Paper | 1. 针对基于脑电图的脑机接口的黎曼几何分析
Marco Congedo, Alexandre Barachant, Rajendra Bhatia. Riemannian geometry for EEG-based brain- computer interfaces; a primer and a review. Brain-Computer Interfaces, Taylor & Francis, 2017, 4 (3), pp.155-174. 10.1080/2326263X.2017.1297192 . hal-01570120。
目录
一、背景介绍
二、黎曼分类框架入门——Minimum Distance to Mean (MDM) classifier
三、黎曼度量为什么这么有效
3.1传感器空间与源空间的等价性
3.2几何均值的鲁棒性
3.3泛化能力
四、性能评估(与csp对比)
五、更先进的黎曼分类器
六、将黎曼几何应用于脑电(EEG)数据
七、总结展望
一、背景介绍
脑机接口(BCI)作为沟通用户和机器的工具,其核心就是解码器(decoder)——将大脑信号转换为机器指令的部件。
传统的解码步骤是预处理(preprocessing),特征提取(feature extraction)与分类(classification)。问题是,目前三种主流的BCI模式,运动想象(MI)、事件相关电位(ERP)与稳态诱发电位(SSEP),均采用不同的预处理、信号处理及分类模块。另外,解码策略本身也很碎片化的。现有解码范式可分为两类:一种遵循复杂的机器学习方法;另一种使用信号处理来提高信噪比,然后使用简单的分类算法。一些机器学习算法(如CNN、LSTM等)可以很好地跨试次和跨被试进行泛化,但需要大量的训练数据且计算复杂。而空间滤波的情况正好相反,在这种情况下,糟糕的泛化能力可以通过快速的训练和较低的计算成本得到补偿。
目前脑机接口实用性不高主要由于被试间变异性(inter-subject physiological variability)以及环境噪声(great variability of real-world environmental conditions),为克服这些缺点,学者们提出了以下方案:
1.迁移学习。实时脑机接口的首要事项就是减少校准时间,目前进展包括通用模型分类器(genetic model classifiers)及域适应理论(domain adaptation methods)——即迁移学习(transfer learning)。迁移学习包括跨试次、跨被试及跨设备,一般是把来自其他被试或试次的数据用来初始化脑机接口来减少校准时间或提高设备效果(数据量少的情况下)。虽然通过迁移学习的通用初始化更容易实现,但我们更倾向于为给定用户寻求最佳初始化,即智能初始化(smart initialization)。
2.分类器持续适应(continuous (on-line) adaptation of the classifier)。适应性是确保无论初始化怎样都实现最佳性能,它还允许通过在不同试次间适应心理和环境的变化来保持最佳性能,从而确保试次内和跨试次的可靠性和鲁棒性。
3.数据集(databases)。只有数据量足够才可以进行解码策略的大规模测试,解释被试间变异的来源以及弄清脑机接口性能与被试能获得能力的关系。
而一个合格的脑机接口应该是什么样子呢?作者认为应该具备以下八个特征:
1.Accurate. 总体上至少保持现有设备的准确性。
2.Reliable. 无论是日常、敌对还是意外情况下的准确性都应该尽可能保持稳定。
3.Initialized with genetic parameter. 应该具有足够好的跨试次和跨被试的泛化能力。
4.Learn fast. 快速学习个体特征,然后保持最优性能;快速适应用户的心理状态和环境变化。
5.Universal. 对不同脑机接口范式(MI, ERP, SSEP)都适用,即适用于混合系统。
6.Algorithmically simple. 保证在无监督的在线操作中具有健壮性和实用性。
7.Computationally efficient. 适用于微电子设备,符合当前的可移植性趋势。
8.Multi-user setting. 多用户设置更符合当下电子设备的社会性期望。
本文的目的就是描述一个简单的、满足上述所有要求的脑机接口解码范式,并最终提出了如图1所示的新一代脑机接口概念。
 图1. 新一代脑机接口概念
图1. 新一代脑机接口概念
①在启动时,BCI查询数据库以获得初始化,可能会发送最少的用户脑电图数据,以便拟合甚至是完成新用户的智能初始化。②BCI可以直接运行,尽管可能在一开始不是最理想的。当BCI被使用时,它会根据用户的情况进行调整,并将数据连同用户信息一起发回数据库,从而丰富数据库,并允许在同一用户以及其他用户的未来会话中进行更智能的初始化。③多用户可以同时使用同一台BCI,在这种情况下,BCI的解码机可能位于服务器上,从而利用大量的数据来提高性能。
二、黎曼分类框架入门——Minimum Distance to Mean (MDM) classifier
在解析几何中,复杂的代数关系往往转化为简单的几何性质,因此用几何语言可以清楚地表达代数关系,且几何关系比代数关系更容易被发现。
对称正定矩阵(symmetric positive definite, SPD) 可以认为是对平方实数的多维的推广。当一维随机变量的方差是正数(平方和)时,N维随机变量的方差是正矩阵,通常称为协方差矩阵。
对有N个传感器的脑电信号,首先考虑其中一个电极(在皮层Cz),即单个时间序列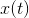 ,这足以检测在脚移动几秒钟后发生的beta-renound现象,因此,它已被用于OpenViBE的“tie-fighter”演示。beta-renound是信号能量在β频率范围(16-24hz)内的暂时增加,通常被称为“功率”。让我们用向量
,这足以检测在脚移动几秒钟后发生的beta-renound现象,因此,它已被用于OpenViBE的“tie-fighter”演示。beta-renound是信号能量在β频率范围(16-24hz)内的暂时增加,通常被称为“功率”。让我们用向量 表示一个由
表示一个由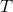 个样本组成的时间窗口,在这个时间窗口中检测到beta-renound,其中k是考虑的时间窗口的指标(如trial)。对于在适当的带通区域滤波的数据,其作用是只保留该区域的能量,使信号的均值无效,即信号在时间窗中的能量可以由信号方差评估,该方差常用表示,可通过滑动窗口在线监测。如图2所示,当当前时间窗的信号k方差超过阈值时,检测到beta-renound。同样,我们可以估计出rest方差的一个代表性值、即rest状态方差的“平均值” ,以及beta-renound状态方差的“平均值” 。当检测到时即为beta-renound状态,其中表示两个标量参数之间的适当距离函数。这样的分类器就被称为Minimum Distance to Mean (MDM)或Nearest Centroid or Mean-of-Class Prototype,其实就是加权(均值也可视为一种权重)最近邻分类器的一种特例。
个样本组成的时间窗口,在这个时间窗口中检测到beta-renound,其中k是考虑的时间窗口的指标(如trial)。对于在适当的带通区域滤波的数据,其作用是只保留该区域的能量,使信号的均值无效,即信号在时间窗中的能量可以由信号方差评估,该方差常用表示,可通过滑动窗口在线监测。如图2所示,当当前时间窗的信号k方差超过阈值时,检测到beta-renound。同样,我们可以估计出rest方差的一个代表性值、即rest状态方差的“平均值” ,以及beta-renound状态方差的“平均值” 。当检测到时即为beta-renound状态,其中表示两个标量参数之间的适当距离函数。这样的分类器就被称为Minimum Distance to Mean (MDM)或Nearest Centroid or Mean-of-Class Prototype,其实就是加权(均值也可视为一种权重)最近邻分类器的一种特例。
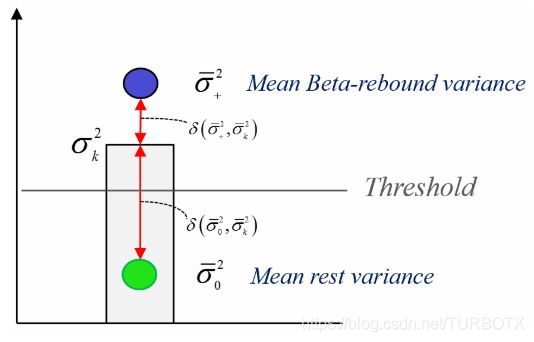 图2. 二分类一维情况下的最小平均距离(Minimum Distance to Mean, MDM / Nearest Centroid or Mean-of-Class Prototype)分类器。给定方差的观察值σk2 ,如果当前试次的值超过阈值,则将其分配给“Beta-rebound”类,否则分配给“rest”类。同样地,根据箭头所示的距离函数,可以估计每个类别的平均值,并将当前试次分配给最接近的平均值。该方法可以以相同方式直接推广到多维情况和任意数量的类
图2. 二分类一维情况下的最小平均距离(Minimum Distance to Mean, MDM / Nearest Centroid or Mean-of-Class Prototype)分类器。给定方差的观察值σk2 ,如果当前试次的值超过阈值,则将其分配给“Beta-rebound”类,否则分配给“rest”类。同样地,根据箭头所示的距离函数,可以估计每个类别的平均值,并将当前试次分配给最接近的平均值。该方法可以以相同方式直接推广到多维情况和任意数量的类
因此要想实现MDM-Riemannian分类器,就需要合适的距离函数(metric)及相应的均值(mean)函数。数学上,距离(metric/distance)是定义集合中每一对元素之间距离的函数,具有以下性质:①非负;②为零当且仅当两元素相等时;③对称;④满足三角不等式。
赋予度量的集合称为度量空间(metric space),度量空间就是正实数集被赋予度量 。根据Fréchet距离准则(principle of Maurice Fréchet),度量空间的每个距离都会引出均值(mean)的概念:令是度量空间内的K个点,该集合的均值就是使最小的点m,用这种方法确定均值就是一个最小二乘法问题。
。根据Fréchet距离准则(principle of Maurice Fréchet),度量空间的每个距离都会引出均值(mean)的概念:令是度量空间内的K个点,该集合的均值就是使最小的点m,用这种方法确定均值就是一个最小二乘法问题。
常用的 就是欧氏距离(Euclidean distance):,相应的欧式均值就是使最小的点m, m就是算术平均数:。因此欧式均值就是可以最小化样本方差的点,均值周围数据集合的离散度就是欧氏距离。
就是欧氏距离(Euclidean distance):,相应的欧式均值就是使最小的点m, m就是算术平均数:。因此欧式均值就是可以最小化样本方差的点,均值周围数据集合的离散度就是欧氏距离。
对于BCI应用,基于欧式距离和相关平均数的MDM分类器在一维情况下已经显示效果很差。BCI领域的实践是考虑用对数变换方差替代,即(一维)几何距离/双曲线距离/对数欧氏距离(log- Euclidean distance, hyperbolic or geometric distance):。与欧氏距离相反,几何距离具有尺度不变性(scale invariance)和逆不变性(invariance under inversion)。相应的几何均值就是使最小的点g, 。
由几何距离推导来的几何均值是方差中心趋势(期望值)的描述,而从欧氏距离推导来的算术平均则不是、它只对对称分布的中心趋势描述比较贴切、因为方差的分布是卡方分布。正如图3所示,对于高斯分布,算术平均数和几何平均数都是中心趋势的良好描述,对于卡方分布,几何平均数是更好的描述。
 图3. 算术和几何平均数
图3. 算术和几何平均数
卡方分布(10自由度,上行)和高斯分布(下行)的经验等密度,没有(左列)和有异常值(右列)。
现在让我们看看如何将正定对称矩阵流形上的黎曼距离理解为一维几何距离的任意维的直接推广,以及如何导出相关的均值。
此时令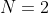 ,让
,让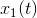 和
和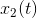 表示C3和C4两个电极的脑电信号,让和表示第k个时间窗口下的信号段,则协方差矩阵
表示C3和C4两个电极的脑电信号,让和表示第k个时间窗口下的信号段,则协方差矩阵 为,此时相比较之前不仅考虑对角元素也考虑非对角元素(协方差)。因为,则是对称矩阵,即该矩阵由个元素决定。因此,我们可以将协方差矩阵表示为三维空间中的数据点,坐标轴分别为,和,如图4所示 。因为是正矩阵,所以,从而由Cauchy-Schwarz不等式任何数据点都被限制在对称锥的内部。电生理层面,当两个电极上任何一个处的能量(方差)发生变化,或者当两个电极上捕获的信号之间的相位同步和/或振幅共调制发生变化时,沿着三个坐标移动。两个点沿着这些坐标彼此远离的越多,它们在圆锥体中占据的分离区域就越多。(更高维度也同样适用)
为,此时相比较之前不仅考虑对角元素也考虑非对角元素(协方差)。因为,则是对称矩阵,即该矩阵由个元素决定。因此,我们可以将协方差矩阵表示为三维空间中的数据点,坐标轴分别为,和,如图4所示 。因为是正矩阵,所以,从而由Cauchy-Schwarz不等式任何数据点都被限制在对称锥的内部。电生理层面,当两个电极上任何一个处的能量(方差)发生变化,或者当两个电极上捕获的信号之间的相位同步和/或振幅共调制发生变化时,沿着三个坐标移动。两个点沿着这些坐标彼此远离的越多,它们在圆锥体中占据的分离区域就越多。(更高维度也同样适用)
 图4. SPD矩阵的对称凸锥。根据Cauchy-Schwarz不等式,任何对称正定矩阵都位于开锥的内部。当这一点接触到圆锥的边缘时,不等式就变成一个等式,矩阵就不再是正定的了
图4. SPD矩阵的对称凸锥。根据Cauchy-Schwarz不等式,任何对称正定矩阵都位于开锥的内部。当这一点接触到圆锥的边缘时,不等式就变成一个等式,矩阵就不再是正定的了
接下来需要为正定矩阵的锥配一个合适的距离度量,类似于的几何距离。 对称矩阵的空间是一个维的线性空间。正定矩阵的锥是对称矩阵的子集,常可用欧式范数表示:(
对称矩阵的空间是一个维的线性空间。正定矩阵的锥是对称矩阵的子集,常可用欧式范数表示:(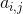 是矩阵
是矩阵 的元素),但实践证明不适合脑机接口。于是提出了如图5所示的可微流形,在流形上的任何基点上的所有对称矩阵的空间称为切空间。黎曼几何首先在每一个切线空间上配置一个内积,从而得到的距离(有时将切空间上的内积称为“距离”。本文从切空间上的内积的定义出发,将距离称为流形上的距离函数)在点与点之间平滑地变化。如图5所示,取流形
的元素),但实践证明不适合脑机接口。于是提出了如图5所示的可微流形,在流形上的任何基点上的所有对称矩阵的空间称为切空间。黎曼几何首先在每一个切线空间上配置一个内积,从而得到的距离(有时将切空间上的内积称为“距离”。本文从切空间上的内积的定义出发,将距离称为流形上的距离函数)在点与点之间平滑地变化。如图5所示,取流形 上两个点
上两个点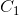 和
和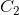 ,这两点的几何均值是连接和的测地线(geodesic, 唯一的最小长度的线)上的中点——它使最小。现在G点构造切空间,该切空间存在且只有一个切向量()对应于从G出发到达流形上的()的测地线。从切空间(对称矩阵S)到流形(对称正定矩阵S ++)的映射是一个指数映射。从流形到切线空间的逆映射是对数映射。此时,点
,这两点的几何均值是连接和的测地线(geodesic, 唯一的最小长度的线)上的中点——它使最小。现在G点构造切空间,该切空间存在且只有一个切向量()对应于从G出发到达流形上的()的测地线。从切空间(对称矩阵S)到流形(对称正定矩阵S ++)的映射是一个指数映射。从流形到切线空间的逆映射是对数映射。此时,点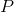 的内积就变成了,相应的范数是,且。
的内积就变成了,相应的范数是,且。
 图5.对称正定矩阵流形的简图表示,包括两个点的几何均值G 及G点的切空间。
图5.对称正定矩阵流形的简图表示,包括两个点的几何均值G 及G点的切空间。
下一步就是使用切空间的内积计算空间内的曲线长度,这可以用微积分完成。幸运的是,在具有内积的正数矩阵的流形中,对于任意两点C1和C2都存在一条测地线。从C1到C2的测地线的长度(反之亦然)给出了黎曼距离:
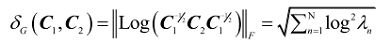 图6 黎曼距离
图6 黎曼距离
这一距离就定义为测地线的长度,这样可以确保它具有距离函数的所有特性。它还有几个很好的附加属性,其中一些对于它在BCI中的使用很重要(增加了鲁棒性)。
特性一:
特性二:
特性三:对任意可逆矩阵
,
特性四:(算术平均数没有)
由黎曼距离可推出黎曼均值:
 图7 黎曼均值
图7 黎曼均值
工具箱:Covariance Toolbox和pyRiemann
三、黎曼度量为什么这么有效
3.1传感器空间与源空间的等价性
基于空间滤波器和源分离的脑机接口特征提取方法是脑机接口领域研究的热点。这些方法的目的是将传感器测量数据分解为信号部分和噪声部分,并仅用信号部分提取的特征进行分类。用黎曼几何操作数据点有效的主要原因是,在传感器空间中的黎曼操作与在同一维的源空间中可以进行的操作是等价的。要了解这一点,首先考虑空间滤波器(Spatial Filters)的性质。
将脑电观测数据视为N维向量,将空间滤波器视为P*N的矩阵 ,。则线性空间滤波器为。矩阵的不同推导方式导致不同的空间滤波器。借用标准机器学习技术,提取的分量
,。则线性空间滤波器为。矩阵的不同推导方式导致不同的空间滤波器。借用标准机器学习技术,提取的分量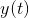 通常被滤波器的构造强制为不相关,并且它们的数目P通常选择小于电极数目N,其中丢弃的N-P个分量解释与任务无关的EEG能量,即滤波器抑制的噪声。
通常被滤波器的构造强制为不相关,并且它们的数目P通常选择小于电极数目N,其中丢弃的N-P个分量解释与任务无关的EEG能量,即滤波器抑制的噪声。
一类特殊的空间滤波器是盲源分离。虽然空间滤波器的分量不需要有任何生理意义,但源分离分量是实际脑源波形的估计,产生了观察到的EEG头皮图。人们普遍认为,观测到的脑电信号可以很好地近似于脑偶极源的线性混合信号,因此我们通常将其作为脑电数据生成模型:—— 是一个包含未知源过程的向量,A是一个混合矩阵(mixing matrix),此处假设是可逆的,其左逆B称为分离矩阵。混合矩阵由偶极子在大脑中的位置和方向、头部的物理特性以及头皮上电极的位置决定。一旦估计出B,源进程就由估计,摒除了通常的缩放和排列的模糊性。
是一个包含未知源过程的向量,A是一个混合矩阵(mixing matrix),此处假设是可逆的,其左逆B称为分离矩阵。混合矩阵由偶极子在大脑中的位置和方向、头部的物理特性以及头皮上电极的位置决定。一旦估计出B,源进程就由估计,摒除了通常的缩放和排列的模糊性。
令 和
和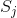 为任意两个试验中,未知源过程的协方差矩阵。由知,两个相应的传感器协方差矩阵是和。则由黎曼距离的特性得:。例如,如果我们估计一个平方空间滤波器,那么传感器空间(
为任意两个试验中,未知源过程的协方差矩阵。由知,两个相应的传感器协方差矩阵是和。则由黎曼距离的特性得:。例如,如果我们估计一个平方空间滤波器,那么传感器空间( 和
和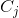 )中的距离与源空间(和)中的距离相等,对提取的成分进行分类的最佳程度无关紧要。我们说EEG空间混合是黎曼空间中的等距。从分类的角度来看,在给定的空间维度上,特性使得无论坐标发生什么变化,都能保持特征空间的信息不变。如果取,意味着我们估计的分量比可用的传感器少,我们仍然可以在源空间的子空间中找到一个投影,从而增强类的分离度,也就是说,我们仍然可以改进MDM在传感器空间中实现的分类。我们将在第四节中看到,在实践中,仅当可用电极的数量较大时,估计空间滤波器的努力是值得的。因为黎曼距离对于噪声分量是不敏感的,如果N很小,噪声分量的数目也很小。
)中的距离与源空间(和)中的距离相等,对提取的成分进行分类的最佳程度无关紧要。我们说EEG空间混合是黎曼空间中的等距。从分类的角度来看,在给定的空间维度上,特性使得无论坐标发生什么变化,都能保持特征空间的信息不变。如果取,意味着我们估计的分量比可用的传感器少,我们仍然可以在源空间的子空间中找到一个投影,从而增强类的分离度,也就是说,我们仍然可以改进MDM在传感器空间中实现的分类。我们将在第四节中看到,在实践中,仅当可用电极的数量较大时,估计空间滤波器的努力是值得的。因为黎曼距离对于噪声分量是不敏感的,如果N很小,噪声分量的数目也很小。
3.2几何均值的鲁棒性
众所周知,基于脑电的脑机接口的主要挑战之一是脑电数据受到多种人工因素的污染,包括生物、环境和仪器因素。与现实情况相比,这些污染在实验室中可以得到更好的控制。黎曼度量被证明具有优势的一个明显原因是几何平均值对异常值的鲁棒性。这如图3所示;当存在异常值时,与算术平均值相比,几何平均值与分布中心的偏差较小,这两种情况下的数据分布为高斯分布(对称)和卡方分布(不对称)。对于卡方数据,算术平均值的失真更为明显。几何平均值的这种鲁棒性直接从几何距离函数继承而来。
3.3泛化能力
黎曼距离的特性也有助于使整个黎曼框架对跨试次和跨被试观察到的典型EEG源空间分布的修改更具鲁棒性。中的真实混合矩阵A对单个受试者具有高度的特异性,并且由于电极位置和阻抗不可避免,同一受试者的不同试次也会发生变化。
我们首先考虑跨会话(cross-session)学习。令和为任意两个试次(trial)中,未知源过程的协方差矩阵。由知,两个相应的传感器协方差矩阵是和。现在考虑在另一个试验(session)中使用相同源进程协方差矩阵和的两个试次,并让 作为新试验的混合矩阵,则新试验的传感器协方差矩阵为和。因此,这两个试验中尽管源协方差是相同的(和),我们观察到不同的协方差矩阵。但显然两个观测协方差矩阵之间的距离在两个试验中应是相同的(不写证明了),即。请注意,认为,A与的距离无关紧要。相反,A与的差异越大,跨试验应用的空间过滤器的性能将越差。该特性的经验验证如图8所示。
作为新试验的混合矩阵,则新试验的传感器协方差矩阵为和。因此,这两个试验中尽管源协方差是相同的(和),我们观察到不同的协方差矩阵。但显然两个观测协方差矩阵之间的距离在两个试验中应是相同的(不写证明了),即。请注意,认为,A与的距离无关紧要。相反,A与的差异越大,跨试验应用的空间过滤器的性能将越差。该特性的经验验证如图8所示。
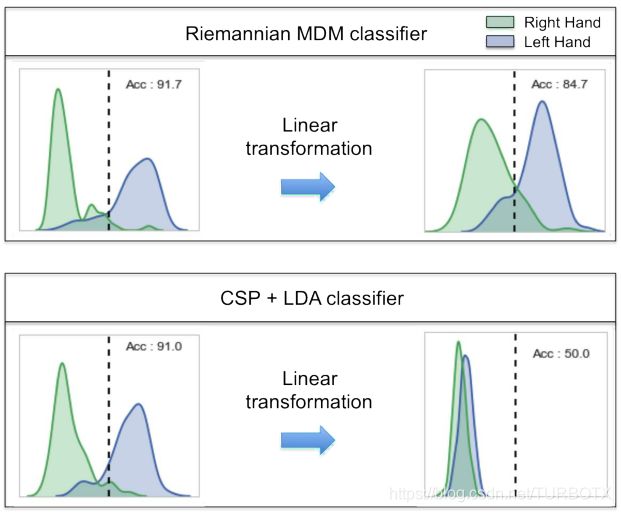 图8. 跨会话(cross-session)迁移学习。运动想象两分类问题的分类输出分布。在应用随机线性变换之后,黎曼分类器保持了相对较好的精度,而基于公共空间模式滤波器(CSP:见第4节)的分类无法捕获相关信息并输出随机标签。
图8. 跨会话(cross-session)迁移学习。运动想象两分类问题的分类输出分布。在应用随机线性变换之后,黎曼分类器保持了相对较好的精度,而基于公共空间模式滤波器(CSP:见第4节)的分类无法捕获相关信息并输出随机标签。
在跨被试(cross-subject)学习中,除了混合矩阵外,不同被试的源过程也不同。因此,对于MDM-Riemannian和基于空间滤波的分类器,性能的恶化都会更大,然而,由于上述混合过程的尺度不变性,前者仍然会更好。
四、性能评估(与csp对比)
在本节中,我们将MDM-Riemannian算法与公共空间模式(Common Spatial Pattern, CSP)这一空域滤波器(在模式识别领域,CSP也被称为Fukunaga-Koontz变换, KFT)进行比较,后者在受控条件下被证明是灵活、简单和准确的。这里我们表明CSP与MDM-Riemannian算法提供的更一般的框架密切相关。首先,考虑空间滤波器的基本原理,特别是如何构造CSP滤波器。
让我们再次考虑BCI中的一般多维情况( ),其中左手和右手运动想象的试验在给定大量训练试验的情况下进行分类。首先将作为A、B两个类期望协方差矩阵的估计(类的顺序不重要)。它们可以通过训练样本协方差矩阵的算术平均值来估计,也可以通过它们的黎曼几何平均值来估计。
),其中左手和右手运动想象的试验在给定大量训练试验的情况下进行分类。首先将作为A、B两个类期望协方差矩阵的估计(类的顺序不重要)。它们可以通过训练样本协方差矩阵的算术平均值来估计,也可以通过它们的黎曼几何平均值来估计。
共空间模式(Common Spatial Pattern):
 图9. 共空间模式
图9. 共空间模式
注意间的黎曼距离是关于矩阵特征值的函数,因此构成该距离的个最极端特征值与形成CSP滤波器 的特征向量相关联。元素和是根据由CSP滤波器过滤的数据的方差。每个相关的特征向量
的特征向量相关联。元素和是根据由CSP滤波器过滤的数据的方差。每个相关的特征向量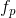 将数据协方差投影到一维空间中,其中两类中的方差比率最大化(19),即,对齐点以便最大程度地分离;第一个P/2向量解释了类A的方差的最大值和类B的最小值,最后的P/2向量解释了B类方差的最大值和A类方差的最小值。若和分别表示两个未标注试次滤波后的协方差矩阵,用和表示各自的对角线元素。矩阵
将数据协方差投影到一维空间中,其中两类中的方差比率最大化(19),即,对齐点以便最大程度地分离;第一个P/2向量解释了类A的方差的最大值和类B的最小值,最后的P/2向量解释了B类方差的最大值和A类方差的最小值。若和分别表示两个未标注试次滤波后的协方差矩阵,用和表示各自的对角线元素。矩阵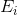 和
和 不是对角的,因此它们的对角元素不是它们的特征值,因此两个试次间的黎曼距离不能直接表示为和的函数。但关于其关系,存在一个如图10所示的不等式,当且仅当和是对角矩阵时不等式相等。不等式左侧是由CSP滤波器提取的特征和(CSP特征)之间的几何距离,右侧是和之间的总黎曼距离(黎曼特征)。
不是对角的,因此它们的对角元素不是它们的特征值,因此两个试次间的黎曼距离不能直接表示为和的函数。但关于其关系,存在一个如图10所示的不等式,当且仅当和是对角矩阵时不等式相等。不等式左侧是由CSP滤波器提取的特征和(CSP特征)之间的几何距离,右侧是和之间的总黎曼距离(黎曼特征)。
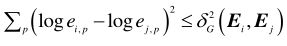 图10. 黎曼距离与协方差矩阵对角线元素的关系。
图10. 黎曼距离与协方差矩阵对角线元素的关系。
我们看到CSP近似于MDM-Riemannian算法所考虑的距离,随着和接近对角线形式,近似值也越来越接近。由于CSP(P≤N)对噪声的抑制作用,该近似一般是有效果的,但该方法对于受远离对角线形式的和噪声污染的试验不具有鲁棒性。
MDM-Riemannian算法对噪声的健壮性对BCI实际应用中非常有用;当N足够小(<32)时,CSP和MDM-Riemannian算法获得的精度差异可以忽略不计,而对于N较大的情况,CSP被证明是优越的,因为CSP忽略了越来越多的不相关组件()。正如3.1节所示,可以应用CSP变换,然后在降噪(去噪)空间中应用MDM-Riemannian算法,这样可以获得更高的精度,但是我们需要再次估计一个空间滤波器,除非我们在线调整它,否则这种滤波器特定于可用的训练数据、失去了泛化能力。另外,当N很小时,如果不对数据进行滤波,则黎曼距离和均值对噪声是鲁棒的。总之,在实际应用中,应用少量的电极,MDM-Riemannian算法提供了一个非常有竞争力的选择,因为不需要估计空间滤波器就可以获得高精度。
五、更先进的黎曼分类器
MDM-Riemannian算法是最简单的黎曼方法。在本节中,我们将简要介绍明显优于CSP和其他优秀方法的更复杂的黎曼分类器,它们利用了切空间(tangent space)的概念。切空间映射(Tangent space mapping)是一种局部投影,它将流形的元素映射到欧氏空间中来保持其距离关系不变。这个操作可以被可视化为将流形弯曲结构的局部展开成一个平面(图5)。一旦投影到切空间中,数据点(即正定对称矩阵)就可以被矢量化以形成标准特征向量,并因此被用到任何标准分类器(如线性判别分析、逻辑回归、支持向量机等)。这个操作允许产生复杂的决策函数,这取决于切线空间中所选的分类器,需要我们将所选分类器的优点与使用黎曼度量的优点结合起来。虽然基于切线空间映射的黎曼方法的总体性能优于MDM-Riemannian算法,并且明显优于现有技术,但由于算法复杂性的增加以及分类器可能需要继承的密集学习,因此它们不太适合在线操作。
六、将黎曼几何应用于脑电(EEG)数据
黎曼几何在脑电领域的应用主要体现在两个方面,一方面用于睡眠阶段的分类,另一方面用于基于运动想象和P300的脑机接口。这些工作成果催生了基于EEG的BCI领域的探索跟进:研究了CSP算法和信息几何(information geometry )工具之间的联系,考虑了几种不同于黎曼距离的散度函数(divergence functions)。(待看)
七、总结展望
黎曼几何学作为一个相对较新的分类框架,在脑-机接口领域直接进行了范式领域内的转换。这篇文章在不涉及任何具体的微分几何知识、从直观的几何解释的情况下提供了一个简单的黎曼分类方法——最小平均距离(MDM, minimum distance to mean)的入门,提供了其工作的基本原理,并强调了其在实践中应用的简单性。MDM-Riemannian方法完全基于两个简单的概念:两个数据点之间的距离(distance)和其均值(mean)。这两个概念作为数学许多分支的基础,很容易理解进而与同行交流。虽然概念简单,但它一种精确而健壮的分类方法,可与更复杂的最新方法的性能相媲美。打个比方,我们似乎很久以前就开始用有偏差的标尺(方差和协方差矩阵的欧几里德距离)测量距离了,因为这样效果并不好,所以就已经开发了更复杂的仪器,以取代不良标尺(空间滤波器和其他矩阵分解方法)。终于,我们找到了一个有效的标尺(SPD矩阵的黎曼度量),现在我们可以回到测量可观测数据之间距离的简单概念上来对BCI数据进行分类。黎曼几何提供了处理对称正定矩阵的自然框架,许多结构协方差矩阵都属于这种类型。无论协方差矩阵是如何定义的,MDM-Riemannian分类器对于所有三种BCI模式,即运动想象、事件相关电位和稳态诱发电位,都是适用的。接下来脑科学家就可以将电生理知识与数学形式联系起来:定义适当的协方差矩阵,并根据脑机接口领域的数据嵌入相关信息。
MDM-Riemannian算法的一个独特方法是,在任何一点上都是确定的,完全没有参数。这与更复杂的机器学习方法(如支持向量机)形成对比,支持向量机必须通过交叉验证来优化一个或多个参数。因此,我们声称MDM-Riemannian方法可以有目的地用于所有BCI模式;事实上,结合其简单性、快速学习的能力(几乎没有训练数据)、良好的跨学科和跨课时概括能力,它很好地符合上面列出的八个要求。
目前大多数关于BCI信号处理的研究仍是通过改进空间滤波器来进行的,因此我们可以说,自从CSP在15年前被接受以来,BCI领域的第一个主要范式转变就是黎曼几何的引入。我们观察到,空间滤波器的改进仅带来基于分类目的的适度改进,并且这种改进不容易转化为可靠性和健壮性的显著提高。事实上,空间滤波器在本质上是高度依赖于被估计数据的,也就是说,它本质上是受特定被试和试次约束的,这说明其健壮性并不行,并且限制了迁移学习效果。尽管如此,正如15年多的实践所证明的那样,CSP和相关方法在经典的测试训练过程中效果还是可以接受的。