在内网中,好的信息搜集能力能够帮助开发者更快地拿到权限及达成目标。 内网里数据多种多样,需要根据需求寻找任何能对下一步渗透行动有所帮助的信 息。信息搜集能力是渗透过程中不可或缺的重要一步。下面将介绍各类搜集信息 的方法。
4.2.1 基于ICMP的主机发现
ICMP(Internet Control Message Protocol ,Internet报文协议)是TCP/IP的一种 子协议,位于OSI 7层网络模型中的网络层,其目的是用于在IP主机、路由器之间 传递控制消息。
1.ICMP工作流程
ICMP中提供了多种报文,这些报文又可分成两大类:“差错通知”和“信息查 询”。
(1)差错通知
当IP数据包在对方计算机处理过程中出现未知的发送错误时,ICMP会向发送 者传送错误事实以及错误原因等,如图4-1所示。
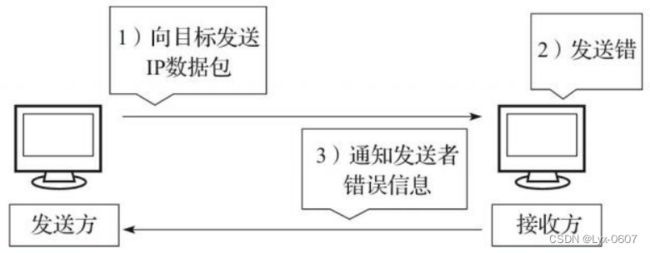
图4-1 差错通知
(2)信息查询
信息查询由一个请求和一个应答构成的。只需要向目标发送一个请求数据
包,如果收到了来自目标的回应,就可以判断目标是活跃主机,否则可以判断目 标是非活跃主机,如图4-2所示。

图4-2 信息查询
2.ICMP主机探测过程
Ping命令是ICMP中较为常见的一种应用,经常使用这个命令来测试本地与目 标之间的连通性,发送一个ICMP请求消息给目标主机,若源主机收到目标主机的 应答响应消息,则表示目标可达,主机存在。例如,我们所在的主机IP地址为
192.168.124.134 ,而通信的目标IP地址为192.168.124.5 。如果要判断192.168.124.5 是否为活跃主机,只需要向其发送一个ICMP请求,如果192.168.124.5这台主机处 于活跃状态,那么它在收到这个请求之后,就会给出一个回应,如下所示:
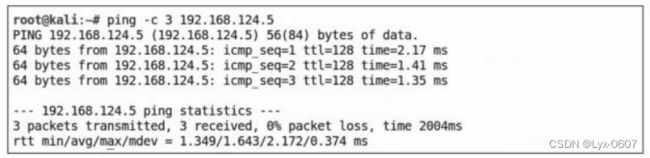
现在来编写一个利用ICMP实现探测活跃主机的代码程序。程序有很多种可实 现方式,此处我们借助Scapy库来完成。Scapy是Python中一个第三方库,在Scapy 库内部已经实现了大量的网络协议,例如TCP 、UDP 、IP 、ARP等,使用Scapy可 以灵活地编写各种网络工具。
首先我们对Scapy进行安装,命令如下:
| 安装过程如下所示: |
 |
| 接下来,我们可以利用Scapy库函数中的ICMP实现探测主机存活,详细过程 如下所示。 1)导入程序代码所应用到的模块:scapy 、random 、optparse ,其中scapy用 于发送ping请求和接收目标主机的应答数据,random用于产生随机字段,optparse 用于生成命行参数形式。示例如下: |
| #!/usr/bin/python #coding:utf-8 from scapy .all import * from random import randin t from optparse import OptionParser |
| 2)对用户输入的参数进行接收和批量处理,并将处理后的IP地址传入Scan函 数。 |
def main() :
parser = OptionParser("Usage:%prog -i ") # 输出帮助信息
parser .add_option( '-i ',type= 'string ',dest= 'IP ',help= 'specify target host ') # 获取IP地址参数
options,args = parser .parse_args()
print("Scan report for " + options .IP + "\n")
# 判断是单台主机还是多台主机
# IP中存在-,说明是要扫描多台主机
if '- ' in options .IP:
# 代码举例:192 .168 .1 .1-120
# 通过“ -”进行分隔,把192 .168 .1 .1和120分开
# 把192.168.1.1通过“,”进行分隔,取最后一个数作为range函数的start,然后把120+
1作为range函数的stop
# 这样循环遍历出需要扫描的IP地址
for i in range(in t(options .IP .split( '- ')[0] .split( ' . ')[3]), in t
(options .IP .split( '- ')[1]) + 1) :
Scan(
options .IP .split( ' . ')[0] + ' . ' + options .IP .split( ' . ')[1] + ' . ' + options .IP .split( ' . ')[2] + ' . ' + str(i))
time .sleep(0 .2)
else:
Scan(options .IP)
print("\nScan finished!. . .\n")
if __name__ == "__main__" :
try:
main()
except Keyboard Interrupt :
print("interrupted by user, killing all threads . . .")
| 3)Scan函数通过调用ICMP ,将构造好的请求包发送到目的地址,并根据目 的地址的应答数据判断目标主机是否存活。存活的IP地址会打印 出“xx.xx.xx.xx →Host is up” ,对于不存活的主机打印出“xx.xx.xx.xx →Host is down”: |
| icmp_id = randin t(1, 65535) icmp_seq = randin t(1, 65535) packet=IP(dst=ip,ttl=64,id=ip_id)/ICMP(id=icmp_id,seq=icmp_seq)/b ' rootkit ' result = sr1(packet, timeout=1, verbose=False) if result : for rcv in result : scan_ip = rcv[IP] .src print(scan_ip + '---> ' 'Host is up ') else: print(ip + '---> ' 'host is down ') |
| 运行效果如下所示。 |
 |
| 此处,我们也可以在程序中导入Nmap库函数,实现探测主机存活工具的编 写。这里使用Nmap函数的-sn与-PE参数,-PE表示使用ICMP ,-sn表示只测试该主 机的状态,具体步骤如下所示。 1)导入程序代码所应用到的模块:nmap 、optparse 。nmap模块用于产生 ICMP的请求数据包,optparse用于生成命令行参数。 |
#!/usr/bin/python3
# -*- coding: utf-8 -*
import nmap
import optparse
| 2)利用optparse模块生成命令行参数化形式,对用户输入的参数进行接收和 批量处理,最后将处理后的IP地址传入NmapScan函数。 |
| if __name__ == '__main__ ' : parser = optparse .OptionParser( 'usage: python %prog -i ip \n\n ' 'Example: python %prog -i 192 .168 .1 .1 [192.168.1.1-100]\n') # 添加目标IP参数-i parser.add_option('-i','--ip',dest='targetIP',default='192.168.1.1 ',type='string', help= 'target ip address ') options,args = parser .parse_args() # 判断是单台主机还是多台主机 # IP中存在“ -”,说明是要扫描多台主机 if '- ' in options .target IP: # 代码举例:192 .168 .1 .1-120 # 通过 '- '进行分割,把192 .168 .1 .1和120进行分离 # 把192.168.1.1通过“,”进行分隔,取最后一个数作为range函数的start,然后把 120+1作为range函数的stop # 这样循环遍历出需要扫描的IP地址 for i in range(in t(options .target IP .split( '- ')[0] .split( ' . ')[2]),in t (options .target IP .split( '- ')[1])+1) : NmapScan(options .target IP .split( ' . ')[0] + ' . ' + options .target IP . split( ' . ')[1] + ' . ' + options .target IP .split( ' . ')[2] + ' . ' + str(i)) else: NmapScan(options .target IP) |
| 3)NmapScan函数通过调用nm.scan() 函数,传入-sn-PE参数,发起ping扫 描,并打印出扫描后的结果。 |
| def NmapScan(target IP) : # 实例化PortScanner对象 nm = nmap .PortScanner() try: # hosts为目标IP地址,argusments为Nmap的扫描参数 # -sn:使用ping进行扫描 # -PE:使用ICMP的 echo请求包(-PP:使用timestamp请求包 -PM:netmask请求包) result = nm .scan(hosts=target IP, arguments= '-sn -PE ') # 对结果进行切片,提取主机状态信息 state = result[ 'scan '][target IP][ 'status '][ 'state '] print("[{}] is [{}]" .format(target IP, state)) except Exception as e: pass |
运行效果如下所示。

基于ICMP的探测主机存活是一种很常见的方法,无论是以太网还是互联网都
可以使用这种方法。但是该方法也存在一定的缺陷,就是当网络设备,例如路由 器、防火墙等对ICMP采取了屏蔽策略时,就会导致扫描结果不准确。
4.2.2 基于TCP 、UDP的主机发现
基于TCP 、UDP的主机发现属于四层主机发现,是一个位于传输层的协议。 可以用来探测远程主机存活、端口开放、服务类型以及系统类型等信息,相比于 三层主机发现更为可靠,用途更广。
TCP是一种面向连接的、可靠的传输通信协议,位于IP层之上,应用层之下 的中间层。每一次建立连接都基于三次握手通信,终止一个连接也需要经过四次 握手,建立完连接之后,才可以传输数据。当主动方发出SYN连接请求后,等待 对方回答TCP的三次握手SYN+ACK ,并最终对对方的SYN执行ACK确认。这种 建立连接的方法可以防止产生错误的连接,所以TCP是一个可靠的传输协议。
因此,我们可以利用TCP三次握手原理进行主机存活的探测。当向目标主机 直接发送ACK数据包时,如果目标主机存活,就会返回一个RST数据包以终止这 个不正常的TCP连接。也可以发送正常的SYN数据包,如果目标主机返回
SYN/ACK或者RST数据包,也可以证明目标主机为存活状态。其工作原理主要依 据目标主机响应数据包中flags字段,如果flags字段有值,则表示主机存活,该字 段通常包括SYN 、FIN 、ACK 、PSH 、RST 、URG六种类型。SYN表示建立连
接,FIN表示关闭连接,ACK表示应答,PSH表示包含DATA数据传输,RST表示 连接重置,URG表示紧急指针。
现在来编写一个利用TCP实现的活跃主机扫描程序,这个程序有很多种方式 可以实现,首先借助Scapy库来完成。在安装好Scapy的终端输入Scapy运行程序。 设定远程IP地址为39.xx.xx.238 ,flag标志为A表示给目标主机发送ACK应答数据 包,通过sr1() 函数将构造好的数据包发出。相关代码如下所示:
>>> ip=IP()
>>> tcp=TCP()
>>> r=(ip/tcp)
>>> r[IP] .dst="39 .xx .xx .238"
>>> r[TCP] .flags="A"
>>> a=sr1(r)
>>> a .display()
通过a.display() 函数查看目标主机的返回数据包信息,此时可以发现flags 标志位为R ,表示远程主机给源主机发送了一个REST 。由此可以验证远程目标主 机为存活状态。响应结果如下所示。
1)导入程序代码所应用到的模块:time 、optparse 、random和scapy 。time模 块主要用于产生延迟时间,optparse用于生成命行参数,random模块用于生成随机 的端口,scapy用于以TCP发送请求以及接收应答数据,例如:
| import time from optparse import OptionParser from random import randin t from scapy .all import * |
| 2)利用optparse模块生成命令行参数化形式,对用户输入的参数进行接收和 批量处理,最后将处理后的IP地址传入Scan() 函数。 |
def main() :
usage = "Usage: %prog -i " # 输出帮助信息
parse = OptionParser(usage=usage)
parse .add_option("-i", '--ip ', type="string", dest="target IP", help=
"specify the IP address") # 获取网段地址
options, args = parse .parse_args() #实例化用户输入的参数
if '- ' in options .target IP:
# 代码举例:192 .168 .1 .1-120
# 通过“ -”进行分隔,把192 .168 .1 .1和120进行分离
# 把192.168.1.1通过“,”进行分隔,取最后一个数作为range函数的start,然后把 120+1作为range函数的stop
# 这样循环遍历出需要扫描的IP地址
for i in range(in t(options .target IP .split( '- ')[0] .split( ' . ')[3]), in t (options .target IP .split( '- ')[1]) + 1) :
Scan(options .target IP .split( ' . ')[0] + ' . ' + options .target IP .split ( ' . ')[1] + ' . ' + options .target IP .split( ' . ')[2] + ' . ' + str(i))
else:
Scan(options .target IP)
if __name__ == '__main__ ' :
main()
| 3)Scan() 函数,通过调用TCP将构造好的请求包发送到目的地址,并根据 目的地址的响应数据包中flags字段值判断主机是否存活。若flags字段为R ,其整 型数值为4时表示接收到了目标主机的REST , 目标主机为存活状态,打印 出“xx.xx.xx.xx Host is up” ,否则为不存活主机,打印出“xx.xx.xx.xx Host is down”。 |
| def Scan(ip) : try: dport = random .randin t(1, 65535) #随机目的端口 packet = IP(dst=ip)/TCP(flags="A",dport=dport) #构造标志位为ACK的数据包 response = sr1(packet,timeout=1 .0, verbose=0) if response: if in t(response[TCP] .flags) == 4: #判断响应包中是否存在RST标志位 time .sleep(0 .5) print(ip + ' ' + "is up") else: print(ip + ' ' + "is down") else: print(ip + ' ' + "is down") except : pass |
运行效果如下所示。

同时,可以打开Wireshark软件进行流量监听,根据抓到的数据流量可以分 析,源主机向目标主机发送ACK请求,当主机存活时, 目标主机会发送一个
REST的应答数据包,效果如图4-3所示。
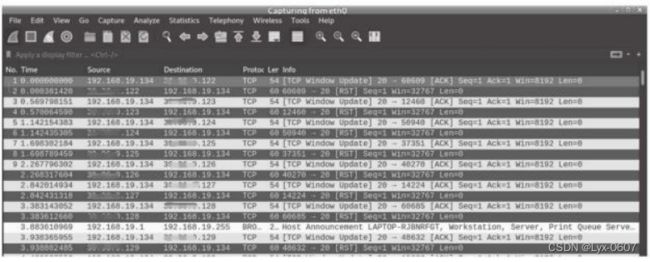
图4-3 向目标主机发送ACK请求时的监听效果
UDP(User Datagram Protocol ,用户数据报协议)是一种利用IP提供面向无 连接的网络通信服务。UDP会把应用程序发来的数据,在收到的一刻立即原样发 送到网络上。即使在网络传输过程中出现丢包、顺序错乱等情况时,UDP也不会 负责重新发送以及纠错。当向目标发送一个UDP数据包之后, 目标是不会发回任 何UDP数据包的。不过,如果目标主机处于活跃状态,但是目标端口是关闭状态 时,会返回一个ICMP数据包,这个数据包的含义为unreachable 。如果目标主机不 处于活跃状态,这时是收不到任何响应数据的。利用UDP原理可以实现探测存活 主机。
现在来编写一个利用UDP实现的活跃主机的扫描程序,首先借助Scapy库来完 成。在安装好Scapy的终端输入Scapy运行程序。设定远程IP地址为39.xx.xx.238,
端口dport可为任意值,此处将dport设为7345 ,通过sr1() 函数将构造好的数据包 发出。相关代码如下所示:
>>> udp=UDP()
>>> r = (ip/udp)
>>> r[IP] .dst="192 .168 .19 .141"
>>> r[UDP] .dport=734
>>> a=sr1(r)
如果目标主机处于存活状态,则会接收到目标主机的应答信息,可通过
a.display() 函数查看数据包信息。可以查看到返回的信息中存在ICMP的应答信 息,“code=port-unreachable”表示目标端口不可达。由此可以验证远程目标主机为 存活状态。若目标主机不为存活状态,则不会收到目标主机的响应数据包。响应 结果如下所示。
根据以上UDP发现存活主机的原理,我们可以编写相应的Python工具进行实 现,具体过程如下所示:
1)导入程序代码所应用到的模块:time 、optparse 、random和scapy 。time模 块主要用于产生延迟时间,optparse模块用于生成命令行参数,random模块用于生 成随机的端口,scapy模块用于以UDP发送请求以及接收应答数据。
| #!/usr/bin/python import time from optparse import OptionParser from random import randin t from scapy .all import * |
| 2)利用optparse模块生成命令行参数化形式,对用户输入的参数进行接收和 批量处理,最后将处理后的IP地址传入Scan() 函数。 |
def main() :
usage = "Usage: %prog -i " # 输出帮助信息
parse = OptionParser(usage=usage)
parse .add_option("-i", '--ip ', type="string", dest="target IP", help=
"specify the IP address") # 获取网段地址
options, args = parse .parse_args() #实例化用户输入的参数
if '- ' in options .target IP:
# 代码举例:192 .168 .1 .1-120
# 通过“ -”进行分隔,把192 .168 .1 .1和120进行分离
# 把192.168.1.1通过“,”进行分隔,取最后一个数作为range函数的start,然后把 120+1作为range函数的stop
# 这样循环遍历出需要扫描的IP地址
for i in range(in t(options .target IP .split( '- ')[0] .split( ' . ')[3]), in t (options .target IP .split( '- ')[1]) + 1) :
Scan(options .target IP .split( ' . ')[0] + ' . ' + options .target IP .split ( ' . ')[1] + ' . ' + options .target IP .split( ' . ')[2] + ' . ' + str(i))
else:
Scan(options .target IP)
if __name__ == '__main__ ' :
main()
| 3)Scan() 函数,通过调用UDP将构造好的请求包发送到目的地址,并根据 是否接收到目标主机的响应数据包判断主机的存活状态。若接收到响应数据包, proto字段整型数据为1时,则代表目标主机为存活状态,打印出“xx.xx.xx.xx Host is up” ,否则为不存活主机,打印出“xx.xx.xx.xx Host is down”。 |
| def Scan(ip) : try: dport = random .randin t(1, 65535) packet = IP(dst=ip)/UDP(dport=dport) response = sr1(packet,timeout=1 .0, verbose=0) response: if in t(response[IP] .proto) == 1: time .sleep(0 .5) print(ip + ' ' + "is up") else: print(ip + ' ' + "is down") else: print(ip + ' ' + "is down") except : pass |
运行效果如下所示。

同时,可以打开Wireshark软件进行流量监听,根据抓到的数据流量可以分 析,源主机向目标主机发送UDP数据包,当主机存活时, 目标主机会发送一
个“Destination unreachableb(port unreachable )” 的应答数据包,效果如图4-4所 示。
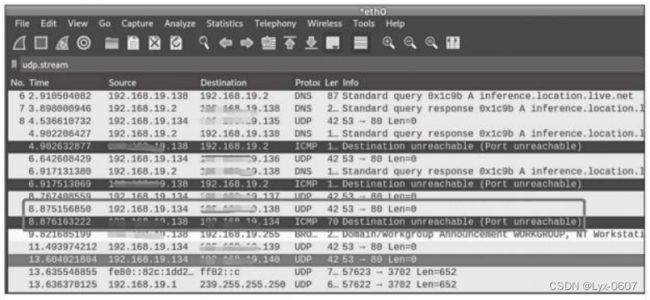
图4-4 向目标主机发送UDP数据包时的监听效果
对于TCP 、UDP主机发现,同样可以借助Nmap库来实现。这里需要用到
Nmap的-sT和-PU两个参数。详细的代码过程这里不再赘述,读者可在4.2.1节的基 础上进行修改,所需修改代码部分如下所示:
| result = nm .scan(hosts=target IP, arguments= '-sT ') |
| TCP主机发现的测试命令及效果如下: |
 result = nm .scan(hosts=target IP, arguments= '-PU ') |
UDP主机发现的测试效果如下:

4.2.3 基于ARP的主机发现
ARP协议(地址解析协议)属于数据链路层的协议,主要负责根据网络层地 址(IP)来获取数据链路层地址(MAC)。
以太网协议规定,同一局域网中的一台主机要和另一台主机进行直接通信, 必须知道目标主机的MAC地址。而在TCP/IP中,网络层只关注目标主机的IP地 址。这就导致在以太网中使用IP协议时,数据链路层的以太网协议接收到的网络 层IP协议提供的数据中,只包含目的主机的IP地址。于是需要ARP协议来完成IP 地址到MAC地址的转换。假设我们当前的以太网结构如图4-5所示。
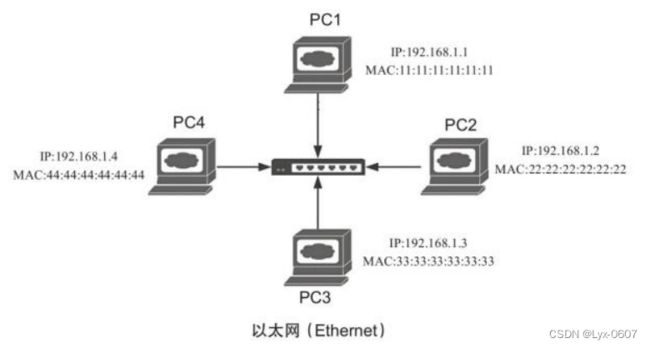
图4-5 以太网结构
在上述以太网结构中,假设PC1想与PC3通信,步骤如下。
1)PC1知道PC3的IP地址为192.168.1.3,然后PC1会检查自己的APR缓存表中 该IP是否有对应的MAC地址。
2)如果有,则进行通信。如果没有,PC1就会使用以太网广播包来给网络上 的每一台主机发送ARP请求,询问192.168.1.3的MAC地址。ARP请求中同时也包 含了PC1的IP地址和MAC地址。以太网内的所有主机都会接收到ARP请求,并检 查是否与自己的IP地址匹配。如果不匹配,则丢弃该ARP请求。
3)PC3确定ARP请求中的IP地址与自己的IP地址匹配,则将ARP请求中PC1 的IP地址和MAC地址添加到本地ARP缓存中。
4)PC3将自己的MAC地址发送给PC1。
5)PC1收到PC3的ARP响应时,将PC3的IP地址和MAC地址都更新到本地 ARP缓存表中。
本地ARP缓存表是有生存周期的,生存周期结束后,将再次重复上面的过 程。
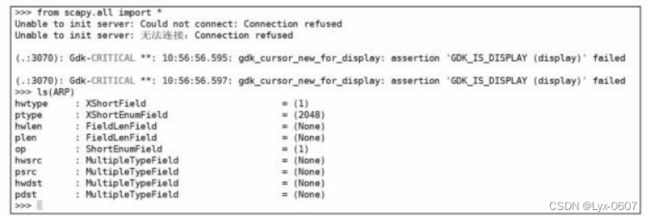
当目标主机与我们处于同一以太网的时候,利用ARP进行主机发现是一个最 好的选择。因为这种扫描方式快且精准。现在我们借助Scapy来编写ARP主机发现 脚本,通过脚本对以太网内的每个主机都进行ARP请求。若主机存活,则会响应 我们的ARP请求,否则不会响应。因为ARP涉及网络层和数据链路层,所以需要 使用Scapy中的Ether和ARP 。Scapy中的ARP参数如下所示:
Scapy中的Ether参数如下所示:

这里介绍一下脚本中所使用的参数。Ether中src表示源MAC地址,dst表示目 的MAC地址。ARP中op代表消息类型,1为ARP请求,2为ARP响应,hwsrc和psrc 表示源MAC地址和源IP地址,pdst表示目的IP地址。接下来我们编写ARP主机发 现脚本。
1)写入脚本信息,导入相关模块:
U
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import
import
import
from scapy .all import *
2)编写本机IP地址和MAC地址获取函数,通过正则表达式来进行获取:
| # 取IP地址和MAC地址函数 def HostAddress(iface) : # os .popen执行后返回执行结果 ipData = os .popen( 'ifconfig '+iface) # 对ipData进行类型转换,再用正则进行匹配 dataLine = ipData .readlines() # re .search利用正则匹配返回第一个成功匹配的结果,存在结果则为true # 取MAC地址 if re .search( '\w\w:\w\w:\w\w:\w\w:\w\w:\w\w ',str(dataLine)) : # 取出匹配的结果 MAC = re .search( '\w\w:\w\w:\w\w:\w\w:\w\w:\w\w ',str(dataLine)) .group(0) # 取IP地址 if re .search(r '((2[0-4]\d|25[0-5]|[01]?\d\d?)\ .){3}(2[0-4]\d|25[0-5]|[01]? \d\d?) ',str(dataLine )) : IP = re .search(r '((2[0-4]\d|25[0-5]|[01]?\d\d?)\ .){3}(2[0-4]\d|25[0-5]| [01]?\d\d?) ',str(dataLine)) .group(0) # 将IP和MAC通过元组的形式返回 addressInfo = (IP,MAC) return addressInfo |
| 3)编写ARP探测函数,根据本机的IP地址和MAC地址信息, 自动生成目标 进行探测并把结果写入文件: |
# ARP扫描函数
def ArpScan(iface= 'eth0 ') :
# 通过HostAddres返回的元组取出MAC地址
mac = HostAddress(iface)[1]
# 取出本机IP地址
ip = HostAddress(iface)[0]
# 对本机IP地址进行分隔并作为依据元素,用于生成需要扫描的IP地址
ipSplit = ip .split( ' . ')
# 需要扫描的IP地址列表
ipList = []
# 根据本机IP生成IP扫描范围
for i in range(1,255) :
ipItem = ipSplit[0] + ' . ' + ipSplit[1] + ' . ' + ipSplit[2] + ' . ' + str(i) ipList.append(ipItem)
'''
发送ARP包
因为要用到OSI的二层和三层,所以要写成Ether/ARP。
因为最底层用到了二层,所以要用srp()发包
'''
result=srp(Ether(src=mac,dst= 'FF:FF:FF:FF:FF:FF ')/ARP(op=1,hwsrc=mac,hwdst= '00:00:00:00:00:00 ',pds t=ipList),iface=iface,timeout=2,verbose=False)
# 读取result中的应答包和应答包内容
resultAns = result[0] .res
# 存活主机列表
liveHost = []
# number 为接收到应答包的总数
number = len(resultAns)
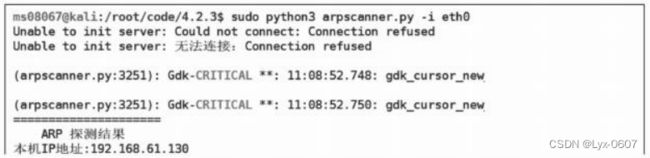
print("=====================")
print("ARP 探测结果")
print("本机IP地址 :" + ip)
print("本机MAC地址 :" + mac)
print("=====================")
for x in range(number) :
IP = resultAns[x][1][1] .fields[ 'psrc ']
MAC = resultAns[x][1][1] .fields[ 'hwsrc ']
liveHost.append([IP,MAC])
print("IP:" + IP + "\n\n" + "MAC:" + MAC )
print("=====================")
# 把存活主机IP写入文件
resultFile = open("result","w")
for i in range(len(liveHost)) :
resultFile .write(liveHost[i][0] + "\n")
resultFile .close()
| 4)编写main 函数,利用optparse模块生成命令行参数化形式: |
| if __name__ == '__main__ ' : parser = optparse .OptionParser( 'usage: python %prog -i interfaces \n\n ' 'Example: python %prog -i e th0\n ') # 添加网卡参数 -i parser .add_option( '-i ', '--iface ',dest= 'iface ',default= 'eth0 ',type= 'string ', help= 'interfaces name ') (options, args) = parser .parse_args() ArpScan(options .iface) |
这样我们的ARP主机发现脚本功能就完成了。脚本测试结果下所示:

查看结果文件如下所示:

提示:普通用户运行时需要进行sudo ,否则会出现Operation not permitted提 醒!
下面介绍通过Nmap库来实现ARP主机发现,这里需要用到Nmap的-PR参数。 详细的过程此处不再赘述,读者可在4.2.1节的基础上进行修改,所需修改的代码 部分如下所示:
U
result = nm .scan(hosts=target IP, arguments= '-PR ')
ARP主机发现,测试效果如下所示:

4.2.4 端口探测
端口是设备与外界通信交流的接口。如果把服务器看作一栋房子,那么端口 就是可以进出这栋房子的门。真正的房子只有一个或几个门,但是服务器可以至 多有65 536个门。不同的端口(门)可以指向不同的服务(房间)。
例如,我们经常浏览网页时涉及的WWW服务用的是80号端口,上传或下载 文件时的FTP服务用的是21号端口,远程桌面用的是3389号端口。
所以入侵者想要获取到房子(服务器)的控制权,势必要先从一个门进入一 个房间,再通过这个房间控制整个房子。那么服务器开了几个端口,端口后面的 服务是什么,这些都是十分重要的信息,可以为入侵者制定详细的入侵计划提供 依据。因此在信息搜集阶段,端口开放情况的扫描就显得尤为重要。
下面将通过Python的Socket模块来编写一个简便的多线程端口扫描工具。
1)导入脚本信息以及相关的模块:
| #!/usr/bin/python3 # -*- coding:utf-8 -*- |
| import import import import import |
sys socket optparse threading queue |
| 2)编写一个端口扫描类,继承threading.Thread 。这个类需要传递3个参数, 分别是目标IP 、端口队列、超时时间。通过这个类创建多个子线程来加快扫描进 度: |
# 端口扫描类,继承threading .Thread
class PortScaner(threading .Thread) :
# 需要传入端口队列、 目标IP,探测超时时间
def __init__(self, portqueue, ip, timeout=3) :
threading .Thread.__init__(self)
self._portqueue = portqueue
self._ip = ip
self._timeout = timeout
def run(self) :
while True:
# 判断端口队列是否为空
if self._portqueue .empty() :
# 端口队列为空,说明已经扫描完毕,跳出循环
break
# 从端口队列中取出端口,超时时间为1s
port = self._portqueue .get(timeout=0 .5)
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s .settimeout(self._timeout)
result_code = s .connect_ex((self._ip, port))
# sys .stdout.write("[%d]Scan\n" % port)
# 若端口开放,则会返回0
if result_code == 0:
sys .stdout.write("[%d] OPEN\n" % port)
except Exception as e:
print(e)
finally:
s .close()
| 3)编写一个函数,根据用户的参数来指定目标IP 、端口队列的生成以及子线 程的生成,同时能支持单个端口的扫描和范围端口的扫描: |
| def StartScan(targetip, port, threadNum) : # 端口列表 port List = [] portNumb = port # 判断是单个端口还是范围端口 if '- ' in port : for i in range(in t(port.split( '- ')[0]), in t(port.split( '- ')[1])+1) : port List.append(i) else: port List.append(in t(port)) # 目标IP地址 ip = targetip # 线程列表 threads = [] # 线程数量 threadNumber = threadNum # 端口队列 portQueue = queue .Queue() # 生成端口,加入端口队列 for port in port List : portQueue .put(port) for t in range(threadNumber) : threads .append(PortScaner(portQueue, ip, timeout=3)) # 启动线程 for thread in threads: thread.start() # 阻塞线程 for thread in threads: thread.join() |
| 4)编写主函数来制定参数的规则: |
| if __name__ == '__main__ ' : parser = optparse .OptionParser( 'Example: python %prog -i 127 .0 .0 .1 -p 80 \n python %prog -i 127 .0 .0 .1 -p 1-100\n ') # 目标IP参数-i parser .add_option( '-i ', '--ip ', dest= 'target IP ',default= '127 .0 .0 .1 ', type= 'string ',help= 'target IP ') # 添加端口参数-p parser .add_option( '-p ', '--port ', dest= 'port ', default= '80 ', type= 'string ', help= 'scann port ') # 线程数量参数-t parser .add_option( '-t ', '--thread ', dest= 'threadNum ', default=100, type= 'in t ', help= 'scann thread number ') (options, args) = parser .parse_args() StartScan(options .target IP, options .port, options .threadNum) |
这里打开了一个CentOS7的服务器作为目标,IP地址为192.168.61.62 ,服务器
开放了22 、80 、3306号端口,然后利用编写好的程序脚本对服务器进行端口扫 描,扫描结果如下所示:

再对服务器进行范围端口的扫描,如下所示:

对于开放端口探测,同样也可以借助Nmap库来实现,这里需要用到Nmap的- p参数。详细的代码此处不再赘述,读者可在4.2.1节的基础上进行修改。所需修 改的代码部分如下所示:
U
result = nm .scan(hosts=target IP, arguments= '-p '+str(targetPort))
测试效果如下:

4.2.5 服务识别
在渗透测试的过程中,服务识别是一个很重要的环节。如果能识别出目标主 机的服务、版本等信息,对于渗透测试将有重要帮助。对于入侵者来说,发现这 些运行在目标上的服务,就可以利用这些软件上的漏洞入侵目标;对于网络安全 的维护者来说,也可以提前发现系统的漏洞,从而预防这些入侵行为。
很多扫描工具都采用了一种十分简单的方式,就是根据端口判断服务类型,
因为通常常见的服务都会运行在固定的端口上(见表4-1~表4-7),例如,FTP服 务总会运行在21号端口上,HTTP服务运行在80号端口上。但是利用该方式进行
服务识别存在明显的缺陷,很多人会将服务运行在其他端口上,例如,将本来运 行在23号端口上的Telnet运行在22号端口上,这样就会误以为这是一个SSH服务, 进而增加不必要的工作量。由于很多软件在连接之后都会提供一个表明自身信息 的banner ,在这里我们可以根据获取的banner信息对运行的服务类型进行判断,进 而可以确定开放端口对应的服务类型及版本号。
表4-1 文件共享服务端口

表4-2 远程连接服务端口
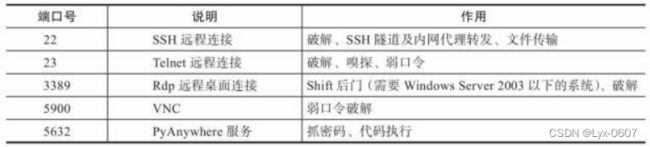
表4-3 Web应用服务端口
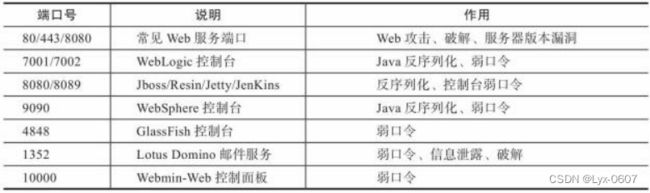
表4-4 数据库服务端口
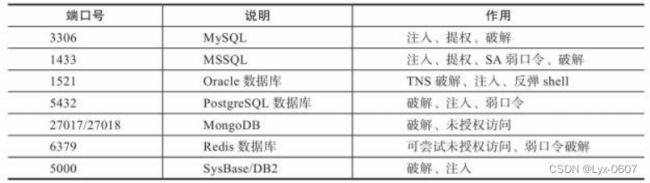
表4-5 邮件服务端口

表4-6 网络常见协议端口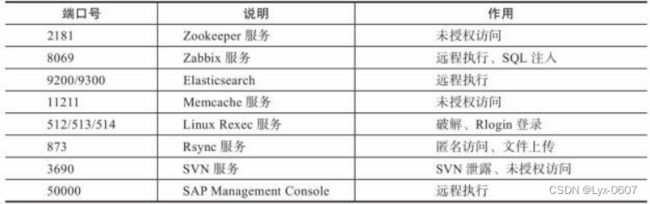
表4-7 特殊服务端口
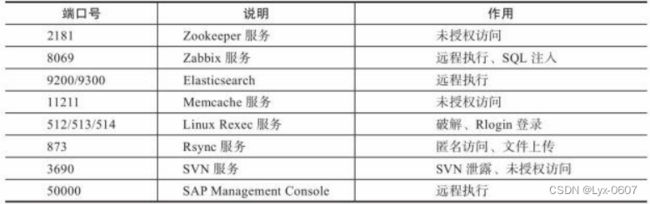
因此,可以向目标开放的端口发送探针数据包,根据目标主机返回的banner 信息与存储总结的banner信息进行比对,进而确定运行的服务类型。著名的Nmap 扫描工具就是采用了这种方法,它包含一个十分强大的banner数据库,而且这个 库仍在不断完善中。接下来按照上面介绍的思路来编写对目标服务进行扫描的程 序。
1)导入程序代码所应用到的模块:time 、optparse 、socket和re 。time模块主 要用于产生延迟时间,optparse模块用于生成命行参数,socket模块用于产生TCP 请求,re模块为正则表达式模块,与指纹信息进行有效匹配,进而确定服务类
型。SIGNS为指纹库,用于对目标
from optparse import OptionParser
import
import
import
SIGNS = (
# 协议 | 版本 | 关键字
b 'FTP |FTP |^220 .*FTP ',
b 'MySQL |MySQL |mysql_native_password ',
b 'oracle-https |^220- ora ',
b 'Telnet|Telnet|Telnet ',
b 'Telnet|Telnet|^\r\n%connection closed by remote host!\x00$ ',
b 'VNC |VNC |^RFB ',
b 'IMAP |IMAP |^\* OK .*?IMAP ',
b 'POP |POP |^\+OK .*? ',
b 'SMTP |SMTP |^220 .*?SMTP ',
b 'Kangle |Kangle |HTTP .*kangle ',
b 'SMTP |SMTP |^554 SMTP ',
b 'SSH |SSH |^SSH- ',
b 'HTTPS |HTTPS |Location: https ',
b 'HTTP |HTTP |HTTP/1 .1 ',
b 'HTTP |HTTP |HTTP/1 .0 ',
)
def main() :
parser = OptionParser("Usage:%prog -i ") # 输出帮助信息
parser .add_option( '-i ',type= 'string ',dest= 'IP ',help= 'specify target host ') # 获取IP地址参数
parser .add_option( '-p ', type= 'string ', dest= 'PORT ', help= 'specify target
host ') # 获取IP地址参数
options,args = parser .parse_args()
ip = options .IP
port = options .PORT
print("Scan report for "+ip+"\n")
for line in port.split( ', ') :
request(ip,line)
time .sleep(0 .2)
print("\nScan finished!. . .\n")
if __name__ == "__main__" :
try:
main()
except Keyboard Interrupt :
print("interrupted by user, killing all threads . . .")
| 3)在request() 函数中,首先调用sock.connect() 函数探测目标主机端口 是否开放,如果端口开放,则利用sock.sendall() 函数将PROBE探针发送给目标 端口。sock.recv() 函数用于接收返回的指纹信息,并将指纹信息及端口发送到 regex() 函数。 |
| def request(ip,port) : response = ' ' PROBE = 'GET / HTTP/1 .0\r\n\r\n ' sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.settimeout(10) result = sock.connect_ex((ip, in t(port))) if result == 0: try: sock.sendall(PROBE .encode()) response = sock.recv(256) if response: regex(response, port) except(ConnectionResetError,socket.timeout) : pass else: pass sock.close() |
| 4)利用re.search() 函数将返回的banner信息与SIGNS包含的指纹信息进行 正则匹配,并将匹配到的结果输出。如果没有在SIGNS中找到相匹配的信息,则 输出Unrecognized。 |
def regex(response, port) :
text = ""
if re .search(b '
502 Bad Gateway ', response) :</p>
<p style="margin-left:.0001pt;text-align:left;">proto = {"Service failed to access !!"}</p>
<p style="margin-left:.0001pt;text-align:left;">for pattern in SIGNS:</p>
<p style="margin-left:.0001pt;text-align:left;">pattern = pattern .split(b ' | ')</p>
<p style="margin-left:.0001pt;text-align:left;">if re .search(pattern[-1], response, re .IGNORECASE) :</p>
<p style="margin-left:.0001pt;text-align:left;">proto = "["+port+"]" + " open " + pattern[1] .decode()</p>
<p style="margin-left:.0001pt;text-align:left;">break</p>
<p style="margin-left:.0001pt;text-align:left;">else:</p>
<p style="margin-left:.0001pt;text-align:left;">proto = "["+port+"]" + " open " + "Unrecognized"</p>
<p style="margin-left:.0001pt;text-align:left;">print(proto)</p>
</div>
<p> </p>
<div>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<table style="width:468pt;">
<tbody>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;"> </p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;">端口服务版本的识别实现起来也是比较困难的, 目前市面上能提供相关服务 的软件也非常多,而且每个软件也会出现多个版本。下面借助Nmap库来实现对主 机端口服务的探测,这里还需要用到Nmap的-sV参数。详细的代码此处就不再赘 述,读者可在4.2.1节的基础上进行修改,所需修改的代码部分如下所示:</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:36.9pt;">(2) print("[{} :{}] : [{} :{}]" .format(targetPort, port_infor[ 'state '] , port_ infor[ 'name '], port_infor[ 'product '])</p> </td>
</tr>
</tbody>
</table>
<p style="margin-left:.0001pt;text-align:left;">测试效果如下:</p>
</div>
<p> </p>
<div>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;">4.2.6 系统识别</p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;">识别出目标主机操作系统的类型和版本,可以大量减少不必要的测试成本, 缩小测试范围,更精确地针对目标进行渗透测试。</p>
<p style="margin-left:.0001pt;text-align:left;">但是判断目标的操作系统并非一件简单的事情。因为现在的操作系统类型繁 多,仅Windows和Linux就有包含了许多衍生系统,同时,现今的防火墙、路由 器、智能设备等都有其自带的操作系统,所以需要精确判断目标操作系统的类型 并非易事。 目前主要通过“指纹识别” 的方式来对目标的操作系统来进行猜测。检 测的方法一般分为两种:主动式探测和被动式探测。</p>
<p style="margin-left:.0001pt;text-align:justify;">(1)主动式探测:向目标主机发送一段特定的数据包,根据目标主机对数 据包做出的回应进行分析,判断目标主机中可能的操作系统类型。与被动式探测 相比,主动式获取的结果更加精确,但也容易触发目标安全系统的警报。</p>
<p style="margin-left:.0001pt;text-align:justify;">(2)被动式探测:通过工具嗅探、记录、分析数据包流。根据数据包信息 来分析目标主机的操作系统。与主动式探测相比,被动式探测的结果虽然不如主 动式探测精确,但是不容易被目标主机安全系统察觉。</p>
<p style="margin-left:.0001pt;text-align:left;">主机识别的技术原理:Windows操作系统与Linux操作系统的TCP/IP实现方式 并不相同,导致两种系统对特定格式的数据包会有不同的响应结果,包括响应数 据包的内容、响应时间等,形成了操作系统的指纹。通常情况下,可在对目标主 机进行ping操作后,依据其返回的TTL值对系统类型进行判断,Windows系统的 TTL起始值为128 ,Linux系统的TTL起始值为64 ,且每经过一跳路由,TTL值减 1。</p>
<p style="margin-left:.0001pt;text-align:left;">Windows的TTL返回值如下:</p>
<p style="margin-left:.0001pt;text-align:left;"><a href="http://img.e-com-net.com/image/info8/c12b8aaefea34a6e9d0a216831079c7c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c12b8aaefea34a6e9d0a216831079c7c.jpg" alt="主动信息搜集_第20张图片" width="650" height="117" style="border:1px solid black;"></a></p>
<p style="margin-left:.0001pt;text-align:left;">Linux的TTL返回值如下:</p>
</div>
<p> </p>
<div>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p> <a href="http://img.e-com-net.com/image/info8/a8485d8a6170445da4bee91ed63f2147.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/a8485d8a6170445da4bee91ed63f2147.jpg" alt="主动信息搜集_第21张图片" width="650" height="137" style="border:1px solid black;"></a>
<p style="margin-left:.0001pt;text-align:left;">根据按照目标主机返回的响应数据包中的TTL值来判断操作系统类型的原 理,可编写Python程序实现自动化,详细过程如下所示。</p>
<p style="margin-left:.0001pt;text-align:left;">1)导入程序代码所应用的模块:optparse 、os和re 。optparse用于生成命行参 数;os用于执行系统命令;re为正则表达式模块,用于匹配返回的TTL值。</p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<table style="width:468pt;">
<tbody>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:16.4pt;">#!/usr/bin/python3 .7</p> <p style="margin-left:16.4pt;">#!coding:utf-8</p> <p style="margin-left:16.75pt;">from optparse import OptionParser</p> <p style="margin-left:16.75pt;">import os</p> <p style="margin-left:16.75pt;">import re</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;">2)利用optparse模块生成命令行参数化形式,对用户输入的参数进行接收和 批量处理,最后将处理后的IP地址传入ttl_scan() 函数。</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:16.75pt;">def main() :</p> <p style="margin-left:37.05pt;">parser = OptionParser("Usage:%prog -i <target host> ") # 输出帮助信息</p> <p style="margin-left:56.65pt;">parser .add_option( '-i ',type= 'string ',dest= 'IP ',help= 'specify target host ') # 获取IP地址参数</p> <p style="margin-left:36.85pt;">options,args = parser .parse_args()</p> <p style="margin-left:36.9pt;">ip = options .IP</p> <p style="margin-left:37.1pt;">ttl_scan(ip)</p> <p style="margin-left:16.75pt;">if __name__ == "__main__" :</p> <p style="margin-left:36.7pt;">main()</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;">3)调用os.popen() 函数执行ping命令,并将返回的结果通过正则表达式识</p> <p style="margin-left:.0001pt;text-align:left;">别,提取出TTL值。当TTL值小于等于64时,操作系统为Linux类型,输 出“xx.xx.xx.xx is Linux/UNIX” ,否则输出“xx.xx.xx.xx is Windows”。</p> </td>
</tr>
</tbody>
</table>
<p style="margin-left:.0001pt;text-align:left;">def ttl_scan(ip) :</p>
<p style="margin-left:.0001pt;text-align:left;">ttlstrmatch = re .compile(r 'ttl=\d+ ')</p>
<p style="margin-left:.0001pt;text-align:left;">ttlnummatch = re .compile(r '\d+ ')</p>
<p style="margin-left:.0001pt;text-align:left;">result = os .popen("ping -c 1 "+ip)</p>
<p style="margin-left:.0001pt;text-align:left;">res = result.read()</p>
<p style="margin-left:.0001pt;text-align:left;">for line in res .splitlines() :</p>
<p style="margin-left:.0001pt;text-align:left;">result = ttlstrmatch.findall(line)</p>
<p style="margin-left:.0001pt;text-align:left;">if result :</p>
<p style="margin-left:.0001pt;text-align:left;">ttl = ttlnummatch.findall(result[0])</p>
<p style="margin-left:.0001pt;text-align:left;">if in t(ttl[0]) <= 64: # 判断目标主机响应包中TTL值是否小于等于64</p>
<p style="margin-left:.0001pt;text-align:left;">print("%s is Linux/UNIX"%ip) # TTL≤64时为Linux/UNIX系统 else:</p>
<p style="margin-left:.0001pt;text-align:left;">print("%s is Windows"%ip) # 反之为Windows系统</p>
<p style="margin-left:.0001pt;text-align:left;">else:</p>
<p style="margin-left:.0001pt;text-align:left;">pass</p>
</div>
<p> </p>
<div>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<table style="width:468pt;">
<tbody>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;">运行结果如下:</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"><a href="http://img.e-com-net.com/image/info8/43550f13e1d04f5990f0b9aeab182b44.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/43550f13e1d04f5990f0b9aeab182b44.jpg" alt="9937f9b7510d41d4b039231045803384.png" width="650" height="73"></a></td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:.0001pt;text-align:left;">当然,这里也可以借助Nmap库来实现操作系统类型识别的功能,通过Nmap 的-O参数对目标主机操作进行系统识别,代码如下所示:</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:468pt;"> <p style="margin-left:17.15pt;">result = nm .scan(hosts=target IP, arguments= '-O ')</p> </td>
</tr>
</tbody>
</table>
<p style="margin-left:.0001pt;text-align:left;">借助Nmap库我们可以很轻松地完成一个主动式系统探测工具,而且其判断的 结果在实际运用中也非常具有参考价值。</p>
<p style="margin-left:.0001pt;text-align:left;">运行结果如下:</p> <a href="http://img.e-com-net.com/image/info8/5d2b19c8d8b6490c9d10494619abce3e.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/5d2b19c8d8b6490c9d10494619abce3e.jpg" alt="主动信息搜集_第22张图片" width="650" height="110" style="border:1px solid black;"></a>
</div>
<p> </p>
<div>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;">4.2.7 敏感目录探测</p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:justify;">资源发现属于信息搜集的一部分,善于发现隐藏的信息,如隐藏目录、隐藏 文件等,可提高渗透测试的全面细致性。本节将用Python实现敏感目录发现。在 渗透测试过程中,资源发现是极其重要的一环。具备好的资源发现能力能够令整 个工作事半功倍。</p>
<p style="margin-left:.0001pt;text-align:justify;">在渗透测试过程中进行目录扫描是很有必要的,例如,当发现开发过程中未 关闭或忘记关闭的页面,可能就会发现许多可以利用的信息。下面我们编写一个 基于字典的目录扫描脚本。</p>
<p style="margin-left:.0001pt;text-align:left;">1)要进行网页目录扫描,需要进行网页访问,所以先导入requests模块备 用,然后等待用户输入url和字典:</p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<table style="width:469.25pt;">
<tbody>
<tr>
<td style="vertical-align:top;width:469.25pt;"> <p style="margin-left:16.75pt;">import requests</p> <p style="margin-left:16.95pt;">headers = {</p> <p style="margin-left:16.85pt;">"User-Agent" : "Mozilla/5 .0 (Windows NT 6 .1; WOW64; rv:6 .0) Gecko/20100101 Firefox/6 .0" }</p> <p style="margin-left:16.95pt;">url = input("url : ")</p> <p style="margin-left:16.95pt;">txt = input( 'php .txt ')</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:469.25pt;"> <p style="margin-left:.0001pt;text-align:left;">2)当用户没有输入字典时,默认打开根目录的php.txt ,后将字典中的内容 放进队列中:</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:469.25pt;"> <p style="margin-left:16.95pt;">url_list = []</p> <p style="margin-left:16.75pt;">if txt == "" :</p> <p style="margin-left:37.1pt;">txt = "php .txt"</p> <p style="margin-left:16.95pt;">try:</p> <p style="margin-left:36.4pt;">with open(txt, 'r ') as f :</p> <p style="margin-left:57pt;">for a in f :</p> <p style="margin-left:77.1pt;">a = a .replace( '\n ', '')</p> <p style="margin-left:77.35pt;">url_list.append(a)</p> <p style="margin-left:57pt;">f.close()</p> <p style="margin-left:16.7pt;">except :</p> <p style="margin-left:37.05pt;">print("error!")</p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:469.25pt;"> <p style="margin-left:.0001pt;text-align:left;">3)将队列中的内容拼接到url中组成需要验证的地址,通过返回值判断是否 存在此目录:</p> <p style="margin-left:.0001pt;text-align:left;"> </p> </td>
</tr>
<tr>
<td style="vertical-align:top;width:469.25pt;"> <p style="margin-left:16.75pt;">for li in url_list :</p> <p style="margin-left:36.85pt;">conn = "http://" + url +"/"+ li</p> <p style="margin-left:37.1pt;">try:</p> <p style="margin-left:62.5pt;">response = requests .get(conn,headers = headers)</p> <p style="margin-left:62.2pt;">print("%s %s" % (conn, response))</p> <p style="margin-left:36.85pt;">except e:</p> <p style="margin-left:57.2pt;">print( '%s-------------%s ' %(conn, e .code))</p> </td>
</tr>
</tbody>
</table>
<p style="margin-left:.0001pt;text-align:left;"> </p>
</div>
<p> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;"> </p>
<p style="margin-left:.0001pt;text-align:left;">至此,一个简单的目录扫描脚本就完成了。运行效果如下所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/f68fc93b6f8746fd8a80e89086aa8f18.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f68fc93b6f8746fd8a80e89086aa8f18.jpg" alt="主动信息搜集_第23张图片" width="650" height="183" style="border:1px solid black;"></a></p>
<p> </p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1753943922737954816"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(笔记)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1950232782412247040.htm"
title="日更006 终极训练营day3" target="_blank">日更006 终极训练营day3</a>
<span class="text-muted">懒cici</span>
<div>人生创业课(2)今天的主题:学习方法一:遇到有用的书,反复读,然后结合自身实际,列践行清单,不要再写读书笔记思考这本书与我有什么关系,我在哪些地方能用到,之后我该怎么用方法二:读完书没映像怎么办?训练你的大脑,方法:每读完一遍书,立马合上书,做一场分享,几分钟都行对自己的学习要求太低,要逼自己方法三:学习深度不够怎么办?找到细分领域的榜样,把他们的文章、书籍、产品都体验一遍,成为他们的超级用户,向</div>
</li>
<li><a href="/article/1950220179610857472.htm"
title="【花了N长时间读《过犹不及》,不断练习,可以越通透】" target="_blank">【花了N长时间读《过犹不及》,不断练习,可以越通透】</a>
<span class="text-muted">君君Love</span>
<div>我已经记不清花了多长时间去读《过犹不及》,读书笔记都写了42页,这算是读得特别精细的了。是一本难得的好书,虽然书中很多内容和圣经吻合,我不是基督徒,却觉得这样的文字值得细细品味,和我们的生活息息相关。我是个界线建立不牢固的人,常常愧疚,常常害怕他人的愤怒,常常不懂拒绝,还有很多时候表达不了自己真实的感受,心里在说不嘴里却在说好……这本书给我很多的启示,让我学会了怎样去建立属于自己的清晰的界限。建立</div>
</li>
<li><a href="/article/1950218819616174080.htm"
title="基于redis的Zset实现作者的轻量级排名" target="_blank">基于redis的Zset实现作者的轻量级排名</a>
<span class="text-muted">周童學</span>
<a class="tag" taget="_blank" href="/search/Java/1.htm">Java</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a>
<div>基于redis的Zset实现轻量级作者排名系统在今天的技术架构中,Redis是一种广泛使用的内存数据存储系统,尤其在需要高效检索和排序的场景中表现优异。在本篇博客中,我们将深入探讨如何使用Redis的有序集合(ZSet)构建一个高效的笔记排行榜系统,并提供相关代码示例和详细的解析。1.功能背景与需求假设我们有一个笔记分享平台,用户可以发布各种笔记,系统需要根据用户发布的笔记数量来生成一个实时更新的</div>
</li>
<li><a href="/article/1950216170401492992.htm"
title="常规笔记本和加固笔记本的区别" target="_blank">常规笔记本和加固笔记本的区别</a>
<span class="text-muted">luchengtech</span>
<a class="tag" taget="_blank" href="/search/%E7%94%B5%E8%84%91/1.htm">电脑</a><a class="tag" taget="_blank" href="/search/%E4%B8%89%E9%98%B2%E7%AC%94%E8%AE%B0%E6%9C%AC/1.htm">三防笔记本</a><a class="tag" taget="_blank" href="/search/%E5%8A%A0%E5%9B%BA%E8%AE%A1%E7%AE%97%E6%9C%BA/1.htm">加固计算机</a><a class="tag" taget="_blank" href="/search/%E5%8A%A0%E5%9B%BA%E7%AC%94%E8%AE%B0%E6%9C%AC/1.htm">加固笔记本</a>
<div>在现代科技产品中,笔记本电脑因其便携性和功能性被广泛应用。根据使用场景和需求的不同,笔记本可分为常规笔记本和加固笔记本,二者在多个方面存在显著区别。适用场景是区分二者的重要标志。常规笔记本主要面向普通消费者和办公人群,适用于家庭娱乐、日常办公、学生学习等相对稳定的室内环境。比如,人们在家用它追剧、处理文档,学生在教室用它完成作业。而加固笔记本则专为特殊行业设计,像军事、野外勘探、工业制造、交通运输</div>
</li>
<li><a href="/article/1950210374787723264.htm"
title="第八课: 写作出版你最关心的出书流程和市场分析(无戒学堂复盘)" target="_blank">第八课: 写作出版你最关心的出书流程和市场分析(无戒学堂复盘)</a>
<span class="text-muted">人在陌上</span>
<div>今天是周六,恰是圣诞节。推掉了两个需要凑腿的牌局,在一个手机,一个笔记本,一台电脑,一杯热茶的陪伴下,一个人静静地回听无戒学堂的最后一堂课。感谢这一个月,让自己的习惯开始改变,至少,可以静坐一个下午而不觉得乏味枯燥难受了,要为自己点个赞。我深知,这最后一堂课的内容,以我的资质和毅力,可能永远都用不上。但很明显,无戒学堂是用了心的,毕竟,有很多优秀学员,已经具备了写作能力,马上就要用到这堂课的内容。</div>
</li>
<li><a href="/article/1950208107430866944.htm"
title="python笔记14介绍几个魔法方法" target="_blank">python笔记14介绍几个魔法方法</a>
<span class="text-muted">抢公主的大魔王</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>python笔记14介绍几个魔法方法先声明一下各位大佬,这是我的笔记。如有错误,恳请指正。另外,感谢您的观看,谢谢啦!(1).__doc__输出对应的函数,类的说明文档print(print.__doc__)print(value,...,sep='',end='\n',file=sys.stdout,flush=False)Printsthevaluestoastream,ortosys.std</div>
</li>
<li><a href="/article/1950205034075582464.htm"
title="《感官品牌》读书笔记 1" target="_blank">《感官品牌》读书笔记 1</a>
<span class="text-muted">西红柿阿达</span>
<div>原文:最近我在东京街头闲逛时,与一位女士擦肩而过,我发现她的香水味似曾相识。“哗”的一下,记亿和情感立刻像潮水般涌了出来。这个香水味把我带回了15年前上高中的时候,我的一位亲密好友也是用这款香水。一瞬间,我呆站在那里,东京的街景逐渐淡出,取而代之的是我年少时的丹麦以及喜悦、悲伤、恐惧、困惑的记忆。我被这熟悉的香水味征服了。感想:感官是有记忆的,你所听到,看到,闻到过的有代表性的事件都会在大脑中深深</div>
</li>
<li><a href="/article/1950203883577995264.htm"
title="我不想再当知识的搬运工" target="_blank">我不想再当知识的搬运工</a>
<span class="text-muted">楚煜楚尧</span>
<div>因为学校课题研究的需要,这个暑假我依然需要完成一本书的阅读笔记。我选的是管建刚老师的《习课堂十讲》。这本书,之前我读过,所以重读的时候,感到很亲切,摘抄起来更是非常得心应手。20页,40面,抄了十天,终于在今天大功告成了。这对之前什么事都要一拖再拖的我来说,是破天荒的改变。我发现至从认识小尘老师以后,我的确发生了很大的改变。遇到必须做却总是犹豫不去做的事,我学会了按照小尘老师说的那样,在心里默默数</div>
</li>
<li><a href="/article/1950199576451411968.htm"
title="20210517坚持分享53天读书摘抄笔记 非暴力沟通——爱自己" target="_blank">20210517坚持分享53天读书摘抄笔记 非暴力沟通——爱自己</a>
<span class="text-muted">f79a6556cb19</span>
<div>让生命之花绽放在赫布·加德纳(HerbGardner)编写的《一千个小丑》一剧中,主人公拒绝将他12岁的外甥交给儿童福利院。他郑重地说道:“我希望他准确无误地知道他是多么特殊的生命,要不,他在成长的过程中将会忽视这一点。我希望他保持清醒,并看到各种奇妙的可能。我希望他知道,一旦有机会,排除万难给世界一点触动是值得的。我还希望他知道为什么他是一个人,而不是一张椅子。”然而,一旦负面的自我评价使我们看</div>
</li>
<li><a href="/article/1950196906563006464.htm"
title="Unity学习笔记1" target="_blank">Unity学习笔记1</a>
<span class="text-muted">zy_777</span>
<div>通过一个星期的简单学习,初步了解了下unity,unity的使用,以及场景的布局,UI,以及用C#做一些简单的逻辑。好记性不如烂笔头,一些关键帧还是记起来比较好,哈哈,不然可能转瞬即逝了,(PS:纯小白观点,unity大神可以直接忽略了)一:MonoBehaviour类的初始化1,Instantiate()创建GameObject2,通过Awake()和Start()来做初始化3,Update、L</div>
</li>
<li><a href="/article/1950190146074767360.htm"
title="大数据技术笔记—spring入门" target="_blank">大数据技术笔记—spring入门</a>
<span class="text-muted">卿卿老祖</span>
<div>篇一spring介绍spring.io官网快速开始Aop面向切面编程,可以任何位置,并且可以细致到方法上连接框架与框架Spring就是IOCAOP思想有效的组织中间层对象一般都是切入service层spring组成前后端分离已学方式,前后台未分离:Spring的远程通信:明日更新创建第一个spring项目来源:科多大数据</div>
</li>
<li><a href="/article/1950187554129113088.htm"
title="Django学习笔记(一)" target="_blank">Django学习笔记(一)</a>
<span class="text-muted"></span>
<div>学习视频为:pythondjangoweb框架开发入门全套视频教程一、安装pipinstalldjango==****检查是否安装成功django.get_version()二、django新建项目操作1、新建一个项目django-adminstartprojectproject_name2、新建APPcdproject_namedjango-adminstartappApp注:一个project</div>
</li>
<li><a href="/article/1950179614320029696.htm"
title="python学习笔记(汇总)" target="_blank">python学习笔记(汇总)</a>
<span class="text-muted">朕的剑还未配妥</span>
<a class="tag" taget="_blank" href="/search/python%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%E6%95%B4%E7%90%86/1.htm">python学习笔记整理</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>文章目录一.基础知识二.python中的数据类型三.运算符四.程序的控制结构五.列表六.字典七.元组八.集合九.字符串十.函数十一.解决bug一.基础知识print函数字符串要加引号,数字可不加引号,如print(123.4)print('小谢')print("洛天依")还可输入表达式,如print(1+3)如果使用三引号,print打印的内容可不在同一行print("line1line2line</div>
</li>
<li><a href="/article/1950175578921431040.htm"
title="Redis 分布式锁深度解析:过期时间与自动续期机制" target="_blank">Redis 分布式锁深度解析:过期时间与自动续期机制</a>
<span class="text-muted">爱恨交织围巾</span>
<a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/1.htm">分布式事务</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%BE%AE%E6%9C%8D%E5%8A%A1/1.htm">微服务</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/go/1.htm">go</a>
<div>Redis分布式锁深度解析:过期时间与自动续期机制在分布式系统中,Redis分布式锁的可靠性很大程度上依赖于对锁生命周期的管理。上一篇文章我们探讨了分布式锁的基本原理,今天我们将聚焦于一个关键话题:如何通过合理设置过期时间和实现自动续期机制,来解决分布式锁中的死锁与锁提前释放问题。一、为什么过期时间是分布式锁的生命线?你的笔记中提到"服务挂掉时未删除锁可能导致死锁",这正是过期时间要解决的核心问题</div>
</li>
<li><a href="/article/1950175508729753600.htm"
title="08.学习闭环三部曲:预习、实时学习、复习" target="_blank">08.学习闭环三部曲:预习、实时学习、复习</a>
<span class="text-muted">0058b195f4dc</span>
<div>人生就是一本效率手册,你怎样对待时间,时间就会给你同比例的回馈。单点突破法。预习,实时学习,复习。1、预习:凡事提前【计划】(1)前一晚设置三个当日目标。每周起始于每周日。(2)提前学习。预习法进行思考。预不预习效果相差20%,预习法学会提问。(3)《学会提问》。听电子书。2.实时学习(1)(10%)相应场景,思维导图,快速笔记。灵感笔记。(2)大纲,基本记录,总结篇。3.复习法则,(70%),最</div>
</li>
<li><a href="/article/1950165603524341760.htm"
title="《如何写作》文心读书笔记" target="_blank">《如何写作》文心读书笔记</a>
<span class="text-muted">逆熵反弹力</span>
<div>《文心》这本书的文体是以讲故事的形式来讲解如何写作的,读起来不会觉得刻板。读完全书惊叹大师的文笔如此之好,同时感叹与此书相见恨晚。工作了几年发现表达能力在生活中越来越重要,不管是口语还是文字上的表达。有时候甚至都不能把自己想说的东西表达清楚,平时也有找过一些书来看,想通过提升自己的阅读量来提高表达能力。但是看了这么久的书发现见效甚微,这使得我不得不去反思,该怎么提高表达能力。因此打算从写作入手。刚</div>
</li>
<li><a href="/article/1950161706533580800.htm"
title="SQL笔记纯干货" target="_blank">SQL笔记纯干货</a>
<span class="text-muted">AI入门修炼</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a>
<div>软件:DataGrip2023.2.3,phpstudy_pro,MySQL8.0.12目录1.DDL语句(数据定义语句)1.1数据库操作语言1.2数据表操作语言2.DML语句(数据操作语言)2.1增删改2.2题2.3备份表3.DQL语句(数据查询语言)3.1查询操作3.2题一3.3题二4.多表详解4.1一对多4.2多对多5.多表查询6.窗口函数7.拓展:upsert8.sql注入攻击演示9.拆表</div>
</li>
<li><a href="/article/1950157326245752832.htm"
title="《4D卓越团队》习书笔记 第十六章 创造力与投入" target="_blank">《4D卓越团队》习书笔记 第十六章 创造力与投入</a>
<span class="text-muted">Smiledmx</span>
<div>《4D卓越团队-美国宇航局的管理法则》(查理·佩勒林)习书笔记第十六章创造力与投入本章要点:务实的乐观不是盲目乐观,而是带来希望的乐观。用真相激起希望吉姆·科林斯在《从优秀到卓越》中写道:“面对残酷的现实,平庸的公司选择解释和逃避,而不是正视。”创造你想要的项目1.你必须从基于真相的事实出发。正视真相很难,逃避是人类的本性。2.面对现实,你想创造什么?-我想利用现有资源创造一支精干、高效、积极的橙</div>
</li>
<li><a href="/article/1950151583857700864.htm"
title="2020-12-10" target="_blank">2020-12-10</a>
<span class="text-muted">生活有鱼_727f</span>
<div>今日汇总:1.学习了一只舞蹈2.专业知识抄了一遍3.讲师训作业完成今日不足之处:1.时间没管理好,浪费了很多时间到现在才做完明日必做:1.讲师训作业完成2.群消息做好笔记3.宽带安装</div>
</li>
<li><a href="/article/1950147339964444672.htm"
title="【Druid】学习笔记" target="_blank">【Druid】学习笔记</a>
<span class="text-muted">fixAllenSun</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a>
<div>【Druid】学习笔记【一】简介【1】简介【2】数据库连接池(1)能解决的问题(2)使用数据库连接池的好处【3】监控(1)监控信息采集的StatFilter(2)监控不影响性能(3)SQL参数化合并监控(4)执行次数、返回行数、更新行数和并发监控(5)慢查监控(6)Exception监控(7)区间分布(8)内置监控DEMO【4】Druid基本配置参数介绍【5】Druid相比于其他数据库连接池的优点</div>
</li>
<li><a href="/article/1950144473719697408.htm"
title="微信公众号写作:如何通过文字变现?" target="_blank">微信公众号写作:如何通过文字变现?</a>
<span class="text-muted">氧惠爱高省</span>
<div>微信公众号已成为许多人分享知识、表达观点的重要平台。随着自媒体的发展,越来越多的人开始关注微信公众号上写文章如何挣钱的问题。本文将详细探讨微信公众号写作的盈利模式,帮助广大写作者实现文字变现的梦想。公众号流量主就找善士导师(shanshi2024)公众号:「善士笔记」主理人,《我的亲身经历,四个月公众号流量主从0到日入过万!》公司旗下管理800+公众号矩阵账号。代表案例如:爸妈领域、职场道道、国学</div>
</li>
<li><a href="/article/1950143071731642368.htm"
title="流利说懂你英语笔记要点句型·核心课·Level 8·Unit 3·Part 2·Video 1·Healing Architecture 1" target="_blank">流利说懂你英语笔记要点句型·核心课·Level 8·Unit 3·Part 2·Video 1·Healing Architecture 1</a>
<span class="text-muted">羲之大鹅video</span>
<div>HealingArchitecture1EveryweekendforaslongasIcanremember,myfatherwouldgetuponaSaturday,putonawornsweatshirtandhe'dscrapeawayatthesqueakyoldwheelofahousethatwelivedin.ps:从我记事起,每个周末,我父亲都会在周六起床,穿上一件破旧的运动衫</div>
</li>
<li><a href="/article/1950142042847899648.htm"
title="java学习笔记8" target="_blank">java学习笔记8</a>
<span class="text-muted">幸福,你等等我</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>一、异常处理Error:错误,程序员无法处理,如OOM内存溢出错误、内存泄漏...会导出程序崩溃1.异常:程序中一些程序自身处理不了的特殊情况2.异常类Exception3.异常的分类:(1).检查型异常(编译异常):在编译时就会抛出的异常(代码上会报错),需要在代码中编写处理方式(和程序之外的资源访问)直接继承Exception(2).运行时异常:在代码运行阶段可能会出现的异常,可以不用明文处理</div>
</li>
<li><a href="/article/1950141538352820224.htm"
title="2025.07 Java入门笔记01" target="_blank">2025.07 Java入门笔记01</a>
<span class="text-muted">殷浩焕</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a>
<div>一、熟悉IDEA和Java语法(一)LiuCourseJavaOOP1.一直在用C++开发,python也用了些,Java是真的不熟,用什么IDE还是问的同事;2.一开始安装了jdk-23,拿VSCode当编辑器,在cmd窗口编译运行,也能玩;但是想正儿八经搞项目开发,还是需要IDE;3.安装了IDEA社区版:(1)IDE通常自带对应编程语言的安装包,例如IDEA自带jbr-21(和jdk是不同的</div>
</li>
<li><a href="/article/1950140148146565120.htm"
title="Java注解笔记" target="_blank">Java注解笔记</a>
<span class="text-muted">m0_65470938</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>一、什么是注解Java注解又称Java标注,是在JDK5时引入的新特性,注解(也被称为元数据)Javaa注解它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程元素类、方法、成员变量等)进行关联二、注解的应用1.生成文档这是最常见的,也是iava最早提供的注解2.在编译时进行格式检查,如@Overide放在方法前,如果你这个方法并不是看盖了超类Q方法,则编译时就能检查</div>
</li>
<li><a href="/article/1950139769560297472.htm"
title="Java 笔记 transient 用法" target="_blank">Java 笔记 transient 用法</a>
<span class="text-muted"></span>
<div>transient关键字用于标记不希望被序列化(Serialization)的字段。序列化是指将对象的状态保存到字节流中,以便将其传输或存储。当使用如ObjectOutputStream进行序列化时,transient修饰的字段将不会被序列化。✅1.使用场景避免序列化敏感信息privatetransientStringpassword;某些字段不需要持久化(如缓存、临时数据)privatetran</div>
</li>
<li><a href="/article/1950139768872431616.htm"
title="Java 笔记 lambda" target="_blank">Java 笔记 lambda</a>
<span class="text-muted">五行缺弦</span>
<a class="tag" taget="_blank" href="/search/Java%E7%AC%94%E8%AE%B0/1.htm">Java笔记</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a>
<div>✅Lambda基本语法(parameters)->expression或(parameters)->{statements}//无参数Runnabler=()->System.out.println("Hello");//单个参数(小括号可省略)Consumerc=s->System.out.println(s);//多参数+多语句Comparatorcomp=(a,b)->{System.out</div>
</li>
<li><a href="/article/1950135315482079232.htm"
title="【208】《班级管理课》读书感悟(一百零五)2023-07-23" target="_blank">【208】《班级管理课》读书感悟(一百零五)2023-07-23</a>
<span class="text-muted">南风如我意</span>
<div>-----------《班级管理课》读书感悟四文/李现风2023年读书笔记读书笔记以以下三个出发点为目的:一、书中的思想,提升自己的教育理念;二、书中的值得借鉴的做法,提升自己的教育技巧;三、书中的美句,有鉴于哲理性的句子,提升自己文章的语言魅力和教育文化水准。读《班级管理课》作者陈宇读书感悟四:【书目】《班级管理课》【页数】第70页第87页【阅读内容(摘录)】第四课开学一个月:班级常规工作正常运</div>
</li>
<li><a href="/article/1950125273672380416.htm"
title="3步搞定群晖NAS Synology Drive远程同步Obsidian笔记" target="_blank">3步搞定群晖NAS Synology Drive远程同步Obsidian笔记</a>
<span class="text-muted"></span>
<div>文章目录1.简介1.1软件特色演示:2.使用免费群晖虚拟机搭建群晖SynologyDrive服务,实现局域网同步2.1安装并设置SynologyDrive套件2.1局域网内同步文件测试3.内网穿透群晖SynologyDrive,实现异地多端同步3.1安装Cpolar步骤4.实现固定TCP地址同步1.简介之前我们介绍过如何免费多端同步Zotero科研文献管理软件,使用了群晖NAS虚拟机和WebDav</div>
</li>
<li><a href="/article/1950122432392130560.htm"
title="R语言笔记Day1(排序、筛选以及分类汇总))" target="_blank">R语言笔记Day1(排序、筛选以及分类汇总))</a>
<span class="text-muted">养猪场小老板</span>
<div>一、排序1、单变量序列排序2、数据表(矩阵)排序二、筛选三、分类汇总一、排序1、单变量序列排序rank、sort和order函数>aa[1]315#rank用来计算序列中每个元素的秩#这里的“秩”可以理解为该元素在序列中由小到大排列的次序#上面例子给出的序列[3,1,5]中,1最小,5最大,3居中#于是1的秩为1,3的秩为2,5的秩为3,(3,1,5)对应的秩的结果就是(2,1,3)>rank(a</div>
</li>
<li><a href="/article/105.htm"
title="Js函数返回值" target="_blank">Js函数返回值</a>
<span class="text-muted">_wy_</span>
<a class="tag" taget="_blank" href="/search/js/1.htm">js</a><a class="tag" taget="_blank" href="/search/return/1.htm">return</a>
<div>一、返回控制与函数结果,语法为:return 表达式;作用: 结束函数执行,返回调用函数,而且把表达式的值作为函数的结果 二、返回控制语法为:return;作用: 结束函数执行,返回调用函数,而且把undefined作为函数的结果 在大多数情况下,为事件处理函数返回false,可以防止默认的事件行为.例如,默认情况下点击一个<a>元素,页面会跳转到该元素href属性</div>
</li>
<li><a href="/article/232.htm"
title="MySQL 的 char 与 varchar" target="_blank">MySQL 的 char 与 varchar</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>
今天发现,create table 时,MySQL 4.1有时会把 char 自动转换成 varchar
测试举例:
CREATE TABLE `varcharLessThan4` (
`lastName` varchar(3)
) ;
mysql> desc varcharLessThan4;
+----------+---------+------+-</div>
</li>
<li><a href="/article/359.htm"
title="Quartz——TriggerListener和JobListener" target="_blank">Quartz——TriggerListener和JobListener</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/TriggerListener/1.htm">TriggerListener</a><a class="tag" taget="_blank" href="/search/JobListener/1.htm">JobListener</a><a class="tag" taget="_blank" href="/search/quartz/1.htm">quartz</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2208624 一.概述
listener是一个监听器对象,用于监听scheduler中发生的事件,然后执行相应的操作;你可能已经猜到了,TriggerListeners接受与trigger相关的事件,JobListeners接受与jobs相关的事件。
二.JobListener监听器
j</div>
</li>
<li><a href="/article/486.htm"
title="oracle层次查询" target="_blank">oracle层次查询</a>
<span class="text-muted">18289753290</span>
<a class="tag" taget="_blank" href="/search/oracle%EF%BC%9B%E5%B1%82%E6%AC%A1%E6%9F%A5%E8%AF%A2%EF%BC%9B%E6%A0%91%E6%9F%A5%E8%AF%A2/1.htm">oracle;层次查询;树查询</a>
<div>.oracle层次查询(connect by)
oracle的emp表中包含了一列mgr指出谁是雇员的经理,由于经理也是雇员,所以经理的信息也存储在emp表中。这样emp表就是一个自引用表,表中的mgr列是一个自引用列,它指向emp表中的empno列,mgr表示一个员工的管理者,
select empno,mgr,ename,sal from e</div>
</li>
<li><a href="/article/613.htm"
title="通过反射把map中的属性赋值到实体类bean对象中" target="_blank">通过反射把map中的属性赋值到实体类bean对象中</a>
<span class="text-muted">酷的飞上天空</span>
<a class="tag" taget="_blank" href="/search/javaee/1.htm">javaee</a><a class="tag" taget="_blank" href="/search/%E6%B3%9B%E5%9E%8B/1.htm">泛型</a><a class="tag" taget="_blank" href="/search/%E7%B1%BB%E5%9E%8B%E8%BD%AC%E6%8D%A2/1.htm">类型转换</a>
<div>使用过struts2后感觉最方便的就是这个框架能自动把表单的参数赋值到action里面的对象中
但现在主要使用Spring框架的MVC,虽然也有@ModelAttribute可以使用但是明显感觉不方便。
好吧,那就自己再造一个轮子吧。
原理都知道,就是利用反射进行字段的赋值,下面贴代码
主要类如下:
import java.lang.reflect.Field;
imp</div>
</li>
<li><a href="/article/740.htm"
title="SAP HANA数据存储:传统硬盘的瓶颈问题" target="_blank">SAP HANA数据存储:传统硬盘的瓶颈问题</a>
<span class="text-muted">蓝儿唯美</span>
<a class="tag" taget="_blank" href="/search/HANA/1.htm">HANA</a>
<div>SAPHANA平台有各种各样的应用场景,这也意味着客户的实施方法有许多种选择,关键是如何挑选最适合他们需求的实施方案。
在 《Implementing SAP HANA》这本书中,介绍了SAP平台在现实场景中的运作原理,并给出了实施建议和成功案例供参考。本系列文章节选自《Implementing SAP HANA》,介绍了行存储和列存储的各自特点,以及SAP HANA的数据存储方式如何提升空间压</div>
</li>
<li><a href="/article/867.htm"
title="Java Socket 多线程实现文件传输" target="_blank">Java Socket 多线程实现文件传输</a>
<span class="text-muted">随便小屋</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/socket/1.htm">socket</a>
<div> 高级操作系统作业,让用Socket实现文件传输,有些代码也是在网上找的,写的不好,如果大家能用就用上。
客户端类:
package edu.logic.client;
import java.io.BufferedInputStream;
import java.io.Buffered</div>
</li>
<li><a href="/article/994.htm"
title="java初学者路径" target="_blank">java初学者路径</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>学习Java有没有什么捷径?要想学好Java,首先要知道Java的大致分类。自从Sun推出Java以来,就力图使之无所不包,所以Java发展到现在,按应用来分主要分为三大块:J2SE,J2ME和J2EE,这也就是Sun ONE(Open Net Environment)体系。J2SE就是Java2的标准版,主要用于桌面应用软件的编程;J2ME主要应用于嵌入是系统开发,如手机和PDA的编程;J2EE</div>
</li>
<li><a href="/article/1121.htm"
title="APP推广" target="_blank">APP推广</a>
<span class="text-muted">aoyouzi</span>
<a class="tag" taget="_blank" href="/search/APP/1.htm">APP</a><a class="tag" taget="_blank" href="/search/%E6%8E%A8%E5%B9%BF/1.htm">推广</a>
<div>一,免费篇
1,APP推荐类网站自主推荐
最美应用、酷安网、DEMO8、木蚂蚁发现频道等,如果产品独特新颖,还能获取最美应用的评测推荐。PS:推荐简单。只要产品有趣好玩,用户会自主分享传播。例如足迹APP在最美应用推荐一次,几天用户暴增将服务器击垮。
2,各大应用商店首发合作
老实盯着排期,多给应用市场官方负责人献殷勤。
3,论坛贴吧推广
百度知道,百度贴吧,猫扑论坛,天涯社区,豆瓣(</div>
</li>
<li><a href="/article/1248.htm"
title="JSP转发与重定向" target="_blank">JSP转发与重定向</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a><a class="tag" taget="_blank" href="/search/Java+Web/1.htm">Java Web</a><a class="tag" taget="_blank" href="/search/jsp%E8%BD%AC%E5%8F%91/1.htm">jsp转发</a>
<div>
在servlet和jsp中我们经常需要请求,这时就需要用到转发和重定向;
转发包括;forward和include
例子;forwrad转发; 将请求装法给reg.html页面
关键代码;
req.getRequestDispatcher("reg.html</div>
</li>
<li><a href="/article/1375.htm"
title="web.xml之jsp-config" target="_blank">web.xml之jsp-config</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/web.xml/1.htm">web.xml</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a><a class="tag" taget="_blank" href="/search/jsp-config/1.htm">jsp-config</a>
<div>1.作用:主要用于设定JSP页面的相关配置。
2.常见定义:
<jsp-config>
<taglib>
<taglib-uri>URI(定义TLD文件的URI,JSP页面的tablib命令可以经由此URI获取到TLD文件)</tablib-uri>
<taglib-location>
TLD文件所在的位置
</div>
</li>
<li><a href="/article/1502.htm"
title="JSF2.2 ViewScoped Using CDI" target="_blank">JSF2.2 ViewScoped Using CDI</a>
<span class="text-muted">sunjing</span>
<a class="tag" taget="_blank" href="/search/CDI/1.htm">CDI</a><a class="tag" taget="_blank" href="/search/JSF+2.2/1.htm">JSF 2.2</a><a class="tag" taget="_blank" href="/search/ViewScoped/1.htm">ViewScoped</a>
<div>JSF 2.0 introduced annotation @ViewScoped; A bean annotated with this scope maintained its state as long as the user stays on the same view(reloads or navigation - no intervening views). One problem w</div>
</li>
<li><a href="/article/1629.htm"
title="【分布式数据一致性二】Zookeeper数据读写一致性" target="_blank">【分布式数据一致性二】Zookeeper数据读写一致性</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a>
<div>很多文档说Zookeeper是强一致性保证,事实不然。关于一致性模型请参考http://bit1129.iteye.com/blog/2155336
Zookeeper的数据同步协议
Zookeeper采用称为Quorum Based Protocol的数据同步协议。假如Zookeeper集群有N台Zookeeper服务器(N通常取奇数,3台能够满足数据可靠性同时</div>
</li>
<li><a href="/article/1756.htm"
title="Java开发笔记" target="_blank">Java开发笔记</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/java%E5%BC%80%E5%8F%91/1.htm">java开发</a>
<div>1、Map<key,value>的remove方法只能识别相同类型的key值
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"a");
map.put(2,"b");
map.put(3,"c"</div>
</li>
<li><a href="/article/1883.htm"
title="图片黑色阴影" target="_blank">图片黑色阴影</a>
<span class="text-muted">bozch</span>
<a class="tag" taget="_blank" href="/search/%E5%9B%BE%E7%89%87/1.htm">图片</a>
<div> .event{ padding:0; width:460px; min-width: 460px; border:0px solid #e4e4e4; height: 350px; min-heig</div>
</li>
<li><a href="/article/2010.htm"
title="编程之美-饮料供货-动态规划" target="_blank">编程之美-饮料供货-动态规划</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92/1.htm">动态规划</a>
<div>
import java.util.Arrays;
import java.util.Random;
public class BeverageSupply {
/**
* 编程之美 饮料供货
* 设Opt(V’,i)表示从i到n-1种饮料中,总容量为V’的方案中,满意度之和的最大值。
* 那么递归式就应该是:Opt(V’,i)=max{ k * Hi+Op</div>
</li>
<li><a href="/article/2137.htm"
title="ajax大参数(大数据)提交性能分析" target="_blank">ajax大参数(大数据)提交性能分析</a>
<span class="text-muted">chenbowen00</span>
<a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a><a class="tag" taget="_blank" href="/search/%E6%A1%86%E6%9E%B6/1.htm">框架</a><a class="tag" taget="_blank" href="/search/%E6%B5%8F%E8%A7%88%E5%99%A8/1.htm">浏览器</a><a class="tag" taget="_blank" href="/search/prototype/1.htm">prototype</a>
<div>近期在项目中发现如下一个问题
项目中有个提交现场事件的功能,该功能主要是在web客户端保存现场数据(主要有截屏,终端日志等信息)然后提交到服务器上方便我们分析定位问题。客户在使用该功能的过程中反应点击提交后反应很慢,大概要等10到20秒的时间浏览器才能操作,期间页面不响应事件。
根据客户描述分析了下的代码流程,很简单,主要通过OCX控件截屏,在将前端的日志等文件使用OCX控件打包,在将之转换为</div>
</li>
<li><a href="/article/2264.htm"
title="[宇宙与天文]在太空采矿,在太空建造" target="_blank">[宇宙与天文]在太空采矿,在太空建造</a>
<span class="text-muted">comsci</span>
<div> 我们在太空进行工业活动...但是不太可能把太空工业产品又运回到地面上进行加工,而一般是在哪里开采,就在哪里加工,太空的微重力环境,可能会使我们的工业产品的制造尺度非常巨大....
地球上制造的最大工业机器是超级油轮和航空母舰,再大些就会遇到困难了,但是在空间船坞中,制造的最大工业机器,可能就没</div>
</li>
<li><a href="/article/2391.htm"
title="ORACLE中CONSTRAINT的四对属性" target="_blank">ORACLE中CONSTRAINT的四对属性</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/CONSTRAINT/1.htm">CONSTRAINT</a>
<div>ORACLE中CONSTRAINT的四对属性
summary:在data migrate时,某些表的约束总是困扰着我们,让我们的migratet举步维艰,如何利用约束本身的属性来处理这些问题呢?本文详细介绍了约束的四对属性: Deferrable/not deferrable, Deferred/immediate, enalbe/disable, validate/novalidate,以及如</div>
</li>
<li><a href="/article/2518.htm"
title="Gradle入门教程" target="_blank">Gradle入门教程</a>
<span class="text-muted">dengkane</span>
<a class="tag" taget="_blank" href="/search/gradle/1.htm">gradle</a>
<div>一、寻找gradle的历程
一开始的时候,我们只有一个工程,所有要用到的jar包都放到工程目录下面,时间长了,工程越来越大,使用到的jar包也越来越多,难以理解jar之间的依赖关系。再后来我们把旧的工程拆分到不同的工程里,靠ide来管理工程之间的依赖关系,各工程下的jar包依赖是杂乱的。一段时间后,我们发现用ide来管理项程很不方便,比如不方便脱离ide自动构建,于是我们写自己的ant脚本。再后</div>
</li>
<li><a href="/article/2645.htm"
title="C语言简单循环示例" target="_blank">C语言简单循环示例</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a>
<div># include <stdio.h>
int main(void)
{
int i;
int count = 0;
int sum = 0;
float avg;
for (i=1; i<=100; i++)
{
if (i%2==0)
{
count++;
sum += i;
}
}
avg</div>
</li>
<li><a href="/article/2772.htm"
title="presentModalViewController 的动画效果" target="_blank">presentModalViewController 的动画效果</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/controller/1.htm">controller</a>
<div>系统自带(四种效果):
presentModalViewController模态的动画效果设置:
[cpp]
view plain
copy
UIViewController *detailViewController = [[UIViewController al</div>
</li>
<li><a href="/article/2899.htm"
title="java 二分查找" target="_blank">java 二分查找</a>
<span class="text-muted">shuizhaosi888</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE/1.htm">二分查找</a><a class="tag" taget="_blank" href="/search/java%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE/1.htm">java二分查找</a>
<div>需求:在排好顺序的一串数字中,找到数字T
一般解法:从左到右扫描数据,其运行花费线性时间O(N)。然而这个算法并没有用到该表已经排序的事实。
/**
*
* @param array
* 顺序数组
* @param t
* 要查找对象
* @return
*/
public stati</div>
</li>
<li><a href="/article/3026.htm"
title="Spring Security(07)——缓存UserDetails" target="_blank">Spring Security(07)——缓存UserDetails</a>
<span class="text-muted">234390216</span>
<a class="tag" taget="_blank" href="/search/ehcache/1.htm">ehcache</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/Spring+Security/1.htm">Spring Security</a>
<div>
Spring Security提供了一个实现了可以缓存UserDetails的UserDetailsService实现类,CachingUserDetailsService。该类的构造接收一个用于真正加载UserDetails的UserDetailsService实现类。当需要加载UserDetails时,其首先会从缓存中获取,如果缓存中没</div>
</li>
<li><a href="/article/3153.htm"
title="Dozer 深层次复制" target="_blank">Dozer 深层次复制</a>
<span class="text-muted">jayluns</span>
<a class="tag" taget="_blank" href="/search/VO/1.htm">VO</a><a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a><a class="tag" taget="_blank" href="/search/po/1.htm">po</a>
<div>最近在做项目上遇到了一些小问题,因为架构在做设计的时候web前段展示用到了vo层,而在后台进行与数据库层操作的时候用到的是Po层。这样在业务层返回vo到控制层,每一次都需要从po-->转化到vo层,用到BeanUtils.copyProperties(source, target)只能复制简单的属性,因为实体类都配置了hibernate那些关联关系,所以它满足不了现在的需求,但后发现还有个很</div>
</li>
<li><a href="/article/3280.htm"
title="CSS规范整理(摘自懒人图库)" target="_blank">CSS规范整理(摘自懒人图库)</a>
<span class="text-muted">a409435341</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/UI/1.htm">UI</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E6%B5%8F%E8%A7%88%E5%99%A8/1.htm">浏览器</a>
<div> 刚没事闲着在网上瞎逛,找了一篇CSS规范整理,粗略看了一下后还蛮有一定的道理,并自问是否有这样的规范,这也是初入前端开发的人一个很好的规范吧。
一、文件规范
1、文件均归档至约定的目录中。
具体要求通过豆瓣的CSS规范进行讲解:
所有的CSS分为两大类:通用类和业务类。通用的CSS文件,放在如下目录中:
基本样式库 /css/core
</div>
</li>
<li><a href="/article/3407.htm"
title="C++动态链接库创建与使用" target="_blank">C++动态链接库创建与使用</a>
<span class="text-muted">你不认识的休道人</span>
<a class="tag" taget="_blank" href="/search/C%2B%2B/1.htm">C++</a><a class="tag" taget="_blank" href="/search/dll/1.htm">dll</a>
<div>一、创建动态链接库
1.新建工程test中选择”MFC [dll]”dll类型选择第二项"Regular DLL With MFC shared linked",完成
2.在test.h中添加
extern “C” 返回类型 _declspec(dllexport)函数名(参数列表);
3.在test.cpp中最后写
extern “C” 返回类型 _decls</div>
</li>
<li><a href="/article/3534.htm"
title="Android代码混淆之ProGuard" target="_blank">Android代码混淆之ProGuard</a>
<span class="text-muted">rensanning</span>
<a class="tag" taget="_blank" href="/search/ProGuard/1.htm">ProGuard</a>
<div>Android应用的Java代码,通过反编译apk文件(dex2jar、apktool)很容易得到源代码,所以在release版本的apk中一定要混淆一下一些关键的Java源码。
ProGuard是一个开源的Java代码混淆器(obfuscation)。ADT r8开始它被默认集成到了Android SDK中。
官网:
http://proguard.sourceforge.net/</div>
</li>
<li><a href="/article/3661.htm"
title="程序员在编程中遇到的奇葩弱智问题" target="_blank">程序员在编程中遇到的奇葩弱智问题</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/jquery/1.htm">jquery</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/ide/1.htm">ide</a>
<div> 现在收集一下:
排名不分先后,按照发言顺序来的。
1、Jquery插件一个通用函数一直报错,尤其是很明显是存在的函数,很有可能就是你没有引入jquery。。。或者版本不对
2、调试半天没变化:不在同一个文件中调试。这个很可怕,我们很多时候会备份好几个项目,改完发现改错了。有个群友说的好: 在汤匙</div>
</li>
<li><a href="/article/3788.htm"
title="解决maven-dependency-plugin (goals "copy-dependencies","unpack") is not supported" target="_blank">解决maven-dependency-plugin (goals "copy-dependencies","unpack") is not supported</a>
<span class="text-muted">xp9802</span>
<a class="tag" taget="_blank" href="/search/dependency/1.htm">dependency</a>
<div>解决办法:在plugins之前添加如下pluginManagement,二者前后顺序如下:
[html]
view plain
copy
<build>
<pluginManagement</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>