Tarjan算法超超超详解(ACM/OI)(强连通分量/缩点)(图论)(C++)
本文将持续更新。
I 前置芝士:深度优先搜索与边的分类
首先我们来写一段基本的DFS算法(采用链式前向星存图):
bool vis[MAXN];
void dfs(int u)
{
vis[u] = true;
for(int e = first[u]; e; e = nxt[e])
{
// 遍历连接u的每条边
int v = go[e];
if(!vis[v]) dfs(v);
// 如果没有访问过就往下继续搜
}
}这段代码我们再熟悉不过了。接下来我们要引入一个叫做时间戳(也叫dfs序)的概念,它代表了每个节点被第一次访问的时间(相邻两个节点的访问时间是连续的)。我们用tot变量作为当前时间,每次访问一个节点tot++。越先访问的节点时间戳越小,越后访问的节点时间戳越大。在下面的代码中,我们用dfn(dfs number)数组作为每个点的时间戳,这样就可以取代vis数组来判断某个点有没有被访问过。具体来说,若没有被访问过,则该点的dfn为0。
int dfn[MAXN], tot = 0;
void dfs(int u)
{
dfn[u] = ++tot; // 时间戳,代表点u是第tot个被访问的节点
for(int e = first[u]; e; e = nxt[e])
{
// 遍历连接u的每条边
int v = go[e];
if(!dfn[v]) dfs(v);
// 如果没有访问过就往下继续搜
}
}再强调一遍:dfn[]随访问顺序严格单调递增。dfn[]数组的某些性质可以为我们寻找强连通分量奠定基础。
在介绍如何寻找强连通分量之前,我们必须利用dfs对图的边进行分类。图的边分为4类:
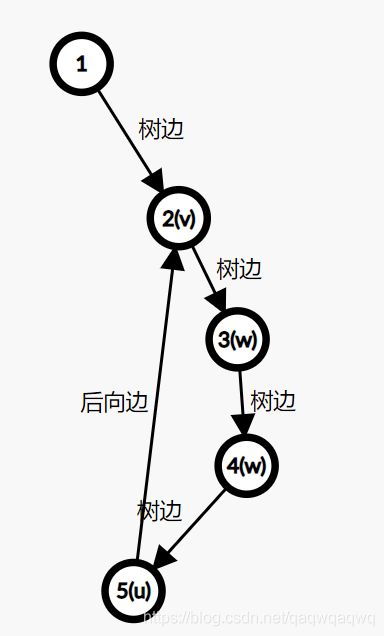
(1)树边。指深度优先搜索树上的边。具体来说,如果上面的代码中这句话
if(!dfn[v]) dfs(v);的if条件成立,即v没有被访问过、接下来要从v开始搜,那么边u→v就被称为树边。
(2)后向边。是指将节点u连接到其在深度优先搜索树中的祖先节点v的边u→v。在上面的代码中,我们并不能根据条件判断一条边是否一定是后向边,不过我们知道一定有
dfn[v] != 0 && dfn[v] <= dfn[u]。即:v被访问过,且v比u先被访问。自循环(u→u)也被认为是后向边(所以是小于等于)。
(3)前向边。是指将节点u连接到其在深度优先搜索树中的后代节点v的边u→v。在上面的代码中,我们也不能根据条件判断一条边是不是后向边,不过我们知道一定有
dfn[v] != 0 && dfn[v] > dfn[u]。即:v被访问过,且v比u后被访问。举个例子:
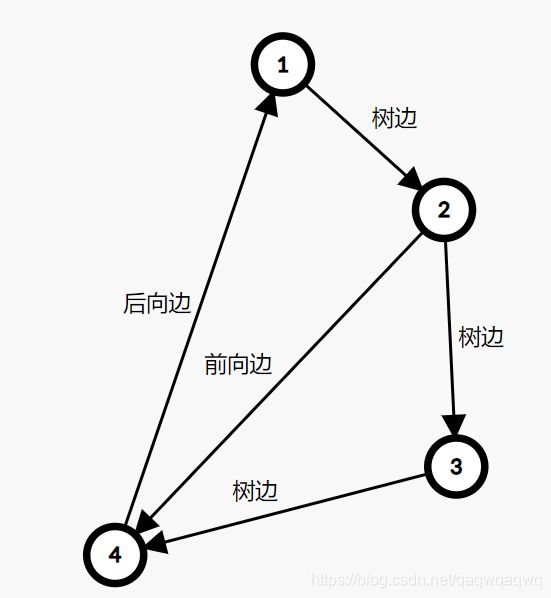
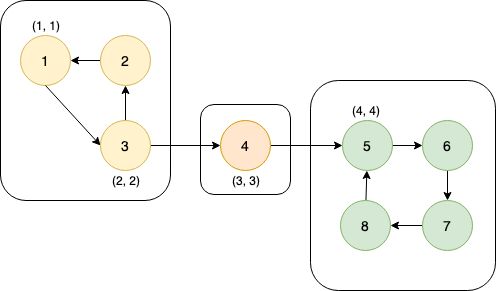
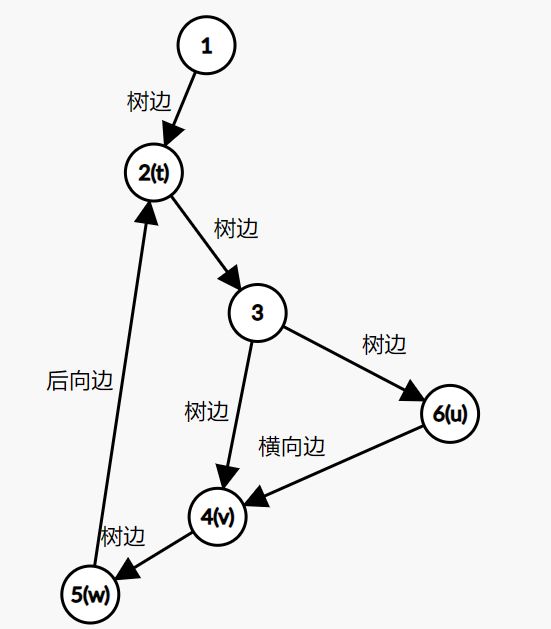
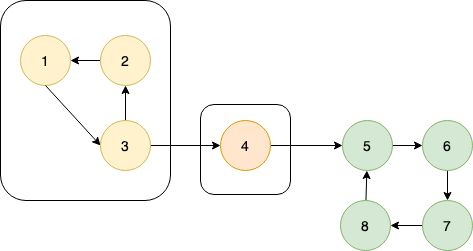
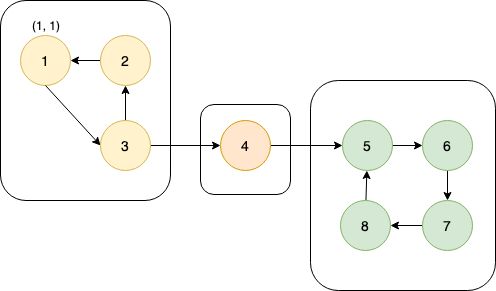
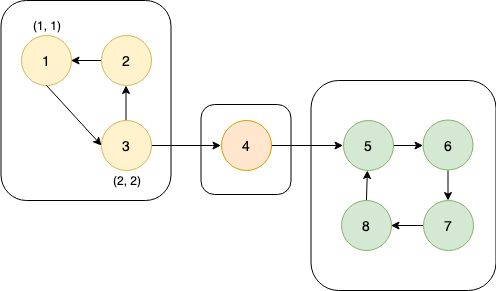
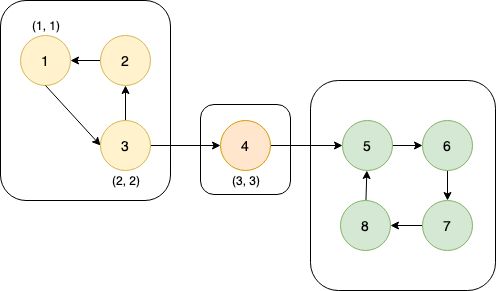
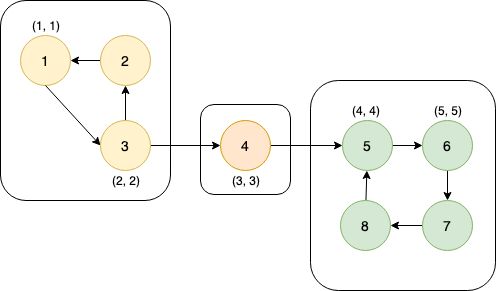
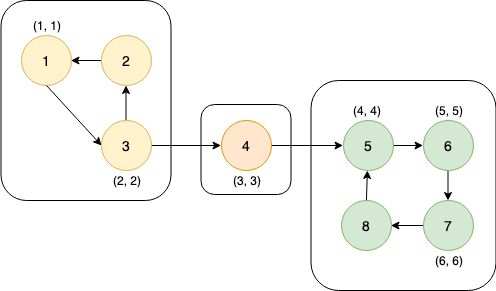
这张图中的搜索顺序为1→2→3→4。节点1、2、3、4的时间戳(dfn)分别为1、2、3、4。在考察边2→4的时候,由于dfn[4]>dfn[2],所以2→4是前向边。又dfn[1] (4)横向边。所有其他边都称为横向边。 其中6→3是横向边(属于在同一棵树上的),因为2→3→4和2→5→6→7分别是树上的两条链,6和3互相不是对方的祖先。 对于横向边,我们有如下性质: 定理1 横向边u→v满足dfn[u]>dfn[v]。 证明:根据深度优先搜索的策略,访问到结点u之后,接下来会访问它所有邻接的未被访问的结点,u到所有这些结点的边都是树边。因为此处u→v不是树边,而是横向边,所以在访问u时v一定已被访问过。根据dfn[]随访问顺序严格单调递增,显然有dfn[u]>dfn[v]。 思考题:如何证明所有的边必属于这4类中的某一类? 定义 在有向图G中,如果两个顶点u,v间有一条从u到v的有向路径,同时还有一条从v到u的有向路径,则称两个顶点强连通。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向非强连通图的极大强连通子图,称为强连通分量(Strongly Connected Components, SCC)。 换句话说,一个强连通分量中的每两个点可以互相到达,且这个强连通分量所包含的的节点数尽可能大。例如:(下图中被框起来的子图就是强连通分量,共三个): 显然,环是一个强连通分量的子图。例如上面的1→2→3→1和5→6→7→8→5。不过,强连通分量不一定是环,也有可能是几个环并起来的,还可能只含有一个节点。 定理2 若存在后向边u→v,则u、v在同一个强连通分量中。 证明:由u→v知v是u的祖先节点,所以路径v→u存在, 且是深度优先搜索树上的一条链。故v→u→v构成一个环。因此u、v在同一个强连通分量中。 定理3表明后向边是构成强连通分量的关键因素。但对于前向边u→v而言,其发挥的作用和树边是相同的——反正不管走树边还是前向边,都可以从u到v,但还是不知道能否从v到u。 那么横向边发挥什么作用呢?设u→v是横向边,如果存在v的一个(在搜索树中)的子节点w,使得w有一条到u、v公共祖先t的后向边,那么u就被接入到了t、v、w所在的强连通分量中,u→v→w→t→u构成个一个环。如下图所示。 总结一下:图的边分为四类:树边、后向边、前向边、横向边。其中,前向边对于我们判断SCC(强连通分量)没有任何帮助,因此我们忽略它们,只考察树边、后向边和横向边。 我们先考虑怎么处理后向边。那么我们怎么判断一条边是是不是后向边呢?我们看到,后向边u→v满足dfn[v]≤dfn[u],同时,横向边也满足dfn[v]≤dfn[u]。因此我们不能简单地根据dfn数组来区分这两种边。那么如何区分呢?我们考虑维护一个栈:栈中的元素是当前搜索树上的点。显然,如果一条边u→v是后向边,那么当我们在访问u时会发现v已经在栈中。然后,如果dfn[v] 所以知道u→v是后向边之后,我们要做什么呢(代码中的DO_SOMETHING)?此时,我们希望用一种方法标明,栈中的元素,从v到u,都属于同一个SCC。我们引入low[]数组,low[u]代表包含u的SCC中第一个被搜索到的节点的dfn值,也可以理解为从u出发能回溯到的dfn最小的节点的dfn值。显然,若u→v是一个后向边,那么v是u的祖先,v是v、u所在的SCC中最先被访问到的节点,low[u]=dfn[v]。而且,对于v→u路径(都是树边)上的每一个节点w,有low[w]=dfn[v],因为w和v、u属于同一个SCC。 UPDATE:这里用low[u]=low[v](而不是dfn[v])也完全可以。因为low[v]=dfn[v]成立。不过在用Tarjan算法求割点和桥时可不能这么写~ 举个例子: 从上图可见,2、3、4、5属于同一个SCC,那么它们每个点的low值都应该是dfn[v]=dfn[2]=2。 问题来了:以何种方式更新low数组呢?可不可以把栈中压在v以上的元素的low值全部改为dfn[v]?可以是可以,但是没有必要。我们这么做:在回溯的时候,设当前节点为u,子节点为v,则执行low[u] = min(low[u], low[v])。 不过为什么要用low[u]=min(low[u], low[v]),而不是直接low[u]=low[v]呢?因为若low[v]=dfn[v],low[u]=dfn[u],则可能low[u] 以上结论的代码实现: 现在我们再考虑横向边。我们只需要解决一个问题:在下图中,6(u)→4(v)是横向边,这条边把6(u)接入到了2、3、4、5所在的强连通分量中。但是,在所有2→3→4→5结束以后,2、3、4、5就被弹出栈了,那么在访问6时怎么知道4在2、3、4、5构成的强连通分量中呢?很简单,因为我们欢迎新的结点加入这个强连通分量,所以我们并不会在函数返回时直接把结点弹出栈,而是在整个强连通分量搜索完之后再弹出,这样由横向边引入的结点也可以加入强连通分量了。 那么怎么标记每一个强连通分量呢?我们采用这样的策略:给每个节点“染色”,在同一个SCC中的节点拥有相同的颜色。当然,这个“色”不是真的色,而是一个树。我们用co[]数组来表示:co[u]代表节点u的颜色。第1,2,3,...个SCC对应的颜色分别是1,2,3...。我们用全局变量col来表示当前颜色,也表示已经染了的颜色的个数。当我们发现low[u] == dfn[u]时,代表u是其所在的SCC的最先访问到的节点,它无法访问到dfn更小的结点。此时,栈中压在u以上的所有元素,包括u,构成一个SCC(不在该SCC中的结点都已经弹出去了)。然后将u即压在它上面的所有元素的颜色标记为++col,并弹出。代码如下: 事实上,我们可以不用instack数组,而将else if(instack[v])改为else if(!co[v]),表示v访问过且未被染色。这两种写法是等价的。 注意:Tarjan本质上是dfs,对于不连通的图要用这样的循环: 以确保所有节点都被访问过。 下面的图片展示了Tarjan算法的执行过程。其中每个节点上面标记的数对是(dfn[u], low[u])。 执行Tarjan(1): dfn[1]=low[1]=1,stk.push(1)。 dfn[3]=low[3]=2,stk.push(3)。假设接下来4比2先访问。 依次访问节点4、5、6、7: 接下来访问节点8。发现8→5是后向边,更新low[8]=dfn[5]=4,回溯,使得dfn[7]=dfn[6]=4。 按顺序弹栈。dfn[5]==low[5]==4,故弹出5、6、7、8,作为第一个SCC。再弹出{4},作为第二个SCC。 然后访问节点2,dfn[2]=8,发现2→1为后向边,low[2]=low[1]=1,栈中元素为[1,3,2]: 因为low[1]==dfn[1]==1,故弹出{2,3,1},作为第三个SCC。 至此,算法结束。 这就是Tarjan算法。做一道模板题吧。 洛谷P3387 【模板】缩点 首先Tarjan,然后找出入度为0的SCC开始DFS+DP。 先用Tarjan染色,然后重新建图:每个点的点权变成了之前每个强连通分量的点权之和,新的边是原来的图中横跨两个SCC的边。 我的宗旨是:背板子很容易,但是要真正做到随机应变,还得把算法理解透彻。为什么这么写、怎么证明算法的合理性,都需要思考和学习。 希望本文对大家有所帮助!挺没有存在感的。换句话说,就是一个点不是另一个的点的祖先。这两个点可以在同一棵深度优先搜索树上,也可以在两棵不同的深度优先搜索树上。(一张图可以包含很多个深度优先搜索树。)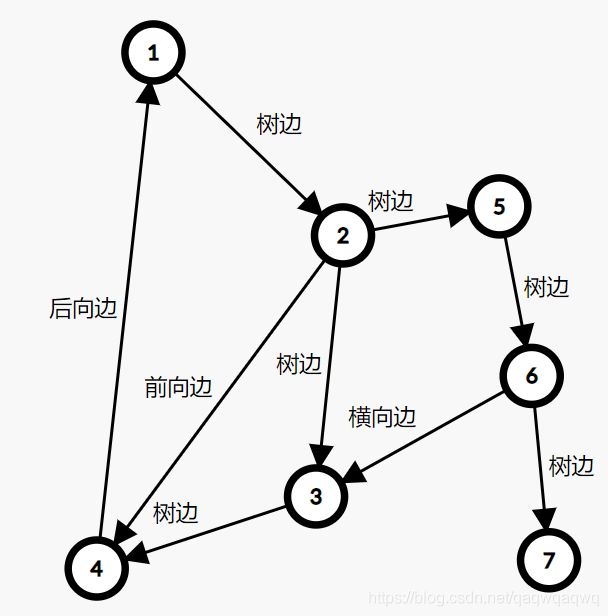
II 强连通分量
III Tarjan算法
#include
#include 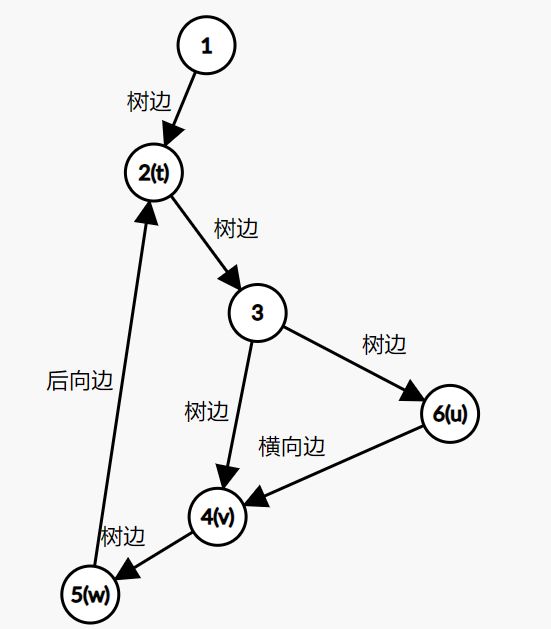
#include for(int i = 1; i <= n; ++i)
if(!dfn[i])
Tarjan(i);
算法示例:
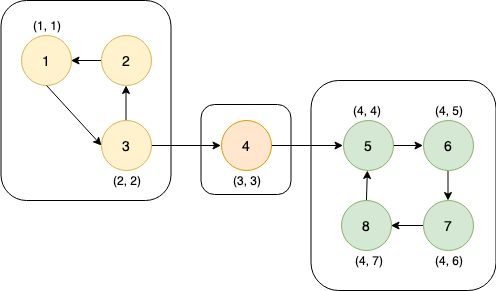
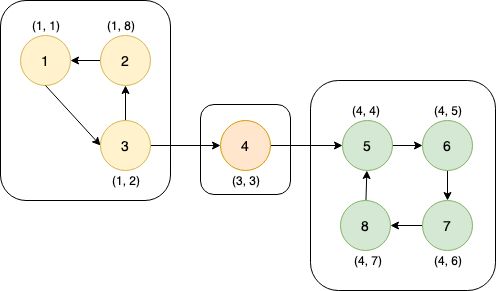
#include