RDMA加速集群性能提升
随着企业数字化进程的加速推进,各类创新应用如雨后春笋般不断涌现并付诸实践。数据作为现代企业的核心资产,对高性能计算、大数据深度分析、人工智能技术以及多元存储解决方案的需求日益旺盛。然而,在满足这些新兴应用场景时,传统的TCP/UDP等数据传输协议在性能与效率方面遭遇了显著挑战,出现了诸多难以逾越的技术瓶颈。
为应对这一问题,RDMA(Remote Direct Memory Access)技术应运而生,并逐渐成为提升集群性能的关键手段。RDMA通过绕过操作系统内核,实现网络间的直接内存访问,大幅度减少了数据处理中的CPU开销和延迟,从而有效解决了传统协议在高吞吐量、低延迟场景下的不足。借助RDMA技术,数据中心可以更好地优化集群间的数据交互效率,进而促进高性能计算任务、大规模数据分析及AI应用效能的显著提升。
RoCE技术优势及其生态系统发展
RoCE技术以其显著优势及生态系统的发展,对集群性能提升起到了关键作用。RDMA(远程直接内存访问)作为一种前沿的高性能网络通信技术,是InfiniBand标准的核心支撑。其原理基于DMA(直接内存访问),即允许设备在无需CPU介入的情况下直接访问主机内存资源。而RDMA更进一步,通过在网络接口层面实现跨越网络的直接内存数据交互,并绕过操作系统内核处理环节,从而提供高效、低延迟且高吞吐量的数据传输服务,尤其适用于大规模并行计算集群环境。
为优化传输效率并充分利用网卡功能,RDMA技术使得应用程序能够更好地掌控和利用网络链路资源。最初专为InfiniBand网络设计实施的RDMA技术,随着需求增长逐渐扩展至传统的以太网领域。在此基础上诞生了两种基于以太网的RDMA实现方式:iWARP和RoCE,其中RoCE又细分出RoCEv1和RoCEv2两个版本。相较于成本相对较高的InfiniBand方案,RoCE与iWARP技术提供了更具性价比的硬件解决方案。
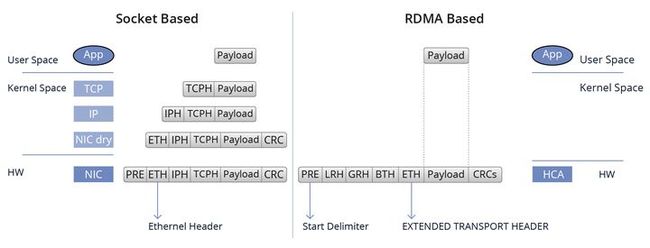
当RDMA技术运行于以太网环境中时,我们称之为RoCE(RDMA over Converged Ethernet)。当前,在高性能网络领域广泛应用的是基于RoCE v2协议(RDMA over Converged Ethernet)的主流网络解决方案。该协议成功将以太网与RDMA技术相结合,在多种以太网部署场景中实现了广泛的应用和深入推广,有力推动了集群性能的整体跃升。
添加图片注释,不超过 140 字(可选)
与传统的TCP/IP通信机制相比较,RDMA技术通过运用内核绕行(Kernel Bypass)和零拷贝(Zero Copy)技术实现了关键性能优化。这种优化显著降低了网络传输延迟,并有效减少了CPU使用率,进而缓解了内存带宽瓶颈问题,充分提升了系统对带宽资源的利用效率。
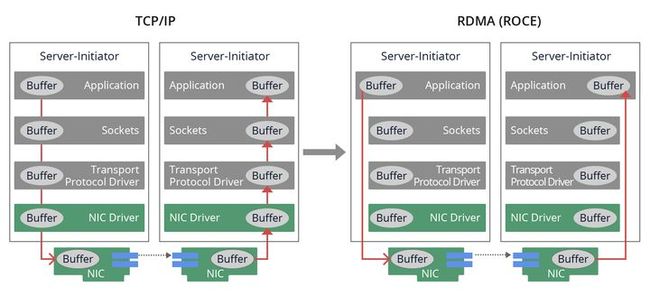
具体来说,RDMA技术开创了一种基于I/O直接访问的新型通道模式。在此模式下,应用程序能够直接借助RDMA设备的能力,跨越操作系统内核的限制,实现对远程虚拟内存空间的直接读写操作。这一特性极大地消除了数据在不同层级缓冲区之间复制的开销,以及上下文切换带来的延迟,从而确保集群中的计算节点能够以更高的速度、更低的延迟进行高效的数据交互,有力地提升了整个集群系统的性能表现。
添加图片注释,不超过 140 字(可选)
RDMA技术在应用程序与网络架构之间构建了一条专门的数据传输通路,巧妙地绕过了操作系统内核层的处理环节。通过精心优化这条直连数据路径,可以将用于数据转发的CPU资源占用率降低至近乎零的状态,充分利用ASIC芯片提供的强大计算性能。RDMA凭借其独特的机制,能够在不干扰操作系统的前提下,高效地将数据直接从网络传输至计算机存储区域,并实现不同系统内存间的高速数据迁移。
这一策略有效地消除了传统外部内存复制和上下文切换过程中产生的额外开销,从而释放了宝贵的内存带宽资源和CPU周期,极大地提升了应用系统的运行效率及整个集群的综合效能。目前,RDMA技术已在全球范围内的超级计算中心及互联网企业中得到广泛应用,并成功建立了一个成熟的应用程序与网络设备协同工作的生态系统。在当前项目中,将RDMA技术整合进企业级大规模数据中心体系结构,标志着该技术生态迈入了一个崭新的发展阶段。
GPU Direct-RDMA技术提升AI/HPC应用效率
在AI与HPC应用性能优化的进程中,GPU Direct-RDMA技术扮演着至关重要的角色。传统的TCP网络架构在数据包管理上高度依赖CPU处理,这导致其难以充分利用现有的带宽资源,尤其是在对带宽和延迟要求极高的AI环境以及大规模集群训练场景中。
RDMA技术不仅革新了CPU内存中用户空间数据在网络中的高效传输,更进一步地实现了跨越多服务器边界、在GPU集群内部不同GPU之间的直接数据交互。这一特性正是GPU Direct技术的核心价值所在,它作为提升HPC/AI系统性能的关键一环,为高性能计算和人工智能领域带来了革命性的变化。
随着深度学习模型复杂度的持续攀升及计算数据规模的指数级增长,单台机器的计算能力已无法满足日益严苛的需求。因此,涉及多台机器和多个GPU并行协同工作的分布式训练方式变得不可或缺。在此情境下,各机器间通信效率成为了衡量分布式训练性能的关键指标。GPUDirect RDMA技术恰逢其时,通过提供跨机器间GPU直接通信的能力,极大地提升了通信速度,从而有力推动了整个集群系统的性能表现。
➢ GPU Direct RDMA: 是一项利用网络适配器的RoCE功能的技术,其主要优势在于能够在GPU集群内的服务器节点之间实现高速内存数据交换。在网络设计与实施方面,NVIDIA通过支持GPU Direct RDMA功能显著提升了GPU集群的性能。
在GPU集群网络领域,对于网络延迟和带宽的高要求显得尤为重要。传统的网络传输方式有时会限制GPU的并行处理能力,导致资源利用率低下。特别是在GPU多节点通信过程中,传统的高带宽数据传输路径通常需要涉及CPU内存,这为内存读写操作和CPU负载引入了瓶颈问题。

添加图片注释,不超过 140 字(可选)
为了解决这些问题,GPU Direct RDMA技术采用了一种直接的方法,即让网络适配器设备暴露给GPU,从而促进GPU内存空间间的直接远程访问。这一创新方法显著提高了带宽和延迟性能,极大地提高了GPU集群运行效率。通过将网络适配器与GPU直接关联,GPU Direct RDMA消除了传统传输路径中涉及CPU的瓶颈,使得GPU之间的数据传输更为高效和快速。
数据中心交换机无损网络解决方案

添加图片注释,不超过 140 字(可选)
数据中心交换机采用的无损网络解决方案,针对在交换机上支持RoCE(远程直接内存访问)流量的场景,通常被称为无损以太网方案。这一全方位解决方案集中了实现高效网络运营的关键技术手段:
➢ ECN(Explicit Congestion Notification)显式拥塞通知技术:ECN在IP层与传输层引入了流量控制和端到端拥塞检测机制。该技术借助于IP数据包头部中的DS字段来实时反映网络传输路径上的拥塞状况。具备ECN功能的终端设备能够依据数据包内容动态评估网络拥塞状态,并据此调整传输策略以缓解拥塞压力。而增强型Fast ECN技术则通过在数据包出队列时即时标记ECN字段,显著减少了转发过程中ECN标记产生的延迟时间。如此一来,接收服务器能够快速识别并响应带有ECN标记的数据包,从而加快发送速率的动态调整过程。
➢ PFC(Priority-based Flow Control)基于优先级的流控制技术:PFC提供了逐跳优先级级别的流控能力。当设备进行数据包转发时,会根据数据包的优先级实施调度与传输,并将数据包映射到相应的队列中。若某一优先级的数据包发送速率超过了接收端的处理能力,导致接收端可用数据缓冲空间不足,此时设备将会向其前一跳节点发送PFC PAUSE帧。收到PAUSE帧后,前一跳节点会暂停对应优先级数据包的传输,直至接收到PFC XON帧或等待一定老化时间后再恢复数据流量。通过这种方式,PFC确保了一种类型流量出现拥塞时不会影响其他类型流量的正常转发,确保了同一条链路上不同类型数据包之间互不干扰的顺畅运行。
优化RDMA和RoCE产品选择
针对RDMA和RoCE产品优化选择,NVIDIA基于其在无损以太网实践中的丰富经验,将ECN视作关键的拥塞控制手段。借助硬件加速的Fast ECN支持,系统能够实现快速响应并确保高效的流量管控。同时,通过整合ETS(Enhanced Transmission Selection)机制以及创新的物理缓存优化技术,资源调度得到了针对多元流量模型的精细化调整。
然而,尽管PFC(Priority-based Flow Control)技术引入带来了一定优势,但也不可忽视其潜在的网络死锁风险。经过对比分析,我们发现PFC流控机制在提高网络稳定性、解决由拥塞引发的数据包丢失问题方面效果有限,并暴露出其固有的安全隐患与性能瓶颈。
RDMA在实现卓越端到端网络通信中扮演着核心角色,专注于大幅提升远程数据传输速率。这一过程涵盖了主机侧内核绕过技术、网络卡上的传输层卸载处理,以及在网络侧实施拥塞流控制等复杂环节的深度融合。这些措施共同带来了显著的低延迟、高吞吐量特性,以及极小的CPU占用率等优势。
不过,当前RDMA的实际应用仍面临可扩展性受限、配置修改过程复杂性等问题的挑战。因此,在不断演进的RDMA与RoCE产品领域中,精准把握技术发展趋势,充分应对各种局限性,是确保无缝集成及保持高性能网络解决方案长期稳定运行的关键所在。
在构建能够显著提升集群性能的RDMA网络架构时,除了不可或缺的高性能RDMA适配器和强大计算能力的服务器之外,高速光模块、高性能交换机以及高质量光纤电缆等核心组件同样扮演着决定性角色。在这方面,飞速(FS)公司提供的可靠高速数据传输产品及解决方案因其卓越表现而备受推崇。
作为业界领先的高速数据传输解决方案供应商,飞速(FS)精心打造了一系列定制化顶级硬件设备,诸如专为低延迟与高速传输场景设计的高性能交换机、 200/400/800G光模块,以及集成智能技术的网卡等。这些产品精准契合了大规模科学计算、实时数据分析、金融交易等领域对于极低延迟与极致稳定性的严苛要求。
飞速(FS)的产品与解决方案已广泛应用于多个行业,并成功满足了各类应用中对超低延迟环境的极高标准。在搭建高性能网络系统的过程中,飞速(FS)凭借其独特优势,在成本效益与运行效能之间实现了理想的平衡,从而成为众多用户部署此类网络时首选的合作伙伴。