《动手学深度学习(PyTorch版)》笔记6.2
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过,同时对于书上部分章节也做了整合。
Chapter6 Convolutional Neural Network(CNN)
6.2 Image Convolution Operation
6.2.1 Convolutional Layer
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(corr2d(X, K))
class Conv2D(nn.Module):
"""实现二维卷积层"""
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
#卷积层的一个简单应用:检测图像中不同颜色的边缘
X = torch.ones((6, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]])
Y=corr2d(X, K)
print(Y)
print(corr2d(X.t(), K))#卷积核K只可以检测垂直边缘,无法检测水平边缘。
# 构造一个二维卷积层,它具有1个输出通道、1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 使用四维输入和输出格式(批量大小、通道、高度、宽度),其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
print(conv2d.weight.data.reshape((1, 2)))#学习到的卷积核非常接近之前定义的卷积核K
6.2.2 Padding and Stride
6.2.2.1 Padding
在应用多层卷积时,我们常常丢失边缘像素。解决这个问题的简单方法为填充(padding):在输入图像的边界填充元素(通常填充元素是 0 0 0)。例如,在下图中,我们将 3 × 3 3 \times 3 3×3输入填充到 5 × 5 5 \times 5 5×5,那么它的输出就增加为 4 × 4 4 \times 4 4×4。阴影部分是第一个输出元素以及用于输出计算的输入和核张量元素: 0 × 0 + 0 × 1 + 0 × 2 + 0 × 3 = 0. 0\times0+0\times1+0\times2+0\times3=0. 0×0+0×1+0×2+0×3=0.

通常,如果我们添加 p h p_h ph行填充(大约顶部一半,底部一半)和 p w p_w pw列填充(大约左侧一半,右侧一半),则输出形状为 ( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) . (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1). (nh−kh+ph+1)×(nw−kw+pw+1).这意味着输出的高度和宽度将分别增加 p h p_h ph和 p w p_w pw。在许多情况下,我们需要设置 p h = k h − 1 p_h=k_h-1 ph=kh−1和 p w = k w − 1 p_w=k_w-1 pw=kw−1,使输入和输出具有相同的高度和宽度。假设 k h k_h kh是奇数,我们将在上下两侧填充 p h / 2 p_h/2 ph/2行;如果 k h k_h kh是偶数,则一种可能性是在顶部填充 ⌈ p h / 2 ⌉ \lceil p_h/2\rceil ⌈ph/2⌉行,在底部填充 ⌊ p h / 2 ⌋ \lfloor p_h/2\rfloor ⌊ph/2⌋行。填充左右两侧同理。
卷积神经网络中卷积核的高度和宽度通常为奇数,好处是保持空间维度的同时,可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。此外,使用奇数的核大小和填充大小也提供了书写上的便利。对于任何二维张量 X \mathbf{X} X,当满足:1. 卷积核的大小是奇数;2. 所有边的填充行数和列数相同;3. 输出与输入具有相同高度和宽度时,可以得出:输出 Y [ i , j ] \mathbf{Y}[i, j] Y[i,j]是通过以输入 X [ i , j ] \mathbf{X}[i, j] X[i,j]为中心与卷积核进行互相关计算得到的。
6.2.2.2 Stride
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。在前面的例子中,我们默认每次滑动一个元素。但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。我们将每次滑动元素的数量称为步幅(stride)。通常,当垂直步幅为 s h s_h sh、水平步幅为 s w s_w sw时,输出形状为
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ . \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor. ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.
如果设置了 p h = k h − 1 p_h=k_h-1 ph=kh−1和 p w = k w − 1 p_w=k_w-1 pw=kw−1,则输出形状为 ⌊ ( n h + s h − 1 ) / s h ⌋ × ⌊ ( n w + s w − 1 ) / s w ⌋ . \lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor. ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋.更进一步,如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状为 ( n h / s h ) × ( n w / s w ) . (n_h/s_h) \times (n_w/s_w). (nh/sh)×(nw/sw).当输入高度和宽度两侧的填充数量分别为 p h p_h ph和 p w p_w pw时,称之为填充 ( p h , p w ) (p_h, p_w) (ph,pw),当 p h = p w = p p_h = p_w = p ph=pw=p时,称填充为 p p p。同理,当高度和宽度上的步幅分别为 s h s_h sh和 s w s_w sw时,称之为步幅 ( s h , s w ) (s_h, s_w) (sh,sw)。特别地,当 s h = s w = s s_h = s_w = s sh=sw=s时,称步幅为 s s s。默认情况下,填充为0,步幅为1。在实践中,通常有 p h = p w p_h = p_w ph=pw和 s h = s w s_h = s_w sh=sw。
本节代码如下:
import torch
from torch import nn
from d2l import torch as d2l
#以下演示通过调整填充数和卷积核大小来使得输入和输出的宽度高度相同
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)#在前面添加了两个维度,分别表示批量大小和通道数,使其适应卷积层的输入要求
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,总共添加了2行和2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
print(comp_conv2d(conv2d, X).shape)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
print(comp_conv2d(conv2d, X).shape)
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
print(comp_conv2d(conv2d, X).shape)
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
print(comp_conv2d(conv2d, X).shape)
6.2.3 Channels
6.2.3.1 Multiple Input Channels
下图演示了一个具有两个输入通道的二维互相关运算的示例。阴影部分是第一个输出元素以及用于计算这个输出的输入和卷积核元素: ( 1 × 1 + 2 × 2 + 4 × 3 + 5 × 4 ) + ( 0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 ) = 56. (1\times1+2\times2+4\times3+5\times4)+(0\times0+1\times1+3\times2+4\times3)=56. (1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)=56.
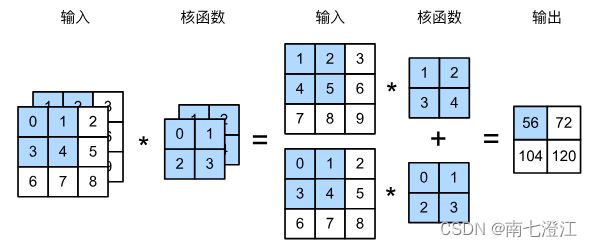
#多输入通道卷积
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
print(corr2d_multi_in(X, K))
6.2.3.2 Multiple Output Channels
用 c i c_i ci和 c o c_o co分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o\times c_i\times k_h\times k_w co×ci×kh×kw。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算,最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)#0是指定的叠加的维度
K = torch.stack((K, K + 1, K + 2), 0)#接收一个包含三个张量的元组,并在第0个维度上叠加它们,构造一个具有3个输出通道的卷积核
print(K.shape)
print(corr2d_multi_in_out(X, K))
6.2.3.3 1 × 1 1\times 1 1×1 Convolutional Layer
1 × 1 1\times 1 1×1卷积的唯一计算发生在通道上。下图展示了使用 1 × 1 1\times 1 1×1卷积核与 3 3 3个输入通道和 2 2 2个输出通道的互相关计算,这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。我们可以将 1 × 1 1\times 1 1×1卷积层看成在每个像素位置应用的全连接层,以 c i c_i ci个输入值转换为 c o c_o co个输出值,同时, 1 × 1 1\times 1 1×1卷积层需要的权重维度为 c o × c i c_o\times c_i co×ci,再额外加上一个偏置。 1 × 1 1\times 1 1×1卷积通过调整通道数、引入非线性映射和促使特征交互,提供了一种灵活而有效的方式来改进网络的性能。

#使用全连接层实现1×1卷积
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6#此时两者效果相同
6.2.4 Pooling
机器学习任务通常跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
此外,当检测较底层的特征(如边缘)时,我们通常希望这些特征保持某种程度上的平移不变性。例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[i, j + 1],则新图像Z的输出可能大不相同。而在现实中,随着拍摄角度的移动,任何物体几乎不可能一直出现在在同一像素上。汇聚(pooling)具有双重作用:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性(也就是降低空间分辨率的同时尽量保留更多空间信息,避免过度丢失有用的局部特征)。
与卷积层类似,汇聚层运算符由一个固定形状的汇聚窗口组成,该窗口根据其步幅大小在输入区域上滑动,为遍历的每个位置计算一个输出。汇聚窗口形状为 p × q p \times q p×q的汇聚层称为 p × q p \times q p×q汇聚层,相应的汇聚操作称为 p × q p \times q p×q汇聚。然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层汇聚运算是确定性的,不包含参数。我们通常计算汇聚窗口中所有元素的最大值或平均值,分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
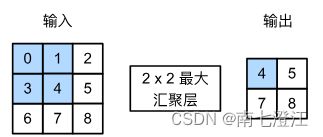
def pool2d(X, pool_size, mode='max'):
"""实现汇聚层"""
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
print(pool2d(X, (2, 2)))
print(pool2d(X, (2, 2), 'avg'))
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
pool2d = nn.MaxPool2d(3)
#步幅与汇聚窗口的大小默认相同,因此如果使用形状为(3, 3)的汇聚窗口,那么默认步幅为(3, 3)
print(pool2d(X))
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
print(pool2d(X))
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
print(pool2d(X))
#在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总,这意味着汇聚层的输出通道数与输入通道数相同
X = torch.cat((X, X + 1), 1)
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
print(pool2d(X))