用粗放管理模式,简单排序各个节点,从而也得到一个满足依赖要求的工程路径,就如前面炒菜烧水的例子,严格一项一项来。虽然两种方式都能达到目的,但是精细控制显然能够缩短时间。当CPU里,这种指令大量存在时,整体改变的效果就会凸显,这就是典型的量变引起质变。
针对上面这些情况,内核提供了一些封装,编译跨平台的使用。
__smp_load_acquire()
__smp_store_acquire()
这两个是对LDAR 和 STAR的封装
__smp_mb() dmb ish
__smp_rmb dmb ishld
__smp_wmb dmb ishst
上面是对内部域内存访问屏障的封装
dma_rb() dmb osh
dma_rmb() dmb oshld
dma_wmb() dmb_oshst
上面几条指令是用于CPU和外部域直接的内存访问屏障。DMA就是此含义。
mb() dsb sy
rmb() dsb lt
wmb dsb st
上面的几条是用于系统域内存和其他部件,比如系统寄存器访问的屏障指令。
显然,内存屏障指令的可能组合不止这些。不过,就常用情况来看,这些应该是能够满足大部分情况的。如果确实需要特殊组合,可以直接汇编指令完成。
最后,在宋宝华老师的直播课上,提到了上海交大陈海波教授团队发表的一篇有关屏障性能的分析。其中的结论这里就直接复制粘贴了:

鉴于篇幅关系,直播课的例子就不再这里列出了。
最后说两点,1是计算机领域精益求精永不过时;2是将复杂的计算机概念通过简练的语言讲述清楚,这并不容易。宋宝华老师和吴军老师都是这方面的优秀代表。