锦上添花!特征选择+深度学习:mRMR-CNN-BiGRU-Attention故障识别模型!特征按重要性排序!最大相关最小冗余!
适用平台:Matlab2023版及以上
特征选择方法:"最大相关最小冗余"(Maximal Relevance and Minimal Redundancy,简称MRMR)是一种用于特征选择的方法。该方法旨在找到最相关的特征集,同时最小化特征之间的冗余,以提高模型的性能和泛化能力。我们将该特征选择方法应用于CNN-BiGRU-Attention故障识别模型上,构建的mRMR-CNN-BiGRU-Attention故障识别模型目前还没人写哦。

在具体的数学表达上,最大相关最小冗余方法通常通过优化某个相关性度量和冗余度量的组合来实现。最常用的相关性度量是皮尔逊相关系数,而冗余度量通常使用互信息或方差。通过调整特征子集中每个特征的权重,可以实现最大化相关性和最小化冗余。

这个方法的优势在于它不仅关注特征与目标变量的关系,还考虑了特征之间的相互关系,以避免选择高度相关的特征,从而减少模型的过拟合风险,增强模型的可解释性。
用mRMR选择5个最重要的特征作为RMR-CNN-BiGRU-Attention故障识别模型的输入:

创新点:
-
特征选择优化: mRMR特征选择的方法,通过最大化特征与目标变量的相关性,同时最小化特征之间的冗余,给特征变量的选择提供有效依据,提高模型的可解释性。
-
时序-空间特征结合:CNN通过卷积层可以有效地捕捉输入故障波形中的局部特征,如脉冲、振动或其它突变。而GRU则能够学习序列中的长期依赖关系,捕捉全局特征,提高了对故障波形中复杂特征的提取能力。
-
故障前后特征:BiGRU双向记忆单元对时间序列进行特征提取,捕捉时间上相邻的特征,同时考虑故障前后所包含的特征。
-
多头自注意力机制:自注意力层被嵌入到BiGRU层后,自注意力层用于捕捉故障波形中的全局依赖关系,自注意力机制允许网络在学习时动态地调整各个采样点的权重,以便更好地捕捉长期依赖和全局模式,实现各特征的重点强化。
程序数据集格式:
数据格式:一行为一个故障样本也可以看成一个故障波形,最后一列表示该样本所属的故障类别,即故障类别标签。

程序结果:

模型结构和测试集的混淆矩阵:
精确率是混淆矩阵的最下面一行,召回率是混淆矩阵的最右边一列

-
精确率:指模型在预测为正类别的样本中,实际为正类别的样本所占的比例。它衡量的是模型在正类别的预测中的准确性。
-
召回率:指实际为正类别的样本中,模型成功预测为正类别的样本所占的比例。它衡量的是模型对正类别样本的覆盖能力。
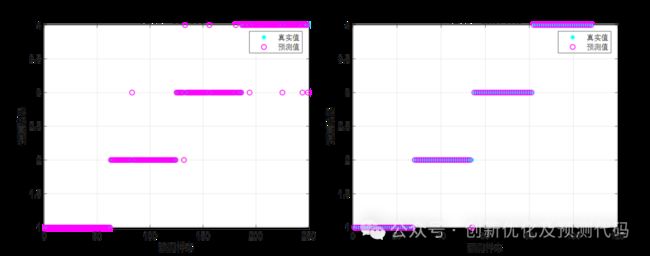
训练集和测试集的散点图:
程序展示准确率、精确率、召回率、F1分数等计算结果:

训练的精确度及损失曲线:

部分代码:
%% 分析数据
num_class = length(unique(res(:, end))); % 类别数(Excel最后一列放类别)
num_dim = size(res, 2) - 1; % 特征维度 公众号:创新优化及预测代码
num_res = size(res, 1); % 样本数(每一行,是一个样本)
num_size = 0.7; % 训练集占数据集的比例
res = res(randperm(num_res), :); % 打乱数据集(不打乱数据时,注释该行)
flag_conusion = 1; % 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1 : num_class
mid_res = res((res(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size * mid_size); % 得到该类别的训练样本个数
P_train = [P_train; mid_res(1: mid_tiran, 1: end - 1)]; % 训练集输入
T_train = [T_train; mid_res(1: mid_tiran, end)]; % 训练集输出
P_test = [P_test; mid_res(mid_tiran + 1: end, 1: end - 1)]; % 测试集输入
T_test = [T_test; mid_res(mid_tiran + 1: end, end)]; % 测试集输出
end
%% 数据转置
P_train = P_train'; P_test = P_test';
T_train = T_train'; T_test = T_test';
%% 得到训练集和测试样本个数
M = size(P_train, 2);
N = size(P_test , 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
t_train = categorical(T_train)';
t_test = categorical(T_test )';
%% 数据平铺 公众号:创新优化及预测代码
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(P_train, num_dim, 1, 1, M));
p_test = double(reshape(P_test , num_dim, 1, 1, N));
%% 构造CNN-BiGRU-Attention网络
lgraph = layerGraph();
% 添加层分支 公众号:创新优化及预测代码
% 将网络分支添加到层次图中。每个分支均为一个线性层组。
tempLayers = [
imageInputLayer([numComponents 1 1],"Name","imageinput")
convolution2dLayer([2 1],16,"Name","conv_1")
batchNormalizationLayer("Name","batchnorm_1")
reluLayer("Name","relu_1")
maxPooling2dLayer([2 1],"Name","maxpool_1")
flattenLayer("Name","flatten")];
lgraph = addLayers(lgraph,tempLayers);
tempLayers = gruLayer(128,"Name","gru");
lgraph = addLayers(lgraph,tempLayers);
tempLayers = [
FlipLayer("flip3")
gruLayer(128,"Name","gru_1")];
lgraph = addLayers(lgraph,tempLayers);