深度强化学习——基本概念(1)
一、基本概念
1、状态、动作、智能体

可以认为状态就是第一张图的环境,虽然状态和observation还是有区别
智能体Agent是马里奥,动作Action就是上下左右的运动
2、策略函数(policyΠ)
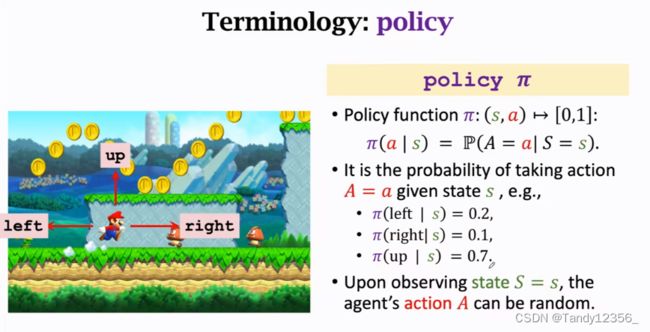
强化学习的重点就是求出这个策略函数,使得在任意一个给定状态S可以做出最应该采取的动作,只要有了policy函数,就可以让超级玛丽自动做出动作来打赢游戏,agent的动作是随机的,根据policy输出的概率来做动作,当然也有确定的policy,那样动作就是确定的了,为了在博弈中取胜,最好使用策略随机,让别人猜不出你的动作,你才有机会赢,所以在很多应用里面,policy最好是个概率密度函数,动作最好是随机抽样得到的
3、奖励
agent每做出一个动作,游戏(环境)就会给一个奖励,这个奖励通常需要我们自己来定义,奖励定义的好坏非常影响强化学习的结果

强化学习的目标就是获得的奖励总和最多

状态转移是随机的,状态转移的随机性是从环境里来的,在这里的环境就是游戏的程序,游戏的程序(环境)来决定下一个状态是什么
比如,超级玛丽向上跳,这个动作是确定的,但是小怪此时此刻有可能向左,也有可能向右,它移动的方向是随机的,这就造成了下一个状态的随机性,即我知道怪物可能往左也可能往右,但是我不确定它往左的概率有多大,所以这个状态转移函数只有环境自己知道,我们玩家是不知道的
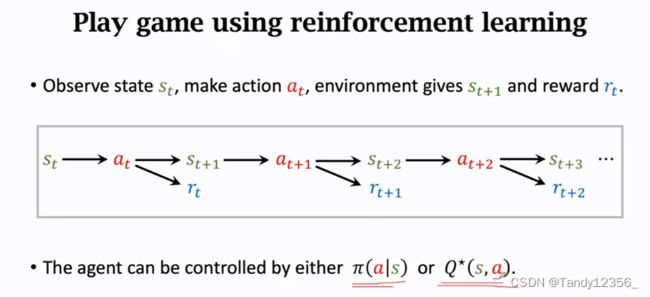
Agent和环境是怎么交互的?
这里的环境是游戏程序,agent是马里奥,状态St是环境告我们的,在超级玛丽的例子里,我们可以把当前屏幕显示的图片看成是状态St,Agent观测到状态St之后要做出一个动作At,动作可以是向左向右走或者是向上跳,Agent做出动作之后,环境会更新状态St为St+1,同时环境还会给Agent一个奖励Rt(+/-/0)

强化学习当中的两个随机性的来源
1、 第一个随机性是从agent的动作来的:因为动作是根据policy函数随机抽样得到的,我们用policy函数来控制agent,给定当前状态S,agent的动作A是根据policy输出函数的概率分布来随机抽样得到的,它有可能做出3个的任意一个动作,但是要根据概率来决定最终采取什么动作
2、另一个随机性的来源是状态转移:假定agent做出了向上跳的动作,环境就要生成下一个状态St+1,这个状态St+1具有随机性,环境用状态转移函数p计算出概率,然后根据概率来随机抽样得到下一个状态St+1,比如游戏设计者让怪物有80%的概率向左走,食人花隔多少秒向上咬人
状态转移函数p输出一个概率分布,环境从这个概率分布中随机抽样得到下一个状态St+1

我们最终的目标就是得到一个policy(Π)函数,帮助我们更好的赢得游戏
这样我们就得到游戏的一个轨迹,s1,a1,r1,s2,a2,r2.....st,at,rt
Return:
回报/未来的累计奖励(Ut)

由于未来的不确定性,所以Rt+1的权重应当小于Rt
折扣汇报记作Ut,折扣率记作γ∈(0,1) ,折扣率是个超参数,需要我们自己来调
什么是超参数?
在机器学习中,超参数是指那些需要手动设置的参数,以调整模型的学习行为和性能的参数,而不是通过训练数据自动学习得到的参数。超参数的值通常需要通过试验和经验得到,而不是直接从数据中学习得到。
例如,在神经网络中,超参数可以包括学习率、权重衰减系数、批量大小、迭代次数、隐藏层神经元数量等。这些超参数的值的选择可能会影响模型的性能和训练时间,因此需要进行调整和优化。常见的调整超参数的方法包括网格搜索、随机搜索和贝叶斯优化等。
需要注意的是,超参数与模型参数不同。模型参数是指模型在训练过程中需要学习的参数,例如神经网络中的权重和偏置。模型参数是根据训练数据自动学习得到的,而不是手动设置的。

Return Ut的随机性:
假如游戏已经结束了,所有的奖励都观测到了,那么奖励就是数值,使用小写字母表示,如果在t时刻游戏还没有结束,这些奖励都还全是随机变量,没有被观测到,我们就使用大写字母R来表示奖励,由于Return Ut依赖于奖励R,所以Ut也是一个随机变量,使用大写字母表示
 Ut与从t时刻开始,未来所有的动作和状态都有关。
Ut与从t时刻开始,未来所有的动作和状态都有关。
为何要定义Ut?
》agent的目标就是让未来得到的奖励总和越大越好,为此我们使用Ut来表示未来得到的奖励总和,如果知道Ut的话,我就知道这局游戏是快要赢了还是快要输了?
》逗你玩的,Ut是个随机变量,在t时刻你并不知道Ut是什么,那么我应该如何评估当前的形势呢?
》我们可以对Ut求期望,把里面的随机性都使用积分给积掉,得到的就是个实数real num,记作QΠ(st,at),这个期望是怎么求的呢?
》期望就是对未来的动作a和状态s求的,把这些随机变量都用积分积掉,除了St和At其他的随机变量都被积掉了,被积掉的随机变量是At+1,At+2..At+n,St+1,St+2...St+n
求期望得到的函数QΠ(st,at)被称为动作价值函数,函数里的随机变量只有St和At没有被积分积掉,他们作为观测到的数值来对待,而不是作为随机变量。QΠ(st,at)的值依赖于St和At,函数QΠ还和policy函数Π有关,因为前面积分去除随机变量的时候会用到policy函数
那么QΠ有什么直观的意义呢?
》它表示如果用给定policy函数Π,那么在当前状态st下做动作at是好还是坏,已知policy函数Π,QΠ就会给当前状态下所有的动作a打分,然后我就知道在当前状态下哪个动作at好,哪个不好

去掉Π函数,即在最优的Π函数下,我们得到Q*函数,它的直观意义是:它可以用来在状态st下对动作a做评价,比如下围棋的时候st就是当前的棋盘,Q*函数就可以告诉我们了,你把棋子放在位置(0,0)的胜算有多大,放到位置(1,1)的胜算有多大

Q*函数非常重要,假如有了Q*,agent就可以根据Q*对动作的评价来做决策了,即观测到一个状态,Q*认为在当前状态下往上跳最终的胜算最高,agent就应该往上跳,Q*认为在当前状态下往左移动最终的胜算最高,agent就应该往左移动(使用Q*来指导agent下一步应该做什么动作)
状态价值函数VΠ
它代表在某一策略下所有动作带来的return(Ut未来的总奖励)的期望,相当于对QΠ再求一次期望
VΠ可以告诉我们当前的状态好不好,假设根据policy函数Π来下围棋,让VΠ来看一下棋盘,VΠ就会告诉我当前的形势怎么样,胜算有多大,我是快赢了还是快输了
这里的期望是关于动作的随机变量A求的,A的概率密度函数是Π,根据期望的定义可以把期望写成连加或者积分的形式,如果动作都是离散的,比如上下左右,这样就可以把期望写成对Π函数和Q函数的乘积做连加,把所有的动作a都算上。有时候动作a是连续变量,比如自动驾驶方向盘转过的角度∈(-90°,90°),使用积分,可以把动作a给积掉

总结一下两种Value Function:
QΠ是Ut的条件期望,Ut是个随机变量,他等于未来所有奖励的加权求和
VΠ是用积分把QΠ中的变量A去掉,这样变量就只剩下状态s,VΠ用于评估当前状态的好坏,即我们是快要赢了还是快要输了,VΠ还能评价policy函数Π的好坏,如果Π越好,那么VΠ的平均值E()就越大

二、如何用强化学习自动打游戏?
如果是超级玛丽游戏,那么我们的目标就是操作马里奥多吃金币,避开敌人,往前走,打赢每一局游戏。
1、策略学习:
通过学习一个policy函数Π ,我们就可以通过Π函数来对agent函数做动作了,每观测到一个st就做出一个动作at,以此来控制马里奥打游戏
2、价值学习
学习Q*函数,假如有了Q*,agent就可以根据Q*函数来做动作了,Q*函数告诉我们如果处于状态s那么做动作a是好还是坏,每观测到一个状态st就把st作参数输入到Q*函数中去,让Q*函数对每一个动作都做一个评价,这样我们就知道向左/右/上/下的每一个动作的Q值,假如向上跳这一个动作的Q值最大,agent就应该向上跳,为什么呢?因为Q值是对未来奖励总值的期望,所以向上跳这个动作意味着在未来获得更多的奖励
数学上的表示:有了Q*函数,选择让Q*函数值最大化的a作为下一个动作at
综上:强化学习的任务就是让agent学习到policy函数Π或者Q*函数二者之一

OpenAI Gym

如果你设计出一种强化学习的算法,你怎么测试算法的性能?
》在标准数据集上检验算法的效果,所有搞强化学习的学者都会用Gym测试算法的优劣

step函数是让agent真正去做这个动作了
总结:
被观测到用小写字母表示,没有被观测到就用大写字母表示

强化学习的目的就是学会怎样控制agent,让agent基于当前的状态s来做出相应的动作a,争取能在未来得到尽量多的奖励
 下面要学习点什么?
下面要学习点什么?
1、DQN,使用一个神经网络来近似Q*,有了神经网络,我们要学习神经网络的参数,这就要用到TD算法
2、策略学习:用一个神经网络来近似policy函数Π 》策略网络,想要学习策略网络中的参数,就要算策略梯度,然后做梯度上升,
3、Actor和Cirtic网络,他是价值和策略网络的结合
4、将AlphaGo这个例子,看看别人是怎么用深度强化学习来解决实际问题的

恭喜你完成了深度强化学习基本概念的学习!!!
下一课我们将学习强化学习中的价值函数:
喜欢的话,欢迎大家点赞收藏支持一波~