Bert Transformer细节总结
常见的attention有几种?
Attention的本质就是一种加权机制。一些的常用实现形式如下:
a t t e n t i o n = f ( Q , K ) attention = f(Q,K) attention=f(Q,K)
多层感知机方法
先将Query和Key进行拼接,然后接一个多层感知机。这种方法不需要Query和Key的向量长度相等,Query和Key之间的交互方式是通过学习获得的。
f ( Q , K ) = m l p ( [ Q ; K ] ) f(Q,K) = mlp([Q;K]) f(Q,K)=mlp([Q;K])
Bilinear方法
通过一个权重矩阵直接建立Query和Key的关系映射,计算速度较快,但是需要Query和Key的向量长度相同。
f ( Q , K ) = Q W K T f(Q,K) = QWK^T f(Q,K)=QWKT
Scaled-Dot Product

这种方式直接求Query和Key的内积相似度,没有需要学习的参数,计算速度极快,需要Query和Key的向量长度相同。考虑到随着向量维度的增加,最后得到的权重也会增加,对其进行scaling。如果最后再乘V,那么要求K和V的序列长度相同,这也是为啥一个是key一个是value的原因。但是如下图,Q和K的序列长度是没有要求的
f ( Q , K ) = s o f t m a x ( Q K T d k ) f(Q,K)=softmax(\frac{QK^T}{\sqrt{d_k}}) f(Q,K)=softmax(dkQKT)
 由于transformer中的self-attention用的是这种形式,叫self-attention的原因就是Q、K、V在self-attention中是一样的,实际上就是求一句话一个词在句子中的关系。
由于transformer中的self-attention用的是这种形式,叫self-attention的原因就是Q、K、V在self-attention中是一样的,实际上就是求一句话一个词在句子中的关系。
Add Attention
加法形式就不要求Query和Key的dim相同,但是加法计算复杂度计算较高,在Massive Exploration of Neural Machine Translation Architectures一文中,作者说当dim足够大时,加法的效果要比乘法效果要好(本文后半部分也有对这个问题的引用)
f ( Q , K ) = tanh ( Q W 1 + K W 2 ) f(Q,K) = \tanh(QW_1+KW_2) f(Q,K)=tanh(QW1+KW2)
self-attention中softmax是在哪个维度的
f ( Q , K , V ) = s o f t m a x ( Q K T d k ) V f(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V f(Q,K,V)=softmax(dkQKT)V
光看公式有时候容易犯迷糊,softmax目的是让每一维归一化到0和1之间,因此和softmax结果相乘的V决定了softmax要作用在shape是m的那个维度上,也就是每行拿出来softmax(如果是句子那么就是每个词的hidden layer拿出来softmax)
LayerNorm是作用在哪个维度的
LayerNorm在transformer里是作用在embedding_dim那个维度上的。但是torch.LayerNorm不像softmax的实现指定dim,而是指定了dim的倒数的shape,容易晕,贴个code清醒一下:
import torch
import torch.nn as nn
def layer_norm_process(feature: torch.Tensor, beta=0., gamma=1., eps=1e-5):
var_mean = torch.var_mean(feature, dim=(-2,-1), unbiased=False)
# 均值
mean = var_mean[1]
# 方差
var = var_mean[0]
# layer norm process
feature = (feature - mean[...,None, None]) / torch.sqrt(var[..., None, None] + eps)
feature = feature * gamma + beta
return feature
def main():
t = torch.rand(4, 2, 3)
print(t)
# 在倒数shape是(2,3)的维度上求均值和方差
norm = nn.LayerNorm(normalized_shape=(2,3), eps=1e-5)
#如果normalized_shape是3,那么torch.var_mean的dim就是-1
# 官方layer norm处理
t1 = norm(t)
# 自己实现的layer norm处理
t2 = layer_norm_process(t, eps=1e-5)
print("t1:\n", t1)
print("t2:\n", t2)
if __name__ == '__main__':
main()
不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
如果不乘QKV参数矩阵,那这个词对应的q,k,v就是完全一样的。
在相同量级的情况下,qi与ki点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
当然,QKV参数矩阵也使得多头,类似于CNN中的多核,去捕捉更丰富的特征/信息成为可能。
Self-Attention 的时间复杂度是怎么计算的?
- scaled dot production复杂度: 2 n 2 d 2n^2d 2n2d
- Q、K、V三个矩阵和输出前的dense: 3 n d 2 + n d 2 = 4 n d 2 3nd^2+nd^2=4nd^2 3nd2+nd2=4nd2
- position-size feedforward: 4 n d 2 + 4 n d 2 = 8 n d 2 4nd^2+4nd^2=8nd^2 4nd2+4nd2=8nd2
scaled dot production复杂度
scaled dot production时间复杂度: O ( n 2 d ) O(n^2d) O(n2d),这里,n是序列的长度,d是embedding的维度。说的更具体一点,主要是两个矩阵乘法 2 n 2 d 2n^2d 2n2d
scaled dot production包括三个步骤:相似度计算,softmax和加权平均,它们分别的时间复杂度是:
- 相似度计算可以看作大小为(n,d)和(d,n)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = O ( n 2 d ) (n,d)*(d,n)=O(n^2d) (n,d)∗(d,n)=O(n2d),得到一个(n,n)的矩阵
- softmax就是直接计算了,时间复杂度为 O ( n 2 ) O(n^2) O(n2)
- 加权平均可以看作大小为(n,n)和(n,d)的两个矩阵相乘: ( n , n ) ∗ ( n , d ) = O ( n 2 d ) (n,n)*(n,d)=O(n^2d) (n,n)∗(n,d)=O(n2d) ,得到一个(n,d)的矩阵
Multi-Head Attention里的scaled dot production复杂度
这里再分析一下Multi-Head Attention里的scaled dot production,它的作用类似于CNN中的多核。多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. —— 来自 google BERT 源码
Transformer/BERT中把 d ,也就是hidden_size/embedding_size这个维度做了reshape拆分,可以去看Google的TF源码或者上面的pytorch源码:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a
注意,d=m*a,这就是为啥multi head self attention要求d是m的整数倍,model_dim/head_cnt=head_dim,其中model_dim是d,head_cnt是m,head_dim是a
并将 num_attention_heads 维度transpose到前面,使得Q和K的维度都是(m,n,a),这里不考虑batch维度。
这样点积可以看作大小为(m,n,a)和(m,a,n)的两个张量相乘,得到一个(m,n,n)的矩阵,其实就相当于(n,a)和(a,n)的两个矩阵相乘,做了m次,时间复杂度是 O ( n 2 m a ) = O ( n 2 d ) O(n^2ma)=O(n^2d) O(n2ma)=O(n2d)。
因此Multi-Head Attention时间复杂度就是 O ( n 2 d ) O(n^2d) O(n2d),而实际上,张量乘法可以加速,因此实际复杂度会更低一些。
整体self attention复杂度
- scaled dot production复杂度: 2 n 2 d 2n^2d 2n2d
- Q、K、V三个矩阵和输出前的dense: 3 n d 2 + n d 2 = 4 n d 2 3nd^2+nd^2=4nd^2 3nd2+nd2=4nd2
- position-size feedforward: 4 n d 2 + 4 n d 2 = 8 n d 2 4nd^2+4nd^2=8nd^2 4nd2+4nd2=8nd2
如果要带上position-size feedforward一起看,可以参考https://kexue.fm/archives/8610中的分析:
Transformer中multi-head attention中每个head为什么要进行降维?
每个head的input维数是dmodel/head个数,请问这么做是为了什么?
一言蔽之的话,大概是:在不增加时间复杂度的情况下,同时,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。
伪代码实现multi-head attention
其实主要是刚才说的两点:
- 如何multihead
- self attention
另外一些点:像LN、position wise feed forward、residual这些点被hugging face Transformer放到BertSelfOutput里面去了,不放到MHA。BertSelfOutput最大的计算量在于里面也放了dense
import torch.nn as nn
import torch
from torch import Tensor
import math
class MyMultiheadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MyMultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.W_Q = nn.Linear(embed_dim,embed_dim)
self.W_K = nn.Linear(embed_dim,embed_dim)
self.W_V = nn.Linear(embed_dim,embed_dim)
self.fc = nn.Linear(embed_dim,embed_dim)
self.ln = nn.LayerNorm(embed_dim)
def scaled_dot_product_attention(self, q:Tensor, k:Tensor, v:Tensor):
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output,attn
def forward(self, query:Tensor, key:Tensor, value:Tensor):
# assert query, key, value have the same shape
# query shape: tgt_len, bsz, input_embedding
tgt_len, bsz, embed_dim = query.shape
head_dim = embed_dim // self.num_heads
q = self.W_Q(query).reshape(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
k = self.W_K(key).reshape(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
v = self.W_V(value).reshape(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
self_output,attn = self.scaled_dot_product_attention(q, k, v)
# self_output: bsz * num_heads, tgt_len, head_dim
# attn: bsz * num_heads, tgt_len, src_len
output = self.fc(self_output.transpose(0, 1).reshape(tgt_len, bsz, -1))
# hugging face版把fc放到BertSelfOutput里去了
return self.ln(output+query),attn
embed_dim,num_heads=100,5
seq_len,bsz = 2,3
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
query = torch.ones(seq_len, bsz, embed_dim)
key = torch.ones(seq_len, bsz, embed_dim)
value = torch.ones(seq_len, bsz, embed_dim)
attn_output, attn_output_weights = multihead_attn(query, key, value)
print('attn_output={}'.format(attn_output.shape))
print('attn_output_weights={}'.format(attn_output_weights.shape))
print('--------------')
my_multihead_attn = MyMultiheadAttention(embed_dim, num_heads)
my_attn_output, my_attn_output_weights = my_multihead_attn(query, key, value)
print('my_attn_output={}'.format(attn_output.shape))
print('my_attn_output_weights={}'.format(attn_output_weights.shape))
'''
输出如下:
attn_output=torch.Size([2, 3, 100])
attn_output_weights=torch.Size([3, 2, 2])
-------------
my_attn_output=torch.Size([2, 3, 100])
my_attn_output_weights=torch.Size([3, 2, 2])
'''
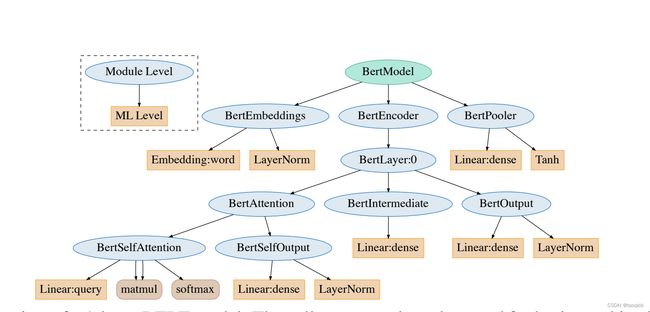
完整huggingface的实现(https://github.com/huggingface/transformers/blob/v4.15.0/src/transformers/models/bert/modeling_bert.py)如下图,可以去看
Transformer如何防止梯度爆炸或者消失
从两个方面来说:
- Short-Cut
- LayerNorm
Decoder 中 Cross Attention 的QKV分别来自于哪里?
Q来自于Decoder,KV都来自于Encoder的输出结果。Q意味着query,也即是需要查询的变量,所以这个部分在解码的时候会这样子做。本质上的意义是,针对于之前的编码器,在解码的部分一点一点的解码,所以Q也就是类似于信号的作用,提取出关键的信息。
另外需要注意的是,KV都是统一来源,并非来自Encoder部分的Attention中的KV矩阵,而是来自相同的输入,也即Encoder的输出结果。
Decoder 中不同的 Layer 和 Encoder 中不同的Layer有什么关系?是一一对应的关系吗?
并没有一一对应的关系,一一对应指的是Encoder中的每一层的输出,都对应Decoder中的一个输入。实际上Decoder的每一层的输入,都含有Encoder最终的输出结果。详见下图中的红色曲线即可。

实现一下decoder
什么是Position Wise Feed Forward Network?
文中的描述指的是卷积为1的CNN结构,实现的时候利用FFN来实现的。使用内核大小为1的两个卷积。输入和输出的维度为dmodel=512,内部层的维度为dff=2048。所以能够体现出,在dimension中,不同的位置计算的方式不同,和卷积的原理类似,所以中文名字才叫做 位置感知前馈神经网络。下面的code里,带不带residual可以再讨论
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.GeLU(),
nn.Linear(d_ff, d_model, bias=False))
def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model)(output + residual) # [batch_size, seq_len, d_model]
Transformer Decoder 部分有几个Attention 网络,为什么?
Decoder部分总共有两个Attention网络,第一个是self-attention,而第二个是cross-attention,两个的作用是不太一样的,第一个指的是把当前的输入全部进行attention机制的学习,找到权重来代表当前的输入,第二个是针对于解码的部分,通过Mask来实现逐个token的预测。下面我们来详细讲解下代码部分。
# 单个Decoder层的网络
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask): # dec_inputs: [batch_size, tgt_len, d_model]
# enc_outputs: [batch_size, src_len, d_model]
# dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
# dec_enc_attn_mask: [batch_size, tgt_len, src_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,
dec_inputs,
dec_self_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, # Q自于Decoder,K和V来自于Encoder里面即可,Query为查询向量
enc_outputs,
dec_enc_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs = self.pos_ffn(dec_outputs) # dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
# Decoder的整个网络
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs: [batch_size, tgt_len]
# enc_intpus: [batch_size, src_len]
# enc_outputs: [batsh_size, src_len, d_model]
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs) # [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask +
dec_self_attn_subsequence_mask), 0) # [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 因为是dec_enc_attn_mask,所以tgt_len是行,也就是[batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers: # dec_outputs: [batch_size, tgt_len, d_model]
# dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
# dec_enc_attn: [batch_size, n_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
def get_attn_pad_mask(seq_q, seq_k):
'''
seq_q: [batch_size, len_q]
seq_k: [batch_size, len_k]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
Padding Mask和Sequence Mask的区别
这俩都是非官方命名
- Padding Mask:处理非定长序列,区分padding和非padding部分,如在RNN等模型和Attention机制中的应用等
- Sequence Mask:防止标签泄露,时序
Transformer的并行化体现在哪个地方?Decoder端可以做并行化吗?
训练时一个 batch 的句子是一起生成的,而且每个句子的每个词也是一起生成的。encoder是并行的,训练的时候decoder也是并行的,但是inference的时候不是,因为你没有golden label,只能一个一个产生,所以decoder端跟RNN一样还是自回归的。细节看源码吧,tensor2tensor或者THUMT的transformer实现。
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。

为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
众所周知,无论在CV还是NLP中,深度模型都离不开归一化技术(Normalization)。在CV中,深度网络中一般会嵌入批归一化(BatchNorm,BN)单元,比如ResNet;而NLP中,则往往向深度网络中插入层归一化(LayerNorm,LN)单元,比如Transformer。
为什么在归一化问题上会有分歧呢?一个最直接的理由就是,BN用在NLP任务里实在太差了(相比LN),此外,BN还难以直接用在RNN中[1],而RNN是前一个NLP时代的最流行模型。
虽然有大量的实验观测,表明NLP任务里普遍BN比LN差太多,但是迄今为止,依然没有一个非常严谨的理论来证明LN相比BN在NLP任务里的优越性。甚至,连BN自身为什么work的问题都一直存在争议。
早期对BN有效性的解释是其有助于缓解神经网络“内部协方差漂移”(Internal Covariance Shift,ICS)问题。即,后面的层的学习是基于前面层的分布来的,只有前面一层的分布是确定的,后面的层才容易学习到有效的模式,然而,由于前面的层的分布会随着batch的变化而有所变动,导致了后面的层看来“前面一直在动,我无法安心学习呀”。
而BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。顾名思义,BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一化来让某层的分布稳定。
BN、LN可以看作横向和纵向的区别。
经过归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。
BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。
为什么要舍弃 BN 改用 LN 呢?朴素版的 BN 是为 CNN 任务提出的,需要较大的 BatchSize 来保证统计量的可靠性,并在训练阶段记录全局的 μ \mu μ 和 σ \sigma σ供预测任务使用。对于天然变长的 RNN 任务,需要对每个神经元进行在每个时序的状态进行统计。这不仅把原本非常简单的 BN 流程变复杂,更导致偏长的序列位置统计量不足。相比之下,LN 的使用限制就小很多,不需要在预测中使用训练阶段的统计量,即使 BatchSize = 1 也毫无影响。
个人理解,对于 CNN 图像类任务,每个卷积核可以看做特定的特征抽取器,对其输出做统计是有理可循的;对于 RNN 序列类任务,统计特定时序每个隐层的输出,毫无道理可言——序列中的绝对位置并没有什么显著的相关性。相反,同一样本同一时序同一层内,不同神经元节点处理的是相同的输入,在它们的输出间做统计合理得多。
简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗
传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)
传统词tokenization方法不利于模型学习词缀之间的关系
E.g. 模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
Character embedding作为OOV的解决方法粒度太细
Subword粒度在词与字符之间,能够较好的平衡OOV问题
BPE(字节对)编码或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。 后期使用时需要一个替换表来重建原始数据。OpenAI GPT-2 与Facebook RoBERTa均采用此方法构建subword vector.
优点
可以有效地平衡词汇表大小和步数(编码句子所需的token数量)。
缺点
基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
WordPiece算法可以看作是BPE的变种。不同点在于,WordPiece基于概率生成新的subword而不是下一最高频字节对。
ULM是另外一种subword分隔算法,它能够输出带概率的多个子词分段。它引入了一个假设:所有subword的出现都是独立的,并且subword序列由subword出现概率的乘积产生。WordPiece和ULM都利用语言模型建立subword词表。
From https://zhuanlan.zhihu.com/p/86965595
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
Transformer在训练的时候是并行执行的,所以在decoder的第一个sublayer里需要seq mask,其目的就是为了在预测未来数据时把这些未来的数据屏蔽掉,防止数据泄露。如果我们非要去串行执行training,seq mask其实就不需要了。
From: https://www.zhihu.com/question/369075515/answer/994819222
Transformer在哪里做了权重共享,为什么可以做权重共享?
(1)Encoder和Decoder间的Embedding层权重共享;
(2)Decoder中Embedding层和FC层权重共享。
对于(1),《Attention is all you need》中Transformer被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于Encoder和Decoder,嵌入时都只有对应语言的embedding会被激活,因此是可以共用一张词表做权重共享的。
“In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30].”
论文中,Transformer词表用了bpe来处理,所以最小的单元是subword。英语和德语同属日耳曼语族,有很多相同的subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。
但是,共用词表会使得词表数量增大,增加softmax的计算时间,因此实际使用中是否共享可能要根据情况权衡。
该点参考:https://www.zhihu.com/question/333419099/answer/743341017
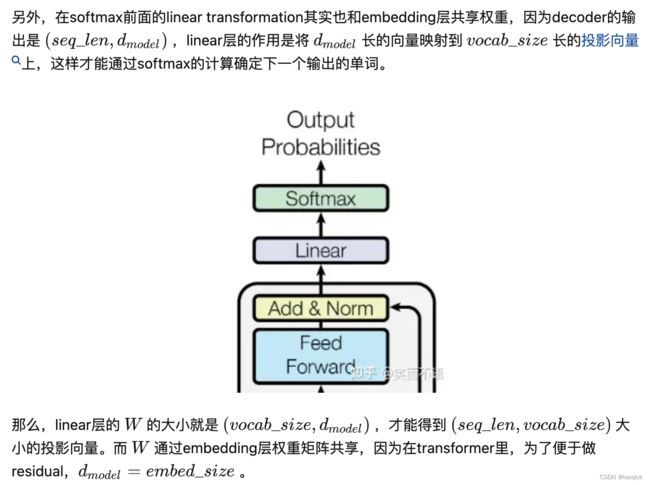
对于(2),Embedding层可以说是通过onehot去取到对应的embedding向量,FC层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的softmax概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在FC层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和softmax概率会是最大的(可类比本文问题1)。
因此,Embedding层和FC层权重共享,Embedding层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder中的Embedding层和FC层有点像互为逆过程。
通过这样的权重共享可以减少参数的数量,加快收敛。
但开始我有一个困惑是:Embedding层参数维度是:(v,d),FC层参数维度是:(d,v),可以直接共享嘛,还是要转置?其中v是词表大小,d是embedding维度。
查看 pytorch 源码发现真的可以直接共享:
fc = nn.Linear(d, v, bias=False) # Decoder FC层定义
weight = Parameter(torch.Tensor(out_features, in_features)) # Linear层权重定义
Linear 层的权重定义中,是按照 (out_features, in_features) 顺序来的,实际计算会先将 weight 转置在乘以输入矩阵。所以 FC层 对应的 Linear 权重维度也是 (v,d),可以直接共享。
转载自https://www.zhihu.com/question/333419099/answer/743341017
为什么BERT在第一句前会加一个[CLS]标志?
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
这里补充一下bert的输出,有两种:
一种是get_pooled_out(),就是上述[CLS]的表示,输出shape是[batch size,hidden size]。
一种是get_sequence_out(),获取的是整个句子每一个token的向量表示,输出shape是[batch_size, seq_length, hidden_size],这里也包括[CLS],因此在做token级别的任务时要注意它。
不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
概括来说,两个原因:
- 实现多头,类似于CNN中的多核,去捕捉更丰富的特征/信息成为可能。
- Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。如果不乘QKV参数矩阵,那这个词对应的q,k,v就是完全一样的。
具体解释:
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
如果不乘QKV参数矩阵,那这个词对应的q,k,v就是完全一样的。
在相同量级的情况下,qi与ki点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
当然,QKV参数矩阵也使得多头,类似于CNN中的多核,去捕捉更丰富的特征/信息成为可能。
为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
BERT采用的Masked LM,会选取语料中所有词的15%进行随机mask,论文中表示是受到完形填空任务的启发,但其实与CBOW也有异曲同工之妙。
从CBOW的角度,这里有一个比较好的解释是:在一个大小为 的窗口中随机选一个词,类似CBOW中滑动窗口的中心词,区别是这里的滑动窗口是非重叠的。
那从CBOW的滑动窗口角度,10%~20%都是还ok的比例。
上述非官方解释,是来自我的一位朋友提供的一个理解切入的角度,供参考。
BERT非线性的来源在哪里?
前馈层的gelu激活函数和self-attention,self-attention是非线性的,感谢评论区指出。
Transformer的正则化
- 正则化: We apply dropout [33] to the output of each sub-layer, before it is added to the
sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks - Label Smoothing:这样真实类别概率和其他类别的概率均值之间的gap(倍数)就会下降一些,降低模型过度自信,提升模型的泛华能力。

Bert 如何解决长文本问题?
举例: 在阅读理解问题中,article 常常长达1000+, 而Bert 对于这个量级的表示并不支持, 诸位有没有什么好的解决办法, 除了分段来做?或者提一提如何分段来做。感谢诸位大佬。
这是个好问题,可以看下Amazon今年EMNLP的这篇文章:Multi-passage BERT 主要思路是global norm + passage rank + sliding window实验做的很扎实,从ablation study看这几个trick都很有用。如果不想切passages就上XLNet吧。
Transformer为何使用多头注意力机制?(为什么不使用一个头)
简单回答就是,多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。其实本质上是论文原作者发现这样效果确实好。举个例子例如“川普”
BERT的三个Embedding直接相加会对语义有影响吗?
Embedding的数学本质,就是以one hot为输入的单层全连接。请参考: https://kexue.fm/archives/4122也就是说,世界上本没什么Embedding,有的只是one hot。现在我们将token,position,segment三者都用one hot表示,然后concat起来,然后才去过一个单层全连接,等价的效果就是三个Embedding相加
作者:苏剑林
链接:https://www.zhihu.com/question/374835153/answer/1042845667
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
transformer中的attention为什么scaled?
假设向量 q和 k 的各个分量是互相独立的随机变量,均值是0,方差是1,那么点积qk 的均值是0,方差是 d k d_k dk。将方差控制为1,也就有效地控制了前面提到的梯度消失的问题。这里我给出一点更详细的推导:


使用BERT预训练模型为什么最多只能输入512个词,最多只能两个句子合成一句?
这是Google BERT预训练模型初始设置的原因,前者对应Position Embeddings,后者对应Segment Embeddings
在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch代码中它们是这样的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
上述BERT pytorch代码来自:https://github.com/xieyufei1993/Bert-Pytorch-Chinese-TextClassification,结构层次非常清晰。
而在BERT config中
"max_position_embeddings": 512
"type_vocab_size": 2
因此,在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
当然,如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。
Bert后的模型改进
-
XLNet: 主要有以下两点:
– AttentionMask或者叫Permutation Language Model:XLNet的出发点就是:能否融合自回归LM(自回归语言模型(Autoregressive LM),GPT 就是典型的自回归语言模型,ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,其实是根据上文内容预测下一个可能跟随的单词)和DAE LM(Denoising Autoencoder,Bert这种完形填空的方式,主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的)两者的优点。XLNet的具体做法比如包含单词Ti的当前输入的句子X,由顺序的几个单词构成,比如x1,x2,x3,x4四个单词顺序构成。假设我们固定住x3所在位置,就是它仍然在Position 3,之后随机排列组合句子中的4个单词,在随机排列组合后的各种可能里,再选择一部分作为模型预训练的输入X。比如随机排列组合后,抽取出x4,x2,x3,x1这一个排列组合作为模型的输入X。于是,x3就能同时看到上文x2,以及下文x4的内容了。这就是XLNet的基本思想。最终实现是通过AttentionMask来实现的,看原文图会很清楚。总结一下,Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已。
– 从Transformer-XL引入分段RNN和相对位置编码:即使用两个token的相对距离代替之前的绝对位置,具体的细节请参考原文,大致做法是在计算attention weight的时候把涉及到位置的矩阵单独拿出来改一下。 -
RoBERTa: Roberta
- 去掉下一句预测(NSP)任务,去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES without NSP)
- 动态掩码。一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking. (The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen
with the same mask four times during training.) - 文本编码。Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
-
Deberta:主要理解下面公式就比较容易,Deberta的主要改进:
q i = ( x i + p i ) W Q k j = ( x j + p j ) W K v j = ( x j + p j ) W V a i , j = s o f t m a x ( q i k j T ) o i = ∑ j a i , j v j q_i=(x_i+p_i)W_Q \\ k_j=(x_j+p_j)W_K \\ v_j=(x_j+p_j)W_V \\ a_{i,j} = softmax(q_ik_j^T) \\ o_i=\sum_j{a_{i,j}v_j} qi=(xi+pi)WQkj=(xj+pj)WKvj=(xj+pj)WVai,j=softmax(qikjT)oi=j∑ai,jvj
上面相当于把self attention的公式进行了展开,如果我们进一步把 q i k j q_ik_j qikj给展开,很明显结果中存在着4项,将不同位置进行替换、加成可训练参数就是XLNet、T5式、Deberta式的区别 -
ERNIE: 百度提出的ERNIE模型主要是针对BERT在中文NLP任务中表现不够好提出的改进。我们知道,对于中文,bert使用的基于字的处理,在mask时掩盖的也仅仅是一个单字,举个栗子:我在上海交通大学玩泥巴-------> 我 在 上 海 [mask] 交 通【mask】学 玩 【mask】 巴。作者们认为通过这种方式学习到的模型能很简单地推测出字搭配,但是并不会学习到短语或者实体的语义信息, 比如上述中的【上海交通大学】。于是文章提出一种知识集成的BERT模型,别称ERNIE。ERNIE模型在BERT的基础上,加入了海量语料中的实体、短语等先验语义知识,建模真实世界的语义关系。
那么怎么样才能使得模型学习到文本中蕴含的潜在知识呢?不是直接将知识向量直接丢进模型,而是在训练时将短语、实体等先验知识进行mask,强迫模型对其进行建模,学习它们的语义表示。此外,为了更好地建模真实世界的语义关系,ERNIE预训练的语料引入了多源数据知识,包括了中文维基百科,百度百科,百度新闻和百度贴吧(可用于对话训练)。具体来说, ERNIE采用三种masking策略:
– Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
– Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
– Entity-Level Masking:首先进行实体识别,然后将识别出的实体进行mask。 -
Albert:
– Factorized Embedding Parameterization: 对于Bert,词向量维度E和隐层维度H是相等的。在large和xlarge等更大规模模型中,E会随着H不断增加。Factorized意思就是在词表V到隐层H的中间,插入一个小维度E,多做一次尺度变换:O(VE+EH)。简单来说,就是没有直接把one-hot映射到hidden layer, 而是先把one-hot映射到低维空间之后,再映射到hidden layer。这其实类似于做了矩阵的分解。
– Cross-layer Parameter Sharing: 具体分为三种模式:只共享attention相关参数,只共享FFN相关参数、共享所有参数。“all-shared"之后,ALBERT-BASE的参数里直接从89M变成了12M,毕竟这种策略相当于把12个完全相同的层摞起来。Cross-layer Parameter Sharing是共享所有层的参数,Transfomer层的encoder部分的参数主要为attention参数和FeedForward的参数,当然LayerNorm也有要学习的参数,不过参数量也别少了。Cross-layer Parameter Sharing主要是共享attention部分的参数和FeedForward部分的参数。这样就大大减少了参数量,但是参数量共享,效果也会下降,论文中通过增加H的维度来进行提升。
– Sentence Order Prediction (SOP): SOP目标补偿了一部分因为embedding和FFN共享而损失的性能。Bert原版的Next Sentence Prediction目标过于简单了,它把"topic prediction"和"coherence prediction"融合了起来。SOP意图对其加强,将负样本换成了同一篇文章中两个逆序的句子,从而消除"topic prediction” -
基于Knowledge Graph的改进: KG-BERT(a),输入为三元组 (h,r,t)的形式,当然还有BERT自带的special tokens。举个栗子,对于三元组 ( S t e v e n J o b s , F o u n d e r , A p p l e ) (Steven Jobs, Founder, Apple) (StevenJobs,Founder,Apple) ,上图中的Head Entity输入可以表示为Steven Paul Jobs was an American business magnate, entrepreneur and investor或者Steve Jobs,而Tail Entity可以表示为Apple Inc. is an American multinational technology company headquartered in Cupertino, California或Apple Inc。也就是说,头尾实体的输入可以是实体描述句子或者实体名本身。
简单介绍一下Transformer的位置编码?有什么意义和优缺点?


缺点:这种编码在编码时考虑了相对位置,但是实际中,经过 W q W_q Wq, W k W_k Wk的变换,位置信息不能有效地被学习。(https://zhuanlan.zhihu.com/p/105001610)导致后序出现了不少改进:比如既然相对位置信息是在self-attention计算时候丢失的,那么最直接的想法就是在计算self-attention的时候再加回来。该工作出自Transformer的原班人马,看来Transformer提出时他们就已经发现这个问题了。具体做法是在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数,并且multi head之间可以共享。
Transformer为基础的大模型应该如何并行
- 数据并行。但是如果模型太大放不到一块卡上就没用了。为了解决把参数放到一块卡上的问题,演进出了论文Zero的思想,分为Zero-DP和Zero-R两部分。Zero-DP是解决Data parallel的问题,并行过程中内容不够,解决思路也比较简单,模型参数w只存在一台机器上,剩下的部分等用的时候找某台机器通过all-reduce请求就可以了。Zero-R是在每一层输入存不下,解决思想是带宽换内存。由Zero论文演进的Deep-speed框架影响了pytorch分布式计算的接口。
- 模型并行。典型的是按照GPipe的思路,将模型按层切开,这样会实现像CPU流水线一样并行的设计。
- 张量并行。典型的是Megatron LM,其实就是将矩阵乘法切开,参考下图:

DeepSpeed中参数量的估计
-
基本问题:在理解ZeRO前需要先理解一个基本问题,对于一个参数量为 Φ \Phi Φ的模型,使用Adam优化器单卡进行混合精度训练过程中至少占多大显存?结果是16* Φ \Phi Φ,分为以下两个部分:
- 模型参数、模型梯度使用半精度FP16进行保存,模型迭代前向反向过程使用的都是FP16,因此对于模型参数、模型梯度的存储需要2* Φ \Phi Φ+2* Φ \Phi Φ个字节(半精度FP16或者BF16占用两个字节所以*2),也就是下图红框中的2+2
- 在optimizer进行模型参数更新时,由于需要大量的累加和乘运算,半精度在这时经常出现精度溢出的情况,因此这时还是换回用FP32来优化,这也是混合精度计算命名的由来。在Adam更新时,原来FP16保存的模型参数会转换成FP32,占用4个字节。Adam中存在一阶矩和二阶矩两个Optimizer state,各占4个字节,也就是8个字节。因此这部分一共需要12个字节,也就是下图蓝框中的K=12(当然使用不同优化器这部分占用的显存是不一样的,这里就不展开了)。

-
核心想法:ZeRO的贡献分为ZeRO-DP(Data Parallel)和ZeRO-R(Residual State Memory)两部分优化思路:
- ZeRO-DP实际上是利用参数服务器all reduce的思想把数据分到Nd块卡上,减少平均到每一块卡上的显存占用。DeepSpeed在实际使用中需要预先配置使用stage1(只数据并行上述K=12优化器状态部分的显存)或者stage2(数据并行上述K=12优化器状态部分+梯度部分的显存)或者stage3(数据并行上述K=12优化器状态部分+梯度部分+模型参数部分的显存),理解上图就理解了Zero工作的核心思想
- ZeRO-R(Residual State Memory),这里Residual State Memory主要几个trick的叠加:1. 神经网络或者多层Transformers总依赖前一层算完才能再算下一层,保存前一层的结果会也会占用显存,ZeRO-R这里采用的是时间换空间通过合理并行来减少显存的想法;2. Constant Size Buffers,多卡通信中如果数据包太大或者太小都不利于整体效率,作者这里做了合理的tradeoff
-
实际操作:由HuggingFace出的accelerate(https://huggingface.co/docs/accelerate/usage_guides/deepspeed)本身可以简化DeepSpeed的配置。DeepSpeed的配置项非常多,手动配置较容易出错,建议使用accelerate config完成初始配置后直接用accelerate launch不带其他accelerate参数启动code
-
视频讲解: 来自李沐老师对这篇文章的精读(https://www.bilibili.com/video/BV1tY411g7ZT?vd_source=e260233b721e72ff23328d5f4188b304)强烈推荐,文章本身写的啰里啰嗦的
-
论文地址: https://arxiv.org/pdf/1910.02054.pdf
Tranformer是如何剪枝的
思路很多,在Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned一文里:even after training models normally(with all heads), many heads can be removed at a test time and it will not significantly affect the BLEU score, in fact, some cases removing few heads led to improving BLEU scores.

再比如A Fast Post-Training Pruning Framework for Transformers(可以参考https://mp.weixin.qq.com/s/XqA_6-i0t5Qcws_uNmAFXw)训练后剪枝:
剪枝是一种经典的模型压缩方法,包括非结构剪枝、结构剪枝,它通过减少模型的冗余参数、以达到降低模型计算复杂度的目的。传统剪枝的实现方式包括训练感知方式(如Network Slimming、SFP、Taylor-prune等)与结构搜索方式(如NetAdapt、AMC等),包含三个阶段,即模型预训练、模型剪枝、模型重训练。因此传统剪枝的压缩成本相对较高,依赖训练资源、且训练的时间开销相对较高。
为了避免较重的训练开销,近年来训练后剪枝逐渐成为研究热点。类似于Post-training量化,仅需少量无标注数据的校准(特征对齐、最小化重建误差等校准方法),通过训练后压缩便能获得较好的压缩效果,且压缩成本可控(对训练资源的依赖较轻、时间代价也较低)
Transformer模型因其特殊的模型结构(MHA+FFN),本文提出了针对性的训练后结构剪枝方法:1)基于Fisher信息设计Mask搜索算法(Mask search),寻找重要性最低的Attention heads或FFN neurons;2)通过Mask重排算法(Mask rearrangement),决定最终的(0-1取值)的剪枝Mask;3)基于少量无标注数据的知识蒸馏实现Mask微调(Mask tuning),获得Soft-mask以保持剪枝后模型的精度。
最终,针对BERT-base与DistilBERT,通过本文提出的训练后剪枝方法能够实现有效的结构剪枝,在GLUE与SQuAD数据集上,能够实现2x的FLOPS降解、1.56x的推理加速,精度损失低于1%;且在GPU单卡上,训练后剪枝的时间开销低于3分钟,实现过程非常轻量。
部分转载自:
- https://zhuanlan.zhihu.com/p/60821628
- https://zhuanlan.zhihu.com/p/105001610
- https://www.zhihu.com/question/347898375/answer/863537122
- https://towardsdatascience.com/head-pruning-in-transformer-models-ec222ca9ece7
- https://blog.csdn.net/nature553863/article/details/127190452
- https://mp.weixin.qq.com/s/XqA_6-i0t5Qcws_uNmAFXw
- https://zhuanlan.zhihu.com/p/630276154