MQ回顾之kafka速通
不定期更新
官网概念自查
官网:Apache Kafka
kafka结构
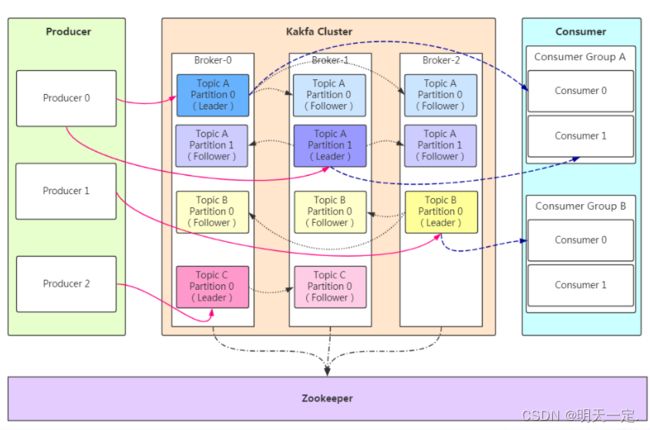
和kafka相关的关键名词有:Producer、Broker、Topic、Partition、Replication、Message、Consumer、Consumer Group、Zookeeper。
各名词解释已经泛滥,如果你想看点不一样的,下边是套用官网的原句翻译解释部分名词
event记录了世界或你的业务中“发生了一些事情”的事实。在文档中也称为记录或消息。在Kafka中读取或写入数据时,需要以事件的形式完成。从概念上讲,事件有键、值、时间戳和可选的元数据头。下面是一个事件的例子:
- Event key: "Alice"
- Event value: "Made a payment of $200 to Bob"
- Event timestamp: "Jun. 25, 2020 at 2:06 p.m."
producers是指向Kafka发布(写入)events的客户端应用程序,consumers是指订阅(读取和处理)这些events的客户端应用程序。
events被组织起来并持久存储在topic中。简单来说,topic类似于文件系统中的文件夹,而events就是该文件夹中的文件。
topic是分区(partitioned)的,这意味着一个topic分布在位于不同Kafka broker上的许多“桶”中。数据的分布式放置对于可扩展性非常重要,因为它允许客户端应用程序同时从多个代理读取和写入数据。
为了使你的数据具有容错性和高可用性,每个topic都可以被replicated,甚至可以跨地理区域或数据中心,这样总是有多个代理都有一份数据副本,以防出现问题,你想对代理进行维护。
Kafka消费者跟踪它在每个分区中消耗的最大偏移量,并有能力提交偏移量,以便在重新启动时从这些偏移量中恢复。Kafka提供了一种选项,可以将给定consumer group 的所有偏移量存储在指定的代理(针对该组)中,称为组协调器(group coordinator)。例如,该consumer group中的任何消费者实例都应该将其偏移提交和获取发送给该组协调器(broker)。consumer group 根据其组名分配给协调器。消费者可以通过向任何Kafka代理发送FindCoordinatorRequest并读取包含协调器详细信息的FindCoordinatorResponse来查找它的协调器。然后,使用者可以继续提交或从协调器代理获取偏移量。如果协调器移动了,使用者将需要重新发现协调器。偏移量提交可以通过消费者实例自动完成,也可以手动完成。
kafka push or pull
我们考虑的最初问题是消费者是否应该从brokers那里提取数据,或者brokers应该将数据推送给消费者。 在这方面,Kafka 遵循大多数消息传递系统所共享的更传统的设计,其中数据从生产者push到代理并由消费者从代理中pull。
基于pull的系统的缺点是,如果代理没有数据,那么消费者可能会陷入一个紧密的循环轮询,实际上就是忙着等待数据的到达。为了避免这种情况,我们在pull request中设置了一些参数,允许用户请求阻塞在一个“长轮询”中,直到数据到达。
如果服务是push模式,则会以恒定速率推给消费者,忽略消费者的消费能力是很可怕的事。
kafka的吞吐量高的原因
我们要明确kafka生产者推送消息分为同步发送和异步发送。
在异步发送中为了实现批量处理,Kafka生产者会尝试在内存中积累数据,并在单个请求中发送更大的批次。批处理可以配置为累计不超过固定数量的消息,并等待不超过某个固定的延迟界限(例如64k或10ms)。这样可以增加发送的字节数,也可以减少服务器上的大型I/O操作。这种缓冲是可配置的,它提供了一种机制,以牺牲少量额外延迟来换取更好的吞吐量。
这样做也有弊端,虽然减少了网络io,但是当生产者宕机时,会导致丢失一批数据,所以理论上它提高了吞吐量但是降低了可靠性。
kafka磁盘读写快的原因
1、顺序写
在JBOD配置的6个7200rpm SATA RAID-5阵列上,线性写的性能约为600MB/s,而随机写的性能仅为100k/s,相差超过6000X。
在某些情况下,顺序磁盘访问可能比随机内存访问更快!点击查看
2、pagecache
用主内存来进行磁盘缓存。建立在JVM之上,减少GC。这样做将在32GB的机器上产生高达28-30GB的缓存,而不会产生GC
即使服务重启,这个缓存也会保持热状态,而进程内缓存需要在内存中重新构建(对于10GB的缓存来说,可能需要10分钟),或者需要从完全冷的缓存开始(这可能意味着糟糕的初始性能)。
这就提出了一个非常简单的设计:与其在内存中维护尽可能多的数据,并在内存空间耗尽时将其全部刷新到文件系统,不如将其反转。所有数据立即写入文件系统上的持久日志,而不必刷写到磁盘。实际上,这仅仅意味着它被传输到内核的页缓存中。
3、零拷贝,懂得都懂,之后或许再写篇说零拷贝。
4、批量压缩
在某些情况下,瓶颈实际上不是CPU或磁盘,而是网络带宽。
高效的压缩要求将多条消息一起压缩,而不是单独压缩每条消息。
5、日志压缩+索引
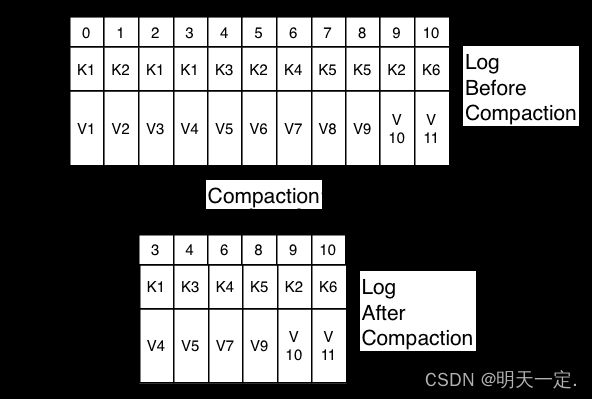
6、批量读写
kafka的rebalance机制
rebalance协议依靠组协调器为组成员分配实体id。这些生成的id是临时的,会在成员重新启动和重新加入时发生变化。对于基于消费者的应用程序,这种“动态成员”可能会导致在管理操作(如代码部署、配置更新和定期重启)期间,将很大比例的任务重新分配给不同的实例。对于大状态应用,混洗任务在处理前需要较长时间恢复其本地状态,导致应用部分或全部不可用。基于这种情况,Kafka的组管理协议允许组成员提供持久的实体id。组成员关系会根据这些id保持不变,因此不会触发再平衡。
发动时机:
- 组成员个数发生变化。例如有新的
consumer实例加入该消费组或者离开组。 - 订阅的
Topic个数发生变化。 - 订阅
Topic的分区数发生变化。
Rebalance 发生时,Group 下所有 Consumer 实例都会协调在一起共同参与,Kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 Consumer Group 会造成比较严重的影响,所有消费者实例都会停止工作,等待 Rebalance 过程完成。
coordinator——rebalance的通知者
组协调器,通常在partition的leader节点所在的broker,负责监控group中consumer的存活,判断consumer的消费超时,消费超时也会触发的rebalance。
Group Coordinator是一个服务,每个Broker在启动的时候都会启动一个该服务。Group Coordinator的作用是用来存储Group的相关Meta信息,并将对应Partition的Offset信息记录到Kafka内置Topic(__consumer_offsets)中。Kafka在 0.9 之前是基于Zookeeper来存储Partition的Offset信息(consumers/{group}/offsets/{topic}/{partition}),因为Zookeeper并不适用于频繁的写操作,所以在 0.9 之后通过内置Topic的方式来记录对应Partition的Offset。

kafka事务机制
通过事务机制,KAFKA 可以实现对多个 topic 的多个 partition 的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个 topic 的哪个 partition, 最终结果都是要么全部写成功,要么全部写失败。
大致流程:将 transactional.id 注册到 transactional coordinator——消息对应的 partition 会首先被注册到 transactional coordinator,然后 producer 按照正常流程发送消息到目标 topic——向 transactional coordinator 提交请求,开始两阶段提交协议——通过事务状态“commited” 或 “abort”将该状态持久化到 transaction log 中
生产者配置
测试场景下,开启事务后性能只有3% 的下降
enable.idempotence = true #开启幂等
acks = “all” # 分布式所有确认
retries >= 1 # 启用幂等性要求这个配置值大于0
transactional.id =xxx # 默认情况下,没有配置TransactionId,这意味着不能使用事务。
消费者配置
开启事务后,对 consumer 的性能影响相对对 producer 的性能影响更小,consumer 仍然是轻量级高吞吐的,几乎没有性能影响
isolation.level= “read_committed” or “read_uncommitted”
控制如何读取以事务方式写入的消息。如果设置为read_committed, consumer.poll()将只返回已提交的事务消息。如果设置为read_uncommitted(默认值),consumer.poll()将返回所有消息,即使是已经中止的事务性消息。在任何一种模式下,非事务性消息都将无条件地返回。
使用

or

spring-kafka配置备忘录
# The offset commit behavior
spring:
kafka:
listener:
ack-mode: manualpublic enum AckMode {
/**
* Commit the offset after each record is processed by the listener.
*/
RECORD,/**
* Commit the offsets of all records returned by the previous poll after they all
* have been processed by the listener.
*/
BATCH,/**
* Commit pending offsets after
* {@link ContainerProperties#setAckTime(long) ackTime} has elapsed.
*/
TIME,/**
* Commit pending offsets after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded.
*/
COUNT,/**
* Commit pending offsets after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded or after {@link ContainerProperties#setAckTime(long)
* ackTime} has elapsed.
*/
COUNT_TIME,/**
* Listener is responsible for acking - use a
* {@link org.springframework.kafka.listener.AcknowledgingMessageListener}; acks
* will be queued and offsets will be committed when all the records returned by
* the previous poll have been processed by the listener.
*/
MANUAL,/**
* Listener is responsible for acking - use a
* {@link org.springframework.kafka.listener.AcknowledgingMessageListener}; the
* commit will be performed immediately if the {@code Acknowledgment} is
* acknowledged on the calling consumer thread; otherwise, the acks will be queued
* and offsets will be committed when all the records returned by the previous
* poll have been processed by the listener; results will be indeterminate if you
* sometimes acknowledge on the calling thread and sometimes not.
*/
MANUAL_IMMEDIATE,}
# 单消费 or 批量消费
spring:
kafka:
listener:
type: singlepublic enum Type { /** * Invokes the endpoint with one ConsumerRecord at a time. */ SINGLE, /** * Invokes the endpoint with a batch of ConsumerRecords. */ BATCH }
生产者配置
spring: kafka: producer: properties[max.block.ms]: 2000 #send超时时间# 主要想展示一下还可以这样配置配置
spring:
kafka:
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
消费者配置
spring: kafka: consumer: auto-offset-reset: earliest#如果Kafka中没有初始偏移量,或者当前偏移量在服务器上已经不存在了,该怎么办
- earliest: 自动重置偏移量到最早的偏移量
- latest: 自动将偏移量重置为最新偏移量
- none: 如果未为使用者的组找到先前的偏移量,则向使用者抛出异常
- anything else: throw exception to the consumer.
enable.auto.commit # 是否自动提交offset
max.poll.records # 最大拉取记录数
max.poll.interval.ms # 消费阻塞时长,如果时间到了还没消费完本次,则被提出消费者组