python3.6.国家政策文本分析代码
根据学习至今的python,和导师吩咐的方向,一共做了5件事:
1.政府网http://www.gov.cn/index.htm中养老政策特殊文本爬取与保存。
2.基于的TF/IDF多文档关键词抽取。
-基于TF-IDF算法的关键词抽取(原文:https://blog.csdn.net/zhangyu132/article/details/52128924)
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
–sentence 为待提取的文本
–topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
–withWeight 为是否一并返回关键词权重值,默认值为 False
–allowPOS 仅包括指定词性的词,默认值为空,即不筛选
-基于TextRank算法的关键词提取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
–基本思想:
1,将待抽取关键词的文本进行分词
2,以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
import jieba
import jieba.analyse
import pandas as pd
for i in range(23):
text = open(r'D:\\python3.6.5\\pycharm\\main\\output\\txt\\'+str(i)+'.txt','r',encoding='utf-8').read()
words=jieba.analyse.extract_tags(text, topK = 15,withWeight =True, allowPOS = ('ns', 'n', 'vn', 'v', 'nr', 'x'))
for word in words:
#print('keywords based on TFIDF:'+'/'.join([word for word in words]))
fileout = r'D:\python3.6.5\gongci\new1.txt'
with open (fileout,'a') as fr:
fr.write(word+'/')
print(word,weight)topK=15表示每篇文章抽取频率最高的前15个词。下一步处理共现时词与词中间需要'/',否则无法共现,然后将每篇抽取的放入同一个xlxs中,抽取结果如图:

3.关键词共现矩阵的生成。
import xlrd
#读入表格数据,返回形如['/././','././','/././','/././']格式的列表
def readxls_bycol(path,colnum):
# path=r'D:\Ditys\python learning\学习任务\第4次任务20170222\test.xlsx' #少了个r有时候会抽风出错!!!!
# colnum=2 #从0开始计数!!所以,第三列的序号为2
xl = xlrd.open_workbook(path)
table = xl.sheets()[0]
data = list(table.col_values(colnum))
print(data)
print('----------1---------')
return data
#处理表格数据, 返回无重复的所有出现过的关键词set
def deal_data(data):
data_list = []
data_set = set()
for i in data:
data_list.extend(i.split('/'))
# data_list.sort() #!!!高亮, 升序排列??????
data_set=set(data_list)
print(data_set)
print('----------2---------')
return data_set
#根据set,可建立一个二维列表,并填充其其一行以及第一列, 返回建好框架的二维列表
def creat_list_2d(data_set):
i = len(data_set)+1
#list1=[['' for x in range(i)] for y in range(i)]
list_2d = [[0 for col in range(i)] for row in range(i)] #建一个空二维列表的方法噢~
n=1
for row_1 in data_set:
list_2d[0][n] = row_1 #填充第一行数据
n+=1
if n == i:
break
print(list_2d)
m=1
print(data_set)
for cols in data_set: #填充第一列数据
list_2d[m][0] = cols
m += 1
if m == i:
break
print(list_2d)
print('----------3---------')
return list_2d
#计算共现次数, 填充二维列表~ 返回填好的列表~
def count_data(list_2d,data,data_set):
data_formted= []
for i in data:
data_formted.append(i.split('/'))
print(data_formted)
print('----------4---------')
for row in range(1,len(data_set)):
for col in range(1,len(data_set)):
if row == col:
continue
else:
counter = 0
for i in data_formted:
if list_2d[col][0] in i and list_2d[0][row] in i :
counter += 1
list_2d[row][col] = counter
print(list_2d)
print('----------5---------')
return list_2d
#把矩阵写进txt~~~~
def putdata_intotxt(path,matrix):
with open(path,'w') as f :
for row in range(0,len(matrix)):
for col in range(0,len(matrix)):#二维列表中的每一个元素都走一遍
f.write(str(matrix[row][col]) + '\t') #因为write()只接字符串类型啊
f.write('\n')
def main():
#path_xls = r'test.xlsx' #---测试数据---
#path_txt= r'共现矩阵.txt' #---测试数据---
path_xls = r'D:\python3.6.5\gongci\test.xlsx' #r不可少
path_txt= r'D:\python3.6.5\gongci\关键词共现矩阵.xlsx'
colnum = 0
data = readxls_bycol(path_xls,colnum)
data_set = deal_data(data)
list_2d = creat_list_2d(data_set)
matrix = count_data(list_2d,data,data_set)
print(matrix)
putdata_intotxt(path_txt,matrix)
if __name__=='__main__':
main()
print('你的文件夹多了一个共现矩阵的结果~快去看看吧XP')结果如图

4.政策词云图的生成(这是一段单独的程序,也可以把上下步骤加进来)
# -*- encoding:utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup # 导入urllib库的request模块
import lxml #文档解析器
import time #时间模块
import os #os模块就是对操作系统进行操作
import matplotlib.pyplot as plt #数学绘图库
import jieba #分词库
from PIL import Image #图片
from wordcloud import WordCloud, ImageColorGenerator #词云库
from collections import Counter #列表、字典、字符串等中计算元素重复的次数
import numpy as np #科学计算
t = time.localtime(time.time()) #转换至当前时区;time.time():返回当前时间的时间戳;
foldername = str(t.__getattribute__("tm_year")) + "-" + str(t.__getattribute__("tm_mon")) + "-" + str(t.__getattribute__("tm_mday"))+ "-" + str(t.__getattribute__("tm_ho ur"))
picpath = 'D:\\python3.6.5\\pycharm\\main\\%s' % (foldername)
def txt(name, text): # 定义函数名
if not os.path.exists(picpath): # 路径不存在时创建一个
os.makedirs(picpath)
savepath = picpath + '\\' + name + '.txt'
file = open(savepath, 'a', encoding='utf-8')
file.write(text)
# print(text)
file.close
return (picpath)
def get_text(bs):
# 读取纯文本
for p in bs.select('p'):
t = p.get_text()
# print(t)#输出文本
txt('url2', t)
def FenCi(pathin,pathout1,pathout2,picturein,pictureout):
text = open(pathin, "r", encoding='utf-8').read()# 1、读入txt文本数据
#2、结巴分词,默认精确模式。可以添加自定义词典userdict.txt,然后jieba.load_userdict(file_name) ,file_name为文件类对象或自定义词典的路径
#自定义词典格式和默认词库dict.txt一样,一个词占一行:每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒
cut_text = jieba.cut(text, cut_all=False)
result = " ".join(cut_text)
#print(result)
with open(pathout1, 'a', encoding='utf-8') as f:
f.write(result)
print("save")
#3、wordcount
with open(pathout1, 'r', encoding='utf-8') as fr: # r:只读;w:只写
data = jieba.cut(fr.read())
data = dict(Counter(data))
with open(pathout2, 'a', encoding='utf-8') as fw: # 读入存储wordcount的文件路径
for k, v in data.items():
fw.write('%s,%d\n' % (k, v))
# 4、初始化自定义背景图片
image = Image.open(picturein)
graph = np.array(image)
# 5、产生词云图
# 有自定义背景图:生成词云图由自定义背景图像素大小决定
wc = WordCloud(font_path=r"D:\Python3.6.5\jieba\ttf\yahei.ttf", background_color='white', max_font_size=50,mask=graph)
wc.generate(result)
# 6、绘制文字的颜色以背景图颜色为参考
image_color = ImageColorGenerator(graph) # 从背景图片生成颜色值
wc.recolor(color_func=image_color)
wc.to_file(pictureout)
def readhtml(path): #读取网页文本
res = urllib.request.urlopen(path) # 调用urlopen()从服务器获取网页响应(respone),其返回的响应是一个实例
html = res.read().decode('utf-8') # 调用返回响应示例中的read(),可以读取html
soupa = BeautifulSoup(html, 'lxml')
result = soupa.find_all('div', class_='result')
download_soup = BeautifulSoup(str(result), 'lxml')#使用查询结果再创建一个BeautifulSoup对象,对其继续进行解析
urls = []
url_all = download_soup.find_all('a')
#抓取所有政策链接
for a_url in url_all:
a_url = a_url.get('href')
urls.append(a_url)
url = a_url
txt('url0', a_url)
res = urllib.request.urlopen(url)# 指定要抓取的网页url
html = res.read().decode('utf-8')
# print(html)
txt('url1', html)
soup = BeautifulSoup(html, 'lxml')
get_text(soup)
for n in range(3):
url = r'http://sousuo.gov.cn/s.htm?q=&n=10&p=' + str(n) + '&t=paper&advance=true&title=%E5%85%BB%E8%80%81&content=&puborg=&pcodeJiguan=&pcodeYear=&pcodeNum=&childtype=&subchildtype=&filetype=&timetype=timeqb&mintime=&maxtime=&sort=&sortType=1&nocorrect=' # 指定要抓取的网页url,必须以http开头
readhtml(url)
#picpath + '\\url2.txt'
a=picpath + '\\url2.txt'
b=picpath + '\\result.txt'
c=picpath + '\\result.csv'
d=r'D:\python3.6.5\jieba\1.jpg'
e=picpath + '\\wordcloud.png'
FenCi(a,b,c,d,e)
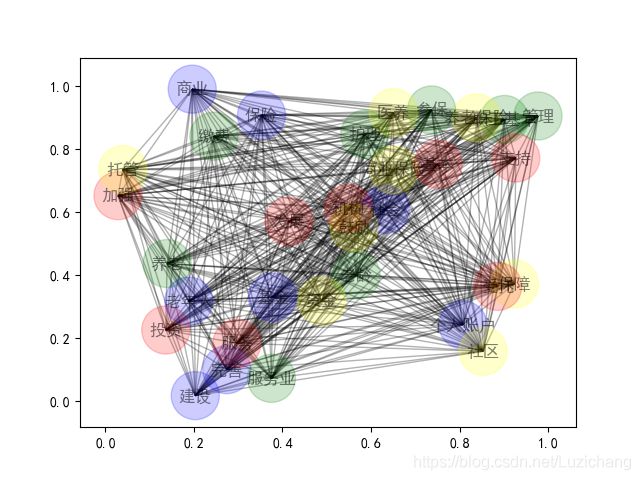
print('finish')5.关键词网络关系图生成。
import pandas as pd
import numpy as np
import codecs
import networkx as nx
import matplotlib.pyplot as plt
a = []
f = codecs.open(r'D:\python3.6.5\gongci\1.txt','r')
line = f.readline()
#print (line)
i = 0
A = []
B = []
while line!="":
a.append(line.split()) #保存文件是以空格分离的
#print (a[i][0],a[i][1])
A.append(a[i][0])
B.append(a[i][1])
i = i + 1
print(i)
line = f.readline()
elem_dic = tuple(zip(A,B))
#print (type(elem_dic))
#print (list(elem_dic))
f.close()
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
colors = ["red","green","blue","yellow"]
G = nx.Graph()
G.add_edges_from(list(elem_dic))
pos=nx.random_layout(G) #random;spring;circular
nx.draw_networkx_nodes(G, pos, alpha=0.2,node_size=1200,node_color=colors)
nx.draw_networkx_edges(G, pos, node_color='r', alpha=0.3) #style='dashed'
nx.draw_networkx_labels(G, pos, font_family='sans-serif', alpha=0.5) #font_size=5
plt.show()
做关系图时要把生成的nxn共现矩阵转换为一个nx3的矩阵,如下图,然后将所有数取倒数,(取倒数前将所有0置为0.01),我认为两词距离越近那么他们之间值应该也越小,而上面得出的共现矩阵以加法形式进行计算。

以下是得出的结果,