hadoop集群部署
hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构, 是一个存储系统+计算框架的软件框架,主要解决海量数据存储与计算的问题,是大数据技术中的基石。
Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,用户可以在不了解分布式底层细节的情况下,开发分布式程序,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
hadoop的部署方式
Hadoop的安装部署的模式一共有三种,就是如下三种:
1、独立模式(本地模式) standalone
默认的模式,无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。使用本地文件系统,而不是分布式文件系统。
2、伪分布模式 pseudodistributed
在一台主机模拟多主机。即Hadoop的守护程序在本地计算机上运行,模拟集群环境,并且是相互独立的Java进程。
3完全分布模式 fulldistributed
完全分布模式的守护进程运行在由多台主机搭建的集群上,在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
hadoop的集群部署(全面)
我也一时半会儿也不知道是伪分布部署,还是完全分布式部署。

1.创建虚拟机
可以先创一台虚拟机,再完全克隆两台虚拟机。
2.修改主机名
vi /etc/hostname
将3台虚拟机中内容分别改为
master
node1
node2
3.重启虚拟机,观看主机名是否修改成功
reboot
4.查看自己的网段
ip a
可以看见我的网段是192.168.200
5.配置静态ip
根据自己的网段进行网络规划:
master 192.168.200.16
node1 192.168.200.17
node2 192.168.200.18
命令如下:
cd /etc/sysconfig//network-scripts/
#查看网卡
ls
截图如下

#可能大家的网卡是其他如eth33,enp0s3之类的
#修改网卡配置文件
vi ifcfg-eno16777736
#master(最后3行,第2行)
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="eno16777736"
UUID="a168e9f7-af12-47d2-82d1-3896fcacc600"
DEVICE="eno16777736"
ONBOOT="yes"
IPADDR=192.168.200.16
GATEWAY=192.168.200.1
NETMASK=255.255.255.0
截图如下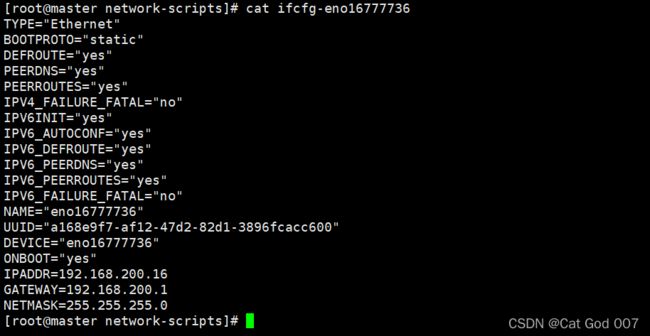
重启网络
service network restart
其他两个node节点网络配置文件如下
#node1(最后3行,第2行)
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="eno16777736"
UUID="36edaca1-6afd-45f5-8311-73df836402cf"
DEVICE="eno16777736"
ONBOOT="yes"
IPADDR=192.168.200.17
GATEWAY=192.168.200.1
NETMASK=255.255.255.0
截图如下
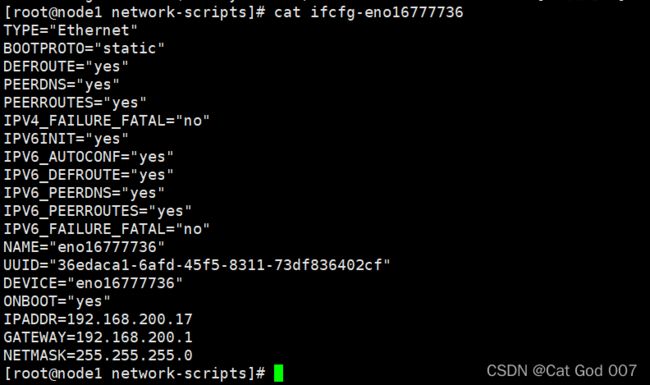
重启网络
service network restart
#node2(最后3行,第2行)
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="eno16777736"
UUID="ea3ed6ed-8f31-446f-bf92-f7152ff57fa1"
DEVICE="eno16777736"
ONBOOT="yes"
IPADDR=192.168.200.18
GATEWAY=192.168.200.1
NETMASK=255.255.255.0
截图如下
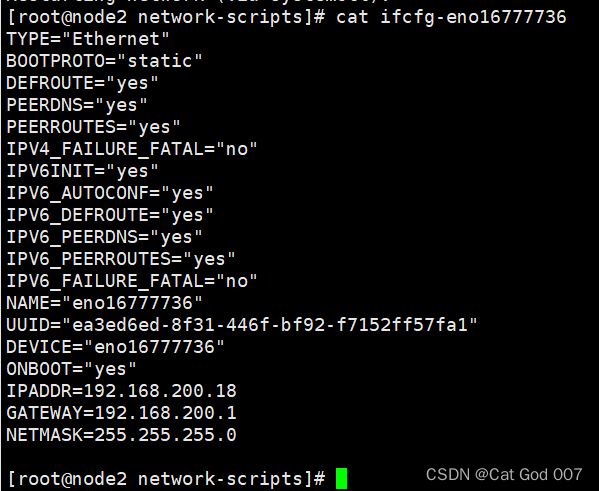
重启网络
service network restart
6.配置域名解析(3个节点都需要添加)
vi /etc/hosts
添加如下内容
192.168.200.16 master
192.168.200.17 node1
192.168.200.18 node2
截图如下

7.验证域名解析是否配置成功
ping -c 4 node1
ping -c 4 node2
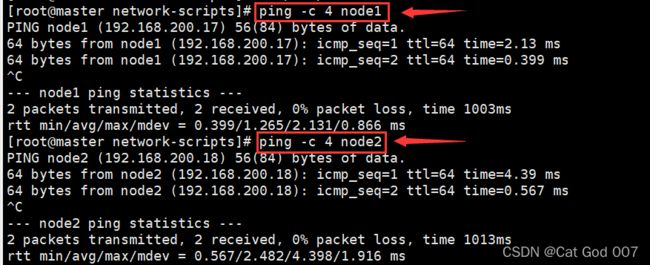
#大家也可尝试在node1节点测试与node2的域名配置是否成功
8.配置SSH免密
(1)先测试ssh是否安装
ssh
截图如下

(2)制作RSA密钥(此命令不唯一)
ssh-keygen -t rsa
3个回车
如图
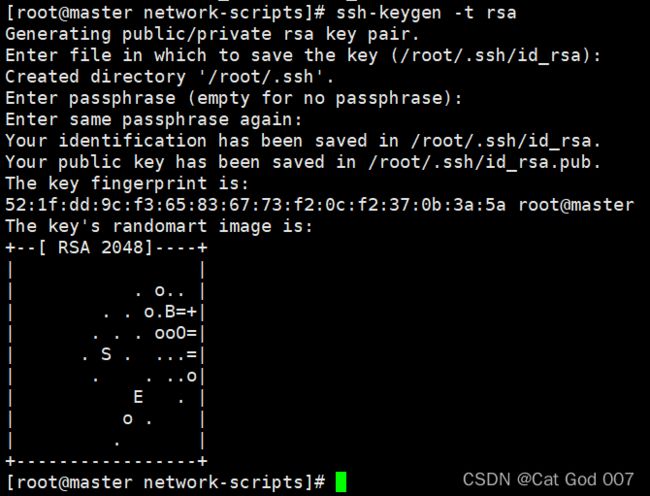
(3)查看创建的密钥,并把公钥文件复制到authorized_keys,并赋权
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
ls
chmod 0600 authorized_keys
(4)测试master是否能免密登录
ssh master
第一次需要输入密码进行验证,第二次不再需要输入密码。
如果是远程连接第一次可能会报错,是因为记录了它的密码,只要第二次登陆得上就行
如图
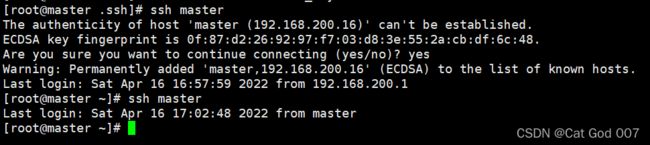
(5)再次查看密钥文件(会发现多了一个配置文件known_hosts)
如图
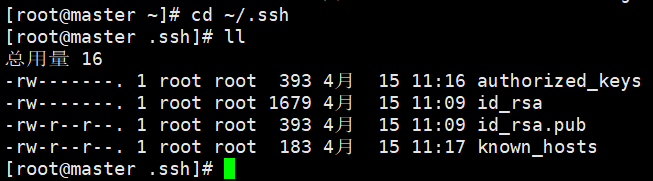
authorized_keys:需要免密登陆的主机的公钥信息
id_rsa:私钥
id_rsa.pub:公钥
known_hosts:已知的主机信息
(6)同理,进行对node节点进行配置
node1
ssh-keygen -t rsa
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
ls
chmod 0600 authorized_keys
ssh node1
截图如下

node2
ssh-keygen -t rsa
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
ls
chmod 0600 authorized_keys
ssh node2
截图如下
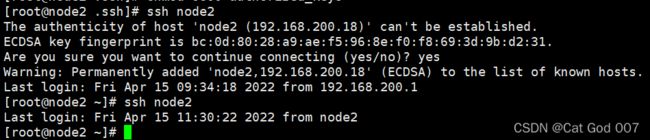
(7)在node节点上发送自己的公钥到master节点,master节点接受node节点发来的公钥。
node1
ssh-copy-id -i master
截图如下

node2
ssh-copy-id -i master
截图如下
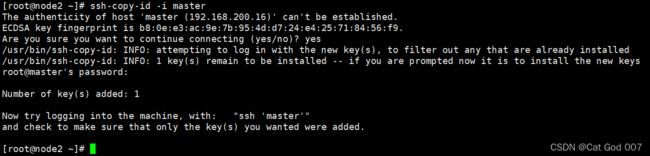
master
ssh-copy-id -i node1
ssh-copy-id -i node2
截图如下

查看master节点的authorized_keys的变化
more ~/.ssh/authorized_keys
截图如下

将自己的授权文件下发到node节点
cd ~/.ssh/
scp ~/.ssh/authorized_keys node1:/root/.ssh/
scp ~/.ssh/authorized_keys node2:/root/.ssh/
到此,主机之间已经实现了免密登陆
master
ssh node1

退出登陆
exit
9.关闭防火墙,selinux(所有节点都要执行)
systemctl stop firewalld
systemctl disable firewalld
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
截图如下

10.安装JDK
(1)创建安装目录
mkdir -p /opt/bigbata/
cd /opt/bigbata/
(2)把下载好的压缩包上传到master主机
(3)解压上传的压缩包
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /usr/local/
(4)修改解压的软件名
mv /usr/local/jdk1.8.0_202 /usr/local/jdk
(5)配置master节点的jdk环境变量
vi /etc/profile
在最后添加:
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
(6)重新加载环境变量文件
source /etc/profile
(7)检验JDK是否配置成功
java -version
截图如下

(8)将bigdata目录下的文件传送到node节点
scp -r /opt/bigbata/ node1:/opt/
scp -r /opt/bigbata/ node2:/opt/
(9)登陆node节点,查看复制的文件
cd /opt/bigbata/
ll
(10)解压,修改解压的软件名,配置node节点的jdk环境变量
node1
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /usr/local/
mv /usr/local/jdk1.8.0_202 /usr/local/jdk
vi /etc/profile
在最后添加:
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
重新加载环境变量文件,并检验JDK是否配置成功
source /etc/profile
java -version
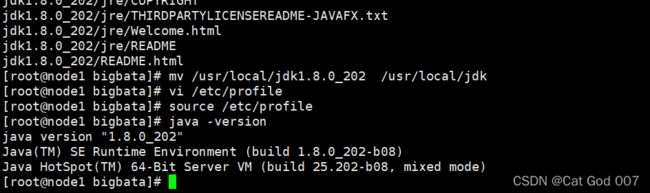
node2
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /usr/local/
mv /usr/local/jdk1.8.0_202 /usr/local/jdk
vi /etc/profile
在最后添加:
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
重新加载环境变量文件,并检验JDK是否配置成功
source /etc/profile
java -version

11.安装hadoop
cd /opt/bigbata/
(1)把下载好的压缩包上传到master主机
(2)解压上传的压缩包
tar -zxvf /opt/bigbata/hadoop-3.3.2.tar.gz -C /usr/local/
mv /usr/local/hadoop-3.3.2/ /usr/local/hadoop
(3)配置环境变量
vi /etc/profile
在最后添加:
export HADOOP_HOME=/usr/local/hadoop/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(4)重新加载环境变量文件,并检验JDK是否配置成功
source /etc/profile
(5)验证hadoop是否安装成功
hadoop version
出现与之前安装JDK相似的信息就行
12.配置Hadoop守护程序的环境
(3)修改hadoop-env.sh文件
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.sh
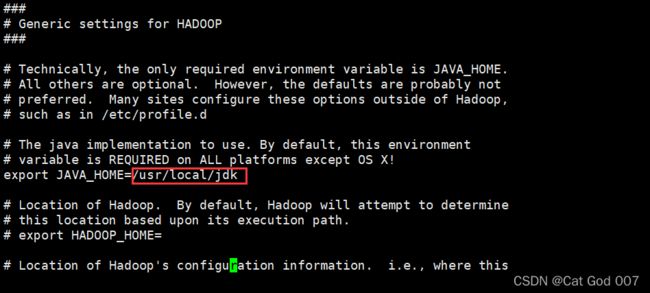
查询搜索:/export JAVA_HOME
添加java_home的绝对地址
export JAVA_HOME=/usr/local/jdk
截图如下
13.配置Hadoop的守护进程
(1)修改core-site.xml
此文件包含诸如用于Hadoop实例的端口号,为文件系统分配的内存,用于存储数据的内存限制以及读/写缓冲区大小的信息。
cd /usr/local/hadoop/etc/hadoop
vi core-site.xml
将
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdata/hadoop-3.0.0/tmp</value>
</property>
</configuration>
(2)修改hdfs-site.xml
此文件包含本地文件系统的复制数据值,namenode路径和datanode路径等信息。这意味着您要存储Hadoop基础架构的位置。
cd /usr/local/hadoop/etc/hadoop
vi hdfs-site.xml
在
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
(3)修改mapred-site.xml
此文件用于指定我们使用的MapReduce框架
cd /usr/local/hadoop/etc/hadoop
vi mapred-site.xml
在
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(4)修改yarn-site.xml
此文件用于将Yarn为Hadoop配置为Hadoop。
cd /usr/local/hadoop/etc/hadoop
vi yarn-site.xml
在
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn/*:/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(5)配置workers文件
cd /usr/local/hadoop/etc/hadoop/
vi workers
修改Datanode节点名
node1
node2
原有的可以删掉或排到最后
(6)将修改的软件包传给node节点
scp -r /usr/local/hadoop/ node1:/usr/local/
scp -r /usr/local/hadoop/ node2:/usr/local/
14.修改启动,停止的脚本
cd /usr/local/hadoop/sbin
(1)修改start-dfs.sh,stop-dfs.sh
vi start-dfs.sh
都在开头处(#!/usr/bin/env bash下)添加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)修改stop-dfs.sh
vi stop-dfs.sh
在开头处(#!/usr/bin/env bash下)添加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(3)修改start-yarn.sh
vi start-yarn.sh
在开头处(#!/usr/bin/env bash下)添加如下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
(4)修改stop-yarn.sh
vi stop-yarn.sh
在开头处(#!/usr/bin/env bash下)添加如下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
(5)将修改的软件包传给node节点
scp -r /usr/local/hadoop/sbin node1:/usr/local/hadoop/sbin
scp -r /usr/local/hadoop/sbin node2:/usr/local/hadoop/sbin
15.启动Hadoop平台
start-all.sh
如果之前启动了,需要先停掉再启动
start-all.sh
stop-all.sh
可能会出现node节点缺少logs目录(在所有node节点执行)
mkdir -p /usr/local/hadoop/logs
16.格式化命名节点
hadoop namenode -format
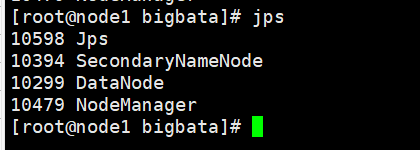
17.查看服务是否安装完毕(各个节点都要执行)
jps
截图如下


18.通过浏览器进行访问
http://192.168.200.16:50070
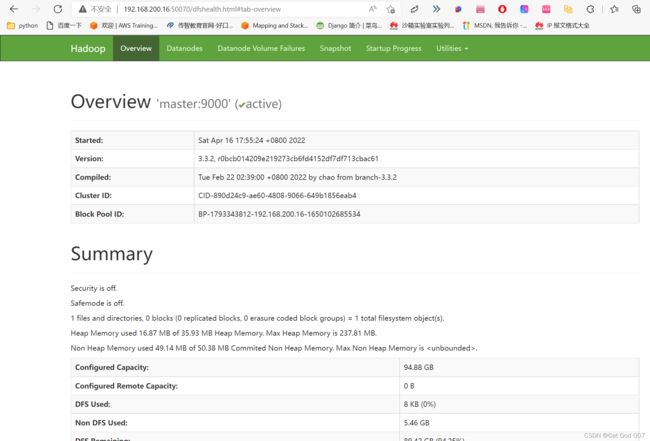
感谢大家,点赞,收藏,关注,评论!