BGP/MPLS虚拟专用网络原理介绍+报文分析+配置示例
个人认为,理解报文就理解了协议。通过报文中的字段可以理解协议在交互过程中相关传递的信息,更加便于理解协议。
因此本文将以典型场景下的MPLS/LDP L3VPNs为例对MP-BGP进行分析,以详细介绍相关内容。

关于BGP/MPLS工作原理的相关内容,可参考2006年发布的RFC4364。
关于MP-BGP协议的相关内容,可参考2007年发布的RFC4760。
关于LDP协议原理相关内容,可参考博客MPLS/LDP原理介绍+报文分析+配置示例。
关于BGP协议原理相关内容,可参考博客BGPv4-原理介绍+报文分析+配置示例。
关于LDP协议报文的相关参数,可参考IANA的Label Distribution Protocol (LDP) Parameters。
关于BGP-4+协议报文的相关参数,可参考IANA的 SAFI Parameters。
关于BGP-4+的扩展团体属性的相关取值,可参考IANA的BGP Extended Communities。
关于以太网PW承载Ethernet/802.3 PDU的相关内容,可参考2006年发布的RFC4448。
关于OSPF和BGP/MPLS VPN的联动相关内容,可参考2006年发布的RFC4577。
关于Constrained Route约束路由的相关内容,可参考2006年发布的RFC4684。
关于BGP在VPLS场景下的自动发现和信令传递,可参考2007年发布的RFC4761。
关于LDP在VPLS场景下的信令实现,可参考2007年发布的RFC4762。
关于LDP在PW建立和维护上的实现,可参考2017年发布的RFC8077。
关于BGP传递特定标签前缀的实现,可参考2017年发布的RFC8277。
…
BGP/MPLS VPN还存在大量相关RFC,感兴趣者可查阅相关资料。
MPLS(Multiprotocol Label Switching)发展早期,主要用于加快数据包转发。随着转发芯片等硬件水平的发展,MPLS目前主要用于承载多种类型的上层网络满足多种复杂场景的应用。
虚拟专用网络(Virtual Private Network,简称VPN)属于远程访问技术,简单地说就是利用公用网络架设专用网络——VPN 网络的任意两个节点之间没有实际的端到端的物理链路,而是通过互联网络搭建的一个虚拟的通道来实现端到端的数据传输。这里主要介绍的是BGP/MPLS L3VPN。
第2和第3章节基本描述了MPLS/LDP的相关内容,有基础者可直接阅读相关内容。
目录
MPLS/LDP L3VPNs
- 目录
- 1.基础内容
-
- 1.1.背景介绍
- 1.2.BGP/MPLS虚拟专用网络
- 1.3.相关术语
- 2.实现原理
-
- 2.1.MP-BGP协议
- 3.BGP/MPLS L3VPN跨域场景
-
- 3.1.VRFs(VPN Routing and Forwarding tables)
- 3.2.OptionA方案
-
- 3.2.1.场景分析之控制面
- 3.2.2.场景分析之转发面
- 3.2.3.配置举例及注意事项
- 3.3.OptionB方案
-
- 3.3.1.场景分析
- 3.3.2.配置举例及相关介绍
- 3.4.OptionC方案1
-
- 3.4.1.场景分析
- 3.4.2.配置举例及相关介绍
- 3.5.OptionC方案2
-
- 3.5.1.场景分析
- 3.5.2.配置举例及相关介绍
- 3.6.跨域方案优劣简介
- 4.CE和PE的互操作细节
-
- 4.1.CE--PE的ISIS重分发
- 4.2.CE--PE的OSPFv2重分发
-
- 4.2.1.原理分析
- 4.2.2.MPLS Domain超级骨干域
- 4.2.3.典型场景及配置示例
- 4.2.4.Sham Links及配置举例
- 4.3.CE--PE的BGP SoO属性
- 4.4.常用查看命令
- 更新
1.基础内容
1.1.背景介绍
虚拟专用网络:
Virtual Private Network(虚拟专用网络)是通过互联网从设备到网络的加密连接。加密连接有助于确保敏感数据的安全传输。它防止未经授权的人窃听流量,并允许用户远程进行工作。
为什么企业使用VPN:
VPN是一种经济高效的方式,可以安全地将远程用户连接到公司网络,同时提高连接速度。有了VPN,企业可以使用高带宽的第三方互联网接入,而不是昂贵的专用WAN(广域网)链路或远程拨号链路。
什么是安全远程访问:
安全远程访问是一种将远程用户和设备安全连接到公司网络的方法。它包括VPN技术,该技术对用户或设备进行身份验证,确认他们满足某些要求(也称为“姿势”),然后才能远程连接到网络。
什么是VPN“隧道”:
“隧道”是VPN建立的加密连接,这样虚拟网络上的流量就可以安全地通过互联网发送。来自计算机或智能手机等设备的VPN流量在通过VPN隧道时会被加密。
目前常用的VPN 技术:
IPsec(互联网协议安全,Internet protocol Security) VPN 、SSL( 安全套接层协议层, Security Socket Layer-SSL)VPN、、VPDN( 虚拟专用拨号网,Virtual Private Dial - up Networks)和MPLS(多协议标签交换,Multi-Protocol Label Switching)VPN 等。
IPsec VPN不是一个单独的协议,它给出了应用于 IP 层上网络数据安全的一整套体系结构。该体系结构包括认证头协议(Authentication Header,AH )、封装安全负载协议(Encapsulating Security Payload,ESP)、密钥管理协议( Internet Key Exchange,IKE)和用于网络认证及加密的一些算法等。IPsec VPN 的搭建不需要电信运营商的参与,不能穿越通常的NAT、防火墙。
SSL VPN是一种基于WEB应用的安全协议,也通常和HTTPs结合使用。SSL VPN通过在远程接入用户和SSL VPN网关之间建立SSL连接、SSL VPN网关对用户进行身份认证等机制对用户数据流量进行保护。SSL VPN和IPsec VPN在架构上一个为浏览器 / 服务器端 (B/S) 应用构架,另一个为客户端 / 服务器端 (C/S) 应用构架。
VPDN是在中国宽带互联网基础上开放的基于拨号方式的虚拟专有网络业务。它向用户提供采用PSTN、ISDN、XDSL、电缆或无线以拨号方式接入中国宽带互联网。VPDN隧道协议有点到点隧道协议(PPTP)、第二层转发协议(L2F)、第二层隧道协议(L2TP)等几种。
MPLS VPN 是电信运营商大量使用的VPN技术,具有较高的灵活性和可扩展性,可以实现点到点,点到多点和任意接入点之间互访的全网状结构,满足用户不同的通信需求。MPLS VPN利用标签交换,一个标签对应一个用户数据流的方式来区分不同的用户,从而实现用户间数据的隔离的VPN 网络,MPLS VPN 网络主要由CE 路由器、PE 路由器和P 路由器3 部分组成
1.2.BGP/MPLS虚拟专用网络

BGP/MPLS虚拟专用网络总的可分为L3和L2类型。其中L2VPN又有ATOM(Any Transport Over MPLS)、VLL(Virtual Leased Line,有时候也称VPWS(VirtualPrivateWanService))和VPLS(VirtualPrivateLanService)等。其他的L2VPN还有L2TP(Layer Two Tunnel Protocol)、EVPN(Ethernet Virtual Private Network)和PBB-EVPN(Provider Backbone Bridging-EVPN)等。
扩展阅读:
ATOM(Any Transport Over MPLS):是一种在三层MPLS/LDP骨干网上传输二层数据包/帧的解决方案。ATOM支持Frame Relay、ATM AAL5、ATM Port Mode、Ethernet VLAN、PPP、HDLC、Sonet/SDH等多种网络模型。基本工作原理类似L3VPN使用双层标签。
VLL(Virtual Leased Line):有时也称为VPWS(VirtualPrivateWanService)是一种建立在MPLS/LDP技术上的点对点的二层隧道技术。主要用于解决以太网、ATM、FR、HDLC等不同二层网络间的隔离问题。实现方式是通过 VC(Virtual Circuit)区分客户数据,为不同客户提供逻辑上的专有通道。
VPLS(VirtualPrivateLanService):是在公用网络中提供的一种点到多点的L2VPN业务。通过这种方式可以实现地域上隔离的用户站点能通过MAN(Metropolitan Area Network,城域网)或WAN(Wide Area Network,广域网)相连,并且使各个站点间的连接效果像在一个LAN中一样。主要实现步骤可分为对端PE设备成员发现和LDP信令协议创建和维护PW。
L2TP(Layer 2 Tunneling Protocol):一种用于承载PPP报文的隧道技术。这种方式通常需要在客户终端上运行相应客户端。用户通过PPPoE客户端拨入LAC(L2TP Access Concentrator),LAC作为PPP/PPPOE终结和LNS(L2TP Network Server)之间建立L2TP隧道。关于L2TP原理的相关内容,可参考1999年发布的RFC2661等资料。
自动换行
关于MPLS L2VPN的相关概念,可参考相关博客。

1.3.相关术语
AC(Attachment Circuit):接入电路,指连接CE与PE的链路,对应的接口可以是实际的物理接口,也可以是虚拟接口。
SP(Service Providers):网络服务供应商,有时也称ISP。ISP提供的P、CE和PE构成了公网。
P(Provider):SP 网络中未连接到客户边缘设备的路由器。
CE(Custom Edge):直接与服务提供商相连的用户边缘设备。
PE(Provider Edge):服务运营商网络上的边缘设备,与CE相连,主要负责VPN业务的接入。
PE又可分为UPE(User facing-Provider Edge/User Provider Edge)和NPE(Network Provider Edge)。
UPE是指靠近用户侧的PE设备,主要作为用户接入VPN的汇聚设备。
NPE是指网络核心PE设备,处于VPLS网络的核心域边缘,提供在核心网之间的VPLS透明传输服务。
例如在L2VPN桥接L3VPN时,L2VPN靠近客户的PE为UPE而L2VPN和L3VPN桥接点PE为NPE。
CPE(Customer Premise Equipment):是一种接收移动信号并以无线WIFI信号转发出来的移动信号接入设备。 一台典型的CPE是一台功能齐全的无线路由器,能够为终端设备提供宽带连接和无线网络。
Site:简单来说是指一组具有不需要使用骨干网的相互IP互连系统。一台CE设备总是可以认为成一个站点,同时站点可能有多个VPN。
UNI(User Network Interface):通常指用户设备(包括IP路由器、ATM交换机、SDH交换机等)和智能光网络之间的接口。
NNI(Network to Network Interface):通常指网络节点互联的接口,它包含了传输网络的两种基本设备,即传输设备和网络节点设备。NNI就是设备之间的接口协议,根据设备不同,业务类型不同,NNI接口的具体内容不同。
VSI(Virtual Switch Instance):将接入电路映射到各条虚拟链路上。每个VSI提供单独的VPLS服务。
PW(Pseudo Wire):在两个VSI之间的一条双向的虚拟连接。
VRFs(VPN Routing and Forwarding tables):虚拟路由转发表实例,在HW中称为VPN实例。在设备单独分配一块处理区域用于单独模拟一台物理设备,处于VRF实例中的接口或进程称为私网接口私网进程。
RD(Route-Target):VRF实例中本地唯一的ID,用于VRF实例间的相互区分。在L3VPN中也可和私网前缀组成VPNv4路由进行路由区分。
RT(Route-Target):VRF实例中的路由收发标识。可分为入方向RT和出方向RT。只有相匹配了对应RT值才可进行相应路由的接收。
RFC4360中定义了 BGP Extended Communities Attribute,这种 Type Code 16 的 Attribute 是一种可选过渡的属性。这一属性又可分为多种 Extended Community Sub-Types。
RFC4360 中定义每一种 Extended Community 有 8 字节:其中 Type 字段分为 Type high 和 Type low:
Type high:1字节,主要用于描述 Extended Community 是 Regular 类型还是 Extended 类型。RFC4360中将这一字节的高位bit进行了定义,I-bit (IANA-bit 用于描述是否支持 First Come First Serve) 和 T-bit (Transitive-bit 用于描述是否支持在AS内传递。)。
例如在 RFC7153 中有区分: 0x00 为 Transitive Two-Octet AS-Specific Extended Community;0x01 为 Transitive IPv4-Address-Specific Extended Community;0x02 为 Transitive Four-Octet AS-Specific Extended Community;0x03 为 Transitive Opaque Extended Community;0x06 为 EVPN Extended Community;等等 Type high 不在进行介绍,感兴趣者可自行查阅资料。
Type low:1字节,主要用于描述每种 Extended Community 的具体类型。
自动换行
这里提到的 Route-Target 属性便是其中一种 Extended Community Sub-Types。
- 0x0002 定义于 RFC4360 表示 Transitive Two-Octet AS-Specific 的 Route-Target;
- 0x0102 定义于 RFC4360 表示 Transitive IPv4-Address-Specific 的 Route-Target;
- 0x0202 定义于 RFC5668 表示 Transitive Four-octet AS 的 Route-Target;
- 0x0002 定义于 RFC5701 和 RFC7153 表示 IPv6-Address-Specific Extended Community 下的 Route-Target,其与上述所描述的 Extended Community 区别在于长度为 20 字节。
自动换行
这里几种 Route-Target 属性的区别是 Value 字段的组成格式不同,通常采用 0x0002 格式下的 Route-Target。这里不在进行进一步介绍,感兴趣者可查阅相关资料。
点击此处回到目录
2.实现原理
2.1.MP-BGP协议
MP-BGP协议也即Multiprotocol Extensions BGP是对BGP-4协议的扩展,有时也将该协议称为BGP-4+。扩展后的BGP协议可以用于支持承载多个网络层协议(例如,IPv6,IPX,L3VPN等)的路由信息。
为了实现多协议扩展,BGP需要满足的两个条件是:
1@:将多协议信息与Next_Hop信息进行关联。
2@:将多协议信息与NLRI(Network Layer Reachable Information)信息进行关联。
这里以IPv6为例进行BGP-4+报文上的相关增改说明:
关于BGP-4协议原理相关内容,可参考博客BGPv4-原理介绍+报文分析+配置示例。这里不做过多说明,而直接进行比对
1@=Open:
 Open报文主要用于对等体间的参数协商,而且在协商之前由TCP进程进行网络信息的相关确认。某些信息例如GTSM其实就是借助TCP/IP来实现的。
Open报文主要用于对等体间的参数协商,而且在协商之前由TCP进程进行网络信息的相关确认。某些信息例如GTSM其实就是借助TCP/IP来实现的。
而且就Open报文结构而言,对等体间的相互区分只通过BGP Identification或Router-ID来实现。而Capability能力由相关TLV来协商。BGP-4+实际上不需要进行额外更改,仅需增加定义相关Capability TLV就好。
因此单纯而言BGP-4+并未更改Open报文,只是增加了一个Capability=Multiprotocol extensions capability
这就是TLV格式定义报文的好处之一,相比之下OSPF对IPv6的支持就需要定义一个新的报文格式OSPFv3。
BGP默认携带该Capability。
自动换行
2@=Update:
而对于Update报文,相关情况发生相应变化。这主要是由于格式报文字段的相应考虑。
BGP-4的Update报文格式
 在Update报文中Withdrawn Routes Length和Withdrawn Routes用于路由撤销的使用,并通过相应字段长度的定义来实现相应内容。
在Update报文中Withdrawn Routes Length和Withdrawn Routes用于路由撤销的使用,并通过相应字段长度的定义来实现相应内容。
Total Path Attribute Length和Path Attributes (variable)用于表明携带路由的相关属性。
Network Layer Reachability Information (variable)则携带了具体的路由信息。
 尽管Withdrawn Routes和Network Layer Reachability Information (variable)可以通过报文确认相关的路由。例如上图的NLRI先指定了24 bit的路由信息前缀,后续就可以只携带24bit的路由信息。理论上IPv6前缀也可通过这种方式来进行传递。
尽管Withdrawn Routes和Network Layer Reachability Information (variable)可以通过报文确认相关的路由。例如上图的NLRI先指定了24 bit的路由信息前缀,后续就可以只携带24bit的路由信息。理论上IPv6前缀也可通过这种方式来进行传递。
在RFC4760中似乎并未明确说明为何没有使用这种方式,或者如其所说为了为了提供向后兼容性,并简化将多协议功能引入BGP-4。
在这种情况下,BGP-4+引入了两个新增Path Attribute:Multiprotocol Reachable NLRI (MP_REACH_NLRI)和Multiprotocol Unreachable NLRI (MP_UNREACH_NLRI)。这两个属性都是Optional可选且Non-Transitive非传递属性。
Multiprotocol Reachable NLRI:携带一组可到达的目标以及用于转发到这些目标的下一跃点信息。(Type Code 14)
 Address Family Identifier与 Subsequent Address Family Identifier结合使用:结合使用共同确定。标识下一跳中携带的地址必须属于的网络层协议集、下一跃点的地址的编码方式以及随后的NLRI的定义。 如果允许下一跳来自多个网络层协议,则下一跃点的编码必须提供一种确定其网络层协议的方法。
Address Family Identifier与 Subsequent Address Family Identifier结合使用:结合使用共同确定。标识下一跳中携带的地址必须属于的网络层协议集、下一跃点的地址的编码方式以及随后的NLRI的定义。 如果允许下一跳来自多个网络层协议,则下一跃点的编码必须提供一种确定其网络层协议的方法。
SAFI:
1-63: Standards Action;
64-127: First Come First Served;
128-240: Some recognized assignments below, others Reserved;
241-254: Reserved for Private Use.
Length of Next Hop Network Address:描述了下一跳地址长。
Network Address of Next Hop:下一跳信息。
Network Layer Reachability Information (NLRI):可变长度字段,它列出了此属性中通告的可行路由的 NLRI。
支持IPv6网络的BGP-4+协议的Multiprotocol Reachable NLRI示例
如上图指示的是IPv6的单播地址族。其他常用的地址族还有
和
等。
Multiprotocol Unreachable NLRI:携带一组无法到达的目的地。(Type Code 15)
 Multiprotocol Unreachable NLRI和Multiprotocol Reachable NLRI字段含义基本相同。
Multiprotocol Unreachable NLRI和Multiprotocol Reachable NLRI字段含义基本相同。
支持IPv6网络的BGP-4+协议的Multiprotocol Unreachable NLRI示例
此外,包含 MP_UNREACH_NLRI 的 UPDATE 消息不需要携带任何其他路径属性。
需要注意
1@BGP-4+协议的Update报文中只有Total Path Attribute Length和Path Attributes (variable)字段是有意义的。而其他字段都无意义;
2@BGP-4协议和BGP-4+协议底层协议和自身协议基本相同,但两者不能相互通用。例如IPv6协议必须建立自己的TCP会话,并且IPv6的BGP对等体通常无法传递IPv4协议路由信息。(SRv6等特殊场景除外)。报文上是无法通用的。
自动换行
3@=Notification、4@Keepalive=和5@=Route-Reflesh:和Open报文的处理原则相同,这三种BGP报文格式基本也无变化。
点击此处回到目录
3.BGP/MPLS L3VPN跨域场景
上文我们已经介绍了场景所涉及的协议:MP-BGP和MPLS/LDP。但在场景实际生效时还存在诸多细节需要确认,这里将一一进行相关介绍。
这里说的跨域场景指的是,搭建的公网环境处于不同的AS域中。而且由于非跨域场景与OptionA场景几乎并无详细差别,因此将其在跨域OptionA方案进行结合说明。
3.1.VRFs(VPN Routing and Forwarding tables)
VRFs(VPN Routing and Forwarding tables):虚拟路由转发表实例,在HW中称为VPN实例。在设备单独分配一块处理区域用于单独模拟一台物理设备,处于VRF实例中的接口或进程称为私网接口私网进程。
RD(Route-Target):VRF实例中本地唯一的ID,用于VRF实例间的相互区分。在L3VPN中也可和私网前缀组成VPNv4路由进行路由区分。
RT(Route-Target):VRF实例中的路由收发标识。可分为入方向RT和出方向RT。只有相匹配了对应RT值才可进行相应路由的接收。
在《1.基础内容》章节,我们提到了VRF的概念。这是VPN实现的一个重要概念。并在实现上主要具有如下几个特点:
1@:VRF实例是在本地重新虚拟出了一台三层隔离设备。通常VRF实例是基于三层接口的,只有同属于一个VRF实例的流量才能进行互通。
2@:VRF实例只具有本地意义。在就报文本身而言,数据帧并不知道其属于哪一个VRF实例不存在固定的类似动态路由协议所定义的格式。VRF的实现是通过厂家自己的内部代码来实现流量隔离的。
3@:通常将未加入VRF实例的网络称为公网,对应公网路由。处于VRF实例中的网络称为私网,对应私网路由。这里可能并不指的是192.168.0.0/24一类的RFC指定的IPv4地址私网地址。
在这里先简单介绍下VRFs的使用举例:
 //如果我们建立如上的拓扑,并将AR1上的三个物理口分别加入公网、VRFs实例test1和例test2中。
//如果我们建立如上的拓扑,并将AR1上的三个物理口分别加入公网、VRFs实例test1和例test2中。
 //VRFs实例通过RD值也即route-target进行相应区分,具有本地唯一属性。(这里的本地唯一指的是可以在其他物理设备上进行相同配置。)同时也在L3VPN for IPv4场景下与IPv4地址组成VPNv4地址。
//VRFs实例通过RD值也即route-target进行相应区分,具有本地唯一属性。(这里的本地唯一指的是可以在其他物理设备上进行相同配置。)同时也在L3VPN for IPv4场景下与IPv4地址组成VPNv4地址。
此外这里未指定RT值(HW称为VPN-target),RT的作用主要由于不同VPN站点间的路由收发上控制。
将在下文进行相关介绍。
在这种情况下,实际上在AR1形成了三块独立进行流量路由的三块区域。只是物理环境上在同一台路由器上。也即下图:
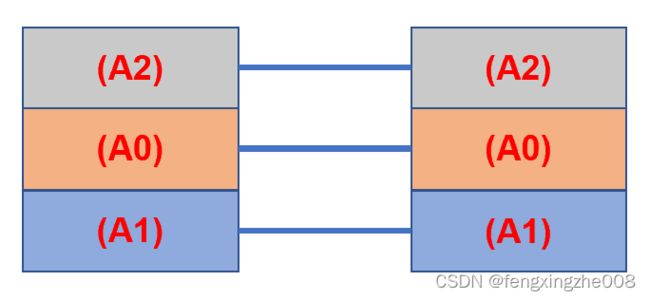 同时在设备上分别具有两个test实例的路由转发表,并且由于VRFs实例是隔离的因此可以配置相同的地址空间:
同时在设备上分别具有两个test实例的路由转发表,并且由于VRFs实例是隔离的因此可以配置相同的地址空间:

扩展阅读之私网路由泄露:
在某些场景下需要将私网VRFs实例的流量导入到公网中,此时的操作可称为私网路由泄露。
//将私网test1的10.1.1.0/24的数据路由到公网下一跳192.168.1.1。当然,将私网路由泄露到其他私网实例中也是可以的。
3.2.OptionA方案
OptionA方案本质是将2个ASBR互相当作自己AS区域的CE设备。因此在ASBR之间进行操作是不携带标签进行转发。
所以这里仅在最后进行相关介绍说明,不与非跨域L3VPN进行过多区分。
 场景介绍:
场景介绍:
1@:AR1、AR2和AR3组成公网环境搭建LDP隧道。
2@:AR4、AR5、AR6和AR7分别作为CE设备作为不同站点。
3@:相关的路由在AR1和AR3这两台PE上进行传递和控制。
这里可以仅选择AR4和AR6进行展示即可,其他CE设备的处理结果类似。
3.2.1.场景分析之控制面
控制面通常指的就是指导流量的路由收发情况。
要实现设备具有正常的路由,应当实现或建立如下功能:
1@:AR1、AR2和AR3应当建立underlay网络。这一过程主要用于隧道站点间的PE设备建立MP-BGP邻居。
在建立了MP-BGP邻居后,PE之间就有了传递私网路由的可能性。
2@:AR1、AR2和AR3应当建立MPLS/LDP隧道。这是因为公网环境下无私网路由,会有路由黑洞。通过在PE、P和对端PE之间建立LSP转发路径,便可依据标签进行转发。
AR1、AR2和AR3应当建立underlay网络也为这里的LDP隧道建立提供支持。因为LDP协议是依据路由表进行转发的。
3@:AR4和AR6之间(CE和PE之间)应当进行双点双向重分发。因为私网需要对端私网明细路由进行转发,PE设备则需要针对私网路由进行传递。
路由控制–RD/RT值:
 RD值:8字节。主要用于地址复用和标识VPN路由。如图在上图MP-BGP传递的Multiprotocol Reachable NLRI中的BGP Prefix部分携带并且与IPv4 Prefix共同组成了VPNv4路由。
RD值:8字节。主要用于地址复用和标识VPN路由。如图在上图MP-BGP传递的Multiprotocol Reachable NLRI中的BGP Prefix部分携带并且与IPv4 Prefix共同组成了VPNv4路由。
在《3.1.VRFs(VPN Routing and Forwarding tables)》章节中我们已经介绍了VRFs的地址复用问题,当时我们指出RD实际上是设备本地概念。然而如果在VPN场景下还用于组成VPNv4路由,此时RD值也就具有全局意义。因此此处的RD应当全局规划唯一。
自动换行
 RT值:8字节。主要用于路由收发控制。如图在上图MP-BGP传递路由时,还额外传递了一个扩展团体属性,并在该属性中携带了600:100和400:100两个RT值。
RT值:8字节。主要用于路由收发控制。如图在上图MP-BGP传递路由时,还额外传递了一个扩展团体属性,并在该属性中携带了600:100和400:100两个RT值。
RT的作用在于路由收发控制,具体来说在VRFs实例本地处会建立入方向和出方向的两个RT值。在本地VRFs路由表中只接受具有与本地入方向相同RT的路由。
//例如此处指定就是入方向400:100和600:100以及出方向的400:100和600:100。
那么MP-BGP的update报文携带的是哪个呢?是只携带出方向列表的RT值。因为入方向是本地控制路由收发的也就没有必要在报文中携带进行通告了。
路由控制–Label:
在上图MP-BGP传递的Multiprotocol Reachable NLRI中的BGP Prefix字段中,我们还可以发现一个24bit的Label。这一标签是由MP-BGP为私网VRFs实例进行分配的。主要用于转发面上的流量识别。
3.2.2.场景分析之转发面
AR4–>AR1–>AR2–>AR3–>AR6:
CE设备AR4–>:CE侧通过远端通告或传递而来的对端私网路由将流量指向本端PE设备AR1。
这一过程与路由的普通转发完全相同,而指向对端私网路由不一定需要由远端传递而来。使用静态路由/缺省路由方式当然也可以。
PE设备AR1–>:本段PE接受到来自CE设备的流量后,为该数据流首先打上内层私网标签。下一跳节点为远端PE,因此路由迭代到MPLS/LDP隧道中。此时再次打上外层公网标签从相应接口进行转发。
1@此处的内层标签由与对端PE建立MP-BGP邻居分配用于流量上的VRFs实例区分。在转发面的流量到达时,设备需要通过报文上的某个标识来向特定VRFs实例转发流量。这一报文标识是通过Label来实现的。
2@本地PE的流量标识同样需要知道应当绑定哪个私网内层标签,这是通过本地绑定了特定VRFs实例的接口来识别的。
3@默认情况下,LDP协议可为VPN路由自动迭代下一跳到MPLS/LDP隧道。因此无需额外配置。
P设备AR2–>:P设备承担的动作是公网标签的SWAP操作,在公网中间节点设备无需关注内层数据。仅需校验核对标签进行转发即可。
1@当然,对于倒数第二跳节点还需要进行Penultimate Hop Poppoing倒数第二跳弹出。
PE设备AR3–>:通常经过了PHP操作后的数据流应当只携带特定VRFs实例的私网标签。PE设备收到后,就将内层标签进行剥离从相应VRFs私网路由表中查询下一跳进行相应转发。
1@PE设备接受到流量中的内层私网标签是自己MP-BGP为私网路由分配。
//apply-label per-instance可以指定MP-BGP为私网路由分配基于VRFs实例,此种情况适用于存在VRFs实例大量私网路由表时每个VRFs实例只分配一个Label。这样可用于节省标签空间和设备资源使用。默认为每条私网路由分配Label,也即apply-label per-route方式。
此外,还有apply-label per-nexthop。用于针对下一跳分配标签。主要用于Options B场景下节省标签空间和设备资源使用。
CE设备AR6–>:对端CE设备接受到的数据流是一个正常状态不携带Label的数据包。对该数据包的转发行为与普通路由转发完全相同。
3.2.3.配置举例及注意事项
1@这里只提供了PE设备关键配置,有能力者可自行进行其他P和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
ip -instance -4
ipv4-family
route-distinguisher 4:1
-target 400:100 export-extcommunity
-target 400:100 import-extcommunity
#
bgp 100
router-id 1.1.1.1
peer 2.2.2.2 as-number 100
peer 2.2.2.2 connect-interface LoopBack1
#
ipv4-family unicast
undo synchronization
undo peer 2.2.2.2 enable
#
ipv4-family v4
policy -target
peer 2.2.2.2 enable
#
ipv4-family -instance -4
import-route direct
#
配置注意事项:
1@:本实例中还指定了P设备作为RR,此种场景适用于大型网络下的网络涉及需要。此时需要在VPNv4地址族下undo policy -target。因为BGP将接受到的VPNv4路由与本地VRFs实例进行比对,丢弃本地不存在的VRFs实例路由。
Cisco对应命令为bgp default route-target filter。
2@:Huawei的LDP协议分配标签时,仅对32位主机路由分配标签。
此外还可以指定路由策略针对特定BGP路由生成LSP。
需要注意的是不同设备的支持情况不同,有些设备还可支持route-filter路由过滤。同时需要关注地址族情况。

3@:这里PE给出的重分发方式为引入静态路由,CE上同时也指定出向的静态路由。这样的一个好处是简单,但是无法进行路由的动态控制。常用的一个方式是在CE和PE之间使用IGP协议,随后在PE上进行IGP和BGP的双向重分发。(远端MP-BGP路由导入私网路由给IGP,IGP将本地私网导入BGP以便传递给远端MP-BGP。)
需要注意的是,PE上建立的IGP协议需要指定对应的VRFs实例。否则PE不认为接收到的路由为私网路由也就无法完成重分发。
自动换行和
//建立私网IGP邻居。当然利用BGP做IGP使用也可以,这里不在做说明。
自动换行
需要注意的是利用IGP进行双点双向重分发时,常常会有多归多活场景,此时需要考虑引入的私网路由防环问题。这一考虑将在下文进行介绍。
4@:VRFs实例简单理解是基于本地的,也就只要PE指定特定的VRFs实例。CE侧实际上是不感知自己的私网状态的。当然在不影响流量通信情况下,也可指定VRFs实例。
此处有一种场景是Multi-VPN-Instance CE:如果在CE上需要进行路由隔离时就可以在CE上建立多个VRFs实例与PE进行对接。
自动换行
OptionA场景解读:
简单来说就是ASBR的PE设备互相将对端当作自己的CE设备。这样的一个好处是方案简单,实现快捷。但是需要注意的是在ASBR之间进行路由导入时,如果使用OSPF等协议可能会由于DN-bit等原因而无法重引入。
但是通常PE节点具有多个VRFs实例,此时就需要针对每个VRFs实例启动多个子接口建立普通邻居。这样对设备性能是很大的考验。
点击此处回到目录
3.3.OptionB方案
在重点介绍各种跨域场景之前,恐怕有一个问题需要解决。那就是为什么需要跨域?
1@:在控制面上,这个问题是好解决的。我们可以通过各种协议,例如BGP,将路由传递到对端VRFs中。尽管有时可能会存在某些路径由于缺少路由下一跳而导致BGP路由无效,但是仍然可以通过重分发IGP或者宣告下一跳解决。
2@:但是在转发面上,这个问题就难以实现了。
第一个问题在于流量在进入自己站点时,需要先嵌套内层标签。在单域场景下,该标签由对端PE为特定FEC/前缀分配至传递至本站点PE。这一内层标签作用在于流量到达对端PE用作流量标识。
那么在跨域场景下,内层私网标签应当如何分配。
第二个问题在于流量进入 BGP/MPLS 隧道后需要嵌套外层标签。该外层标签由LDP为特定FEC/前缀(underlay网络前缀)分配,也就需要在 BGP/MPLS 隧道都为该FEC/前缀分配标签。
那么在跨域场景下,外层公网标签应当如何分配。
OptionB解决方案:
本质是利用MP-BGP协议为EBGP邻居传递而来的VPNv4路由分配标签。此时,流量在经过ASBR时会使用单层标签进行相应数据流的转发。
3.3.1.场景分析

场景介绍:
1@:AR7和AR8作为CE节点单归至PE节点AR1和AR6。
2@:AR1、AR2和AR3以及AR4、AR5和AR6分别形成AS自治系统100和AS自治系统200,并在各自自治系统中建立BGP/MPLS Domain。AR2和AR5分别作为各自AS的RR设备。
3@:AR3和AR4分别作为ASBR设备建立MP-BGP传递VPNv4路由。
控制面行为分析:
这里以私网路由8.8.8.8/32的传递为例进行说明,其他情况可参照说明。
1@:对端PE节点AR6设备接收到重分发入BGP的私网路由,将其转化为VPNv4路由向对端传递。
该路由下一跳为自身建立BGP对等体关系的loopback地址。并且携带了自身为该私网路由分配的标签。
2@:对端ASBR节点AR4设备接收到该VPNv4路由,将其传递给另一个AS的eBGP邻居(或者说MP-eBGP邻居)。也即本ASBR节点AR3设备。
- 这里在各自AS内启用了RR,相关内容可参考博客BGPv4-原理介绍+报文分析+配置示例。
- 这里由于是VPN环境,有特性默认更改VPNv4路由下一跳为自身。普通IP路由不会更改。
3@:本AS的ASBR节点AR3设备收到该VPNv4后,将该路由向私网PE节点AR1进行转发。
Q:这里传递的VPNv4路由相关属性如何
- RT属性需要经本地VPN RT策略进行确认接收。这里可以体现OptionB方案的一个好处是,进行了类似路由策略的效果对路由进行了过滤。而OptionA方案则只是将路由不经选择的重分发出去。(或者需要额外的路由策略)。
- 标签属性更改,原先的私网标签用于AR4节点上嵌套内层标签。该内层标签为OUT标签,需要AR4节点的MP-BGP分配IN标签为本端AS提供。
- 当然本AS的ASBR节点AR3在传递该VPNv4路由时,为iBGP邻居更改下一跳为自身Loopback地址。
4@:PE节点AR1接收到该路由后,验证合格后放入VRFs表中转化为普通IPv4路由重分发入IGP。
这里同样需要进行RT过滤。
转发面行为分析:
这里重点介绍相应的流量转发行为
1@:CE节点AR7根据普通路由表进行2层封装发往下一跳PE节点AR1。
2@:本端PE节点AR1收到该流量后,查询VRFs路由表指向本AS内的ASBR节点AR3。并需要封装内层私网标签。
//这里显示该VPNv4路由原始下一跳为3.3.3.3,并且Label为1027。

查询fib表公网下一跳表应当迭代入BGP/MPLS 隧道中。并Push相应的公网标签:
//TunnelID非0表示需要迭代隧道。这里默认迭代BGP/MPLS隧道。
//MPLS LSP路径显示出标签为1024,也即Push相应的公网外层标签1024。
自动换行
1@这里说默认迭代BGP/MPLS BE隧道,当然就有在TE场景或者存在RSVP-TE,GRE隧道的情况。此时就需要根据策略路由将相应的流量导入隧道中去了,隧道之间可以支持负载分担等方式。
2@这里可能有疑问为什么FEC的3.3.3.3有两个LSP条目。另一个条目是自身作为Transit节点产生的,只是这里未真正建立AR1节点的上游设备。
3@:流量经本AS的BGP/MPLS隧道SWAP后到达本AS的ASBR节点,检查相应的标签后继续向对端发送。
//本AS的ASBR节点AR3的LSP上看,外层公网标签已经POP弹出只露出私网标签1027。该私网标签又可迭代对端AS的ASBR节点AR4设备分配而来的1027向对端进行发送。
//本AS的ASBR节点AR3收到另一个AS传递而来的VPNv4路由也可以佐证这一点。
因此在本AS的ASBR节点AR3需要将内层Label=1027进行SWAP为Label=1027向对端AS的ASBR节点AR4发送。当然此时就不在进行PHP。
4@:流量到达对端AS的ASBR节点AR4上,同样检查相应的标签后继续向对端AS的PE节点AR6发送。
这里进行的操作与AR1节点几乎相同,只是AR1上的流量IN标签为Null而这里为自己MP-BGP为对端AS分配的Label=1027而已。
自动换行
//从对端AS的ASBR节点AR4的LSP路径上可以看到,内层标签(L3VPN LSP)进行了一次SWAP由1027转化为了1026,外层迭代公网LSP需Push标签1024。
自动换行
//报文上也可分别看出相应的内外层标签。
这里的内层标签就为对端AS的PE节点AR6的MP-BGP所分配,外层标签为对端AS的LDP所分配。
最终的效果为:
 内层私网标签在传递时,实际上进行了SWAP操作。
内层私网标签在传递时,实际上进行了SWAP操作。
3.3.2.配置举例及相关介绍
1@这里只提供了AR3作为ASBR设备配置,有能力者可自行进行其他P(RR)和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
ip -instance -a
ipv4-family
route-distinguisher 3:3
-target 100:200 export-extcommunity
-target 100:200 import-extcommunity
#
mpls lsr-id 3.3.3.3
mpls
mpls ldp
#
bgp 100
router-id 3.3.3.3
peer 2.2.2.2 as-number 100
peer 2.2.2.2 connect-interface LoopBack1
peer 10.3.4.4 as-number 200
#
ipv4-family unicast
undo synchronization
undo peer 2.2.2.2 enable
peer 10.3.4.4 enable
#
ipv4-family v4
undo policy -target
peer 2.2.2.2 enable
peer 10.3.4.4 enable
#
配置注意事项:
1@:undo policy -target用于执行RT过滤,用于防止在自身未配置该VPN时丢弃VPNv4路由,建议在RR和这里进行关闭。
Cisco对应命令为bgp default route-target filter。
2@:在ASBR之间使用MP-BGP为特定前缀分配标签,MP-BGP也是MPLS的一种。因此需要在ASBR之间链路上开启MPLS功能。LDP协议就不需要了。
3@:HW默认为每一条路由分配标签。为了节省资源,可以在ASBR之间针对下一跳开启标签分配。
//使能ASBR按下一跳为VPNv4或VPNv6路由分标签。缺省情况下,ASBR标签分配策略是每条VPNv4或VPNv6路由分配一个标签。
自动换行
在OptionA方案中我们介绍了在VPN实例中基于实例分配标签:
//使能所有发往对端PE的路由都使用同一个标签值。缺省情况下,VPN实例地址族为每一条去往对端PE的路由分配一个标签。有时需要结合该命令使用以便使路由的入标签和出接口一致,才可使apply-label per-nexthop生效。
4@:OptionA场景的部分相关原则这里也是适用的。
点击此处回到目录
3.4.OptionC方案1
OptionC解决方案:本质是利用各种方式建立一条完整的公网LSP。
OptionC方案1给出的方式是在本端ASBR从对端的ASBR学到对端AS域内的带标签BGP公网路由后,通过策略为该路由分配标签发布给本端PE并在自己AS内建立相应公网LSP。
此时流量在经过自己AS时,携带三层Label:内层私网标签由对端AS发布。中间公网标签由对端AS发布。最外层公网标签由自己AS内发布。详细的原理及发布介绍将在后文介绍。
 //最终效果如图所示。
//最终效果如图所示。
在进行进一步介绍OptionC方案之前,似乎还隐含一个问题需要解释。各种跨域方案与不跨域到底有什么区别?根本原因在哪里?
1@:在不跨域场景下,内层标签在不同站点PE之间互相传递。公网标签由LDP自动关联BGP路由分配。
2@:在跨域场景下,情况似乎有所不同。
OptionA给出的方案是把这一过程分成两端,在各自AS内形成两段/多段毫不关联的LSP。各自负责进行转发,在AS间传递流量时不携带标签完全是普通流量转发。
OptionB给出的方案是桥接内层标签,公网标签由各自AS内各自形成各自传递。在AS间传递流量时携带标签需要内层标签SWAP的标签。
OptionC给出了终极方案,那就是私网标签直接由各自站点PE的MP-eBGP直接传递,公网标签则建立一条完整的公网LSP。这个相应的“完整性”体现将在后文进行介绍了。
从以上描述结果就比较清晰了,原因在于LDP协议虽然基于路由表进行标签分配。但是LDP似乎无法直接为跨域的IGP协议建立完成LSP,即使可能每个节点都具有相应的路由信息。
3.4.1.场景分析
上图的标签:Label1为VPN 私网标签,Label2为 BGP 标签,Label3为 Tunnel 公网标签。
同时还需注意有PHP的相关效果。
为了使OptionC方案1便于理解,我们这里直接基于流量结果进行控制面的说明。
1@:每个站点的PE需要直接建立MP-eBGP邻居传递私网路由。
Q:为什么需要直接建立MP-eBGP邻居
A:因为通过ASBR转发而来的VPNv4路由不仅会自动修改下一跳属性,NLRI的BGP Prefix字段中的Label也会被修改。
- 为了使两台PE直接建立VPNv4邻居,一个可选择的方案是在各自ASBR的BGP上宣告PE单播地址。其他方式比如重分发则会大大增加环路的风险。因为本身AS内的BGP/MP-BGP通过IGP建立邻居。
- 这里隐含了一个非常特殊的network宣告行为。BGP可以宣告自己路由表所具有的有效路由,无需关注其转发行为。此时该路由具有BGP始发属性。这在OSPF/ISIS中是不可想象,作为链路状态协议IGP传递路由方式只能network宣告自身所拥有的链路或者重分发其他路由。
2@:传递PE间的BGP/IPv4标签路由。
- 第二层标签建立的是BGP LSP,LSP的目的为对端PE节点。
- 需要说明的是这一层级间的LSP实际上是三个LSP组成:自己AS BGP分配Label+ASBR分配的标签+对端AS内公网标签。
3@:传递至ASBR的tunnel公网路由。
Q:这里已经有了到对端PE的LSP了(LDP协议分配和BGP分配结合组成的LSP),为什么还需要一层外层标签。
A:因为该LSP在AS内是不完整的。每个PE,ASBR之间已经具有了完整的LSP。或者说只要ASBR才可识别该流量。
但是流量在AS内传递时,P节点设备并无该明细路由也没有下游主动分配的标签。OptionC方案1解决方式是在上层套一层LSP,将中间的LSP迭代至本AS的ASBR上。
转发面的流量行为也就非常清楚了:7.7.7.7—>8.8.8.8
1@:本AS的PE节点AR1接收到来自私网7.7.7.7发往8.8.8.8的流量后。查表下一跳为6.6.6.6,Push私网标签。
//这里还有一些其他属性,比如最终迭代效果。
2@:本AS的PE节点AR1将流量发向6.6.6.6。该公网下一跳6.6.6.6,由本AS的ASBR节点AR3发布而来。公网路由携带BGP标签并且下一跳指向3.3.3.3,也就是自己–本AS的ASBR节点AR3。
这一层级完整的LSP为1.1.1.1—>6.6.6.6:由BGP分配的IPv4/BGP标签路由。
//这里是公网路由,BGP也为该公网路由分配的标签。这一行为是路由策略的结果。
//这里由于每个AS有RR的存在因此为RR传递;并且该路由不携带ExCommunity属性。
3@:最终AR1将7.7.7.7—>8.8.8.8的流量迭代到了本AS的ASBR节点AR3上。此时情形与普通BGP/MPLS场景一致,走LDP产生的公网Tunnel。
这里发往3.3.3.3的流量迭代入了BGP/MPLS隧道中。这一隧道为1.1.1.1<—>3.3.3.3。在该隧道中进行Label的SWAP。
//本AS的P节点AR2接受到该标签流量后,进行SWAP后出标签为3也就进行PHP操作。
4@:本AS的ASBR节点AR3收到该流量后,继续进行标签迭代。此时LSP目标节点为对端AS的PE节点AR6,也就是6.6.6.6。
//对端BGP/下游LSP分配1028标签,自己产生为上游分配1029标签。
5@:对端AS的ASBR节点AR4收到该流量,进行LSP为1.1.1.1—>6.6.6.6的SWAP操作。
//:对端AS的ASBR节点AR4为上游分配1028的标签,并且该路由为自己分配。
//同时该流量正好衔接LDP产生的LSP有下游分配标签1025。这一层级完整的LSP为1.1.1.1—>6.6.6.6,其中4.4.4.4—>6.6.6.6的部分与普通BGP/MPLS场景完全相同。
6@:流量其余部分与单域场景完全相同。
//对端AS的P节点AR5设备进行SWAP后的PHP传递给对端AS的PE节点设备AR6。
对端AS的PE节点设备AR6根据内层VPN私网标签向特定VPN实例进行转发。
 最终的展示效果如上图所示。同时需注意节点间的SWAP操作。
最终的展示效果如上图所示。同时需注意节点间的SWAP操作。
3.4.2.配置举例及相关介绍
1@这里只提供了AR3作为ASBR设备配置,有能力者可自行进行其他P(RR)和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
mpls lsr-id 3.3.3.3
mpls
#
mpls ldp
#
bgp 100
router-id 3.3.3.3
peer 2.2.2.2 as-number 100
peer 2.2.2.2 connect-interface LoopBack1
peer 10.3.4.4 as-number 200
#
ipv4-family unicast
undo synchronization
network 1.1.1.1 255.255.255.255
peer 2.2.2.2 enable
peer 2.2.2.2 route-policy PE export
peer 2.2.2.2 next-hop-local
peer 2.2.2.2 label-route-capability
peer 10.3.4.4 enable
peer 10.3.4.4 route-policy label export
peer 10.3.4.4 label-route-capability
#
route-policy label permit node 5
apply mpls-label
#
route-policy PE permit node 5
if-match mpls-label
apply mpls-label
#
相关关键内容已在《3.4.1.场景分析》中进行说明。这里仅对功能实现的关键配置进行说明。
1@:路由策略 route-policy label 用于实现为BGP的IPv4路由分配标签形成IPv4/BGP标签路由
2@:路由策略 route-policy PE 用于实现迭代成1.1.1.1<—>6.6.6.6完整的LSP。
点击此处回到目录
3.5.OptionC方案2
OptionC解决方案:本质是利用各种方式建立一条完整的公网LSP。
OptionC方案2给出的方式是在本端ASBR从对端的ASBR学到对端AS域内的带标签BGP公网路由后,将其引入IGP协议中。因此触发为带标签的公网BGP路由建立LDP LSP。
3.5.1.场景分析
 具体来说此时的1.1.1.1—>7.7.7.7流量传递途径如上图所示。
具体来说此时的1.1.1.1—>7.7.7.7流量传递途径如上图所示。
OptionC1和OptionC2的主要区别在于公网LSP的生成方式
OptionC1:通过路由策略方式强制将来自对端的公网BGP路由分配标签,并为该公网BGP路由分配标签传递给上游。

OptionC2:通过路由策略方式强制将来自对端的公网BGP路由分配标签,并通过LDP协议产生标签传递给上游。

这里额外介绍下OptionC2的RR场景:
在普通场景下需要PE之间建立MP-BGP邻居关系,ASBR建立BGP邻居关系。
相似的RR场景应变化为:
在普通场景下需要RR之间建立MP-BGP邻居关系,ASBR建立BGP邻居关系。(当然每个AS的RR需要和PE建立MP-BGP邻居关系。)
但是此时LSP由于缺少PE节点的路由ASBR之间在宣告时,不仅需要宣告RR节点的地址还需要PE节点的地址。
区别在于传递VPNv4路由时,下一跳应当保持为PE节点地址。
3.5.2.配置举例及相关介绍
1@这里只提供了AR3作为ASBR设备配置,有能力者可自行进行其他P(RR)和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
mpls lsr-id 3.3.3.3
mpls
lsp-trigger bgp-label-route
#
mpls ldp
#
isis 10
is-level level-2
network-entity 49.0000.0000.0003.00
import-route bgp
#
bgp 100
router-id 3.3.3.3
peer 10.3.4.4 as-number 200
#
ipv4-family unicast
undo synchronization
network 1.1.1.1 255.255.255.255
peer 10.3.4.4 enable
peer 10.3.4.4 route-policy label export
peer 10.3.4.4 label-route-capability
#
route-policy label permit node 5
apply mpls-label
#
相关关键内容已在《3.5.1.场景分析》中进行说明。这里仅对功能实现的关键配置进行说明。
1@:OptionC2方案实际上仅需要ASBR间建立普通eBGP邻居,PE间建立MP-BGP邻居。
2@:在各自ASBR上需要将BGP引入IGP以便正确产生完整LSP。
3@:AS间通过BGP强制将两端LDP隧道串接。
lsp-trigger bgp-label-route用于使能LDP为BGP分配标签。
点击此处回到目录
3.6.跨域方案优劣简介
为了进一步理解以上跨域方案,这里简单进行对比介绍。
OptionA
1@:OptionA本质上与普通BGP/MPLS场景并无不同。每个AS的ASBR来说都将对端AS节点当成普通PE节点,向其转发流量时已经完成了私网VPN实例的鉴别。因此但就流量来看是普通的数据流。
2@:在实现方式上,OptionA原理简单方案复杂性低。但是在每个ASBR上需要建立多个子接口多个IGP实例进行维护,并且由于缺少的VPN路由的RT属性也就缺少了进行路由过滤的能力。在具体实现上略显笨拙,且建立多个实例对设备性能有一定考验。
自动换行
OptionB
1@:OptionB的原理是每个AS内进行普通的BGP/MPLS 隧道迭代,而在ASBR之间通过VPNv4自动分配标签进行串联内层标签。
注意形成的不是完整的LSP。在每个AS内的LSP的目标节点都仅指向ASBR。
2@:OptionB的一个改进是在ASBR间建立VPNv4邻居关系,此时也就具有相关路由过滤能力。
自动换行
OptionC方案1
1@:OptionC给出了终极方案:直接建立完整的LSP,私网路由由各自AS的PE直接建立MP-BGP邻居关系传递。OptionC方案1具体实现上通过路由策略使MPLS为公网BGP路由分配标签形成了完整的LSP。
2@:这样ASBR之间甚至不在需要建立VPNv4邻居关系,只需要传递公网路由。私网路由直接由每个AS的PE进行控制维护。
自动换行
OptionC方案2
1@:OptionC方案2属于“终极方案Plus”,主要是通过BGP使能公网LDP LSP和公网BGP LSP的串接能力。
此时由于MPLS/LDP的标签通告DU+标签保留Liberal+标签分配Ordered特性,公网自动进行迭代产生LSP。(主要是Order特性。)
2@:OptionC方案2和OptionB有很多相似之处。最大的区别在于是否有完整的公网LSP。
自动换行
点击此处回到目录
4.CE和PE的互操作细节
在3章节《BGP/MPLS L3VPN跨域场景》的OptionA方案时我们提到,在PE上进行双点双向重分发时,有可能引入环路问题。我们在此浅谈下路由的防环问题。
//例如在此环境下AR3可能将来自AR2传递给AR1的私网路由重新引入到MPLS Domain中。在此种环境下就有可能导致路由环路。
4.1.CE–PE的ISIS重分发
如果在CE和PE之间建立的IGP协议是ISIS时,PE引入远端PE上的VRFs实例路由时会在ISIS的LSP报文的路由前缀上携带DU位置1的路由信息。CE接收到该路由后,不在将DU置位的路由回注到Level-2中实现路由防环。此处也不再引入到PE中去。
有关ISIS协议原理的详细内容,可参考博客《IS-IS报文分析+原理详解+典型配置》的4.2.2.章节《Level-2路由泄露》
4.2.CE–PE的OSPFv2重分发
相似的,如果在CE和PE之间建立的IGP协议是ISIS时,PE引入远端PE上的VRFs实例路由时通过LSA中的Options 字段中的DN-bit和额外携带的一个32bits的Tag字段。
其他PE接收到DN-bit置位或相匹配的4字节的Tag字段时,不将该LSA参与路由计算。
1@:PE上引入来自对端VPNv4路由进入OSPF私网实例时默认DN-bit位置位。
//依照特定LSA设置相应的Option DN-bit位,仅在OSPF私网实例中生效。
//同时也可以相应的对设备自身检查DN-bit的设置情况。
2@:注意Tag字段是一个本地概念。RFC4577定义:缺省情况下,Tag值的前面两个字节为固定的0xD000,后面的两个字节为本端BGP的AS号;如果BGP AS号大于65535,则Tag值为0,可以手动修改Tag值。如果没有配置BGP,则默认值为0。
//设置路由的tag。
并且Huawei定义tag有如下选择原则import-route>route-tag>tag。
CE–PE的OSPFv2重分发特点:
1@:Options字段出现在Hello报文,DBD报文和LSA信息中出现。
2@:Cisco对应32bits的Domain-Tag字段进行防环。
3@:有关OSPFv2协议原理的详细内容,可参考博客《OSPFv2原理详解(基于RFC2328)+配置介绍+RFC2328翻译》中有关OSPFv2报文字段的相关内容
4@:对于Type-3 Summary LSA和Type-5 AS-EXternal LSA应当将其DN-bit位置位,此外Type-5 AS-External LSA还可携带32-bits的路由tag用于防环考虑。
4.2.1.原理分析
场景解读:
在VPN站点使用的IGP协议两端都为OSPF时,MP-BGP协议在传递重分发的OSPF路由会有特殊的机制。此时OSPF将整个MPLS Domain视为一个OSPF超级骨干区域,以便连接同一个客户不同站点的网络。(不同站点CE-PE连接都为骨干区域。)
2006年发布的RFC4577为BGP/MPLS IP VPNs定义了OSPF作为PE-CE交互的扩展机制。
并且可以理解的是,在做这些考虑时不应当事先假定OSPF站点的网络情况。例如暂时不应认为客户站点设置了Stub或NSSA区域或者假定两个站点属于同一个OSPF区域或者站点内存在真正的骨干域。
自动换行
基于以上考虑有如下设计:
1@:如果 VPN 站点 A 和 B 位于同一 OSPF domain中,则从一个站点到另一个站点的路由应显示为 OSPF 网络内路由。
主要是通过PE引入私网路由方式为Type-3 Summary LSA实现。
2@:应当允许后门链路Sham-link存在的情况,而不论其是否是同一个OSPF Area或者Area为骨干域。
在VPN出口和Sham-link同时出现的情况下,不应当将Sham-link作为可选路径。这样的实现方式在普通场景下是难以实现的,因为普通引入的OSPF外部路由难以比OSPF内部路由优先选择。详细的情况将在后文进行介绍。
3@:从传统的私有 OSPF 主干网到 VPN 服务的过渡必须简单明了。不影响站点对VPN骨干还是普通骨干的路由选择及服务替换过渡。
4@:分配给给定路由的 OSPF Metirc应在 VPN 骨干网上透明地传输。
5@:来自不在同一 OSPF 域中的站点的路由当然将显示为Type-5 AS-External LSA外部路由。此时该PE显示为ASBR角色。
6@:OSPF Domain ID是决定PE引入路由类型的唯一原则。当然原本为Type-5 AS-External LSA外部路由仍会被认为成Type-5 AS-External LSA外部路由,不受OSPF Domain ID影响。
并且在具体的实现上RFC4577对路由引入原则还做出如下规定:
- VRFs表中对相同的IPv4前缀OSPF-distributed路由和VPNv4路由,优选OSPF-distributed路由
- PE在将VPNv4导入VRFs时,该VPNv4路由应当是最优路由。需要说明的时,是否真正引入还需考虑路由策略的影响。
- PE节点上的VRF可能有多个OSPF实例,因此应当对每个实例引入LSA的类型做出相应区分。
- 如果PE和CE链路所在OSPF区域为非骨干域,此时应当将PE视为OSPF的ABR。
- 上文我们介绍,如果PE节点作为骨干路由器存在。那么MPLS Domain会构成一个超级骨干区域。此时OSPF将从原来的两级层次结构升级为三级层级结构,并且允许原有骨干区域的中断而不影响网络。
4.2.2.MPLS Domain超级骨干域
将在此以下图所示环境进行介绍
此处展示的一个环境就是MPLS Domain将OSPF骨干区域分割。
 场景介绍:
场景介绍:
1@:AR1和AR5分为作为CE节点单归至PE节点AR2和AR4。
2@:剩余AR3启用RR功能作为P节点与AR2和AR4共同组成BGP/MPLS Domain使用。
AR2和AR4建立MP-BGP邻居关系后,在传递私网路由5.5.5.5/32时将额外传递与OSPF相关的扩展团体属性。
如下图MP-BGP Update报文携带的Path Attribute:
 除原有用于VPN站点间路由识别的RT之外,还额外携带了3个与OSPF参数相关的团体属性:Domain ID、Route Type和Router ID。
除原有用于VPN站点间路由识别的RT之外,还额外携带了3个与OSPF参数相关的团体属性:Domain ID、Route Type和Router ID。
OSPF Domain ID:共8字节。RFC4577认为每个OSPF实例应当至少具有一个Domain ID。RFC4577认为默认Domian ID或未配置场景应当为null。
Type:1字节。
SubType:1字节。Type和SubType主要用于共同确定携带的扩展团体属性类型OSPF Domain ID。默认的类型为0x0005。
目前所定义的OSPF Domain类型主要有0x0005,0x0105,0x205,0x8005。这几种类型主要是用于定义如何选择Domain值。例如0x0005表示Domain ID组成方式为所定义的Domain ID Value(4字节)+Value(2字节)。
有一点奇怪的是Huawei的Domain ID Value为10进制点分而Value为16进制,这在报文中显示为
这里只是显示方式不同。257和16842753显示为0x0101和0x0101 0001。
其他的表示方式,似乎也一致。这里不在进行一一介绍。感兴趣者可自行和报文进行对应。
AS:2字节。
AN:4字节。
- 如果定义了多个Domian ID,应当有一个作为主Domian ID。并且此时Null不应当算在Domain ID中。
- 如果定义了多个Domian ID,但是在MP-BGP的Update报文中仍然只携带一个主Domian ID。如果携带该Domian ID可与其他站点的OSPF Domain ID列表匹配则认为是同一个Domian域,并且通告方式将取决于路由的 OSPF 路由类型。否则认为不在一个Domain域中,此时就将该路由引入为Type-5 AS-External LSA外部路由。
- 即使两个OSPF实例的Domian ID为Null,在某些场景下也有可能认为其在不同的Domain中。
- RFC4577认为默认Domian ID或未配置场景应当为null,Huawei以此逻辑实现。Cisco则默认将以OSPF实例号作为Domian ID。
- RFC4577的4.2.8.1.章节定义了OSPF Domian ID属性被认为一致的三种情况:1@8字节完全相同;2@低阶6字节完全相同但Type和SubType字段满足相应兼容条件;3@低阶6字节都为0。
- RFC4577的4.2.8.1.章节定义了PE接收路由时是否与OSPF实例在同一个Domain的两种情况:1@路由和 OSPF 实例各自属于 NULL 域(NULL域指默认为空情况);2@路由Domian ID等于 OSPF 实例的Domian ID。不满足以上情况时,将VPNv4路由引入为外部路由并根据所在区域类型决定引入Type-5 AS-External LSA还是Type-7 NSSA LSA。同时将DN置位并携带Route-tag。
OSPF Route Type:共8字节。
Type:1字节。
SubType:1字节。Type和SubType主要用于共同确定0x0306为OSPF Route Type。同时保证向后兼容也可选择0x8000并将0x8000视为0x0306。
Area Number:4字节。 对于 AS 外部路由,该值为 0。 非零将路由标识为 OSPF 域内部。 此值与Domain内路由区域相关联。
Route Type:1字节。标识LSA类型,可选择的有Type-1,Type-2,Type-3,Type-5和Type-7。但是对OSPF域内LSA的处理动作都一致,根据Domain ID在对端PE上决定将其引入为另一个站点的Type-3还是Type-5型路由。对于Route Type为Type-5和Type-7,依照本地传递Type-5或Type-7。
并且RFC4577规定,PE不得引入Type-4 ASBR LSA路由。而在引入Type-5 AS-External LSA时,转发地址置为0。
Option:1字节。仅对Type-5和Type-7有效,0表示引入为一类OSPF外部路由,1表示引入为二类OSPF外部路由。
OSPF Router-ID:共8字节。
Type:1字节。
SubType:1字节。Type和SubType主要用于共同确定0x0107为OSPF Router-ID字段。相似的,同时保证向后兼容也可选择0x8001并将0x8001视为0x0107。
Router-ID:4字节。
这里还有2字节的Reserved未展示:2字节。
扩展团体属性示例:
相应的字段可依照报文自行进行对照,这里不在进行说明。
自动换行
除以上定义外,RFC4577还对MED值进行规定:
//默认情况下,此值应设置为与路由关联的 OSPF 距离的值加 1。
自动换行
还有一个特殊情况是:对于Huawei的CE-PE直连链路,可能将其导入到MP-BGP时,不携带以上扩展团体属性。因此将PE直连CE链路以Type-5类方式传递至对端。
以上情况我们介绍了在BGP/MPLS Domain在OSPF在作为不同站点CE-PE链路情况下,可作为一个超级骨干区域。通过MP-BGP传递OSPF相关属性,实际上将不同站点但相同OSPF Domain连接成为了一个超级OSPF Domain。此时可以将整个OSPF Domain理解形成了一个三级层级结构,同时在站点CE上甚至可以看到对端的LSA信息。
当然是只能反应路由信息的Type-3 Summary LSA或除Type-4的其他路由型LSA。
LSA的信息主要是从MP-BGP传递的OSPF属性中获知。
4.2.3.典型场景及配置示例
在这里我们简单提出几个场景进行场景介绍,以供大家参考。
场景1:
Note:以下场景可能不适用实际情况或其他厂家,仅作参考。
 场景介绍:
场景介绍:
1@:AR1作为CE节点双归至PE节点AR2和AR3。
2@:AR6作为对端CE节点与PE节点AR5连接。
3@:剩余AR4作为P节点与AR2、AR3和AR5共同组成BGP/MPLS Domain使用。
依照上图进行正常配置后,预期每个节点可以正常互通。
但是可以设想如下场景:
1@:AR3由于某种原因和AR4链路中断而无法连接到GGP/MPLS骨干网中,此时由于AR1传递而来的Type-3 Summary LSA路由携带DN-bit,Type-5 AS-External LSA携带DN-bit和route-tag而失去LSA计算能力。因此也就不在具有跨站点通信能力。
2@:相似的如果AR1所在站点的OSPF Domain的其他设备需要连接到其他BGP/MPLS Domain中时,同样由于DN或Tag而无法引入另一个出口PE。
此时便可通过关闭DN检查和去使能Route-Tag设置进行规避。
1@这里只提供了AR3作为PE设备配置,有能力者可自行进行其他P和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
bgp 10
peer 4.4.4.4 as-number 10
peer 4.4.4.4 connect-interface LoopBack1
#
ipv4-family unicast
undo synchronization
undo peer 4.4.4.4 enable
#
ipv4-family v4
policy -target
peer 4.4.4.4 enable
#
ipv4-family -instance -a
import-route ospf 10
#
ospf 10 router-id 3.3.3.3 -instance -a
import-route bgp
dn-bit-check disable summary
dn-bit-check disable ase
dn-bit-check disable nssa
route-tag disable
area 0.0.0.10
network 10.1.3.0 0.0.0.255
#
还有一条命令可供参考使用:-instance-capability simple
//用来禁止路由环路检测(DN位和route-tag检查),直接进行路由计算。默认使能路由环路检查。
场景2:
Note:以下场景可能不适用实际情况或其他厂家,仅作参考。
 场景介绍:
场景介绍:
1@:AR1作为CE节点双归至PE节点AR2和AR3。
2@:AR6作为对端CE节点与PE节点AR5连接。
3@:剩余AR4作为P节点与AR2、AR3和AR5共同组成BGP/MPLS Domain使用。
依照上图进行正常配置后,预期每个节点可以正常互通。
但是在此种情况下AR1额外承担了ABR的角色。此时有一个特性是AR1会将来自AR2的远端私网路由的DN-bit位清零。此时AR3上将收到AR1发送的DN-bit不置位的远端OSPF路由并且由于OSPF路由优先级优于BGP而导致到远端的流量优选AR1作为下一跳。
也就形成了次优路径。
1@这里不在提供配置说明,一种解决办法是可以在AR1和AR3启用vlink虚链路或者可以通过修改BGP或OSPF的路由优先级进行规避。
从以上场景我们可以看出,针对不同的场景需要进行不同的配置而在防环和次优中进行抉择使用。
4.2.4.Sham Links及配置举例
Sham Links也即伪链路通常使用在如下场景:
不同OSPF Domain站点主流量通过BGP/MPLS骨干网传输流量。除上述描述的流量路径外,站点之间还建立了Bakcdoor后门低速链路用作冗余和流量备份。
 场景介绍:
场景介绍:
1@:AR1和AR5作为CE节点分别连接至PE节点AR2和AR4。
2@:AR1和AR5还存在Backdoor Link后门链路进行
相似的这样的场景在普通配置下明显是存在问题的,由于BGP/MPLS骨干网总是传递路由型LSA(Type-3 Summary LSA,Type-5 AS-External LSA和Type-7 NSSA LSA)后门链路则有可能传递Type-1 Route LSA。OSPF的设计上区域内路由优于区域间路由优于自治域外路由。
因此很有可能主流量不在经过BGP/MPLS骨干网而是走后门链路,这样反而造成了浪费。此时。需要在BGP/MPLS骨干网的站点PE之间建立Sham-Link让OSPF优选BGP/MPLS骨干网。
在RFC4577中定义了如下关于Sham-link的使用原则:
1@:可以为任何区域(包括区域 0)创建Sham-link。
2@:当且仅当 VRF 中安装了到虚链路的 32 位远程端点地址的路由时,才会考虑连接两个 VRF 的Sham-link。
3@:Sham-link不得用作 OSPF 虚拟链路的端点地址。
Sham-link基本原理:
1@:在两端PE节点创建作为承载OSPF的underlay地址进行通信。
2@:在OSPF中指定地址建立Sham-link链路。
3@:OSPF根据指定的地址传递相应的LSDB进行相应的路由计算。
 //仔细观察可以发现该地址通过BGP/MPLS网络走标签传递流量。
//仔细观察可以发现该地址通过BGP/MPLS网络走标签传递流量。
自动换行
Sham-link注意事项:
1@:OSPF sham-link的underlay链路需要通过BGP/MPLS网络进行通信,因此需要建立在相应私网实例下并可通过BGP宣告至远端PE。
2@:通过Sham-link远端CE节点AR5已经具有通过BGP/MPLS骨干网传递而来的OSPF Type-1 Route LSA和Type-2 Network LSA并可通过SPF算法计算相应的路由。那么还需要在PE节点AR2上将OSPF路由引入BGP吗?
- 答案当然是需要的。CE节点AR5具有OSPF的LSDB可通过SPF算法计算最短路径下一跳为PE节点AR4。PE节点AR4接收到来自CE节点AR5目的IP为对端CE时,将会发现自己缺少相应的下一跳。(尽管有OSPF通过SPF算法计算而来的路径)。因为BGP/MPLS网络并没有该BGP路由也就无法为该流量正常进行标签分发并将流量导向隧道。
3@:相似的,需要在PE节点AR4上将BGP路由引入OSPF吗?
- 此时答案可能将不是必要的。因为在PE上将BGP引入OSPF私网实例的原因在于私网缺少对端的路由,这一问题已经通过Sham-link传递而来的LSDB进行了解决。
4@:OSPF的Sham-link是最终的一个完美的解决办法吗?
- 当然此时的答案同样也不是一个完美的解决办法。此时如果通过Sham-link计算而来的链路开销大于后门链路时,节点仍然会优选后门链路进行路由转发。
- 因此需要额外的手段,比如更改链路开销进行人为的路由选路。
Sham-link配置:
1@这里只提供了AR2作为PE设备配置,有能力者可自行进行其他P和PE设备的配置。
有需要者可私信联系提供模拟器源文件及配置。
bgp 10
router-id 2.2.2.2
peer 4.4.4.4 as-number 10
peer 4.4.4.4 connect-interface LoopBack1
#
ipv4-family unicast
undo synchronization
undo peer 4.4.4.4 enable
#
ipv4-family v4
policy -target
peer 4.4.4.4 enable
#
ipv4-family -instance -1
network 22.22.22.22 255.255.255.255
import-route ospf 10
#
ospf 10 router-id 2.2.2.2 -instance -1
import-route bgp
area 0.0.0.0
network 10.1.2.0 0.0.0.255
sham-link 22.22.22.22 44.44.44.44
#
 //查看Sham-link状态。与V-link相似的,Sham-link不可通过普通的邻居状态display ospf peer进行发现
//查看Sham-link状态。与V-link相似的,Sham-link不可通过普通的邻居状态display ospf peer进行发现
 //查看通过BGP/MPLS骨干网的Sham-link传递而来的对端PE的Type-1 Route LSA。
//查看通过BGP/MPLS骨干网的Sham-link传递而来的对端PE的Type-1 Route LSA。
关于Sham-link的更多知识这里不在进行相关介绍,比如Sham-link的OSPF参数配置,以及Sham-link的按需链路情况。并且关于本例中使用Sham-link还可能出现相应的路由重复引入的情况,也不再进行深入研究。
感兴趣者可自行阅读相关资料。
点击此处回到目录
4.3.CE–PE的BGP SoO属性
BGP本身作为一种路由传递协议具有各种丰富的手段进行路由选择和路由防环,并不需像OSPF那样做过多的场景要求。
因此这里仅在特定场景下对BGP的SoO/substitute-as进行介绍:
Note:以下场景可能不适用实际情况或其他厂家,仅作参考。
 场景介绍:
场景介绍:
1@:AR1作为CE节点双归至PE节点AR2和AR3。此外还有AR9作为单独节点单归至PE节点AR3。
2@:AR6作为对端CE节点与PE节点AR5连接。
3@:剩余AR4作为P节点与AR2、AR3和AR5共同组成BGP/MPLS Domain使用。
依照上图进行正常配置后,除AR1和AR9节点外,预期每个节点可以正常互通。那么如何完美的实现AR1和AR9节点的通信呢。
此时可通过BGP Path Attribute中扩展团体属性的Site-of-Origin,也即SoO属性。
SoO属性本质是BGP扩展团体属性的一种,称为Route Origin属性。下文将进行介绍。
场景分析:
当然在普通情况下,由于的AS_PATH防环原则这是不可能实现的。
有三条命令可以有助于解决:
1@:peer <> fake-as <>
 //以指定AS number与对端建立虚假的AS邻居关系。从而规避AS_PATH的防环原则。
//以指定AS number与对端建立虚假的AS邻居关系。从而规避AS_PATH的防环原则。
这种设计通常需要进行事先网络设计,通常也仅用于网络过渡场景的临时规划。而且对应VPNv4邻居有可能不支持,可能仅支持单播和VPN实例地址族。
2@:peer <> allow-as-loop <>
 //允许来自对端的BGP路由环路,也即允许对端传递AS_PATH包含自己AS_Number的个数。
//允许来自对端的BGP路由环路,也即允许对端传递AS_PATH包含自己AS_Number的个数。
因此需要在PE上进行相应配置,常用于Hub and Spoke组网。关于该组网主要原理是通过RT进行路由上的收发,具体来说是在总部Hub-PE节点与总部Hub-CE节点建立两个BGP邻居同时在Hub-PE节点创建私网BGP邻居时划定特定的RT进行路由控制。通过这种方式实现分支Spoke节点流量需通过Hub-CE节点进行转发。
如果Hub-PE节点与总部Hub-CE节点仅建立一个BGP邻居恐怕就难以实现该要求了。
3@:peer <> substitute-as和peer <> Soo <>
 //peer <> substitute-as表示在AS_PATH中用本地AS Number替换指定与对端建立BGP邻居AS_Number。
//peer <> substitute-as表示在AS_PATH中用本地AS Number替换指定与对端建立BGP邻居AS_Number。
也即如果本地AS100与对端AS200建立邻居,就将AS_PATH中为200的AS Number替换为100。在VPN实例地址族下进行使用。
 //peer <> soo在PE上使用表示为来自该对等体的路由添加soo扩展团体属性。
//peer <> soo在PE上使用表示为来自该对等体的路由添加soo扩展团体属性。
peer <> soo是一个出站策略,对来自该对等体的路由添加该团体属性但不向该邻居传递该属性值。这一团体属性仅在传递VPNv4路由时携带,也即仅传递给VPNv4地址族邻居时携带。在VPN实例地址族下进行使用。
//这里传递SoO属性就是12:12。有一点需要注意的是这一字段共8字节,除去Type字段外剩余6字节。这里实际允许配置65535:65535,因此中间有2字节是保留位。
>
BGP对SoO属性的处理原则为:PE将VPNv4路由转化为私网路由时,如果VPNv4路由携带的SoO属性与私网对等体实例配置的SoO属性一致,就不讲该路由传递给该私网对等体。
4.4.常用查看命令
对于特定VPN实例对等体有:
 //查看特定VPN私网实例对等体邻居,Huawei也将该VPN私网实例对等体算入v4中但无法查看其路由。
//查看特定VPN私网实例对等体邻居,Huawei也将该VPN私网实例对等体算入v4中但无法查看其路由。
 //查看特定VPN私网实例对等体邻居传递Update报文中的路由信息,该信息进行BGP选路或路由策略。
//查看特定VPN私网实例对等体邻居传递Update报文中的路由信息,该信息进行BGP选路或路由策略。
更新
点击此处回到目录