以最快的速度带你体验炼出一炉LoRA的感觉!
正式开始LoRA训练
示范(以原神中的凝光作为案例)
step1 收集训练集
训练集图片要求:
-
训练集应当尽量涵盖训练对象的“多样化样本”
-
训练单一角色、数量在20~30张为宜
这里就使用
-
官方的立绘图
-
各个不同角度的游戏建模截图
-
少量还原度高的二创作品
step2 图片预处理(裁剪&打标)
裁剪:使用Web UI预训练(后期处理)的智能裁剪即可,
原则:
-
明白裁剪的目标是让ai更好的通过图片辨析训练对象
-
智能裁剪后可以对图片做手工调整
-
使图片聚焦在人物本身上
-
如果裁剪导致人物“截肢”等情况出现,可以选择不进行裁剪,要求没有那么死,像素也不是必须512
打标:使用WD 1.4 Tagger
最简单的方式就是使用WebUIl后期处理中的BLIP和DeepBooru,但是其结果不够准确和详细
WD 1.4 Tagger 可以在跑图的过程中可以帮我们反推作品提示词来准确还原画面元素;也拥有批处理功能,可以一次性给一个文件夹里所有的图片打标并生成同名txt文件
附加标签功能
可以在其中加入特定字词作为特定主体的“触发词”,比如角色姓名,添加之后就会出现在打好标的txt文件中并且排在首位
step3 设置训练参数
选择底模
设置底模(模型训练的基底),原则上使用最原始的模型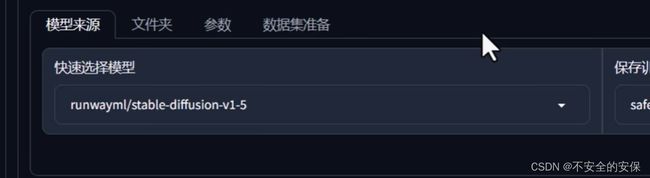
建议切换到Custom(自定义)后再通过下面的选单选择电脑中模型

SD模型一览
-
SD 1.4/1.5 (“第一代”模型) 流传广度高,占据绝对的主导地位
-
SD 2.0/2.1 (“第二代”模型) 流传广度低
-
SDXL 0.9/1.0 (“第三代”模型) 流传广度一般
-
原始训练集尺寸、原始绘制精度/图像质量,训练要求均提升,效果逐步提高
版本的意义:使用某个版本训练LoRA,则LoRA只能与该版本下的大模型一起使用,否则会报错(各个版本的底层逻辑不同)
NovelAI(NAL)
当训练模型偏二次元风格时,推荐使用NovelAI的初版泄露模型
SD最初也是使用“自然语言”出图
tag的由来
NovelAI用SD(1.5)的开源模型加入大量二次元图像进行大量二次元图像微调-推出二次元小说插图辅助生成服务,而这些二次元图片图片大多来自于一个叫Danbooru的网站,这个网站给图片打标签的方式就是今天tag的由来
-
tagger打标之所以好,就是因为他的反推模型是利用同一套图库标签进行训练
由于novelai模型的泄露和第4课接触到的模型融合技术的存在,这个模型成为今天绝大多数二次元风格的“祖师爷”
所以,如果你希望它在一个要打Tag出图的模型里可以表现得好,那我们同样使用一个用tag喂养的大模型——Novel AI(NAI)
挑选使用的模型
诸如NAI、SD1.5这样的模型已经算是“老古董”了,训练水平相对于一些新模型没有那么高
我们可以选择一些符合训练风格,且风格特征相对“中立”的比较新的触合模型进行训练
真实系风格对象:ChillOut Mix、Realistic Vision、MajicMix Realistic...
二次元系风格对象:AnyLoRA、Anything V3/V5、ReV Animated...
不考虑适用性:喜欢的就是最好的
建立项目文件夹
准备操作
新建一个文件夹并命名为训练项目的名字,在里面创建三个文件夹并分别命名为“image”,“models”,“log”
PS:文件夹路径中不要有任何中文和空格!会干扰一些脚本的执行
在“image”文件中再新建一个文件夹并命名为“重复次数次数_概念”,如“6_NingGuang”,其余两个文件空着就好,后续会生成训练产生的模型和记录训练状态的日志
-
重复次数Repeat:重复学习训练集图片的次数,影响步数计算和学习效果(见参数分析)
重复次数越多,AI学习效果越“深刻”
-
二次元图片建议设置为5~10
-
三次元可以考虑在10~30之间
-
概念名称Concept:训练对象的主要概念名称(可以是触发词),可利用此种方式向一个LoRA植入多种概念(后续讨论)
PS:预处理过的图片和文本需要放在这个文件夹里
回到Kohya
在第二个文件夹选单中将三个对应文件夹位置填写好,其中,“图片文件夹”应填写“image”文件夹而不是其中的概念文件夹。
最后一个“正则化图像”是一种用于避免图像过拟合的方式,为可选项可以不填。
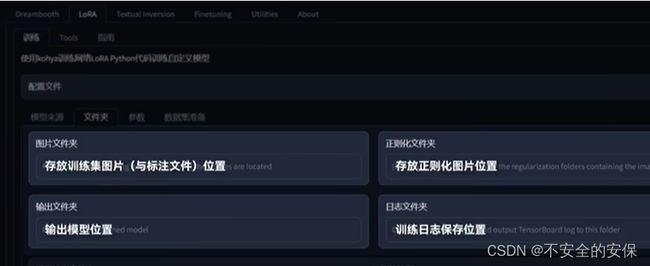
接着填写输出文件夹
调节参数
这里我们只需要两步,就可以直接体验用最快的速度炼出一炉LoRA的感觉!
-
将Presets(其中有很多经过检验的预设好的参数)设置为“iA3-Prodigy-sd15”
-
定义训练训练时长
训练集在20~30张,最大训练步数在1200~1500会是个不错的选择
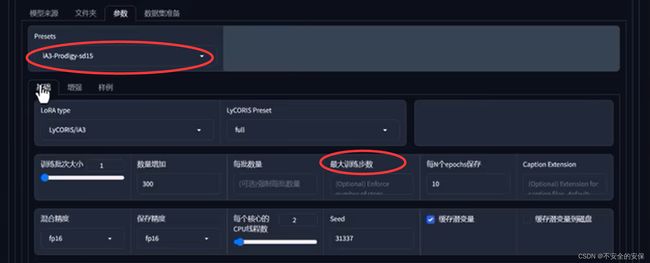
所有参数设置完毕,点击“开始训练”!
回到命令行窗口
命令行中会开始输出各种训练相关的信息,最上方的这些参数就是我们刚才设置的一切选项,也是训练脚本最真实的形态,如果这是报错就是其中设置的某个选项出现了问题
等待命令行推进,直至看见“学习开始”的标志就是训练正常在推进的标志了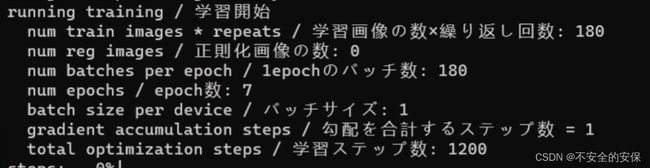
相较于其他训练模型,LoRA模型的训练的时间可谓是转瞬即逝。我们只需要20-60分钟即可完成训练,大功告成!训练成功!
验货!
回到最初设置的“models”文件夹中找到那个不带任何数字的文件,把它放到Stable Dlffusion的models/lora文件夹内后再打开Web UI
通过Lora选项调用训练好的LoRA模型![]()
输入我们最开始的提示词我们就可以得到我们想要的结果了!
学习资料:60分钟速通LORA训练!绝对是你看过最好懂的AI绘画模型训练教程!StableDiffusion超详细训练原理讲解+实操教学,LORA参数详解与训练集处理技巧_哔哩哔哩_bilibili