CogView:通过Transformers完成文本到图像的生成
1 Title
CogView: Mastering Text-to-Image Generation via Transformers(Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhouz, Da Yin,Junyang Linz, Xu Zou, Zhou Shao, Hongxia Yang, Jie Tang)
2 Conclusion
This study proposes CogView, a 4-billion-parameter Transformer with VQ-VAE tokenizer to advance this problem. We also demonstrate the finetuning strategies for various downstream tasks, e.g. style learning, super-resolution, text-image ranking and fashion design, and methods to stabilize pretraining, e.g. eliminating NaN losses.
3 Good Sentences
1.Among various pretext tasks, text-to-image generation expects the model to (1) disentangle shape, color, gesture and other features from pixels, (2) understand the input text, (2) align objects and features with corresponding words and their synonyms and (4) learn complex distributions to generate the overlapping and composite of different objects and features, which, like painting, is beyond basic visual functions requiring a higher-level cognitive ability.(The Ideal process of the text to image mission)
2.The idea of CogView comes naturally: large-scale generative joint pretraining for both text and image(from VQ-VAE) tokens. (Why try to proposed CogView)
3.Currently, pretraining large models (>2B parameters) usually relies on 16-bit precision to save GPU memory and speed up the computation. Many frameworks, e.g. DeepSpeed ZeRO [40], even only support FP16 parameters. However, text-to-image pretraining is very unstable under 16-bit precision. Training a 4B ordinary pre-LN Transformer will quickly result in NaN loss within 1,000 iterations. There are two kinds of instability: overflow (characterized by NaN losses) and underflow (characterized by diverging loss). The following techniques are proposed to solve them.(The stabilization of training problems and how to solve)
本文并预训练了一个具有40亿个参数的Transformer,并且提出Precision Bottleneck Relaxation和Sandwich Layernorm解决了数据异构性导致的不稳定问题,并且本文的transformer是开源的
Tokenization:
image tokenizer是一个离散的自动编码器,类似于VQ-VAE的第一阶段。由于discrete selection,image tokenizer的训练过程是非平凡的,以下是四种不同的image tokenizer的训练方法。
1.The nearest-neighbor mapping, straight-through estimator :VQ-VAE提出的原始方法,当码本很大并且没有仔细初始化时,由于维数灾难,只有少数嵌入会被使用
2.Gumbel sampling, straight-through estimator
3.The nearest-neighbor mapping, moving average:在训练期间周期性地更新码本中的每个嵌入,作为最近映射到它的向量的平均值
4.The nearest-neighbor mapping, fixed codebook:codebook在初始化之后是固定的。
如果初始化正确,码本中嵌入的学习不是很重要。在预训练中,本文使用第三种方法。
Auto-regressive Transformer
CogView的主干是一个单向的Transformer(GPT),Transformer有48层,隐藏大小为2560,40个注意力头,总共40亿个参数。如图3所示,四个分隔符token,[ROI 1](图像的参考文本)、[BASE]、[BOI1](图像开头),[EOI1](图像的结尾)被添加到每个序列中以指示文本和图像的边界。所有序列都被裁剪或填充为1088的长度。
文本建模是文本到图像预训练成功的关键。如果文本token的损失权重设置为零,模型将无法找到文本和图像之间的联系,并生成与输入文本完全无关的图像

本文发现文本到图像预训练在16位精度下非常不稳定,存在两种不稳定性:溢出(以NaN损失为特征)和下溢(以发散损失为特征)。提出了以下技术来解决它:
1、Precision Bottleneck Relaxation (PB-Relax):溢出总是发生在两个瓶颈操作上,即最后的LayerNorm或Attention。
2.Sandwich LayerNorm (Sandwich-LN):pre-LN不足以用于文本到图像的预训练
Post-LN来自原始论文; Pre-LN是目前最流行的结构; Sandwich-LN是我们提出的稳定训练的结构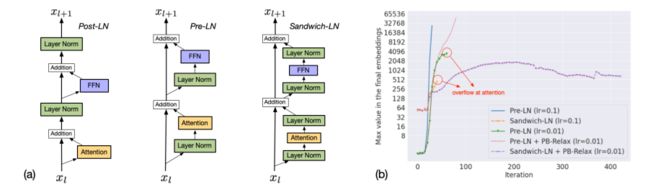
没有Sandwich-LN的训练在主分支中溢出;没有PB-放松的训练在注意力中溢出;只有双方的训练才能继续。