基于GAN-CNN-CNN的鲁棒笔迹识别方法(二)
上一篇文章讲到了HTID_0数据集的建立以及它的缺陷,本节主要内容是模型的架构和新数据集HTID_1的建立.
笔迹识别
有了制作HTID_0的经验,我意识到分类任务并不是最难解决的那部分,因为现在已经有非常多性能优秀的分类网络,重点是传入网络的图片质量,也就是笔迹图像.理想的输入为图片中只有笔迹信息,没有多余的杂质(如横线、印刷体、污渍等).
一些笔迹来源原始材料(来自互联网、IMA数据集[1]、ICDAR2017[2]):









以上图片主要有两个特点:
- 包含比较多的杂质,甚至有些与笔迹重叠了.
- 汉字大部分都是单字存在连笔,多字连笔比较少见;而以字母作为书写对象的语种多存在词连笔甚至句连笔的情况.
对于特点1,对于一些比较简单的情况,如笔迹颜色与杂质颜色存在明显差异,可以通过二值化解决.

但是对于一些复杂的情况,笔迹与背景颜色相似,二值化无法去除这些背景,印刷体和笔迹颜色相近也无法去除.这些对后续的单字切割都产生了不良影响,背景杂质会导致单字定位出现异常,切割后存在较多杂质(关于这点后面会讨论).
对于特点2,国外文献提出的笔迹识别方法几乎都是基于块级(词级、句级、行级等),但这些方法都是针对非汉字的,我认为按现有技术无法准确地分割每一个字母(符),与其卷分割技术,不如针对分类技术进行研究.国内有些针对汉字的笔迹识别研究也是块级的,但我认为要利用好单字独立存在这个特性.本文主要研究是基于字级的汉字笔迹识别,提取单字笔迹后,进行白边切割,重心-中心线性归一化,再把多个单字凑成一张纹理图.把纹理图输入分类网络提高了像素的利用率,同时让网络一次能学习到更多特征.
模型架构
基于以上认识,我把笔迹识别分为三部分:
- 笔迹提取:去除笔迹检材中的杂质(印刷体、线段等与笔迹无关的像素),输出一张只有笔迹的图像,该部分使用EraseNet[3]实现,这是一种基于GAN的模型,用于端到端场景文本删除的神经网络.
- 笔迹切割:输入由上一部分生成的笔迹图像,进行单字定位并切割.该部分使用HRCenterNet[4],该模型结合了无锚对象检测方法和并行架构,文章提到该模型具有最佳的速度与精度,实测使用CPU也能非常快地切割.
- 笔迹识别:上一部分产生了单字笔迹,将单字笔迹拼接成纹理图,输入分类模型进行训练、推理.
第三部分为什么不使用Transformer?训练Transformer要有足够大的数据集,在小数据集上CNN发挥的更好,对于笔迹的数据,每人能获取100个单字已经很不错了.同时训练Transformer的时间普遍较长,需要高性能GPU,也就是Transformer的成本要比CNN大.我的设想是笔迹推理部分能放在低性能设备上完成,让产品落地的成本减少.

下图展示了整个模型的工作流程:
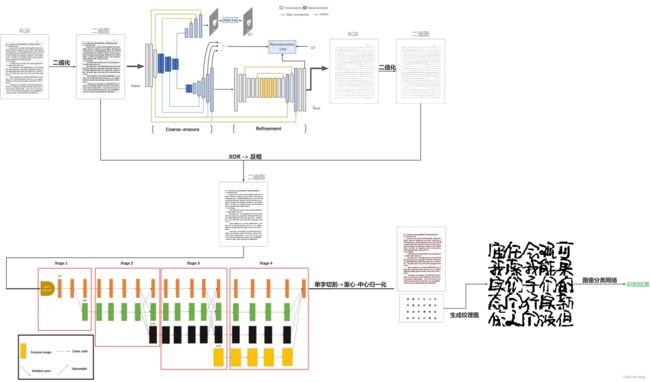
模型的具体细节请查看原论文,这里就不再赘述了.
HTID_1
上一节提出了用于笔迹识别任务的数据集HTID_0,但存在一些缺陷.本节将制作一个较为完善的数据集HTID_1.
下图展示了纹理图制作的全流程(笔迹提取、单字切割、生成纹理图):
笔迹提取部分依靠训练出来的模型,训练模型需要输入两张图像,一张是原始图像,一张是无笔迹图像.由于制作无笔迹图像比较废人,我这里只制作了5对图像,每对图像又随机切割成大小大于512*512的子图像然后进行训练.制作无笔迹图像时我没有针对每一个字仔细擦除,我是使用白色矩形覆盖笔迹的,所以导致模型学习了这种错误的做法,对笔迹底部与横线的相交处没有处理好.

单字切割后,我将每个人的单字笔迹库分为了两部分,总740人,这两部分是互斥的,两部分不存在相同的单字笔迹图像.然后分别用这两部分生成训练集和测试集的纹理图,每张纹理图有5*5个单字,每个单字为32*32像素的二值图,在训练集中每人生成100张纹理图,测试集中每人随机生成100~200张纹理图(总111,601张).训练集和测试集数量比为74000:111601,约为3:5.
在测试集中top1准确率为92%,top5准确率为98%.
对HTID_1进行的实验将在下一节介绍.
参考文献
[1]U. Marti and H. Bunke. The IAM-database: An English Sentence Database for Off-line Handwriting Recognition. Int. Journal on Document Analysis and Recognition, Volume 5, pages 39 - 46, 2002.
[2]“ScriptNet: ICDAR2017 Competition on Historical Document Writer Identification (Historical-WI),” Zenodo, 2017, doi: https://doi.org/10.5281/zenodo.1324999. Available: https://zenodo.org/records/1324999.
[3]C. Liu, Y. Liu, L. Jin, S. Zhang, C. Luo and Y. Wang, "EraseNet: End-to-End Text Removal in the Wild," in IEEE Transactions on Image Processing, vol. 29, pp. 8760-8775, 2020, doi: 10.1109/TIP.2020.3018859.
[4]C.-W. Tang, C.-L. Liu, and P.-S. Chiu, “HRCenterNet: An Anchorless Approach to Chinese Character Segmentation in Historical Documents,” arXiv (Cornell University), Dec. 2020, doi: https://doi.org/10.1109/bigdata50022.2020.9378051. Available: https://arxiv.org/abs/2012.05739.