基于大数据平台的kylin安装部署手册

目录
一. 单例Kylin部署
1.环境准备
1.1 软件要求
1.2 硬件要求
1.3 Hadoop环境
1.4 安装前环境检查
1.4.1 开启时钟同步
1.4.2 安装net-tools
1.4.3 检查hbase是否可用
1.4.4 检查hive是否可用(etl用户,控制台输入)
1.4.5 检查Hive配置文件
2. Kylin安装
2.1 配置环境变量
2.2 修改tomcat的配置文件
2.3 检查tomcat依赖包
4.4 检查Kylin权限
4.5 启动前环境检查
3. Kylin的启动和测试
3.1 启动
3.2 测试
3.2.1 重新加载元数据
3.2.2 进行cube构建
4. 安装问题
5. Kylin集群模式部署
5.1 Kylin在线扩展成分布式
5.1.1 修改节点配置文件
5.1.2 启动三台kylin机器
5.1.3 查询测试
6. Nginx安装
6.1 安装编译工具及库文件
6.2 首先要安装 PCRE
6.3 安装 nginx
一. 单例Kylin部署
1.环境准备
1.1 软件要求
| 组件 | 版本 |
| Hadoop | 2.7+, 3.1+ (since v2.5) |
| Hive | 0.13 - 1.2.1+ |
| HBase | 1.1+, 2.0 (since v2.5) |
| Spark (可选) | 2.3.0+ |
| Kafka (可选) | 1.0.0+ (since v2.5) |
| JDK | 1.8+ (since v2.5) |
| OS | Linux only, CentOS 6.5+ or Ubuntu 16.0.4+ |
注:使用的金山大数据平台KDE,上述软件要求达标,如果有发现上述软件没有安装的,请先安装。
1.2 硬件要求
运行 Kylin 的服务器的最低配置:
| 硬件 | 配置 |
| CPU | 4 core |
| 内存 | 16 GB |
| 磁盘 | 100 GB |
对于高负载的场景,建议使用 24 core CPU,64 GB 内存或更高的配置。
注:目前本次安装的配置信息如下,master作为kylin的主节点,单例模式的安装使用master2即可,后面章节中的集群模式安装,再添加两台节点查询节点。查询节点可以使用slave节点,配置较高。如果使用etl节点,后面nginx的配置,server权重要调一下。
1.3 Hadoop环境
Kylin依赖于Hadoop 集群处理大量的数据集。需要准备一个配置好 HDFS,YARN,MapReduce,Hive, HBase,Zookeeper 和其他服务的 Hadoop 集群供 Kylin 运行。部署kylin的节点上 Hive,HBase,HDFS 等命令行已安装好且 client 配置(如 core-site.xml,hive-site.xml,hbase-site.xml及其他)也已经合理的配置且其可以自动和其它节点同步。
运行 Kylin 的 Linux 账户要有访问 Hadoop 集群的权限,包括创建/写入HDFS 文件夹,读写Hive 表,读写HBase 表和提交 MapReduce 任务的权限。
kylin的安装和启动的用户,必须拥有足够的权限,hdfs,hbase,hive,spark权限,增删改查都给,不然安装启动成功后,构建cube可能会报错。
1.4 安装前环境检查
1.4.1 开启时钟同步
检查安装kylin的机器是否开启时钟同步(root用户)
#步骤1:
systemctl status ntpd #查看状态
A、状态为开启,跳过后面的步骤执行下一个环境检查 1.4.2
B、状态为关闭,如下图所示,执行步骤如下步骤
#步骤1: systemctl start ntpd #启动 #步骤2: systemctl enable ntpd #设置开机自启动ntp服务 #步骤3: systemctl status ntpd #再次检查状态为开启即可
'
C、状态为没有安装ntp,如下图所示,
执行如下步骤
#步骤1: su root #切换到root用户安装ntp,输入root密码 #步骤2: sudo yum install ntp #安装ntp,安装完 #步骤3: systemctl start ntpd #启动 #步骤4: systemctl enable ntpd #设置开机自启动ntp服务 #步骤5: systemctl status ntpd #再次检查状态为开启即可
1.4.2 安装net-tools
使用root用户执行
yum install -y net-tools #安装net-tools,否则后面执行./check-env.sh会报错1.4.3 检查hbase是否可用
切换回etl用户
#步骤1:
hbase shell #进入habse,如果需要输入密码,请配置成免密登录
#步骤2:
list #查看没有出错即可,出错请排查后继续
#步骤3:
desc '[namespacename:]tablename' #查看desc命令是否可用1.4.4 检查hive是否可用(etl用户,控制台输入)
#步骤1:
hive #进入hive,如需密码请配置免密
#步骤2:
show databases #查看没有出错即可,出错请排查后继续1.4.5 检查Hive配置文件
检查hive的hive-site.xml是否配置了如下属性,如果没有,添加后重启hive
hive-site.xml添加如下3个property:
hive.security.authorization.sqlstd.confwhitelist.append
mapred.*|hive.*|mapreduce.*|spark.*
hive.security.authorization.sqlstd.confwhitelist
mapred.*|hive.*|mapreduce.*|spark.*
hive.server2.builtin.udf.blacklist
empty
2. Kylin安装
将软件包(直接解压后上传kylin文件夹),利用ftp或者其他工具,上传到etl用户有操作权限的目录。安装目录为/home/etl/kylin。
2.1 配置环境变量
开始配置master2节点的环境变量文件(可以添加在/etc/profile文件,对任意用户生效。本次配置是在etl用户的用户环境变量上,则后续启动和停止都需要利用etl用户操作)
#步骤1:
vi ~/.bashrc #或者vi /etc/profile,修改后要source /etc/profile生效
#步骤2:
export KYLIN_HOME=/home/etl/kylin #~/.bashrc中添加
#步骤3:
:wq #保存退出注意:以上环境变量需要根据实际安装软件包路径添加
2.2 修改tomcat的配置文件
修改tomcat的conf文件夹下的server.xml
#步骤1:
cd /home/etl/kylin/tomcat/conf #进入配置文件目录
#步骤2:
vi server.xml #进入server.xml
#步骤3:注释掉如下属性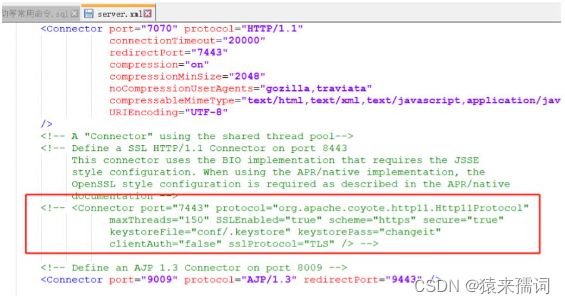
2.3 检查tomcat依赖包
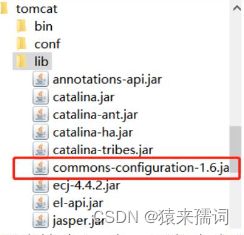
看tomcat的lib文件夹下是否有如下jar包(给的压缩包已经添加该jar包)
 \
\
注意:没有这个jar包,可能会出现启动成功但是无法打开web页面的错误。
4.4 检查Kylin权限
查看kylin的bin、logs等是否具有可执行权限(方便起见,给全部权限)
#步骤1:
cd /home/etl/kylin/ #进入目录
#步骤2:
ll #查看,如果没有可执行权限,修改权限
#步骤3:
chmod -R 777 * #给当前文件夹下的文件所有权限如下所示,没有可执行权限后续执行环节检查的shell会报错

4.5 启动前环境检查
cd /home/etl/kylin/bin #进入目录
./check-env.sh #执行依赖的环境检查,没有输出错误信息即可![]()
3. Kylin的启动和测试
3.1 启动
cd /home/etl/kylin/bin #进入目录
./kylin.sh start #执行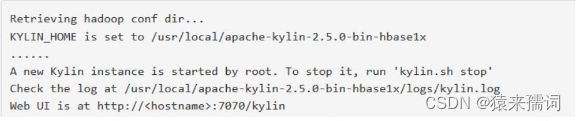
出现如上页面表示启动成功,在页面上输入http://<安装kylin机器的IP>:7070/kylin即可出现登录页面。输入账号:ADMIN 密码:KYLIN
服务器启动,可以通过查看 /home/etl/kylin/logs/kylin.log 获得运行时日志进行启动失败的问题排错。
3.2 测试
测试kylin可用性,导入kylin的测试例子
./kylin.sh stop #在/home/etl/kylin/bin目录下关掉kylin
./sample.sh #执行,看到最后几行如下则成功
hive #进hive
use default #使用default数据库,kylin默认使用default存储
show tables #查看表,出现如下的5张表后表示成功
##kylin_account、kylin_cal_dt、kylin_category_groupings、kylin_country、kylin_sales
./kylin.sh start #启动kylin3.2.1 重新加载元数据
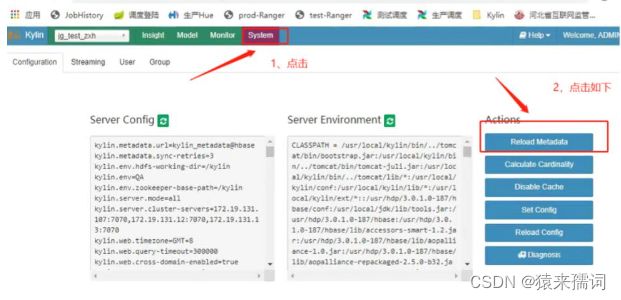 2)选择选择kylin项目learn_kylin项目,点击model,出现如下页面
2)选择选择kylin项目learn_kylin项目,点击model,出现如下页面
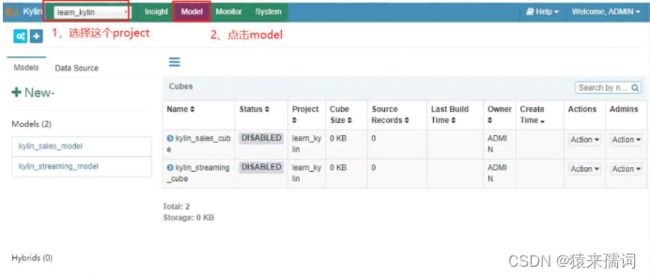
3.2.2 进行cube构建
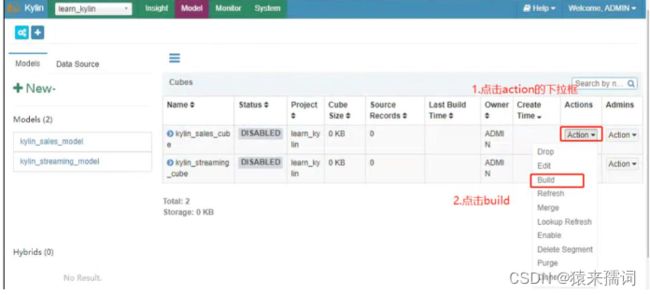
选择构建的表的数据的结束日期,然后点击submit

查看构建的进度,当进度达到100%的时候,表示成功。此处大概至少需要十几二十分钟进行构建。
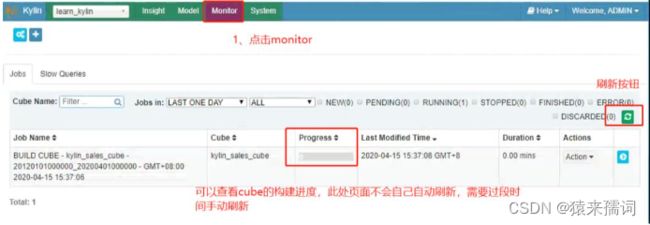
如果此处出现error,可以点击如下页面的按钮查看日志,也可以通过如下页面查看执行到哪个步骤。


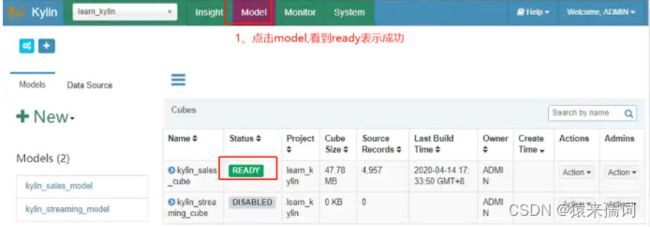
当进度达到100%的时候,点击model查看cube的状态变成了ready
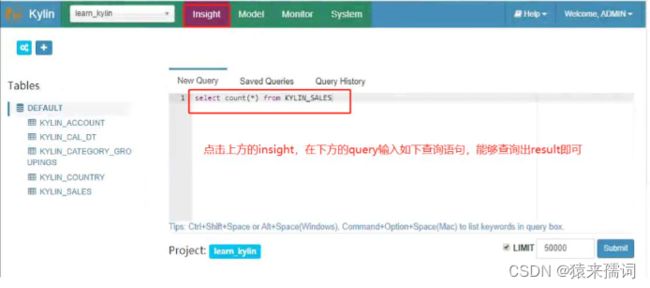
3.2.3 查询操作
select count(*) from KYLIN_SALES
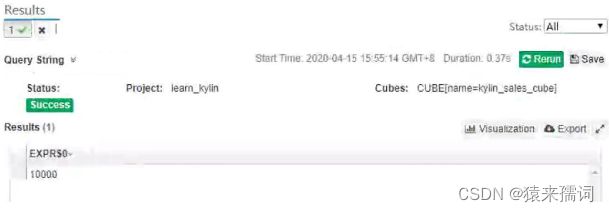
结果的status为success即可
4. 安装问题
4.1 执行./check-env.sh环境检查的时候出现netstat的问题
yum install -y net-tools (执行的时候如果出现权限问题 切换到root用户安装)

4.2 启动的时候./kylin.shstart出现如下错误
检查启动kylin的账户是不是拥有hdfs、hive、hbase的权限(详见1.1.4章节)或者直接查看ranger对于用户权限的配置,添加权限。

4.3 kylin启动成功,但是web页面打不开。
查看是否修改tomcat的conf文件夹下的server.xml并注释掉了1.1.4中的那段话,接着检查tomcat的lib目录是否添加了jar包:commons-configuration-1.6.jar
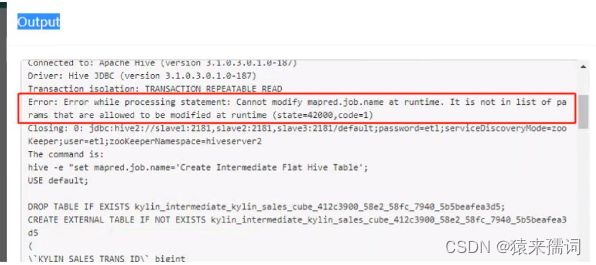
4.4 构建cube的时候,出现如下错误,需要在集群的hive-site.xml中添加如下属性。
hive-site添加如下3个property:
hive.security.authorization.sqlstd.confwhitelist.append mapred.*|hive.*|mapreduce.*|spark.* hive.security.authorization.sqlstd.confwhitelist mapred.*|hive.*|mapreduce.*|spark.* hive.server2.builtin.udf.blacklist empty
4.5 cube构建时,一直卡在第一步很久,log显示no data avaliable。
请查看hive是否可以正常使用:包括输入hive命令后,正常进入数据库,无需输入用户名和密码!以及show databases; select,drop等权限都正常。
5. Kylin集群模式部署
5.1 Kylin在线扩展成分布式
5.1.1 修改节点配置文件
修改master2主节点的kylin.properties
cd /home/etl/kylin/bin #进入kylin的bin目录
./kylin.sh stop #如果之前运行过请先关闭,否则跳过此步骤
cd /home/etl/kylin/conf #进入kylin的配置文件目录
vi kylin.properties #进入kylin.properties
#添加如下三条属性,注意只有一台节点是all模式,其余节点必须是query
kylin.server.mode=all
kylin.server.cluster-servers=172.19.131.135:7070,172.19.131.16:7070,172.19.131.18:7070
kylin.web.timezone=GMT+8
#注意:servers替换成实际自己的IP地址
:wq #保存退出同理操作其他两个节点(eg: etl1,etl2)
注意:对其他两个节点,必须先执行 1.4 安装前环境检查的所有步骤
执行完环境检查的步骤之后,通过ftp把kylin文件夹上传到安装目录/home/etl/后,执行如下步骤
cd /home/etl/kylin/conf #进入kylin的配置文件目录 vi kylin.properties #进入kylin.properties #添加如下三条属性,注意只有一台节点是all模式,其余节点必须是query kylin.server.mode=query kylin.server.cluster-servers=172.19.131.135:7070,172.19.131.16:7070,172.19.131.18:7070 kylin.web.timezone=GMT+8 #注意:servers替换成实际自己的IP地址,同(5.1) :wq #保存退出 vim ~/.bashrc #编辑用户的环境变量,添加如下两个环境变量 export KYLIN_HOME=/home/etl/kylin #此处两台机器都要执行(1.B)的小节中的所有操作,并且都是query模式 cd /home/etl/kylin/tomcat/conf #进入配置文件目录 vi server.xml #进入server.xml #注释掉如下属性(同2.2) #看tomcat的lib文件夹下是否有如下jar包(给的压缩包已经添加该jar)(同2.3)
5.1.2 启动三台kylin机器
cd /home/etl/kylin/bin #进入目录
./kylin.sh start #执行注意:启动的时候可能会出现有的机器卡在Using cached dependency...之后卡很久,如果卡主3分钟还没有继续输出信息,可以敲两个回车,等待15-20分钟以后再去查看,一般就已经启动成功(只有集群模式的时候出现这种情况,后续会在排查具体原因,不影响使用)
5.1.3 查询测试
登录三台机器的web页面,进行简单的测试,三台都进行查询测试

查询能出结果,则集群模式部署完成
6. Nginx安装
kylin的主节点安装
安装负载均衡器。为了将查询请求发送给集群而非单个节点,您可以部署一个负载均衡器,如Nginx,F5 或cloudlb等,使得客户端和负载均衡器通信代替和特定的Kylin实例通信。下面的操作步骤也可以参考网址:
Nginx 安装配置 | 菜鸟教程Nginx 安装配置 Nginx('engine x')是一款是由俄罗斯的程序设计师Igor Sysoev所开发高性能的 Web和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 在高连接并发的情况下,Nginx是Apache服务器不错的替代品。 Nginx 安装 系统平台:CentOS release 6.6 (Final) 64位。 一、安装编译工具及库文件 yum -y.. https://www.runoob.com/linux/nginx-install-setup.html
https://www.runoob.com/linux/nginx-install-setup.html
pcre-8.35.tar.gz,nginx-1.6.2.tar.gz。
6.1 安装编译工具及库文件
切换到主节点的root用户
yum -y install make zlib zlib-devel gcc-c++ libtool openssl openssl-devel6.2 首先要安装 PCRE
cd /usr/local/src/
wget http://downloads.sourceforge.net/project/pcre/pcre/8.35/pcre-8.35.tar.gz
tar zxvf pcre-8.35.tar.gz #解压
cd pcre-8.35
./configure
make && make install
pcre-config --version #查看安装版本6.3 安装 nginx
cd /usr/local/src/
wget http://nginx.org/download/nginx-1.6.2.tar.gz
tar zxvf nginx-1.6.2.tar.gz #解压
cd nginx-1.6.2
./configure --prefix=/usr/local/webserver/nginx --with-http_stub_status_module --with-http_ssl_module --with-pcre=/usr/local/src/pcre-8.35
make
make install
/usr/local/webserver/nginx/sbin/nginx -v #查看版本
/usr/sbin/groupadd www #创建运行nginx的账户
/usr/sbin/useradd -g www www
cd /usr/local/webserver/nginx/conf/ #配置nginx.conf
mv nginx.conf nginx.conf.bak #将原来的conf备份
vi nginx.conf #新建 nginx.conf复制如下内容到文件中(注意检查一下,有部署的时候发现黏贴进去user少了us字符,以及#后面的注释可以去掉,如果不去掉,注意检查不要串行):
user www www;
worker_processes auto;
error_log /usr/local/webserver/nginx/logs/nginx_error.log crit;
pid /usr/local/webserver/nginx/nginx.pid;
#Specifies the value for maximum file descriptors that can be opened by this process.
worker_rlimit_nofile 65535;
events
{
use epoll;
worker_connections 65535;
}
http
{
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $http_x_forwarded_for';
#charset gb2312;
access_log /usr/local/webserver/nginx/logs/access.log;
#下面是server虚拟主机的配置
server
{
listen 18080; #监听端口
server_name 172.19.131.*; #域名,此处好像不影响nginx,可根据实际IP修改
index index.html index.htm index.php;
root /usr/local/webserver/nginx/html; #站点目录
location /
{
proxy_pass http://kylin.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
upstream kylin.com {
ip_hash;
server 172.19.xxx.xx:7070 weight=3; #注意替换成自己的IP
server 172.19.xxx.xx:7070; #注意替换成自己的IP
server 172.19.xxx.xx:7070; #注意替换成自己的IP
}
}
注意:蓝色部分按照实际修改,如果三台机器性能一样可以不添加weight=3
/usr/local/webserver/nginx/sbin/nginx -t #检查配置文件nginx.conf的正确性
/usr/local/webserver/nginx/sbin/nginx #启动
ps -ef | grep nginx #查看是否启动成功配置完成以后输入http://172.19.xxx.xxx:18080/kylin/(所部署的nginx节点的IP)输入用户ADMIN和密码KYLIN,看到kylin正常的页面即成功。标注蓝色的部分按照实际安装的路径和IP填写,确定三台节点kylin都已经启动

其他nginx命令
/usr/local/webserver/nginx/sbin/nginx -s reload # 重新载入配置文件
/usr/local/webserver/nginx/sbin/nginx -s reopen # 重启
Nginx/usr/local/webserver/nginx/sbin/nginx -s stop # 停止 Nginx
注意:部署完成以后,第二天可以查看一下三台kylin的页面是否还是能够正常访问,如果出现web页面出不来,可能是节点挂掉了,重启该节点的kylin即可。
如果老挂,请查看kylin的日志,排查是否存在环境问题。
附加知识点(无需操作):
upstream bakend{ #定义负载均衡设备的Ip及设备状态 ip_hash; server 10.0.0.11:9090 down;
##这台机器先不用 server 10.0.0.11:8080 weight=2;
##给与较大权重,默认权重是1 server 10.0.0.11:6060; server 10.0.0.11:7070 backup;
##备份机器,其他节点都挂掉的时候启用
}
kylin.job.jar=/usr/local/kylin/lib/kylin-job-3.0.0.jar
kylin.coprocessor.local.jar=/usr/local/kylin/lib/kylin-coprocessor-3.0.0.jar #提升性能
kylin.job.yarn.app.rest.check.status.url=http://172.19.131.107:8088/ws/v1/cluster/apps/${job_id}?anonymous=true #yarn工作区
kylin.job.jar=/home/etl/kylin/lib/kylin-job-3.0.0.jar
kylin.coprocessor.local.jar=/home/etl/kylin/lib/kylin-coprocessor-3.0.0.jar
kylin.job.yarn.app.rest.check.status.url=http://172.19.131.135:8088/ws/v1/cluster/apps/${job_id}?anonymous=true