High-Performance Parallel Fault Simulation for Multi-Core Systems 多核系统的高性能并行故障仿真
这篇文献提出了一种针对多核系统的高性能并行故障模拟(FS)技术,旨在减少FS的执行时间。以下是文献的速读概要:
标题: 高性能并行故障模拟技术在多核系统中的应用
作者: Masoomeh Karami, Mohammad-hashem Haghbayan, Masoumeh Ebrahimi, Hamid Nejatollahi, Hannu Tenhunen, Juha Plosila
机构: 芬兰图尔库大学未来技术系、瑞典皇家理工学院电子与嵌入式系统系、美国加州大学欧文分校
核心内容:
- 提出了一种基于事件驱动的并行多线程FS技术,以最小化FS时间。
- 描述了从故障注入到在不同核心上调度并行计算任务的整个过程。
- 实验结果显示,该技术在单核平台上可减少25%的时间,在双核心平台上,线程数量增加可使执行时间减半。
方法论:
- 使用了事件驱动FS,它比时间驱动FS更高效,因为它更快、使用更少的内存,且更灵活。
- 提出了一种并行FS技术,通过在多核平台上并行处理事件来加速模拟过程。
- 任务调度是实现高性能的关键,包括故障分组、注入和模拟。
实验与结果:
- 在单核和双核系统上进行了实验,使用了Netlist-Generator工具和Microsoft Visual Studio环境。
- 实验结果表明,随着线程数量的增加,FS的CPU时间减少,尤其是在双核系统中效果更为显著。
结论:
- 提出的多线程并行FS方法在多核系统中表现出效率,尤其是在大型设计中。
- 未来的工作计划将使用这种方法来分析在多核系统上运行的神经网络等应用中的故障。
图表与算法:
- 文献中包含了多个图表和伪代码,展示了并行FS的示例和算法,如事件驱动FS的伪代码和多核并行FS的算法。
这篇文献为VLSI设计中的故障模拟提供了一种新的高效方法,特别是在多核处理器上的应用,这对于提高设计效率和降低测试成本具有重要意义。
VLSI是Very Large Scale Integration的缩写,意为超大规模集成电路。它是一种电子工程领域的技术和学科,涉及将数百万甚至数十亿个晶体管集成到单个芯片上的设计和制造过程。VLSI技术的发展使得计算机和电子设备的性能得到了显著提升,同时也推动了信息技术的快速发展。
CUT在VLSI设计中是指"Cell Under Test",即被测试的电路单元。在VLSI芯片的设计和制造过程中,通常会将整个芯片划分为多个电路单元,每个电路单元都是由一组逻辑门和寄存器等元件组成的。CUT就是指被测试的这个电路单元,用于验证其功能和性能是否符合设计要求。测试人员会通过输入不同的信号和数据来激活CUT,并检查其输出是否与预期一致,以判断CUT的正确性和可靠性。
reference 1 :电路逻辑门图形符号汇总_八种逻辑门电路符号-CSDN博客
再收敛扇出(Reconvergent Fanout)是指在逻辑电路中,一个信号源(如一个逻辑门的输出)被多个逻辑门作为输入使用,然后这些逻辑门的输出再次汇集到一个或多个逻辑门的输入。这种情况下,多个逻辑门的输出会汇集到同一个逻辑门的输入,形成再收敛扇出。
再收敛扇出可能会导致一些问题,例如信号延迟、功耗增加和逻辑冲突等。由于多个逻辑门的输出会汇集到同一个逻辑门的输入,这可能会导致输入信号的冲突,从而影响电路的正确功能。为了解决这些问题,可以采取一些优化措施,如引入缓冲器、重新设计电路结构等。
再收敛扇出是逻辑电路设计中需要考虑的一个重要因素,特别是在大规模集成电路(VLSI)设计中。通过合理的电路设计和优化,可以减少再收敛扇出带来的问题,提高电路的性能和可靠性。
可靠性和正确性是两个相关但不同的概念。
可靠性指的是系统或设备在一定时间内能够正常工作的能力,即系统在面对各种异常情况或故障时,能够继续提供预期的功能和性能。可靠性的评估通常涉及到故障率、可用性、维修时间等指标。一个可靠的系统应该具有较低的故障率、较高的可用性,并能够在发生故障时快速恢复。
正确性则是指系统或设备提供的结果或行为符合预期的规范、要求或逻辑。正确性关注的是系统的功能是否按照设计要求来执行,是否满足特定的逻辑、算法或规则。例如,在软件开发中,正确性意味着程序能够按照预期的逻辑和规则执行,产生正确的输出。
可以说,可靠性是关于系统是否能够持续工作的问题,而正确性是关于系统是否按照预期工作的问题。一个系统可以是可靠的但不正确,也可以是正确的但不可靠。在实际设计和开发中,通常需要同时考虑和追求可靠性和正确性,以确保系统既能够正常工作,又能够提供正确的结果。
鲁棒性(Robustness)是指系统或算法对于输入数据的变化、异常情况或干扰的抵抗能力。一个鲁棒的系统或算法能够在面对不完全、不准确或有噪声的输入时,仍能够保持良好的性能和正确的行为。
鲁棒性是指系统的稳定性和适应性。它关注的是系统在面对各种异常情况时的表现,包括输入数据的变化、噪声、错误或攻击等。一个鲁棒的系统能够正确处理这些异常情况,不会因为输入的变化而导致系统崩溃或输出错误的结果。
在软件开发中,编写鲁棒的代码意味着要考虑到各种可能的输入情况,并采取适当的措施来处理异常情况,例如输入验证、错误处理和异常处理。在机器学习和人工智能领域,鲁棒性是指模型对于噪声、异常值或干扰的抵抗能力,能够保持良好的性能和泛化能力。
鲁棒性的重要性在于提高系统的可靠性和稳定性,以应对现实世界中的各种变化和不确定性。一个鲁棒的系统能够适应不同的环境和输入,减少故障和错误的发生,并提供稳定和可靠的性能。
模拟和仿真是两种常见的电子工程领域中使用的技术。
模拟是指使用实际的电路或系统来进行测试和分析。在模拟中,我们使用实际的物理元件和电路来构建系统,然后通过对电路施加不同的输入信号来观察输出的响应。模拟可以提供准确的结果,但构建和测试实际电路可能需要较长的时间和成本。
仿真是指使用计算机程序来模拟电路或系统的行为。在仿真中,我们使用电路设计软件或仿真工具来建立电路模型,并通过输入不同的信号来模拟电路的行为。仿真可以更快速地测试和分析电路的性能,而不需要实际构建和测试物理电路。但是,仿真结果可能会受到模型的精度和计算机性能的限制。
总的来说,模拟是使用实际电路进行测试和分析,而仿真是使用计算机程序模拟电路的行为。两者都有各自的优缺点,根据具体的需求和资源,选择适合的方法来进行电路设计和分析。
Netlist生成器是一种工具或程序,用于根据电路设计文件生成电路的Netlist。Netlist是一种描述电路拓扑结构和元件连接关系的文本文件,通常以某种特定的格式表示。
Netlist生成器通常用于将电路设计文件转换为可用于仿真、布局和布线等后续步骤的格式。它可以读取电路设计文件,解析其中的元件、连接和参数信息,并将其转换为Netlist格式。
生成的Netlist文件通常包含电路中的元件类型、引脚连接、元件参数、电源信息等。这些信息可以用于后续的仿真工具,例如SPICE仿真器,进行电路性能分析和验证。
Netlist生成器在电子设计自动化(EDA)工具中扮演着重要的角色,它可以帮助设计工程师更高效地将电路设计转化为可用于后续设计流程的格式。
RTL是Register Transfer Level(寄存器传输级)的缩写,是数字电路设计中的一种抽象级别。在RTL级别上,电路被描述为一系列寄存器之间的数据传输操作。
在RTL级别的设计中,电路被分解为多个寄存器和组合逻辑电路。寄存器用于存储数据,而组合逻辑电路用于处理和操作这些数据。RTL级别的描述通常使用硬件描述语言(如Verilog或VHDL)编写。
RTL级别的设计是在高层次上描述电路的功能和数据流,并且不涉及具体的门电路实现。它更关注电路的逻辑行为和数据传输,而不是电路中的门电路和物理实现细节。
RTL级别的设计可以用于验证电路的功能和性能,并且可以用于生成后续设计步骤(如逻辑综合和布局布线)所需的中间文件。
总的来说,RTL级别是数字电路设计中的一种抽象级别,用于描述电路的功能和数据传输操作。它是电路设计的重要阶段,为后续的设计流程提供基础。
CPU时间是指中央处理器(CPU)在执行特定任务或程序时所花费的时间。它通常用于衡量计算机系统的性能,特别是在多任务处理和并行计算中。
CPU时间可以分为用户CPU时间和系统CPU时间。用户CPU时间是指CPU用于执行用户程序的时间,而系统CPU时间是指CPU用于执行操作系统和系统服务的时间。
在实际应用中,我们可以通过监测和记录程序的CPU时间来评估其效率和性能。通过比较不同算法或优化技术的CPU时间,我们可以选择最有效的解决方案。
需要注意的是,CPU时间并不是唯一衡量计算机系统性能的指标,还有其他因素如内存访问速度、硬盘读写速度等也需要考虑。
ISCAS基准是指国际电子电路与系统学会(International Symposium on Circuits and Systems,简称ISCAS)所提供的一系列标准电路,用于评估和比较不同电路设计方法的性能。
ISCAS基准电路是由ISCAS组织成员设计的,涵盖了不同的电路类型和复杂度级别。这些电路包括了数字电路、模拟电路和混合信号电路,用于测试和验证不同电路设计技术的效果。
ISCAS基准电路具有一定的代表性和标准化,可以作为设计者和研究者之间进行性能比较和评估的基准。通过使用ISCAS基准电路,设计者可以更好地了解自己的设计在性能和功耗方面的表现,并与其他设计进行比较。
ISCAS基准电路通常以Netlist的形式提供,可以在电路仿真工具中加载和分析。这些电路的特点是规模适中,具有一定的复杂性,可以代表实际应用中的典型电路设计问题。
提高CPU时间,可以考虑以下几个方面:
1. 提升CPU的时钟频率:增加CPU的时钟频率可以加快CPU的运行速度,从而减少执行任务所需的时间。但是需要注意,提高时钟频率可能会导致功耗和散热问题,需要平衡性能和稳定性。
2. 优化算法和代码:通过优化算法和代码,可以减少CPU执行任务的时间。例如,使用更高效的算法、减少循环次数、避免不必要的计算等。
3. 并行计算:利用多核处理器或者并行计算技术,将任务分解为多个子任务并在多个处理器或核心上同时执行,可以加快任务的完成时间。
4. 缓存优化:合理利用CPU的缓存,减少内存访问的次数,可以提高CPU的执行效率。例如,尽量使用局部性较好的数据结构,减少缓存不命中的情况。
5. 使用硬件加速:对于某些特定的计算任务,可以使用硬件加速技术,如GPU、FPGA等,来提高计算速度。
需要注意的是,提高CPU时间并不是一件简单的事情,需要综合考虑硬件和软件的因素,并进行合理的优化和调整。
故障传播是指在电路或系统中发生故障后,该故障会向其他部分传播并导致更广泛的故障。故障传播可以是由于电路设计上的缺陷、电路元件的故障或外部干扰等原因引起的。
在数字电路中,故障传播可以导致错误的信号传输、数据丢失、功能失效等问题。当一个故障发生时,它可能会影响到与之相连的其他逻辑门或寄存器,进而影响到整个电路的正常运行。这种传播可以是逐级的,即一个故障引发另一个故障,也可以是并行的,即多个故障同时发生。
为了减少故障传播的影响,电路设计中通常采取了一些措施,如冗余设计、错误检测和纠正技术、时序约束等。这些措施可以帮助识别和修复故障,防止故障传播到整个系统。
此外,故障传播也是电路测试和故障诊断的重要问题。通过测试和诊断技术,可以确定故障的起源和传播路径,从而进行修复和优化。
层次化事件驱动仿真(Hierarchical Event-Driven Simulation)是一种常用的电路仿真方法,用于模拟和验证复杂的数字电路系统。它基于事件驱动的原理,将电路系统分解为多个层次,并按照事件的发生顺序进行仿真。
在层次化事件驱动仿真中,电路系统被分解为多个层次,每个层次包含一组相关的电路模块。每个模块在仿真过程中按照事件的发生顺序进行处理,而不是按照时钟周期进行仿真。当一个事件发生时,会触发相应的模块进行计算和状态更新。这种事件驱动的方式可以提高仿真效率,因为只有真正发生事件的模块才会进行计算,而其他模块则可以暂时忽略。
层次化事件驱动仿真的主要优点包括:
1. 灵活性:通过层次化的设计,可以方便地对电路系统进行模块化和复用。每个层次可以独立地进行仿真和验证,从而提高开发效率和可靠性。
2. 高效性:由于只有发生事件的模块才会进行计算,层次化事件驱动仿真可以减少不必要的计算和延迟,从而提高仿真速度。
3. 精确性:事件驱动的仿真方法可以更准确地模拟电路系统的行为,因为它考虑了事件的发生顺序和时序关系。
层次化事件驱动仿真在电路设计和验证中得到广泛应用,特别是对于大规模和复杂的电路系统。它可以帮助工程师在设计阶段发现和解决问题,降低开发风险,并提高电路系统的性能和可靠性。
(声明:自此之下的内容均为 翻译论文中的内容 或 翻译论文中的内容)
多核系统的高性能并行故障仿真
摘要:故障模拟是一个耗时的过程,需要定制的方法和技术来加速它。多线程和多核方法是两种有前途的技术,可以通过同时使用硬件的不同部分来加速故障模拟过程。然而,高效的并行化只能通过相对于硬件平台的软件细化来获得。本文提出了一种并行多线程故障仿真技术来加速多核平台上的仿真过程。在这种方法中,门输入值被独立分配给每个线程。每个输入值都携带多个并行仿真过程的信息。这提供了多线程并行故障模拟环境。实验结果表明,所提出的技术能够有效地利用硬件平台。在单核平台中,所提出的技术可以将时间减少 25%,而在双核平台中,增加线程大约可以使执行时间减少一半。
关键词—多核系统、多线程、并行化、故障模拟
- 简介
故障仿真(FS)在不同领域发挥着重要作用,例如测试模式生成、内置自测试、可控性和可观测性分析[1]、[2]。这个过程在 VLSI 设计中是一项具有挑战性且耗时的任务。在 FS 中,针对给定的故障模型和一组测试模式对被测电路 (CUT) 进行仿真。这个过程通常是计算密集型的,特别是对于需要大量测试模式的现代系统。
VLSI 电路最流行的故障模型之一是固定故障模型 [2]。一些工作已经使用并行和并发 FS 方法来最小化单核 [2]、[3] 和多核处理器 [4]、[5] 中固定故障模型的 FS 执行时间。他们还使用混合级故障模拟、并行化和事件驱动等不同方法来加速 FS 过程。混合级 FS 是一种使用更高抽象级别(例如行为级别)更快地模拟电路无故障部分的方法 [6]。由于FS具有可并行化的特性,并行处理已被广泛用于最小化执行时间。一种并行化技术是将电路划分为互斥的部分并并行模拟它们[7]、[8]。其他并行化解决方案基于针对不同故障集(数据并行)或测试模式(模式并行)并行模拟电路[9]、[10]。
实现门级故障模拟有两种方法:时间驱动的FS和事件驱动的FS。在时间驱动的FS中,模拟器计算并更新每个小时间时期内所有门的输入/输出变量。在事件驱动的FS中,门的输入/输出变量是根据新发生的事件计算的,例如,线值的变化。与时间驱动方法相比,事件驱动方法更高效,速度更快,使用更少的内存,并且更灵活[11],[12]。
本文提出了一种适用于多核系统的并行事件驱动的 FS 技术,以最小化 FS 时间。我们描述了从故障注入到调度任务在不同核上并行计算的整个过程。所提出的技术基于对网表每一层中发生的事件的并行处理。

图 1:1 位乘法器中固定 FS 的示例
- 并行故障模拟
加速FS过程的方法之一是并行FS[16],本文也采用了这种方法。在并行 FS 中,门的输入变量中的每一位代表注入故障到输出门的传播。然后通过编程中的逻辑运算来评估输出门。图 2 描述了图 1 的 1 位多路复用器的并行 FS。图 2 中并行模拟了四种故障传播场景。第一种场景研究线路 1(即线路 1 (S@1))上 S@1 故障的传播。此场景的输出等于 0,这意味着故障被屏蔽。其他场景显示黄金结果和故障传播发生在导线 2 (S@0) 和导线 3 (S@1) 上。在此示例中,只能在输出上观察和检测导线 3 (S@1) 的影响。

图 2:1 位乘法器中并行 FS 的示例 B. 事件驱动的故障模拟
在事件驱动的FS中,FS仅适用于发生事件的门,而不是所仿真所有门。因此它减少了模拟时间。算法 1 描述了事件驱动的 FS 的伪代码。首先,将测试模式注入到模拟中(第 1 行)。因为我们的模拟是事件驱动的,所以所有发生的事件都被推入 ST ACK(第 2 行),以便以正确的顺序弹出它们并计算和更新变量(第 4 行)。如果在注入故障(第 5 行)后主输出发生变化,则会检测到故障(第 6 行),因此事件会被推送到 ST ACK(第 7 行)。ST ACK 由检测到的事件组成。

事件驱动FS的主要问题是再收敛扇出(RF)引起的情况。如果设计中存在 RF,则应延迟门的评估,直到评估门的所有输入为止。否则,内部线路或主输出可能会出现故障。该问题增加了执行时间并为故障检测添加了额外的进程。为了解决这个问题,分层事件驱动模拟可能是一个可行的选择,它将事件评估限制在每个级别。在层次化的事件驱动FS中,首先,设计是层次化的,其中每个级别中的门从前一个级别获取输入。每个新发生的事件都被放置在其相应级别的列表中。在每个级别,事件列表中的门都会被顺序评估。算法 2 用伪代码说明了这个过程。电平化故障注入电路的实现是自动的。在算法 2 中,针对每个级别发生的事件采用动态堆栈数组。这个过程一直持续到所有测试模式都被注入为止。

层次化事件驱动FS可以与并行FS相结合。在这种情况下,每个事件堆栈可用于并行故障发生的所有事件。层次化事件驱动的并行 FS 方法构成了我们 FS 算法的基础。
- 多核系统并行故障模拟的建议
- 并行处理
多核/众核系统中并行FS的目的是尽可能多地利用系统中的可用核,从而实现高性能。面临的挑战是找到内核之间任务调度的最佳方法。在所提出的 FS 中应用故障的主要策略是应用一种测试模式并注入所有可用的故障,然后对其他测试模式重复该过程。通过实验,我们注意到,与其他等效方法相比,使用此技术可以实现更好的并行性。图 3 显示了所提出的多核系统上并行 FS 方法的示例。如图所示,系统中有三个可用核心,每个门考虑三个输入变量,其中输入变量包含每个线程的数据。值得一提的是,变量的数量不一定与核心的数量相同。变量是 32 位整数,因此每个线程每次迭代可以执行 32 个 FS 场景。我们将每个线程上执行的 FS 称为任务。因此,每个任务都分配给一个线程,操作系统(OS)可以根据系统上的可用内核为每个任务调度线程[17]。
并发任务之间的数据依赖性可能会对整体性能造成负面影响。因此,线程的调度是一个必须仔细执行的重要步骤。另一方面,任务调度高度依赖于执行 FS 算法所选择的技术。在下一节中,我们将解释所提出的算法中的任务调度过程。
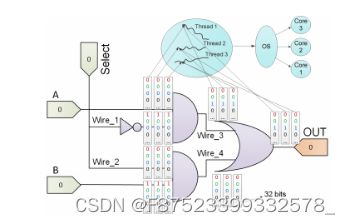
图3:该方法的整体流程
- 并行计算的任务调度
并行计算的重要因素之一是任务调度。任务调度应该平衡系统中所有核心的利用率,以达到最大并发度。在所提出的任务调度算法中,首先,为所有任务生成测试模式的黄金结果。然后,将一组故障应用于 FS 的每个任务。对于并发任务,故障组应该彼此独立。执行完所有线程后,未检测到的故障将会累积。这个过程一直持续到所有故障都被注入为止。最后,所有线程中累积的未检测到的故障将被收集起来作为下一个测试模式注入。算法3详细描述了所提出的多核FS和任务调度算法。该算法对所提出的分层多核事件驱动FS进行建模,该FS可分为四个主要工作:故障折叠、故障分组、故障注入和故障仿真。
- 故障注入过程:如图 4 所示,可以通过将线路与逻辑 1 进行“或”运算,将 S@1 故障应用于设计中的线路。同样,可以通过“与”运算来生成 S@0 故障逻辑 0 的线路。所提出的故障模拟算法以与算法 2 不同的方式对事件进行排序。在算法 3 中,我们将受激励门 (GATE STACK) 的内存与受激励故障门的内存区分开来 (故障门堆栈)。这是因为故障注入方法,其中与下一级故障门相关的事件先于普通门的事件进行评估。通过使用这种故障注入方法,并行 FS 的某些故障无法同时注入到线程中。这些故障(称为相关故障)应分类为不同的组,以便分配给不同的线程。称为独立故障分组的功能执行此分类。

图 4:两个相关故障的示例

- 故障分组:如前所述,对于故障注入,与 0 进行 AND 运算以及与 1 进行 OR 运算可分别用于生成 S@0 和 S@1 故障。这种故障注入方法限制了层次化事件驱动FS的多个故障的级联。图 4 说明了使用逻辑门(称为故障门)进行故障注入的过程。在此图中,设计中注入了两个故障。
- 在线性故障崩溃中,扇出的输入和输出具有单独的故障模型,应在 FS 中单独考虑[2]、[18]。这种情况可能会导致一系列故障门。在级别化事件驱动FS中,级别中发生的事件将根据级别顺序进行处理。在每个级别中,FAULT GATE STACK 将在 GATE STACK 之前进行评估。如果故障门上发生了事件,则该事件将存储在下一级故障门堆栈中。如果两个故障门级联,则在下一级中将错过第二个故障的评估。在故障分组中,相关故障将被放置在不同的组中。在这种情况下,相关故障将被应用于不同的线程以并行运行。
- 用于多核故障模拟的openmp.h:在所提出的方法中,如算法3所示,创建线程并确定线程的数量是至关重要的。还需要将崩溃的故障分布在线程之间以实现更高的并发性。因此,应适当设置最佳线程数,并确定临界区。根据所提出的算法,每个门应该为每个线程提供一些非共享变量。这些变量的副本将被分配给线程,最后收集故障检测结果。我们使用C++的openmp.h库来实现该算法。算法 4 描述了使用 openmp.h 函数来创建一种测试模式的多线程故障传播。#pragma编译器根据线程id生成线程。故障传播函数开始在每个线程中传播故障,然后将检测到的故障放入其对应的df线程中。带 plus 参数的归约参数意味着每个线程检测到的所有故障数都应添加到df线程的最终值中。 numthreads 确定应为所选代码创建的线程数(根据线程 ID)。

应收集未检测到的故障并将其重新分配给线程以进行下一轮的仿真。然而,收集所有未检测到的故障可能会导致访问内存的线程之间发生冲突或竞争。为了消除竞争情况,提出了临界区定义,如算法5所示。faultStack NDF是收集未检测到的故障的内存。关键参数限制线程同时执行所选代码。如果线程之间的任务调度是平衡的,这个临界区不会对性能产生太大的影响。

- 实验结果
为了评估所提出的 FS 方法,检查了几个基准。我们利用 Netlist-Generator [2] 评估 RTL 级 HDL 代码上的 FS。使用此工具,首先以 RTL 格式对设计进行建模,然后进行综合。我们使用开源版本的 Microsoft Visual Studio 环境来调用 openmp.h 库。此外,还开发了一种工具,用于将 ISCAS 基准电路转换为 FS 的适当数据结构。为了将所提出的方法与其他现有方法的性能进行比较,我们使用动态堆栈和链接列表等动态功能在 Visual Studio 环境中实现了 Hope [13] 故障模拟器的源代码。通过该方法获得的结果与通过所提出的方法对于一个线程生成获得的结果相同。
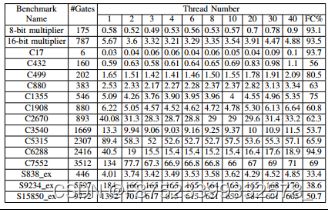
- 单核和双核系统的CPU时间
在具有 2.2GHz 时钟周期和 4GB RAM 的双核 CPU 上执行的。为了与单核处理器比较结果,使用了具有 2.3 GHz CPU 和 512 MB RAM 的单核。表 I (a) 和 (b) 分别显示了双核和单核系统上 20 个随机测试模式下 FS 的 CPU 时间。使用一些通用电路,例如8位和16位乘法器以及ISCAS基准作为基准。平均故障覆盖率(FC)为66.67%。从两个表中可以看出,在大多数情况下,CPU 时间随着线程数量的增加而减少。这是因为所提出的方法在利用系统中的可用内核方面具有灵活性。
- 双核系统
- 单核系统

表 I:ISCAS 基准上故障模拟的 CPU 时间结果
在另一个实验中,我们测量了为 FS 运行不同数量的线程时的核心利用率。使用三线程时,核心利用率达到97%的高利用率,而使用一线程和二线程时,利用率分别为50%和89%。这表明,线程数量加倍并不一定会使利用率加倍,这是多线程中常见的现象。原因是同步、内存访问冲突以及不同软件层中的其他问题。增加线程数时,内存使用量略有增加,即 1、2 和 3 个线程分别为 1.22 GB、1.28 GB 和 1.30 GB。
B. CPU 时间与线程数
图 5 (a) 和 (b) 描述了运行三个大型 ISCAS 基准测试和四个小型 ISCAS 基准测试时,双核系统中与生成线程数相关的 CPU 时间。该图表明,适当的线程数可以提供最佳的 CPU 时间。可以看出,通过增加线程数,FS时间首先急剧下降,然后稳定下来,最后又开始上升。需要注意的是,由于系统中有两个核心,因此将线程数量增加到两个以上并不会导致执行时间大幅减少。此外,由于系统中存在大量线程,线程和操作系统之间的总体通信时间超过了并行性所减少的时间。
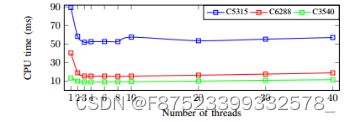
- 大尺寸ISCAS基准电路
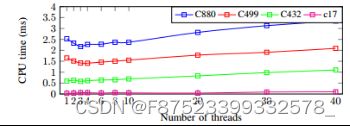
- (b) 小尺寸 ISCAS 基准电路
图 5:CPU 时间与线程数。
C. CPU 时间与门数的关系
由于并行性需要更多的数据结构和通信开销,因此所提出的方法不适合较小的设计,而是适合较大的设计。图 6 显示了应用所提出的方法时 CPU FS 时间随门数的增加减少。可以看出,所提出的方法比较小的设计更能改善较大设计的 FS 时间。
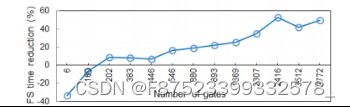
图 6:FS 时间减少与门数的关系
- 与多线程相关的 CPU 时间
多线程 FS 可以提高双核和单核系统的 FS CPU 时间。图 7 显示了 C5315 在单核和双核系统上的 FS 时间。从图中可以看出,单核系统中CPU时间可以从175ms减少到160ms,而双核系统中这种减少幅度更大,即从89.4ms减少到52ms。原因是由于高级别(操作系统级别)的任务并行性,而不是各个内核上的任务调度。

图 7:c5315 单核和双核系统的 CPU 时间
- 结论
故障仿真是一种具有挑战性的算法。它的执行时间,同时也是 VLSI 设计中的关键步骤。减少故障仿真执行时间对于开发更好的测试模式来调试硅后 VLSI 电路起着重要作用。在本文中,我们提出了一种针对多/众核系统的多线程并行故障仿真方法。该方法的重要步骤之一是任务调度,它定义了如何对故障进行分组、注入和传播。所提出的方法基于层次化事件驱动仿真。结果证实了故障仿真方法在核心数量、线程数量和门数量方面的效率。作为未来的工作,我们计划使用这种方法来分析应用程序中的故障,例如在多核系统上运行的神经网络。
参考文献
[1] D. Lee 和 J. Na,“一种用于可靠性分析的新型模拟故障注入方法”,IEEE 计算机设计与测试,2009 年,第 50-61 页。
[2] Z. Navabi,“数字系统测试和可测试设计:使用 HDL 模型和架构”,Springer Publisher,2010 年。
[3] N. Bombieri、F. Fummi 和 V. Guarnieri,“通过 RTL-to-tlm 抽象加速 RTL 故障模拟”,ETS,2011 年,第 117-122 页。
[4] S. Hadjitheophanous、S. N. Neophytou 和 M. K. Michael,“共享内存多处理器系统的可扩展并行故障模拟”,VTS,2016 年,第 1-6 页。
[5] M. Gorev、R. Ubar 和 S. Devadze,“多核环境中并行精确关键路径跟踪的故障模拟”,载于 DATE,2015 年,第 123 页。
1180–1185。
[6] S. Mirkhani、M. Lavasani 和 Z. Navabi,“使用行为和门级硬件模型进行分层故障模拟”,载于 ATS,2002 年,第 17 页。
374–379。
[7] A. Ehteram、H. Sabaghian-Bidgoli、H. Ghasvari 和 S. Hessabi,“使用近似并行关键路径追踪进行故障模拟的简单而快速的解决方案”,《加拿大电气与计算机工程杂志》,2020 年,第 100–110 页。
[8] J. Kousaar、R. Ubar、S. Kostin、S. Devadze 和 J. Raik,“时序电路中的并行关键路径跟踪故障模拟”,MIXDES,2018 年,第 305-310 页。
[9] K. Gulati 和 S. Khatri,“使用图形处理单元加速故障模拟”,DAC,2008 年,第 822-827 页。
[10] R. Mueller-Thuns 等人,“通用并行计算机上的 VLSI 逻辑和故障仿真”,IEEE Trans。集成电路与系统 CAD,1993 年。
[11] E. Gascard 和 Z. Simeu-Abazi,“通过蒙特卡罗模拟对动态故障树进行定量分析:事件驱动的模拟方法”,《可靠性工程与系统安全》,2018 年,第 487-504 页。
[12] J. A. Garrido、R. R. Carrillo、N. R. Luque 和 E. Ros,“尖峰神经网络的事件和时间驱动混合模拟”,《计算智能进展》,2011 年,第 554-561 页。
[13] H. K. Lee 和 D. S. Ha,“Hope:同步时序电路的高效并行故障模拟器”,载于 IEEE Transactions on ComputerAided Design of Integrated Circuits and Systems,1996 年,第 1048-1058 页。
[14] D. Chatterjee、A. DeOrio 和 V. Bertacco,“使用 gp-gpus 进行事件驱动的门级仿真”,DAC,2009 年,第 557-562 页。
[15] M. Haghbayan、S. Teravě ainen、A. Rahmani、P. Liljeberg 和 H. Ten- hunen,“多核微处理器系统上的自适应故障模拟”,载于 DFTS,2015 年,第 151 页– 154.
[16] J. Fan 和 Z. Zhang,“使用并行故障模拟加速故障模拟”,Procedia Engineering 15,2011,第 1817-1821 页。
[17] W. Stallings,“操作系统”,Prentice Hall,2001 年。
[18] M. H. Haghbayan、S. Karamati、F. Javaheru 和 Z. Navabi,“HDL 环境中时序电路的测试模式选择和压缩”,ATS,2010 年,第 53-56 页。