win爬取网址获取宵宫语音,使用python的selenium库来模拟点击
前言:经过大量的收集资料,发现因为seleuninm的更新,所有的教程都各不相同,因此自己花了半天时间学习了完整的一个爬取过程,并分享一个用Chrome爬取的示例。
一、环境准备
python>=3.6都没有问题,我使用的是python3.9
官方下载:Download Python | Python.org
二、库安装
1、安装selenium
pip install selenium2、安装浏览器模拟webdriver(谷歌插件需要科学上网)
Firefox:https://github.com/mozilla/geckodriver/releases/
Chrome:https://sites.google.com/a/chromium.org/chromedriver/
三、运行模拟浏览器部分
1、启动浏览器
# 实例化一款浏览器
from selenium import webdriver
driver = webdriver.Chrome()2、向某地址发送请求
这里例如获取原神宵宫的语音
# 对指定的url发起请求
driver.get('https://www.voistock.com/ja/playlist/detail.php?pk=BZUFGBJNR')
到这一步,我们已经可以模拟登录浏览器的操作,下一步就是寻找文件获取
四、获取文件
1、获取文件名称
(1)在浏览器中打开页面,按f12或者右击-检查,审查元素。
(2)点击左上角的小图标,再单击文件名,就可以定位名字的位置

(3)在元素中右击-复制-复制Xpath路径,可以得到该名字的Xpath路径
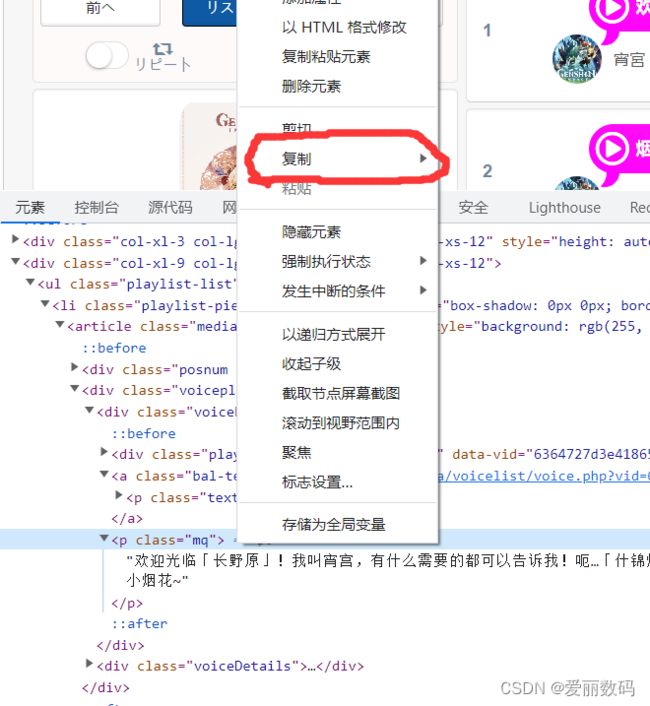
/html/body/div[1]/div/div[4]/div/div[2]/ul/li[1]/article/div[2]/div[1]/p(4)模拟浏览器中,通过Xpath获取文件名
# 获取元素,带.text获取纯文本
name =driver.find_element(
By.XPATH,'/html/body/div[1]/div/div[4]/div/div[2]/ul/li[1]/article/div[2]/div[1]/p'
).text注:如果这里报错 DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
那么因为你用了如下旧的写法,这种写法在新版本已经启用,如果使用这个方法请退selenium的版本
# 旧方法 name =driver.find_element_by_xpath,'/html/body/div[1]/div/div[4]/div/div[2]/ul/li[1]/article/div[2]/div[1]/p').text如果报错 NameError: name 'By' is not defined
那记得导入by
from selenium.webdriver.common.by import By(5)多名字的获取
我们不可能一个一个获取全部的xpath(那还不如手动保存),这里写一个for函数就可以
# 这里为音频的数量,建议取个很大的值,以便全覆盖 for n in range(1,223): # .format来替换str的内容 name =driver.find_element( By.XPATH,'/html/body/div[1]/div/div[4]/div/div[2]/ul/li[{}]/article/div[2]/div[1]/p'.format(n) ).text这样每一次循环里,都能获取一次对应的名字,接下来就该获取文件了
2、获取音频
此前我尝试过使用requests.get或post来获取,但都返回了一个错误的json,检查发现adiuo元素里有preload="none",音频文件必须要点击后才能加载,这样就没办法直接获取音频,因此我选择了使用selenium库来模拟点击来获取文件。
同上定位语音点击按钮的xpath(默认在循环里了),定位到链接位置,因为是该元素的src元素,我们使用.get_attribute('src')来获取,这里如果在xpath中是没办法获取的,需要注意。
由于获取到url,我们便可以通过requests.get请求下载文件了
import requests # 点击按钮 driver.find_element( By.XPATH,r'/html/body/div[1]/div/div[4]/div/div[2]/ul/li[{}]/article/div[2]/div[1]/div'.format(n) ).click() # 获取音频url url = driver.find_element( By.XPATH,"/html/body/div[1]/div/div[4]/div/div[2]/ul/li[{}]/article/div[2]/div[1]/div/span/audio".format(n) ).get_attribute("src") # 下载音频并命名 data = requests.get(url).content with open(file,'wb') as fp: fp.write(data) print(name,'下载成功')
五、模拟其他的帮助操作
爬取总是会遇到各种问题或者需要优化的地方
1、名字出现空值
原因:要不然就是xpath路径错误,重新检查一下是否每一个路径都是如此,要不然就是网络过慢,还没有获取成功就开始下载命名,我们可以通过隐性等待来解决,下示例效果是如果没有加载完成,最多等待10秒
driver.implicitly_wait(10)2、出现404 not fount
原因:具体不太清楚,但是我在get请求后面加了个头就解决了
hearders={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } data = requests.get(url,headers=hearders).content3、下载位置和名字?
原因:这个非常基础,如果不会建议找其他教程....下面给个我自己的示例
# 我用的绝对路径,确保路径存在 file_name_old = 'E:\音乐\原神\宵宫' # 文件下载路径 file_path_old = os.path.dirname(file_name_old) file = os.path.join(file_path_old,'宵宫',name+'.mp3')4、如何跳过已经下载的文件?
原因:使用os判断即可
# file为路径+名字,在for循环里 if os.path.exists(file)==True: print(name+'已存在') continue
六、写个启动脚本
不双击启动怎么是好脚本呢()
假设py文件名为test.py,新建一个txt文件,双击写入
python test.py保存退出,重命名后缀为.bat(名字随便)
双击启动
参考文章:
1、Python+Selenium基础入门及实践 - 简书
2、Xpath简明教程(十分钟入门)
3、find_element_by_xpath()被弃用解决方案_异想实验室的博客-CSDN博客_find_element_by_xpath
4、Selenium等待时间——隐性等待(implicitly_wait())_@林夕的博客-CSDN博客_implicitly_wait()
5、Python continue 语句 | 菜鸟教程