HDFS RBF 联邦企业级生产实战
一 HDFS Federation介绍
关于HDFS Federation的介绍,请查看文章 HDFS Federation前世今生。
RBF (Router-Based Federation) is a new feature of HDFS of Apache Hadoop. By enabling the RBF, it can handle multiple Hadoop cluster transparently as one of the Hadoop cluster for the user.
Background and development situation that RBF has appeared, please refer to the resources below.
- https://qiita.com/ajis_ka_old/items/d132c040f98836f2f3de
- https://www.slideshare.net/techblogyahoo/apache-hadoop-hdfs2018dbts2018
二 RBF与ViewFS比较
Hadoop社区提供了两种Federation方案:分别是ViewFS 和 Router-Based Federation。在 Hadoop 3.1.3 版本下两者对比如下表:
| 功能 | Router-Based Federation | ViewFS | 备注 |
|---|---|---|---|
| schema前缀 | hdfs:// | viewfs:// | |
| 挂载信息存储方式 | 本地或zookeeper | 配置文件 | |
| 客户端配置 | 轻 | 重 | |
| 调用耗时 | 适中 | 无 | RBF加了一层router |
| 缓存映射表 | 支持 | 支持 | cache |
| 权限设置 | 支持 | 不支持 | |
| Quota设置 | 支持 | 不支持 | |
| 多NS挂载 | 支持 | 支持(备份方式) | |
| 跨子集群的balance | 社区开发中 | 不支持 | |
| 跨子集群的cp/mv | 社区开发中 | 不支持 | |
| 安全认证 | 不支持(3.3开始支持) | 支持 | |
| Hadoop版本要求 | Hadoop 2.9+ | Hadoop 0.23+ |
综合来看,Router-Based Federation 和 ViewFS 相比,在Hadoop 版本上要求较高需要2.9 以上,在升级管理方面更易于维护,且客户端改动更小,更好推动。
三 RBF安装配置
3.1 配置总览
基于hdp 3.1.5 搭建 HDFS RBF,配置如下:
- Router x 2
- Receives the client’s request, referring to the mount information of StateStore, and then routed to the appropriate NameNode
- StateStore (ZooKeeper)
- HDFS has to save the mount information of the Hadoop cluster on. In other words, by bundling a HDFS multiple Hadoop cluster, it holds one of the virtual directory tree
- Hadoop(HDP) cluster x 2
- Gateway (Hadoop node that the client has been installed)

3.2 集群概况
Cluster A 是存量集群且NameNode HA。
Cluster B是新建集群且还未配置NameNode HA。
3.2.1 Cluster A 概况
存量集群,并且hive中已经存在数据。
| 主机 | NN | JN | ZK | client |
|---|---|---|---|---|
| test.bigdata.song482w (hdp150) | √ | √ | ||
| test.bigdata.song483w (hdp151) | √ | √ | √ | |
| test.bigdata.song484w (hdp152) | √ | √ | √ | |
| test.bigdata.song485w (hdp153) | √ |
hdfs-site.xml
<! - Name Service ->
<property name="dfs.nameservices" value="hdpOne"/>
<property name="dfs.ha.namenodes.hdpOne" value="nn1,nn2"/>
<- RPC address -!>
<property name="dfs.namenode.rpc-address.hdpOne.nn1" value="test.bigdata.song483w:8020"/>
<property name="dfs.namenode.rpc-address.hdpOne.nn2" value="test.bigdata.song484w:8020"/>
<- HTTP address -!>
<property name="dfs.namenode.http-address.hdpOne.nn1" value="test.bigdata.song483w:50070"/>
<property name="dfs.namenode.http-address.hdpOne.nn2" value="test.bigdata.song484w:50070"/>
3.2.2 Cluster B概况
新建集群,安装完hdfs和zookeeper后,不要开启 hdfs ha。
然后进行如下步骤:
- stop hdfs
- 清空原来的hdfs目录
- hdfs初始化是指定与Cluster A 相同的clusterId:
sudo -u hdfs hdfs namenode -format -clusterId clusterId - start hdfs
- enable namenode ha
注意上面步骤的顺序
| 主机 | NN | JN | ZK |
|---|---|---|---|
| test.bigdata.song487w (hdp155) | √ | √ | √ |
| test.bigdata.song488w (hdp156) | √ | √ | √ |
| test.bigdata.song489w (hdp157) | √ | √ |
hdfs-site.xml
<! - Name Service ->
<property name="dfs.nameservices" value="hdpTwo"/>
<property name="dfs.ha.namenodes.hdpTwo" value="nn1,nn2"/>
<- RPC address -!>
<property name="dfs.namenode.rpc-address.hdpTwo.nn1" value="test.bigdata.song487w:8020"/>
<property name="dfs.namenode.rpc-address.hdpTwo.nn2" value="test.bigdata.song488w:8020"/>
<- HTTP address -!>
<property name="dfs.namenode.http-address.hdpTwo.nn1" value="test.bigdata.song487w:50070"/>
<property name="dfs.namenode.http-address.hdpTwo.nn2" value="test.bigdata.song488w:50070"/>
3.3 服务端hdfs-site.xml配置
first delete unnecessary configuration:dfs.internal.nameservices.
然后添加如下配置:
<property name="dfs.nameservices" value="hdpOne,hdpTwo" />
<property name="dfs.ha.namenodes.hdpOne" value="nn1,nn2" />
<property name="dfs.ha.namenodes.hdpTwo" value="nn1,nn2" />
<property name="dfs.namenode.rpc-address.hdpOne.nn1" value="test.bigdata.song483w:8020" />
<property name="dfs.namenode.rpc-address.hdpOne.nn2" value="test.bigdata.song484w:8020" />
<property name="dfs.namenode.http-address.hdpOne.nn1" value="test.bigdata.song483w:50070" />
<property name="dfs.namenode.http-address.hdpOne.nn2" value="test.bigdata.song488w:50070" />
<- The address of the cluster B (Ns2) -!>
<property name="dfs.namenode.rpc-address.hdpTwo.nn1" value="test.bigdata.song487w:8020" />
<property name="dfs.namenode.rpc-address.hdpTwo.nn2" value="test.bigdata.song488w:8020" />
<property name="dfs.namenode.http-address.hdpTwo.nn1" value="test.bigdata.song487w:50070" />
<property name="dfs.namenode.http-address.hdpTwo.nn2" value="test.bigdata.song488w:50070" />
每个集群的配置都相同
3.4 路由器设置
3.4.1 配置
Router 的设置值也在hdfs-site.xml.
HDFS-14516 by hdfs-rbf-site.xmleven now can be described. (Hadoop-3.3.0 or later)
因为hdp的hadoop版本为3.1,故需要在hdfs-site.xml中设置
Router主要的端口有3个:
dfs.federation.router.rpc-address: Router的默认RPC端口8888, Client发送RPC到此dfs.federation.router.admin-address: Router的默认routeradmin命令端口8111dfs.federation.router.http-address: Router的默认UI地址50071
<! - the default name service specifies the cluster A ->
<property>
<name>dfs.federation.router.default.nameserviceIdname>
<value>hdpOnevalue>
property>
<property>
<name>dfs.federation.router.default.nameservice.enablename>
<value>truevalue>
property>
<property>
<name>dfs.federation.router.store.driver.classname>
<value>
org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreZooKeeperImpl
value>
property>
<property>
<name>hadoop.zk.addressname>
<value>test.bigdata.song482w:2181,test.bigdata.song483w:2181,test.bigdata.song484w:2181value>
property>
<property>
<name>dfs.federation.router.store.driver.zk.parent-pathname>
<value>/hdfs-federationvalue>
property>
<property>
<name>dfs.client.failover.random.ordername>
<value>truevalue>
property>
<property>
<name>dfs.federation.router.monitor.localnamenode.enablename>
<value>falsevalue>
property>
<property>
<name>dfs.federation.router.monitor.namenodename>
<value>hdpOne.nn1,hdpOne.nn2,hdpTwo.nn1,hdpTwo.nn2value>
property>
<property>
<name>dfs.federation.router.quota.enablename>
<value>truevalue>
property>
<property>
<name>dfs.federation.router.cache.ttlname>
<value>10svalue>
property>
<proterty>
<name>dfs.federation.router.file.resolver.client.classname> <value>org.apache.hadoop.hdfs.server.federation.resolver.MultipleDestinationMountTableResolvervalue>
proterty>
<property>
<name>dfs.federation.router.rpc-addressname>
<value>0.0.0.0:8888value>
property>
<property>
<name>dfs.federation.router.rpc-bind-hostname>
<value>0.0.0.0value>
property>
<property>
<name>dfs.federation.router.handler.countname>
<value>20value>
property>
<property>
<name>dfs.federation.router.handler.queue.sizename>
<value>200value>
property>
<property>
<name>dfs.federation.router.reader.countname>
<value>5value>
property>
<property>
<name>dfs.federation.router.reader.queue.sizename>
<value>100value>
property>
<property>
<name>dfs.federation.router.connection.pool-sizename>
<value>6value>
property>
<property>
<name>dfs.federation.router.metrics.enablename>
<value>truevalue>
property>
在目前的规范中,需要在Router配置文件中描述所有要路由的NameNode的RPC地址和HTTP地址。随着集群数量的增加,难度会越来越大,所以以后会实现服务发现功能。
* 2019 年 6 月添加
HDFS-14118添加了允许使用 DNS 循环对 NameNode 和路由器进行名称解析的功能。这消除了在配置文件中写入真实主机名的需要,从而更容易添加或删除主机。(Hadoop-3.3.0 或更高版本)
3.4.2 StateStore存储方式
正式使用目前一般都是用ZK存储(如上面配置所示), 后续官方也会支持DBMS类似Mysql存储
DBMS State Store的实现支持(HDFS-13245),目前已有相关patch,正在review中。DBMS State Store在实际场景中其实是一个非常常见的一个存储方式,一旦这块能够支持了,那么RBF在应用性上将会好很多。
如果你没配置ZK, 也没有修改配置文件换成本地/HDFS存储映射, 启动router后尝试添加记录, 会提示Cached State Store not initialized. 那选本地它存在哪呢?
这个配置官方文档没说, 从源码里可得知是dfs.federation.router.store.driver.file.directory , 如果不配置, 则会写到临时目录/tmp下(时间戳开头), ,
本地存储配置如下:
<property>
<name>dfs.federation.router.store.driver.classname>
<value>org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreFileImplvalue>
property>
<property>
<name>dfs.federation.router.store.driver.file.directoryname>
<value>/tmp/ssFilesvalue>
property>
本地存储的结构是:
# 以刚操作的映射具体为例
/tmp/1587999869041-0
├── DisabledNameservice # 关闭的NS
|
├── MembershipState # NS/NN信息
| |
| |# ha标签 + NS名 + nnIP
│ └── null-sc1-nnIP_8888 # 若未使用HA, 这里第一项就是null
|
├── MountTable # 挂载表信息
│ ├── 0SLASH0router_share
│ ├── 0SLASH0router_share1
│ ├── 0SLASH0router_share2
│ ├── 0SLASH0router_test1
│ ├── 0SLASH0router_test2
| ├── ......(略)
|
└── RouterState # Router的信息
└── routerIP_8888
# 查看这些文件的内容, 应该是被base64编码处理了 (细节待代码确认)
cat /tmp/1587999869041-0/MountTable/0SLASH0router_test3
# 显示如下
Cg0vcm91dGVyX3Rlc3QzEg0KA3NjMRIGL3Rlc3QyGL2d7eGbLiC9ne3hmy4oATAAUgR3b3JrWgR3b3JrYO0DahoIABD///8BGAAgAQ==
配置HDFS存储暂未测试 (后续测试应使用HDFS, 因为本地存储不能共享, 失去了跨NS的功能)
3.4.3 路由器启停
如果到目前为止设置没有问题,您可以启动路由器。
Router的启动/停止方式和启动DN/NN类似, 作为一个独立进程, 也有自己单独的日志 :
# 启动
# 第一次启动后router会进入safemode, 注意观察日志
[[email protected] ~]$ sudo hdfs --daemon start dfsrouter
[[email protected] ~]$ sudo hdfs --daemon start dfsrouter
# 60s后会自动退出safemode
hdfs dfsrouteradmin -safemode leave
# 停止
[[email protected] ~]$ sudo hdfs --daemon stop dfsrouter
[[email protected] ~]$ sudo hdfs --daemon stop dfsrouter
3.4.4 Router UI
Router的UI风格基本是和NN界面一样, 几个主要模块:
Overview(概览)
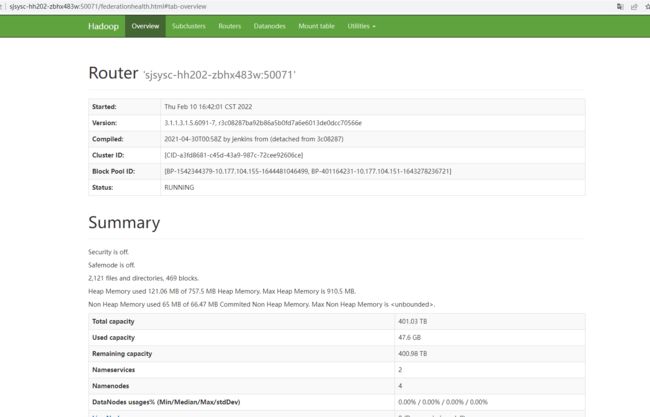
Subcluster(子集群信息)
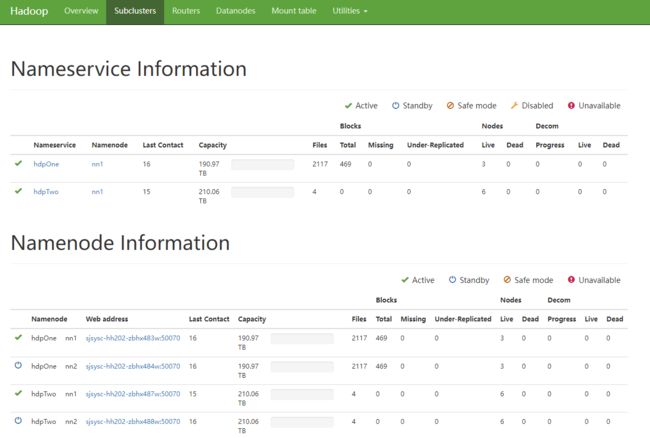
Routers
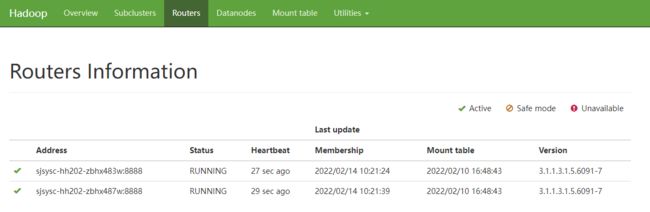
Mount table
3.4.5 Router Cli
dfsrouteradmin命令只能在 router所在机器执行
关键在于我们需要添加路由表, 常见的方式是通过routeradmin命令增删改查:
# 核心是add(添加)命令, 有这些选项:
# -readonly -owner -group -mode (通用)
# -faulttolerant -order [HASH|LOCAL|RANDOM|HASH_ALL|SPACE] (多映射专用)
# 1.1 添加一个映射, 用户test, 组admin
./bin/hdfs dfsrouteradmin -add /router_test1 sc1 /test1 -owner test -group admin
# 1.2 添加一个映射, 读写权限设置为750
./bin/hdfs dfsrouteradmin -add /router_test2 sc1 /test2 -mode 750
# 1.3 添加一个映射, 希望此目录是只读, 任何用户不可写入的
./bin/hdfs dfsrouteradmin -add /router_readOnly sc1 /test3 -readonly
# 2.1 添加多(NS)对一映射, 让2个NS指向1个目录, 容忍多操作失败 (默认hash策略)
./bin/hdfs dfsrouteradmin -add /router_share sc1,sc2 /tmp -faulttolerant
# 2.2 添加多对一映射, 让2个NS指向1个目录 (使用优选最近策略)
./bin/hdfs dfsrouteradmin -add /router_share1 sc1,sc2 /tmp1 -order LOCAL
# 3. 查看目前的mount信息, 见图
./bin/hdfs dfsrouteradmin -ls
# 4. 修改已经创建过的映射, 参数同add (重复add不会覆盖已有)
./bin/hdfs dfsrouteradmin -update /router_test2 sc1 /test2 -mode 500
# 5. 删除映射记录, 只用写映射的路径(source)
./bin/hdfs dfsrouteradmin -rm /router_test2
# 立刻刷新本机router同步操作, 默认ns才会同步刷新
./bin/hdfs dfsrouteradmin -refresh
# router-quota默认关闭, 后续再说
# 1. 开启/关闭NS (后跟NS名)
bin/hdfs dfsrouteradmin -nameservice enable/disbale sc1
# 1.1 获取关闭的NS
bin/hdfs dfsrouteradmin -getDisabledNameservices
# 2. 设置Router-Quota (生效需要修改配置文件么?)
# nsQuota代表文件数, ssQuota代表大小(单位字节)
bin/hdfs dfsrouteradmin -setQuota /router_share1 -nsQuota 2 -ssQuota 2048
3.5 客户端设置
您可以通过直接向路由器而不是 NameNode 发送请求来执行 Hadoop 命令,而无需在客户端进行任何设置。
hdfs dfs -ls hdfs://test.bigdata.song483:8888/
-ls: java.net.UnknownHostException: test.bigdata.song483
[[email protected] ~]$ hdfs dfs -ls hdfs://10.177.104.151:8888/
下面先来说一下客户端的配置, 它是访问Router的主体, 如果和NN一台机器, 建议单独复制包分开, 不要在NN配置里添加客户端的配置 (有冲突)
客户端如果想要通过router的方式访问联邦集群,hdfs-site.xml做如下调整,添加新的namespace(hdp-fed),并配置高可用模式,注意dfs.namenode.rpc-address.hdp-fed.r1属性配置的是router对应的服务,端口是8888。
<property>
<name>dfs.nameservicesname>
<value>hdpOne,hdpTwo,hdp-fedvalue>
property>
<property>
<name>dfs.ha.namenodes.hdp-fedname>
<value>r1,r2value>
property>
<property>
<name>dfs.namenode.rpc-address.hdp-fed.r1name>
<value>test.bigdata.song483w:8888value>
property>
<property>
<name>dfs.namenode.rpc-address.hdp-fed.r2name>
<value>test.bigdata.song487w:8888value>
property>
<property>
<name>dfs.client.failover.proxy.provider.hdp-fedname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.federation.router.default.nameserviceIdname>
<value>hdpOnevalue>
property>
<property>
<name>dfs.client.failover.random.ordername>
<value>truevalue>
property>
客户段配置只需要在客户端添加即可,不需要在服务端添加
那之前viewFS时需要修改core-site.xml的fs.defaultFS参数, 现在还需要修改么? 应该配置成什么呢?
<property>
<name>fs.default.namename>
<value>hdfs://hdp-fedvalue>
property>
配置上后,yarn启动不了,为查明原因,可能与client
即可通过 hadoop fs -ls hdfs://hdp-fed/xxx 的方式访问联邦集群。
四 排错
实验过程中遇到过这些错, 记录一下供大家参考:
# 1.Unknown Host异常, 需加上对应proxy.provider配置 (详见配置文件)
WARN fs.FileSystem: Failed to initialize fileystem hdfs://hdpTwo:
java.lang.IllegalArgumentException: java.net.UnknownHostException: hdpTwo
# 2.配置后启动router提示, 说明你的NS配置中, 本地NS和Client用的NS同时是一台机器
# 它需要你再用NS_ID来区分, 否则ID自动生成相同的就会认为冲突. (详见配置文件)
Configuration has multiple addresses that match local node's address.
Please configure the system with dfs.nameservice.id and dfs.ha.namenode.id
解决方案:
client不要部署到NS上,或者只在clent所在机器添加客户端配置
# 3.启动router时提示找不到ip:8888的Namenode (client和NN混用)
Cannot locate a registered namenode for routers from test1:8888
# 这里存在一个冲突, client访问router需要配置8888端口代替原有的NN端口
# 但是启动router的时候, 默认它又会去找同一配置, 把router视为一个NN
# 这样来看, NN自身作client的时候, 似乎就有冲突问题?
# 我目前的做法是相对原始但有效的办法: (参考上面客户端配置)
# 就是你复制一份hdfs包, 单独使用, 不复用同一份配置.
五 测试
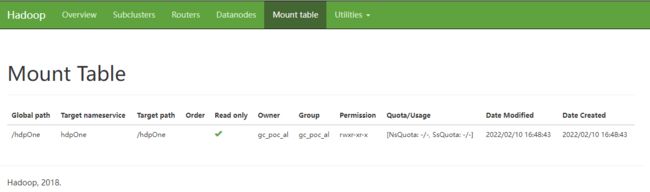
5.1 Mount Table
[[email protected] ~]$ sudo -u hdfs hdfs dfs -mkdir -p hdfs://hdpOne/data/hdpOne
[[email protected] ~]$ sudo -u hdfs hdfs dfs -chown gc_poc_al:gc_poc_al hdfs://hdpOne/data/hdpOne
[[email protected] ~]$ echo hdpOne > hdpOne.txt && hdfs dfs -put hdpOne.txt hdfs://hdpOne/data/hdpOne
[[email protected] ~]$ sudo -u hdfs hdfs dfs -mkdir -p hdfs://hdpTwo/data/hdpTwo
[[email protected] ~]$ sudo -u hdfs hdfs dfs -chown gc_poc_al:gc_poc_al hdfs://hdpTwo/data/hdpTwo
echo hdpTwo > hdpTwo.txt && hdfs dfs -put hdpTwo.txt hdfs://hdpTwo/data/hdpTwo
[[email protected] ~]$ echo hdpTwo > hdpTwo.txt && hdfs dfs -put hdpTwo.txt hdfs://hdpTwo/data/hdpTwo
[[email protected] ~]$ hdfs dfsrouteradmin -add /data/hdpOne hdpOne /data/hdpOne
[[email protected] ~]$hdfs dfsrouteradmin -add /data/hdpTwo hdpTwo /data/hdpTwo
查看挂载表信息:
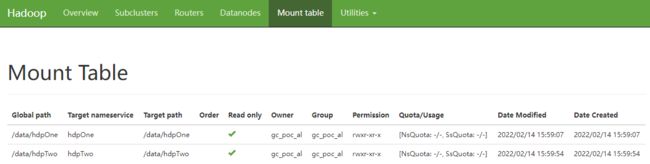
5.2 HDFS命令
5.2.1 跨子集群cp
[[email protected] ~]$ hdfs dfs -cp hdfs://hdp-fed/data/hdpOne/hdpOne.txt hdfs://hdp-fed/data/hdpTwo
[[email protected] ~]$ hdfs dfs -ls hdfs://hdp-fed/data/hdpTwo
Found 2 items
-rw-r--r-- 3 gc_poc_al gc_poc_al 7 2022-02-14 16:21 hdfs://hdp-fed/data/hdpTwo/hdpOne.txt
-rw-r--r-- 3 gc_poc_al gc_poc_al 7 2022-02-14 16:16 hdfs://hdp-fed/data/hdpTwo/hdpTwo.txt
5.2.2 跨子集群mv(不支持)
[[email protected] ~]$ hdfs dfs -mv hdfs://hdp-fed/data/hdpTwo/hdpTwo.txt hdfs://hdp-fed/data/hdpOne
mv: Rename of /data/hdpTwo/hdpTwo.txt to /data/hdpOne/hdpTwo.txt is not allowed, no eligible destination in the same namespace was found.
5.2.3 联邦rm
[[email protected] ~]$ hdfs dfs -rm hdfs://hdp-fed/data/hdpTwo/hdpOne.txt
rm: Failed to move to trash: hdfs://hdp-fed/data/hdpTwo/hdpOne.txt: Rename of /data/hdpTwo/hdpOne.txt to /user/gc_poc_al/.Trash/Current/data/hdpTwo/hdpOne.txt is not allowed, no eligible destination in the same namespace was found.
[[email protected] ~]$ hdfs dfsrouteradmin -add /user/gc_poc_al/.Trash hdpOne,hdpTwo /user/gc_poc_al/.Trash -order SPACE
[[email protected] ~]$ hdfs dfs -rm hdfs://hdp-fed/data/hdpTwo/hdpOne.txt
22/02/17 17:09:26 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hdp-fed/data/hdpTwo/hdpOne.txt' to trash at: hdfs://hdp-fed/user/gc_poc_al/.Trash/Current/data/hdpTwo/hdpOne.txt
5.2.4 联邦put
[[email protected] ~]$ echo hdpOne > hdpOneTmp.txt && hdfs dfs -put hdpOneTmp.txt hdfs://hdp-fed/data/hdpOne
[[email protected] ~]$ hdfs dfs -ls hdfs://hdp-fed/data/hdpOne
Found 2 items
-rw-r--r-- 3 gc_poc_al gc_poc_al 7 2022-02-14 16:17 hdfs://hdp-fed/data/hdpOne/hdpOne.txt
-rw-r--r-- 3 gc_poc_al gc_poc_al 7 2022-02-14 16:30 hdfs://hdp-fed/data/hdpOne/hdpOneTmp.txt
5.2.5 Quota设置
# 设置Quota
# nsQuota代表文件数, ssQuota代表大小(单位字节)
[[email protected] ~]$ sudo -u hdfs hdfs dfsrouteradmin -setQuota /data/hdpOne -nsQuota 10 -ssQuota 2048
Successfully set quota for mount point /data/hdpOne
5.2.6 权限设置
[[email protected] ~]$ hdfs dfsrouteradmin -update /data/hdpOne hdpOne /data/hdpOne -owner gc_poc_al -group gc_poc_al
Successfully updated mount point /data/hdpOne
5.3 mapreduce
源集群目录测试
[[email protected] ~]$ hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar wordcount hdfs://hdp-fed/data/hdpOne hdfs://hdp-fed/data/hdpOne/output
[[email protected] ~]$ hdfs dfs -cat hdfs://hdp-fed/data/hdpOne/output/*
hdpOne 2
联邦集群目录测试
[[email protected] ~]$ hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar wordcount hdfs://hdp-fed/data/hdpTwo hdfs://hdp-fed/data/hdpTwo/output
[[email protected] ~]$ hdfs dfs -cat hdfs://hdp-fed/data/hdpTwo/output/*
hdpTwo 1
5.4 Hive
原数据:
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> show create table student;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `student`( |
| `id` int, |
| `name` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' |
| LOCATION |
| 'hdfs://hdpOne/warehouse/tablespace/managed/hive/tmp.db/student' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transactional'='true', |
| 'transactional_properties'='default', |
| 'transient_lastDdlTime'='1645086530') |
+----------------------------------------------------+
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> select * from student;
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1001 | ZhangSan |
| 1002 | LiSi |
+-------------+---------------+
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> select count(1) from student;
+------+
| _c0 |
+------+
| 2 |
+------+
rbf启用后,原hive集群不受影响
新数据:
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> create table student_fed(id int, name string) location 'hdfs://hdp01:8888/user/root/';
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> show create table student_fed;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `student_fed`( |
| `id` int, |
| `name` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' |
| LOCATION |
| 'hdfs://hdp01:8888/user/root' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transactional'='true', |
| 'transactional_properties'='default', |
| 'transient_lastDdlTime'='1645090801') |
+----------------------------------------------------+
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> insert into student_fed(id, name) values (1001,'ZhangSan'),(1002,'LiSi');
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> select * from student_fed;
+-----------------+-------------------+
| student_fed.id | student_fed.name |
+-----------------+-------------------+
| 1001 | ZhangSan |
| 1002 | LiSi |
+-----------------+-------------------+
0: jdbc:hive2://hdp01.test.cn:2181,hdp02.test> select count(1) from student_fed;
+------+
| _c0 |
+------+
| 2 |
+------+
rbf后,hive新数据建表时只需指定location为router url即可
六 遇到的问题
6.1 跨子集群mv
目前版本rbf不能执行跨子集群mv命令
6.2 rm执行失败
在HDFS集群中,在哪个用户下执行rm操作,数据会被移动到/user/用户/.Trash目录下,默认的该目录挂载在Namespace1中,因此Namespace2中执行rm会报错rm失败。解决方法:将Trash挂载到两个集群。
6.3 Hive location问题
Hive会以绝对路径的方式存储元数据,因此如果修改fs.defaultFS则需要大批量修改Hive元数据,因此,保留fs.defaultFS的设置,在HDFS中更改该nameservice的映射关系,即由原来的映射NameNode修改为映射到LVS和Router。
6.4 客户端部署问题
客户端不可以和NameNode部署在同一台机器上,有冲突。
七 HDP3.1.5 RBF不足
7.1 Kerberos认证
Hadoop 3.1.3版本的RBF是不支持kerberos的,社区修复了这一问题。
HDFS-13358
7.2 StateStore存储问题
目前StateStore正式使用目前一般都是用ZK存储。
HDFS权限认证包括Kerberos 和 Delegation Token认证两种方式。
按照社区现在的实现,是由 Router 来构造 Delegation Token,认证Client。为了让所有的 Router 能同步已构造的 Delegation Token,需要将其存到 State Store 来让 Router 间进行同步。这样做的好处实现简单,不需要和所有的 NameNode 进行通信就可以在 Router层完成认证。坏处是需要 Router 间进行同步,这可能会导致性能问题,以及由于 Zookeeper 并非保证强一致性,Router 可能会读不到另一个 Router构造的 Delegation Token,结果 Client 认证失败。
DBMS State Store的实现支持(HDFS-13245),目前已有相关patch,正在review中。DBMS State Store在实际场景中其实是一个非常常见的一个存储方式,一旦这块能够支持了,那么RBF在应用性上将会好很多。
八 生产环境可用性
目前是基于hdp 3.1.5 hadoop3.1 进行测试的,此版本的RBF还未成熟。
社区RBF的开发进度主要包括核心功能与稳定性两个方面。
8.1 社区RBF核心功能开发进度
核心功能分为两个大的汇总, 在V3.2已经近乎实现完成
- (V3.0) 核心功能V1阶段 [HDFS-10467]
- (V3.2) 核心功能V2阶段 [HDFS-12615]
它可以完全取代ViewFS, 那只是它最基本的功能之一, 而且因为它不需要使用新的schema前缀, 业务使用原有hdfs:// 或hdfs:///访问都是正常的.
8.2 社区RBF核心功能开发进度
核心的稳定性有两个主要的汇总JIRA:
- (V3.3) 稳定性V1阶段 [HDFS-13891]
- (完成50%) 稳定性V2阶段 [HDFS-14603]
核心的稳定性问题已经修复, 但是一些进阶功能, 比如跨集群mv/cp的方案, DBMS支持等还未GA. 生产环境需要实际集群测试, 目前运维资料较少, 采用V3.3.x的稳定版为宜.
8.3 结论
需要将hadoop版本升级到hadoop3.3+稳定版本才可以上生产
