【Kafka】 分区和副本 Partition 详解
目录
- 概述
- AR、ISR和OSR
- LEO和HW
- 分区Leader选举
- 分区重新分配
- 自动再均衡
- 修改分区副本
- 分区分配策略
-
- RangeAssignor
- RoundRobinAssignor
- StickyAssignor
- 自定义分配策略
概述
Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。同组分区的不同副本分布在不同的 Broker 上,保存相同的消息(可能有滞后)。
副本有两种类型:
- leader 副本:负责处理读写请求,每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。
- follower 副本:follower副本不处理来自客户端的请求,它们唯一的任务就是从leader那里复制消息,保持与首领一致的状态。如果首领发生崩溃,其中的一个跟随者会被提升为新首领。

当集群中的一个broker宕机后系统可以自动故障转移到其他可用的副本上,不会造成数据丢失。
通常,分区比broker多,并且Leader分区在broker之间平均分配。
AR、ISR和OSR
分区的所有副本统称为 AR(Assigned Replicas),其中所有与 leader 副本保持一定同步的副本(包括 leader 副本在内)组成 ISR(In-Sync Replicas),与 leader 同步滞后过多的副本组成 OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。
follower 副本是否与 leader 同步的判断标准取决于 Broker 端参数 replica.lag.time.max.ms(默认为 10 秒),follower 默认每隔 500ms 向 leader fetch 一次数据,只要一个 Follower 副本落后 Leader 副本的时间不连续超过 10 秒,那么 Kafka 就认为该 Follower 副本与 leader 是同步的。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
当 leader 副本所在 Broker 宕机时,Kafka 会借助 ZK 从 follower 副本中选举新的 leader 继续对外提供服务,实现故障的自动转移,保证服务可用。为了使选举的新 leader 和旧 leader 数据尽可能一致,当 leader 副本发生故障时,默认情况下只有在 ISR 集合中的副本才有资格被选举为新的 leader,而在 OSR 集合中的副本则没有任何机会(可通过设置 unclean.leader.election.enable 改变。
当 Kafka 通过多副本机制解决单机故障问题时,同时也带来了多副本间数据同步一致性问题。Kafka 通过高水位更新机制、副本同步机制、 Leader Epoch 等多种措施解决了多副本间数据同步一致性问题,下面我们来依次看下这几大措施。
LEO和HW
参考:https://mp.weixin.qq.com/s/_g11mmmQse6KrkUE8x4abQ
- HW: High Watermark,高水位,表示已经提交(commit)的最大日志偏移量,Kafka 中某条日志“已提交”的意思是 ISR 中所有节点都包含了此条日志,并且消费者只能消费 HW 之前的数据;
- LEO: Log End Offset,表示当前 log 文件中下一条待写入消息的 offset;
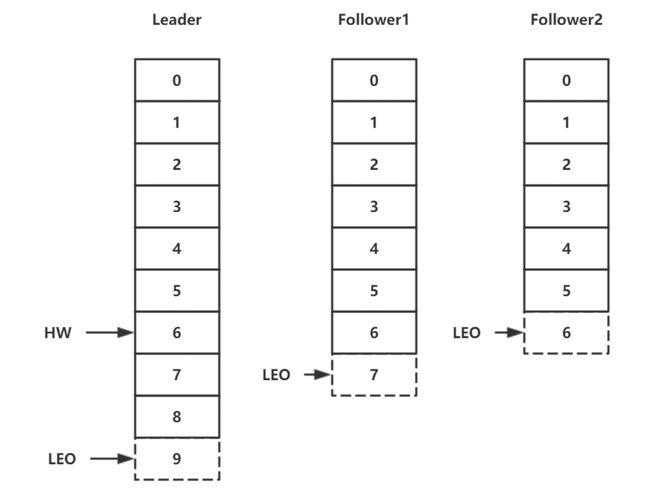
注意:所有副本都有对应的 HW 和 LEO,只不过 Leader 副本比较特殊,Kafka 使用 Leader 副本的高水位来定义所在分区的高水位。换句话说,分区的高水位就是其 Leader 副本的高水位。Leader 副本和 Follower 副本的 HW 有如下特点:
- Leader HW:min(所有副本 LEO),为此 Leader 副本不仅要保存自己的 HW 和 LEO,还要保存 follower 副本的 HW 和 LEO,而 follower 副本只需保存自己的 HW 和 LEO;
- Follower HW:min(follower 自身 LEO,leader HW)。
注意:为方便描述,下面Leader HW简记为HWL,Follower HW简记为HWF,Leader LEO简记为LEOL ,Follower LEO简记为LEOF。
下面演示一次完整的 HW / LEO 更新流程:
- 初始状态
HWL=0,LEOL=0,HWF=0,LEOF=0。
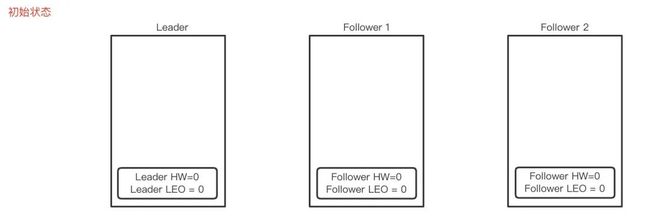
- Follower 第一次 fetch
- Leader收到Producer发来的一条消息完成存储, 更新LEOL=1;
- Follower从Leader fetch数据, Leader收到请求,记录follower的LEOF =0,并且尝试更新HWL =min(全部副本LEO)=0;
- Leader返回HWL=0和LEOL=1给Follower,Follower存储消息并更新LEOF =1, HW=min(LEOF,HWL)=0。
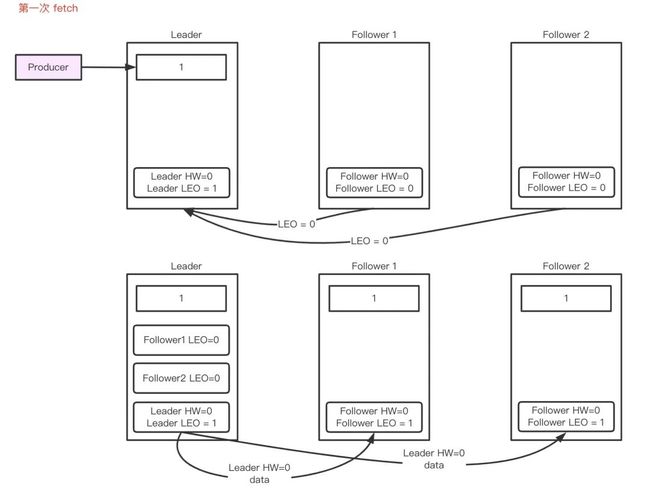
- Follower 第二次 fetch
- Follower再次从Leader fetch数据, Leader收到请求,记录follower的LEOF =1,并且尝试更新HWL =min(全部副本LEO)=1;
- leade返回HWL=1和LEOL=1给Follower,Leader收到请求,更新自己的 HW=min(LEOF,HWL)=1。

上述更新流程中 Follower 和 Leader 的 HW 更新有时间 GAP。如果 Leader 节点在此期间发生故障,则 Follower 的 HW 和 Leader 的 HW 可能会处于不一致状态,如果 Followe 被选为新的 Leader 并且以自己的 HW 为准对外提供服务,则可能带来数据丢失或数据错乱问题。
数据丢失问题

第 1 步:
- 副本 B 作为 leader 收到 producer 的 m2 消息并写入本地文件,等待副本 A 拉取。
- 副本 A 发起消息拉取请求,请求中携带自己的最新的日志 offset(LEO=1),B 收到后更新自己的 HW 为 1,并将 HW=1 的信息以及消息 m2 返回给 A。
- A 收到拉取结果后更新本地的 HW 为 1,并将 m2 写入本地文件。发起新一轮拉取请求(LEO=2),B 收到 A 拉取请求后更新自己的 HW 为 2,没有新数据只将 HW=2 的信息返回给 A,并且回复给 producer 写入成功。此处的状态就是图中第一步的状态。
第 2 步:
此时,如果没有异常,A 会收到 B 的回复,得知目前的 HW 为 2,然后更新自身的 HW 为 2。但在此时 A 重启了,没有来得及收到 B 的回复,此时 B 仍然是 leader。A 重启之后会以 HW 为标准截断自己的日志,因为 A 作为 follower 不知道多出的日志是否是被提交过的,防止数据不一致从而截断多余的数据并尝试从 leader 那里重新同步。
第 3 步:
B 崩溃了,min.isr 设置的是 1,所以 zookeeper 会从 ISR 中再选择一个作为 leader,也就是 A,但是 A 的数据不是完整的,从而出现了数据丢失现象。
问题在哪里?在于 A 重启之后以 HW 为标准截断了多余的日志。不截断行不行?不行,因为这个日志可能没被提交过(也就是没有被 ISR 中的所有节点写入过),如果保留会导致日志错乱。
数据错乱问题
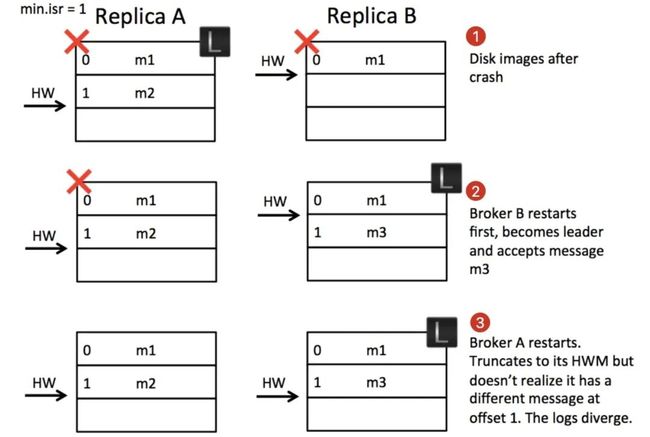
在分析日志错乱的问题之前,我们需要了解到 kafka 的副本可靠性保证有一个前提:在 ISR 中至少有一个节点。如果节点均宕机的情况下,是不保证可靠性的,在这种情况会出现数据丢失,数据丢失是可接受的。这里我们分析的问题比数据丢失更加槽糕,会引发日志错乱甚至导致整个系统异常,而这是不可接受的。
第 1 步:
- A 和 B 均为 ISR 中的节点。副本 A 作为 leader,收到 producer 的消息 m2 的请求后写入 PageCache 并在某个时刻刷新到本地磁盘。
- **副本 B 拉取到 m2 后写入 PageCage 后(尚未刷盘)**再次去 A 中拉取新消息并告知 A 自己的 LEO=2,A 收到更新自己的 HW 为 1 并回复给 producer 成功。
- 此时 A 和 B 同时宕机,B 的 m2 由于尚未刷盘,所以 m2 消息丢失。此时的状态就是第 1 步的状态。
第 2 步:
由于 A 和 B 均宕机,而 min.isr=1 并且 unclean.leader.election.enable=true(关闭 unclean 选择策略),所以 Kafka 会等到第一个 ISR 中的节点恢复并选为 leader,这里不幸的是 B 被选为 leader,而且还接收到 producer 发来的新消息 m3。注意,这里丢失 m2 消息是可接受的,毕竟所有节点都宕机了。
第 3 步:
A 恢复重启后发现自己是 follower,而且 HW 为 2,并没有多余的数据需要截断,所以开始和 B 进行新一轮的同步。但此时 A 和 B 均没有意识到,offset 为 1 的消息不一致了。
问题在哪里?在于日志的写入是异步的,上面也提到 Kafka 的副本策略的一个设计是消息的持久化是异步的,这就会导致在场景二的情况下被选出的 leader 不一定包含所有数据,从而引发日志错乱的问题。
Leader Epoch
为了解决上述缺陷,Kafka 引入了 Leader Epoch 的概念。leader epoch 和 raft 中的任期号的概念很类似,每次重新选择 leader 的时候,用一个严格单调递增的 id 来标志,可以让所有 follower 意识到 leader 的变化。而 follower 也不再以 HW 为准,每次奔溃重启后都需要去 leader 那边确认下当前 leader 的日志是从哪个 offset 开始的。下面看下 Leader Epoch 是如何解决上面两个问题的。
数据丢失解决
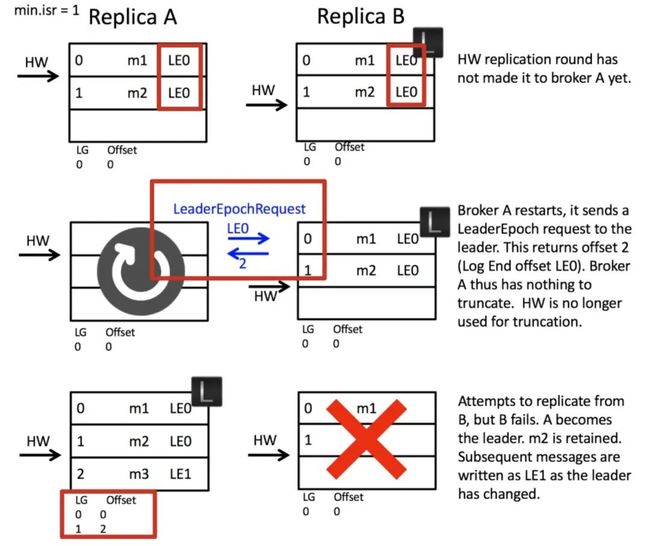
这里的关键点在于副本 A 重启后作为 follower,不是忙着以 HW 为准截断自己的日志,而是先发起 LeaderEpochRequest 询问副本 B 第 0 代的最新的偏移量是多少,副本 B 会返回自己的 LEO 为 2 给副本 A,A 此时就知道消息 m2 不能被截断,所以 m2 得到了保留。当 A 选为 leader 的时候就保留了所有已提交的日志,日志丢失的问题得到解决。
如果发起 LeaderEpochRequest 的时候就已经挂了怎么办?这种场景下,不会出现日志丢失,因为副本 A 被选为 leader 后不会截断自己的日志,日志截断只会发生在 follower 身上。
数据错乱解决
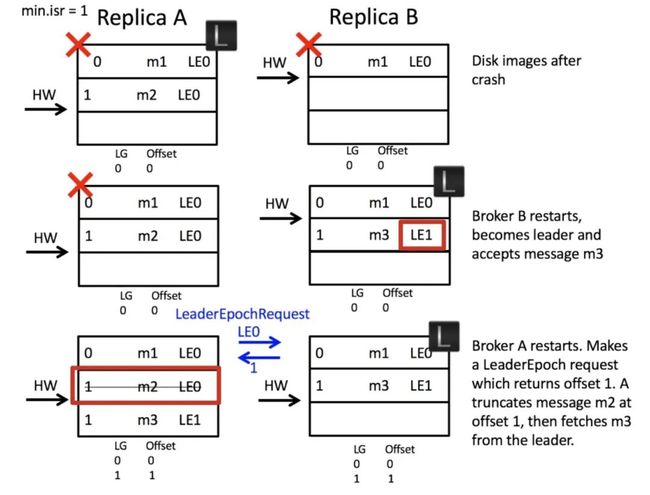
这里的关键点还是在第 3 步,副本 A 重启作为 follower 的第一步还是需要发起 LeaderEpochRequest 询问 leader 当前第 0 代最新的偏移量是多少,由于副本 B 已经经过换代,所以会返回给 A 第 1 代的起始偏移(也就是 1),A 发现冲突后会截断自己偏移量为 1 的日志,并重新开始和 leader 同步。副本 A 和副本 B 的日志达到了一致,解决了日志错乱。
小结
Broker 接收到消息后只是将数据写入 PageCache 后便认为消息已写入成功,但是,通过副本机制并结合 ACK 策略可以大概率规避单机宕机带来的数据丢失问题,并通过 HW、副本同步机制、 Leader Epoch 等多种措施解决了多副本间数据同步一致性问题,最终实现了 Broker 数据的可靠持久化。
分区Leader选举
Leader副本和Follower副本之间的关系并不是固定不变的,在Leader所在的broker发生故障的时候,就需要进行分区的Leader副本和Follower副本之间的切换,需要选举Leader副本。
如何选举?
前面说到只有那些跟Leader保持同步的Follower也就是ISR才应该被选作新的Leader。
如果某个分区的Leader不可用,Kafka就会从ISR集合中选择一个副本作为新的Leader。
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。
假设某个topic有N+1个副本,kafka可以容忍N个服务器不可用。
为什么不用少数服从多数的方法?
少数服从多数是一种比较常见的一致性算发和Leader选举法。它的含义是只有超过半数的副本同步了,系统才会认为数据已同步;选择Leader时也是从超过半数的同步的副本中选择。
这种算法需要较高的冗余度,跟Kafka比起来,浪费资源。譬如只允许一台机器失败,需要有三个副本;而如果只容忍两台机器失败,则需要五个副本。而kafka的ISR集合方法,分别只需要两个和三个副本。
如果所有的ISR副本都失败了怎么办?
此时有两种方法可选,
- 等待ISR集合中的副本复活
- 选择任何一个立即可用的副本,而这个副本不一定是在ISR集合中。需要设置
unclean.leader.election.enable=true
这两种方法各有利弊,实际生产中按需选择。如果要等待ISR副本复活,虽然可以保证一致性,但可能需要很长时间。而如果选择立即可用的副本,则很可能该副本并不一致
总结:
Kafka中Leader分区选举,通过维护一个动态变化的ISR集合来实现,一旦Leader分区丢掉,则从ISR中随机挑选一个副本做新的Leader分区。
如果ISR中的副本都丢失了,则:
- 可以等待ISR中的副本任何一个恢复,接着对外提供服务,需要时间等待。
- 从OSR中选出一个副本做Leader副本,此时会造成数据丢失
分区重新分配
向已经部署好的Kafka集群里面添加机器,我们需要从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。
问题:新添加的Kafka节点并不会自动地分配数据,无法分担集群的负载,除非我们新建一个topic。需要手动将部分分区移到新添加的Kafka节点上。
使用Kafka自带的 kafka-reassign- partitions.sh 工具来重新分布分区。该工具有三种使用模式:
- generate模式,给定需要重新分配的Topic,自动生成reassign plan(并不执行)
- execute模式,根据指定的reassign plan重新分配Partition
- verify模式,验证重新分配Partition是否成功
使用前我们先查看当前的分区分配:
kafka-topics.sh --zookeeper node1:2181/myKafka -- describe --topic tp_re_01
Topic:tp_re_01 PartitionCount:5 ReplicationFactor:1 Configs:
Topic: tp_re_01 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 3 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 4 Leader: 0 Replicas: 0 Isr: 0 1234567
然后加入我们已经新加了一个broker。
然后按照要求定义一个文件,里面说明哪些topic需要重新分区,例如:
[root@node1 ~] cat topics-to-move.json
{
"topics": [
{ "topic":"tp_re_01" }
],
"version":1
}
然后使用 kafka-reassign-partitions.sh 工具生成reassign plan
kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka - -topics-to-move-json-file topics-to-move.json --broker-list "0,1" --generate
Current partition replica assignment {"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas": [0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration {"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas": [1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas": [1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas": [0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration下面生成的就是将分区重新分布到broker 1上的结果。我们将这些内容保存到名为result.json文件里面(文件名不重要,文件格式也不一定要以json为结尾,只要保证内容是json即可),然后执行这些reassign plan:
kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka - -reassignment-json-file topics-to-execute.json --execute
Current partition replica assignment {"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas": [0],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback Successfully started reassignment of partitions.
这样Kafka就在执行reassign plan,我们可以校验reassign plan是否执行完成:
kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka - -reassignment-json-file topics-to-execute.json --verify
Status of partition reassignment:
Reassignment of partition tp_re_01-1 completed successfully
Reassignment of partition tp_re_01-4 completed successfully
Reassignment of partition tp_re_01-2 completed successfully
Reassignment of partition tp_re_01-3 completed successfully
Reassignment of partition tp_re_01-0 completed successfully
查看主题的细节:

使用 kafka-reassign-partitions.sh 工具生成的reassign plan只是一个建议,方便大家而已。其实我们自己完全可以编辑一个reassign plan,然后执行它,如下:
{
"version": 1,
"partitions": [{
"topic": "tp_re_01",
"partition": 4,
"replicas": [1],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 1,
"replicas": [0],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 2,
"replicas": [0],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 3,
"replicas": [1],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 0,
"replicas": [0],
"log_dirs": ["any"]
}]
}
将上面的json数据文件保存到my-topics-to-execute.json文件中,然后也是执行它:
kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file my-topics-to-execute.json --execute
自动再均衡
我们可以在新建主题的时候,手动指定主题各个Leader分区以及Follower分区的分配情况,即什么分区副本在哪个broker节点上。
随着系统的运行,broker的宕机重启,会引发Leader分区和Follower分区的角色转换,最后可能Leader大部分都集中在少数几台broker上,由于Leader负责客户端的读写操作,此时集中Leader分区的少数几台服务器的网络I/O,CPU,以及内存都会很紧张。
Leader和Follower的角色转换会引起Leader副本在集群中分布的不均衡,此时我们需要一种手段,让Leader的分布重新恢复到一个均衡的状态。
Kafka提供的自动再均衡脚本:kafka-preferred-replica-election.sh
先看介绍:

该工具会让每个分区的Leader副本分配在合适的位置,让Leader分区和Follower分区在服务器之间均衡分配。
如果该脚本仅指定zookeeper地址,则会对集群中所有的主题进行操作,自动再平衡。
具体操作:
- 执行脚本创建topic:
kafka-topics.sh --zookeeper node1:2181/myKafka --create -- topic tp_demo_03 --replica-assignment "0:1,1:0,0:1"
上述脚本执行的结果是:创建了主题tp_demo_03,有三个分区,每个分区两个副本,Leader副本在列表中第一个指定的brokerId上,Follower副本在随后指定的brokerId上。
- 创建preferred-replica.json,内容如下:
{
"partitions": [{
"topic": "tp_demo_03",
"partition": 0
}, {
"topic": "tp_demo_03",
"partition": 1
}, {
"topic": "tp_demo_03",
"partition": 2
}]
}
- 执行操作:
kafka-preferred-replica-election.sh --zookeeper node1:2181/myKafka --path-to-json-file preferred-replicas.json
Created preferred replica election path with
{"version":1,"partitions":[{"topic":"tp_demo_03","partition":0}, {"topic":"tp_demo_03","partition":1}, {"topic":"tp_demo_03","partition":2}]}
Successfully started preferred replica election for partitions Set(tp_demo_03-0, tp_demo_03-1, tp_demo_03-2)
- 查看操作的结果:
kafka-topics.sh --zookeeper node1:2181/myKafka -- describe --topic tp_demo_03
恢复到最初的分配情况。
之所以是这样的分配,是因为我们在创建主题的时候:
--replica-assignment "0:1,1:0,0:1"
在逗号分割的每个数值对中排在前面的是Leader分区,后面的是副本分区。那么所谓的preferred replica,就是排在前面的数字就是Leader副本应该在的brokerId。
修改分区副本
实际项目中,我们可能由于主题的副本因子(每个分区的副本数量)设置的问题,需要重新设置副本因子或者由于集群的扩展,需要重新设置副本因子。topic一旦使用又不能轻易删除重建,因此动态增加副本因子就成为最终的选择。
说明:kafka 1.0版本配置文件默认没有default.replication.factor=x, 因此如果创建topic时,不指定–replication-factor , 默认副本因子为1. 我们可以在自己的server.properties中配置上常用的副本因子,省去手动调整。例如设置default.replication.factor=3, 详细内容可参考官方文档https://kafka.apache.org/documentation/#replication
原因分析:
假设我们有2个kafka broker分别broker0,broker1。
-
当我们创建的topic有2个分区partition时并且replication-factor为1,基本上一个broker上一个分区。当一个broker宕机了,该topic就无法使用了,因为两个个分区只有一个能用。
-
当我们创建的topic有3个分区partition时并且replication-factor为2时,可能分区数据分布情况是
broker0, partiton0,partiton1,partiton2,
broker1, partiton1,partiton0,partiton2,
每个分区有一个副本,当其中一个broker宕机了,kafka集群还能完整凑出该topic的两个分区,例如当broker0宕机了,可以通过broker1组合出topic的两个分区。
步骤:
- 创建主题:
kafka-topics.sh --zookeeper node1:2181/myKafka -- create --topic tp_re_02 --partitions 3 --replication-factor 1
- 查看主题细节:
kafka-topics.sh --zookeeper node1:2181/myKafka -- describe --topic tp_re_02
Topic:tp_re_02 PartitionCount:3 ReplicationFactor:1 Configs:
Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
- 修改副本因子:
使用 kafka-reassign-partitions.sh 修改副本因子。
创建increment-replication-factor.json:
{
"version": 1,
"partitions": [{
"topic": "tp_re_02",
"partition": 0,
"replicas": [0, 1]
}, {
"topic": "tp_re_02",
"partition": 1,
"replicas": [0, 1]
}, {
"topic": "tp_re_02",
"partition": 2,
"replicas": [1, 0]
}]
}
- 执行分配:
kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file increase-replication- factor.json --execute
- 查看主题细节
kafka-topics.sh --zookeeper node1:2181/myKafka -- describe --topic tp_re_02
Topic:tp_re_02 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1,0
Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
结束
分区分配策略
在Kafka中,每个Topic会包含多个分区,默认情况下一个分区只能被一个消费组下面的一个消费者消费,这里就产生了分区分配的问题。Kafka中提供了多重分区分配算法(PartitionAssignor)的实现:RangeAssignor、RoundRobinAssignor、StickyAssignor。
PartitionAssignor接口用于用户定义实现分区分配算法,以实现Consumer之间的分区分配。
消费组的成员订阅它们感兴趣的Topic并将这种订阅关系传递给作为订阅组协调者的Broker。协调者选择其中的一个消费者来执行这个消费组的分区分配并将分配结果转发给消费组内所有的消费者。
RangeAssignor
Kafka默认采用RangeAssignor的分配算法。
RangeAssignor对每个Topic进行独立的分区分配。对于每一个Topic,首先对分区按照分区ID进行数值排序,然后订阅这个Topic的消费组的消费者再进行字典排序,之后尽量均衡的将分区分配给消费者。这里只能是尽量均衡,因为分区数可能无法被消费者数量整除,那么有一些消费者就会多分配到一些分区。

大致算法如下:
assign(topic, consumers) {
// 对分区和Consumer进行排序
List<Partition> partitions = topic.getPartitions();
sort(partitions);
sort(consumers);
// 计算每个Consumer分配的分区数
int numPartitionsPerConsumer = partition.size() / consumers.size();
// 额外有一些Consumer会多分配到分区
int consumersWithExtraPartition = partition.size() % consumers.size();
// 计算分配结果
for (int i = 0, n = consumers.size(); i < n; i++) {
// 第i个Consumer分配到的分区的index
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
// 第i个Consumer分配到的分区数
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
// 分装分配结果
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
RangeAssignor策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个Topic,RangeAssignor策略会将消费组内所有订阅这个Topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
这种分配方式明显的一个问题是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来越严重,比如上图中4个分区3个消费者的场景,C0会多分配一个分区。如果此时再订阅一个分区数为4的Topic,那么C0又会比C1、C2多分配一个分区,这样C0总共就比C1、C2多分配两个分区了,而且随着Topic的增加,这个情况会越来越严重。
字典序靠前的消费组中的消费者比较“贪婪”。

RoundRobinAssignor
RoundRobinAssignor的分配策略是将消费组内订阅的所有Topic的分区及所有消费者进行排序后尽量均衡的分配(RangeAssignor是针对单个Topic的分区进行排序分配的)。
如果消费组内,消费者订阅的Topic列表是相同的(每个消费者都订阅了相同的Topic),那么分配结果是尽量均衡的(消费者之间分配到的分区数的差值不会超过1)。
如果订阅的Topic列表是不同的,那么分配结果是不保证“尽量均衡”的,因为某些消费者不参与一些Topic的分配。

相对于RangeAssignor,在订阅多个Topic的情况下,RoundRobinAssignor的方式能消费者之间尽量均衡的分配到分区(分配到的分区数的差值不会超过1——RangeAssignor的分配策略可能随着订阅的Topic越来越多,差值越来越大)。
对于消费组内消费者订阅Topic不一致的情况:假设有两个个消费者分别为C0和C1,有2个TopicT1、T2,分别拥有3和2个分区,并且C0订阅T1和T2,C1订阅T2,那么RoundRobinAssignor的分配结果如下:

看上去分配已经尽量的保证均衡了,不过可以发现C0承担了4个分区的消费而C1订阅了T2一个分区,是不是把T2P0交给C1消费能更加的均衡呢?
StickyAssignor
尽管RoundRobinAssignor已经在RangeAssignor上做了一些优化来更均衡的分配分区,但是在一些情况下依旧会产生严重的分配偏差,比如消费组中订阅的Topic列表不相同的情况下。
更核心的问题是无论是RangeAssignor,还是RoundRobinAssignor,当前的分区分配算法都没有考虑上一次的分配结果。显然,在执行一次新的分配之前,如果能考虑到上一次分配的结果,尽量少的调整分区分配的变动,显然是能节省很多开销的
从字面意义上看,Sticky是“粘性的”,可以理解为分配结果是带“粘性的”:
- 分区的分配尽量的均衡
- 每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出StickyAssignor特性的。
我们先来看预期分配的结构,后续再具体分析StickyAssignor的算法实现。
例如:
- 有3个Consumer:C0、C1、C2
- 有4个Topic:T0、T1、T2、T3,每个Topic有2个分区
- 所有Consumer都订阅了这4个分区
StickyAssignor的分配结果如下图所示(增加RoundRobinAssignor分配作为对比):

如果消费者1宕机,则按照RoundRobin的方式分配,打乱从新来过,轮询分配,结果如下:
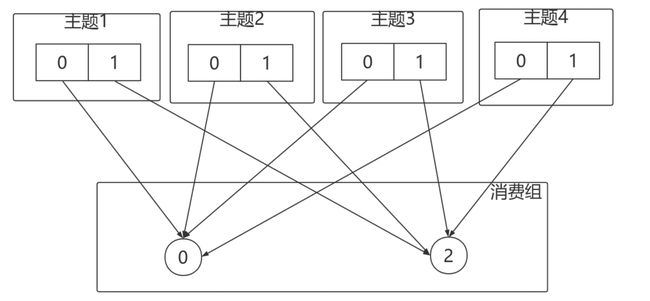
按照Sticky的方式:仅对消费者1分配的分区进行重分配,红线部分。最终达到均衡的目的。
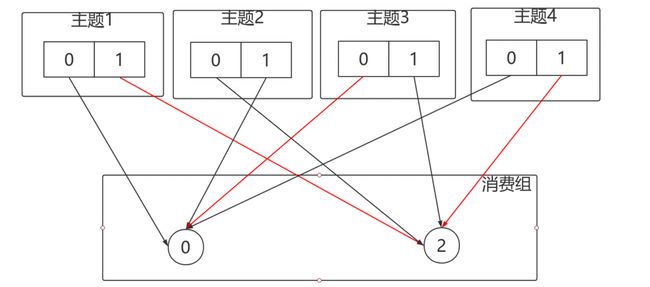
再举一个例子:
- 有3个Consumer:C0、C1、C2
- 3个Topic:T0、T1、T2,它们分别有1、2、3个分区
- C0订阅T0;C1订阅T0、T1;C2订阅T0、T1、T2
分配结果如下图所示:
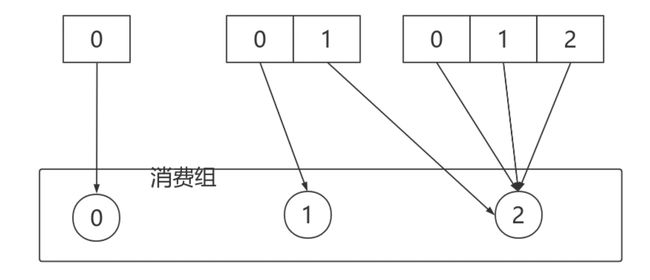
消费者0下线,则按照RoundRobin的方式分配如下:

按照Sticky方式分配分区,仅仅需要动的就是红线部分,其他部分不动:

自定义分配策略
自定义的分配策略必须要实现org.apache.kafka.clients.consumer.internals.PartitionAssignor接口。PartitionAssignor接口的定义如下:
Subscription subscription(Set<String> topics);
String name();
Map<String, Assignment> assign(Cluster metadata, Map<String, Subscription> subscriptions); void onAssignment(Assignment assignment);
void onAssignment(Assignment assignment);
class Subscription {
private final List<String> topics;
private final ByteBuffer userData;
}
class Assignment {
private final List<TopicPartition> partitions;
private final ByteBuffer userData;
}
PartitionAssignor接口中定义了两个内部类:Subscription和Assignment。
Subscription类用来表示消费者的订阅信息,类中有两个属性:topics和userData,分别表示消费者所订阅topic列表和用户自定义信息。PartitionAssignor接口通过subscription()方法来设置消费者自身相关的Subscription信息,注意到此方法中只有一个参数topics,与Subscription类中的topics的相互呼应,但是并没有有关userData的参数体现。为了增强用户对分配结果的控制,可以在subscription()方法内部添加一些影响分配的用户自定义信息赋予userData,比如:权重、ip地址、host或者机架(rack)等等。
再来说一下Assignment类,它是用来表示分配结果信息的,类中也有两个属性:partitions和userData,分别表示所分配到的分区集合和用户自定义的数据。可以通过PartitionAssignor接口中的onAssignment()方法是在每个消费者收到消费组leader分配结果时的回调函数,例如在StickyAssignor策略中就是通过这个方法保存当前的分配方案,以备在下次消费组再平衡(rebalance)时可以提供分配参考依据。
接口中的name()方法用来提供分配策略的名称,对于Kafka提供的3种分配策略而言,RangeAssignor对应的protocol_name为“range”,RoundRobinAssignor对应的protocol_name为“roundrobin”,StickyAssignor对应的protocol_name为“sticky”,所以自定义的分配策略中要注意命名的时候不要与已存在的分配策略发生冲突。这个命名用来标识分配策略的名称,在后面所描述的加入消费组以及选举消费组leader的时候会有涉及。
真正的分区分配方案的实现是在assign()方法中,方法中的参数metadata表示集群的元数据信息,而subscriptions表示消费组内各个消费者成员的订阅信息,最终方法返回各个消费者的分配信息。
Kafka 2.8之后中,PartitionAssignor接口和相关的类已经被移除了。
可以使用ConsumerRebalanceListener接口。这个接口提供了onPartitionsRevoked和onPartitionsAssigned两个方法,你可以在这些方法中进行自定义的逻辑处理。
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 当分区被回收时的逻辑处理
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 当分区被分配时的逻辑处理
}
});