继R绘制列线图之后的模型验证(包括内、外部),适合新手上路(无废话)
前言:经验之谈
继续上次的话题(R语言绘制列线图构建(以二分类Logistic为例)超详细-CSDN博客),基于Logistic回归模型构建的列线图之后,一般都是要进行模型验证的。但模型验证这块最好还是先把理论弄清楚,不然你不知道怎么选择哪些结果、如何解释你的结果。
为什么模型验证?
平常用SPSS分析出来的回归模型包括标准化系数、SE、OR、95%CI以及P值等,这是以表格呈现出来的结果,为实现个体化应用,或者说用可视化的形式呈现出一个患者的结局预测情况,列线图就应运而生,与SPSS里统计出来的结果一致,因此“列线图”本身只是模型的可视化而已,本身并不代表模型,只是习惯性成为“列线图模型”,验证的是“Logistic回归模型”。
因SPSS得出的结果中,只有模型拟合情况(Hosmer and Lemeshow Test 结果框)、模型系数的综合检验(Omnibus Tests of Model Coefficients),以及最重要的纳入最终模型的变量(Variables in the Equation)。以上只能看到这个回归模型构建的怎么样、好不好,但并不涉及验证。
打个比方:你按照图纸参数做出来一件羽绒服,做出来后是不是要测量一下是不是符合图纸上的参数?另外是不是还得穿一穿,看下实际中穿的效果。(这个比喻还是有点欠妥,只是初步的让你了解何为验证)
至于怎么做模型验证这个统计分析呢,SPSS暂时还给不出想要的结果,就得借助其他分析软件,SAS、R倒是可以做,那有需求的同志们就往下看看
模型的验证需要有哪些内容
模型的验证包括内部验证和外部验证两大类,具体呈现情况如下图所示(别着急忙慌的试图理解这个图的全部,先看看后面文字):
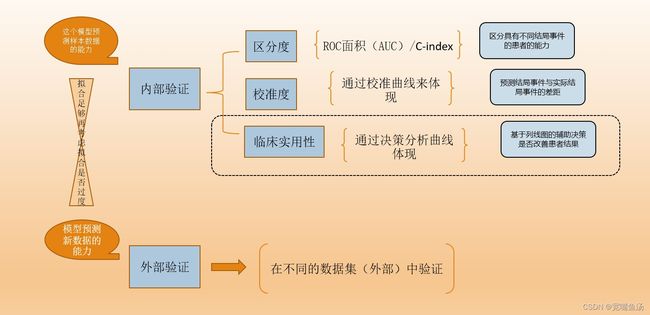
通常来说要有外部验证是最好的,但外部验证的数据集是要重新收集,而不是把内部的随机划分两组充当验证集和训练集,当然,你在一开始就这样分为两组建模倒也没关系。
内部验证其实主要是看区分度+校准度两个,区分度简单来说就是这个模型能正确把人群分为患者/非患者的能力,可以用SPSS里的模型预测概率下的ROC面积表示,也就是AUC,与C指数其实是等价的(注意是等价,不是等于=)。举个例子,模型预测张三发生肺癌的ACU为0.85,C指数是0.75,就是这个模型有85%的把握认为张三发生肺癌的概率是75%。这个其实不用理解的太深,会偏离咱们今天的主题,总之就是要晓得大概得意思。
为了使模型更稳定,伟大的先驱们引入校准度概念,就是说结局实际发生的概率和模型预测出的概率之间的一致性,你叫它一致性、拟合优度都行。这里举例子不太行,要配合图片说明,就是查看图片上的可信区间吧,它测的是绝对误差度量,我还没找到说什么具体的指标来反应这个线。
至于我用虚线圈起来的临床适用/实用性这个评估,靠的是DCA(决策曲线)来体现的,判断基于这个模型评估下的干预决策是否改善患者结局,但这其实属于前瞻性评估,需要把患者随机分组(相当于在影响因素分析基础上,给患者随机分组,一组基于常规措施,一组予以基于风险模型下的干预措施。),然后统计两组的结局。但这不太现实,违背伦理,而且时间线也凑不上,因此引入了DCA决策曲线。因临床上有些疾病无法确诊时,医师要么凭借经验用药,或者说无需治疗,再就是进一步检查,给点小治疗。这就涉及到对患者而言,划不划算的问题。毕竟人生病很少按照教科书或者风险模型上来生病的。更深层次的理解,后续再说。
模型的内部验证命令
① 校准曲线的命令
先来个校准度吧,上校准曲线命令:
Mydata<-read.csv(file.choose() ,header = TRUE,
fileEncoding = "GBK") # 假如数据读取失败,显示多节段字符数串有误
summary(Mydata) ##初步查看我的数据
library(Hmisc) ##加载包
library(rms) ##加载包
dd<-datadist(Mydata) #开始打包数据
options(datadist="dd")
f_lrm <-lrm(GROUP~old+bedridden.time +EN+Probiotics+Albumin
, data=Mydata) #构建回归方程,使用lrm()函数构建二元LR
summary(f_lrm) #查看回归方程的结果
par(mgp=c(2.4,0.3,0),mar=c(6,5,3,3)) ##设置画布的命,里面的画布数字是自己改的
fit2<-lrm(GROUP~old+bedridden.time +EN+Probiotics+Albumin
, data=Mydata,x=TRUE,y=TRUE) #建立校准曲线
cal1<-calibrate(fit2,method = "boot",B=1000)
plot(cal1,xlim=c(0,1.0),ylim=c(0,1.0),
xlab = "Nomogram Predicted 结局", ylab = "Actual 结局") #绘制校准图***如果对前面列线图构建以及csv文件输入字符串等出现bug的,可以看看我之前的文章哟***
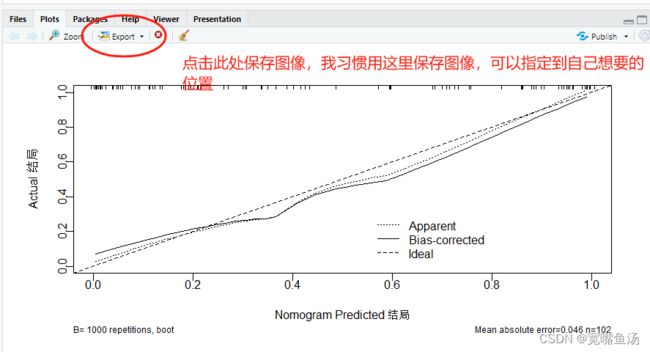
以前是习惯用命了想,就每次跑数据挨个跑,方便我调节画布,把图片大小调节的好看一点。如果是直接跑完数据,使用 dev.off() 命令可以保存,图片是默认存在的工作路径的。怕不好找的话,建议首先把工作路径修改下;不会修改也没关系, 用Export自己保存设置也可以。另外,校准度还可以用Hosmer-Lemeshow 检验(H-L 检验)进行检验,而这个结果可以从SPSS里面得到哦!若得到的P值小于0.05,那说明模型的预测值和真实值之间有差异。我这个校准度其实做的还有粗糙,没有可信区间,下次再补上。
②决策曲线DCA的命令
不是因为其他的,仅是因为这个DCA有图,我就拿来做了,用的是rmda的程序包,命令如下:
install.packages("rmda")#前期准备工作,DCA的决策曲线图命令
library(rmda) #载入
dim(Mydata) # 数据集 初步查看变量数和例数
head(Mydata) # 数据集,一一列出数据集
str(Mydata) # 还是与整理数据集有关
set.seed(123) #不知道
fit3<- decision_curve(GROUP~old+bedridden.time +EN+Probiotics+Albumin
, data=Mydata,study.design = "cohort",
bootstraps =500) # 重抽样次数,另外这是二分类变量,并重新命名为模型fit3
plot_decision_curve(fit3, curve.names = "DCA图",# DCA图是我自己命名的,你们可以自己改
cost.benefit.axis = F, # 是否需要损失:获益比轴
confidence.intervals = "none") # 不画可信区
summary(fit3) # 输出结局
查看下对应的输出结果,在模型fit3输入后会出现这种提示note,这是一个提示信息而不是一个错误。即使你收到这个错误,你的逻辑回归模型仍将被拟合,但可能值得分析一下原始数据框,分析下是不是有什么异常值导致的。我就没管它了。
> set.seed(123) #不知道
> fit3<- decision_curve(GROUP~old+bedridden.time +EN+Probiotics+Albumin
+ , data=Mydata,study.design = "cohort",
+ bootstraps =500) # 重抽样次数,另外这是二分类变量
Note: The data provided is used to both fit a prediction model and to estimate the respective decision curve. This may cause bias in decision curve estimates leading to over-confidence in model performance.
Warning message:
glm.fit:拟合機率算出来是数值零或一 
③临床影响曲线的命令
至此,我们需要的2张图片也出来了,顺便给个临床影响曲线图吧的命令吧,至于后面怎么解释,后面咱们继续看:。
plot_clinical_impact(fit3,
population.size= 1000,
cost.benefit.axis = T,
n.cost.benefits= 8,
col=c('red','blue'),
confidence.intervals= T,
ylim=c(0,1000),
legend.position="topright")
其实,作图还是比较简单的,难的是怎么去理解这些图背后代表的意义。对付下一般的文章,有这些图片+数据说明,可以的了
目前我的这个演示数据中没有验证集,只有训练集,毕竟还没到外部验证这个,外部验证就看后面的,再出一篇相应的文章,顺便把图片的信息量再充实充实,自己反复训练也能对R更加的熟悉了。
喜欢的话,希望点赞收藏+关注,大家一起成长哟