linux进程切换、多进程编程、进程间通信详解
目录
0.写在前面
1.这里用跟踪helloworld程序 来对计算机系统的学习
1.进程相关概念介绍
1.查看电脑上运行的进程:ps
2.什么是进程
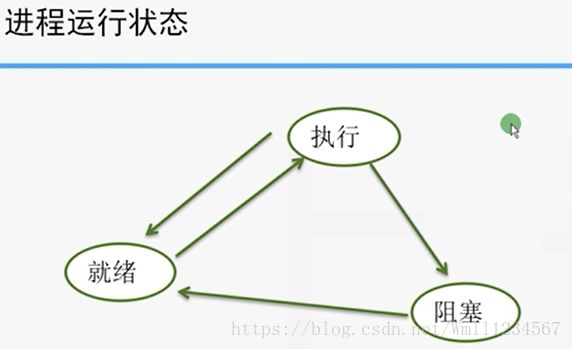
3.进程切换
进程切换终极总结
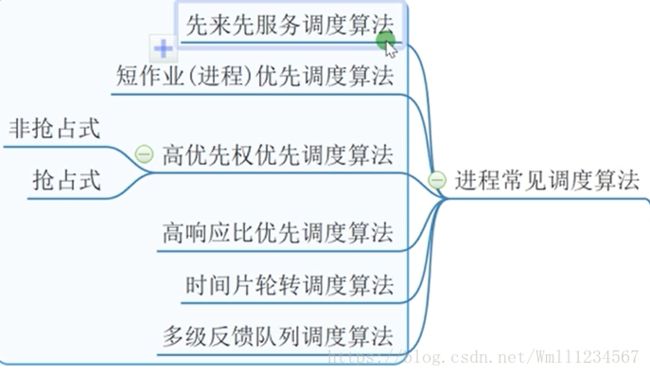
4.进程管理
3.进程创建
1.函数fork()
fork()函数特性
实例验证fork()特性
4.进程/线程同步的方式和机制、进程间通信
进程间通信主要包括管道, 系统IPC(包括消息队列,信号量,共享存储), SOCKET.
进程间同步:
二、进程间通信 —— 管道
1.无名管道
2.命名管道fifo
三、进程间通信 —— 共享内存映射
普通文件进程通信
存储I/O映射
四、进程间通信 —— 本地套接字
其实就是socket编程,只不过使用上参数使用不同:见如下
四、进程间同步
0.写在前面
在讲正文之前,还想说明一些程序是怎么跑起来的,在计算机种是怎么存在和运行的?以及一些计算机组成相关知识 这将有助于理解多进程、多线程的的应用场景。(这里将十分诚恳强烈推荐一本书:深入理解计算机系统(黑皮书)对于新手则非常棒)
从上思维导图的三角图形展示,我们知道,存储器的一些性能特征:我们用一个数量级来说明这种差异:
从磁盘读一个字的时间开销 VS 从主存读取要慢1000万倍
从主存读的开销 VS 从寄存器读取要慢 100 倍
1.这里用跟踪helloworld程序 来对计算机系统的学习
【1】.键盘输入:./hello shell(这里是bash)程序将字符逐一读入寄存器中,再放入主存(如果有DMA,则不需要经过cpu,直接将程序和数据放入主存)
【2】放入主存后,cpu开始处理程序每条指令,最终结果从主存赋值到显示设备,hello world就打印出来了。
以上只是一个大致的流程。这里详细说一下,hello这个进程运行起来在内存是什么样子的?
进程是对正在运行的程序一种抽象。操作系统刻意同时运行多个进程,表面上看似乎是大家同时在使用计算机系统资源(如处理器,主存,I/O设备)。其实并不是。大家其实是并发运行,很快的轮流使用这些资源,所以看起来似乎大家一起在使用(这里就像灯泡,灯泡的频率很高,以至于人眼无法观察到,所以认为灯泡一直亮着)
如何实现并发(一个进程和另一个进程指令交错执行,操作系统实现这种交错执行的机制称之为上下文切换)呢? :进程切换来实现。
虚拟内存:又为每个进程提供了一个假象,即每个进程都在独占使用主存,每个进程看到的内存都是一样的,成为虚拟地址空间。
如下是进程的虚拟地址空间结构
虚拟内存、内存管理的知识我觉得非常重要,可以系统学习下。我这里问一个问题,刺激一下大家想要去学习的欲望。?我们的主存也就4g,8g大小,那是如何运行起比这还大的程序呢?
另:MMU:虚拟你存映射单元 ,在cpu里 (一般为4K ),这个完成虚拟内存和物理内存的联系。
用户空间 内核空间

1.进程相关概念介绍
1.查看电脑上运行的进程:ps
我们的操作系统上运行了很多进程
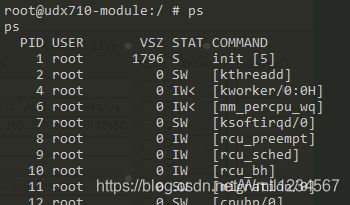
可以看到第一个进程 init .在Linux系统中,第一个进程是系统固有的、与生俱来的或者说是由内核的设计者安排好的,内核在引导并完成了基本的初始化以后,就有了系统的第一进程。并且所有的进程都是由这个原始进程或者它的子孙后代所创建,都是这个进程的“后代”
2.什么是进程
1、进程可以看做程序的一次执行过程。在linux下,每个进程有唯一的PID标识进程。PID是一个从1到32768的正整数,其中1一般是特殊进程init,其它进程从2开始依次编号。当用完32768后,从2重新开始。
2、进程在linux中呈树状结构,init为根节点,其它进程均有父进程,某进程的父进程就是启动这个进程的进程,这个进程叫做父进程的子进程。
3、linux系统提供了一个函数fork(),fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
3.进程切换
进程是对正在运行的程序一种抽象。操作系统刻意同时运行多个进程,表面上看似乎是大家同时在使用计算机系统资源(如处理器,主存,I/O设备)。其实并不是。大家其实是并发运行(不停的进行进程切换),很快的轮流使用这些资源,所以看起来似乎大家一起在使用(这里就像灯泡,灯泡的频率很高,以至于人眼无法观察到,所以认为灯泡一直亮着)
我们这里如果想知道 进程如何切换的,需要先学习一下虚拟内存这个概念
虚拟内存:为每个进程提供了一个假象,即每个进程都在独占使用主存,每个进程看到的内存都是一样的,成为虚拟地址空间。
- 什么时候可能进行进程切换呢?
这里我们先对进程做一个粗略的抽象:一个任务(就是进程)含有代码段、数据段、堆栈段,还有一个任务状态段TSS。这个任务状态段TSS记录当前任务的所有状态信息,包括寄存器、系统参数等等。TSS段的描述符放在TR寄存器中(也就是说访问TR就能访问当前任务的TSS段了)
- 1.系统调用
系统调用可以解释为操作系统为用户提供的一些接口,这些接口提供了对系统硬件功能的操作。这样说大家可能还有点抽象,我再举一个更具体的例子:比如我要写一个程序,这个程序的功能就是在屏幕上显示一个字符串“hello,world!”。那么实现这么一个在屏幕上显示一个字符串的操作就是系统调用write()的功能。
那么系统调用的意义在哪里呢?
你想想看,你写一个程序还需要自己去实现在屏幕上打印字符串的代码,这也太累人了吧,,因此系统调用把我们从底层的硬件编程中解放了出来。再者,系统调用是内核代码,内核代码能访问系统上的所有地址空间,而我们执行的代码是用户空间的代码,用户空间的代码在对系统进行操作时是有限制的,(作为一个菜鸟程序员,系统如果不对你写的代码进行限制,,万一把系统搞蹦了呢。。)。因此系统调用的另一个功能就是维护了系统的安全性,,你要用就直接调用我这个接口就行了,,不用你自己写。系统调用还有一个功能就是为了方便程序的移植性。。
总之,你就把系统调用当做一个接口,什么时候你需要使用它了,调用一下它就行了,既方便又安全。。
你可能会有疑问,我们平时在写C语言时打印一个字符串不是用printf()函数吗?这个printf()跟前面提到的那个系统调用write()有什么区别呢?问对了。
其实你可以把库函数当做是对系统调用的又一次封装。。什么意思呢?系统调用作为内核提供给我们的接口,它的执行效率是比较高效精简的。但是有时候我们需要对获取的信息进行更复杂的处理,这个时候如果我们把这些处理过程包装成一个函数再提供给程序员,不是更方便编程了吗?因此一个库函数有可能含有一个系统调用,有可能有好几个系统调用,当然也有可能没有系统调用,比如有些操作就不需要涉及内核的功能。
总之,库函数是面向程序员的应用编程接口。看一下下面这张图也许更明白了它们之间的关系:
说完了库函数和系统调用之间的关系,下面我们来看看系统调用到底是怎么运行的。
当一个进程正在运行时,遇到读写文件什么的,此时会发生一个中断,中断发生后,系统会把当前用户进程的一些寄存器信息保存在内核堆栈中(以备将来恢复),接着去执行中断服务程序,我们这里是去执行系统调用,Linux中通过执行int $0x80来执行系统调用的中断,但是内核实现了很多系统调用,所以进程必须指明需要哪个系统调用,这时候就需要传递一个系统调用号。这个系统调用号就存放在%eax寄存器中。
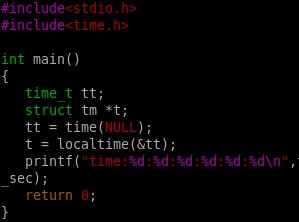
下面我们通过一个例子来说明:我们这里这个程序用来显示当前的时间。
首先我们通过库函数来实现:
结果如下:成功获得当前时间。
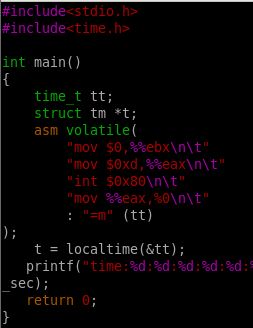
接下来我们通过嵌入汇编语言来实现系统调用:
发现没?首先通过mov $0xd %%eax来将系统调用号放入%eax寄存器中,通过查阅,发现time()的系统调用号是13。这个时候通过执行int $0x80,系统就会去执行time()这个系统调用了。
查看结果:
看,依然能够获得系统的时间!
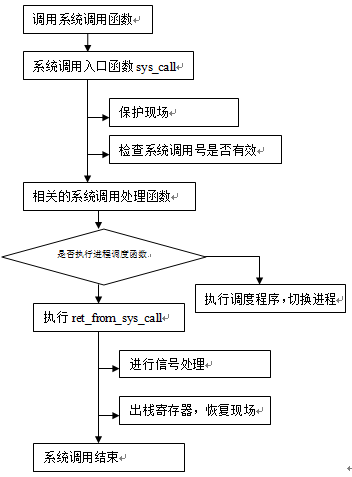
整个过程如下:首先指令流执行到系统调用函数时,系统调用函数通过int 0x80指令进入系统调用入口程序,并且把系统调用号放入%eax中,如果需要传递参数,则把参数放入%ebx,%ecx和%edx中。进入系统调用入口程序(System_call)后,它首先把相关的寄存器压入内核堆栈(以备将来恢复),这个过程称为保护现场。保护现场的工作完成后,开始检查系统调用号是不是一个有效值,如果不是则退出。接下来根据系统调用号开始调用系统调用处理程序(这是一个正式执行系统调用功能的函数),从系统调用处理程序返回后,就会去检查当前进程是否处于就绪态、进程时间片是否用完,如果不在就绪态或者时间片已用完,那么就会去调用进程调度程序schedule(),转去执行其他进程。如果不执行进程调度程序,那么接下来就会开始执行ret_from_sys_call,顾名思义,这这个程序主要执行一些系统调用的后处理工作。比如它会去检查当前进程是否有需要处理的信号,如果有则去调用do_signal(),然后进行一些恢复现场的工作,返回到原先的进程指令流中。至此整个系统调用的过程就结束了。
注:关于进程调度函数schedule()和信号处理函数do_signal()我们会在后面的博客中具体进行讲解。
好了,知道了系统调用的大致执行过程,下面我们来看看Linux0.11内核是如何实现这一功能的。
我们以Linux0.11内核中init/main.c中的fork()函数为例(fork()是一个系统调用)。
在main.c中有这么几行代码:
这里的_syscall0表示内嵌宏代码,(不明白?没关系),我们只要知道执行fork(),就相当于执行_syscall0(),它的定义在include/Unistd.h中:
这是一段嵌入在C语言的汇编代码(注:在Linux内核中有很多这样的代码,为的是在某些关键的地方使用汇编代码提供运行效率)。这段代码的大致含义是:执行int 0x80,把系统调用号放入%eax。这个时候系统就自动进入了系统调用入口程序_system_call中,它在kernel/System_call.s中:
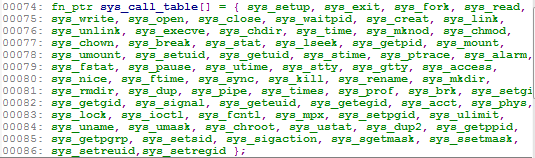
第81-82行的代码是判断系统调用号是不是有效值。从第83-93就在进行一些入栈的操作,紧接着第94行代码执行call _sys_call_table(,%eax,4),这个_sys_call_table是什么东西呢?它就是系统调用处理函数的指针数组,它里面包括了所有的系统调用。这个指针数组定义在include/linux/Sys.h,截个图给大家看看
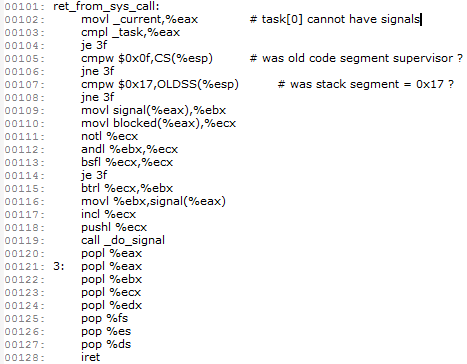
看到没?我们要调用的fork()它的处理函数就是sys_fork(),它处在第3个位置上,所以当我们执行call _sys_call_table(,%eax,4)时,它就自动去执行sys_fork()啦!从系统调用处理函数返回后,第96-100的代码会去判断需不需要执行调度函数schedule。如果不需要的话,就开始执行ret_from_sys_call了,它同样在kernel/System_call.s中:
这个函数会去检查是否有信号需要处理,如果有则调用do_signal函数。标号3那个位置的汇编代码就是进行一些恢复现场的工作。
Linux0.11内核的系统调用的整个过程大概就是这样!
- 2.硬件中断
硬件中断是一个异步信号, 表明需要注意, 或需要改变在执行一个同步事件.硬件中断是由与系统相连的外设(比如网卡 硬盘 键盘等)自动产生的. 每个设备或设备集都有他自己的IRQ(中断请求), 基于IRQ, CPU可以将相应的请求分发到相应的硬件驱动上(注: 硬件驱动通常是内核中的一个子程序, 而不是一个独立的进程). 比如当网卡受到一个数据包的时候, 就会发出一个中断.
处理中断的驱动是需要运行在CPU上的, 因此, 当中断产生时, CPU会暂时停止当前程序的程序转而执行中断请求. 一个中断只能中断一颗CPU(也有一种特殊情况, 就是在大型主机上是有硬件通道的, 它可以在没有主CPU的支持下, 同时处理多个中断).
硬件中断可以直接中断CPU. 它会引起内核中相关代码被触发. 对于那些需要花费时间去处理的进程, 中断代码本身也可以被其他的硬件中断中断.对于时钟中断, 内核调度代码会将当前正在运行的代码挂起, 从而让其他代码来运行. 它的存在时为了让调度代码(或称为调度器)可以调度多任务.
- 3.时钟中断 (包括时间片到)
以下出自:https://www.cnblogs.com/yudao/p/4388575.html
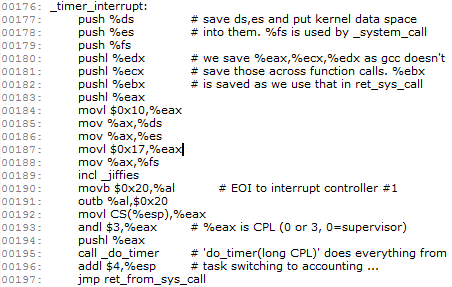
假设此刻CPU正在执行进程1,我们知道:系统有一个时钟频率,每隔一段时间就会发生一次时钟中断,这个时间段我们称为一个滴答。假设经过了一个滴答,系统发生时钟中断,此时时钟中断处理程序就会被自动调用(timer_interrupt),timer_interrupt定义在kernel/System_call.s中,如下图所示:
同我们上一篇讲的_system_call一样,它首先会执行一些保护现场的工作,接着在第189行代码中把_jiffies的值加1(_jiffies表示自系统启动以来经过的滴答数),接下来第192-194的代码将执行此次时钟中断的特权级CPL压入堆栈,用来作为后面do_timer的参数,接下来开始执行do_timer,do_timer函数定义在Kernel/Sched.c中,这个函数的主要作用是将当前进程的用户态执行时间或内核态执行时间加1,然后将当前进程的剩余时间片减1.
如果当前进程的时间片还有剩余,那么直接return返回继续执行,接下来判断当前任务的CPL是否是0,如果是0,说明当前任务是在内核态被中断的,而Linux0.11中内核态是不能被抢占的,所以直接返回执行,如果不是0,则执行进程调度程序schedule()。接下来我们来分析schedule()这个函数,schedule函数同样定义在Sched.c中,它里面包含下面两段代码:
这段代码的作用是:遍历任务数组,检查它们的报警定时值,如果该值小于jiffies,说明该任务的alarm时间已经过了,那么就在它的信号位图中置SIGALRM信号,表示向任务发送SIGALARM信号,然后将alarm清零,接下来检查是不是还有别的未被阻塞的信号,如果有并且当前的进程状态是可以被打断的,那么把这个任务置为就绪态。
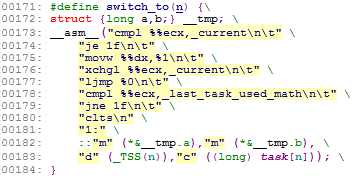
第124-142行的代码重新遍历整个任务数组,找出任务状态处于TASK_RUNING并且时间片最长的那个任务。并调用swith_to()函数切换到那个任务。swith_to函数定义在include/Linux/Sched.h中。
switch_to是一段汇编代码,下面来解释一下这段代码的含义:首先检查要切换的任务是不是当前任务,如果是则直接退出。接下来把任务n(要切换去的任务)的TSS段放到_tmp.b中,然后把任务n放入_current中,把当前任务放入%ecx中切换出来,然后执行一个长跳转到*&_tmp的位置(这是新任务的TSS地址处),此时CPU会把所有寄存器的内容保存到当前任务TR执行的TSS段中,然后把新任务的TSS段中的寄存器信息恢复到CPU的各个寄存器中,这样系统就正式开始执行新的任务了。第178-180的代码是判断原任务是否使用过协处理器,如果没有则直接结束






进程切换终极总结
以上所有讲述其实我们只用知道:进程在切换的时候:
要做到两步:首先是切换虚拟地址空间,怎么切换呢,
第一步:只需要在cpu的页表目录里找到下一进程的虚拟页表,再根据虚拟页表找到其起始物理地址装入到控制寄存器CR3(此寄存器总是指向当前进程的页面目录)中
第二步(关键的一步):堆栈的切换
接下来把任务n(要切换去的任务)的TSS段放到_tmp.b中,然后把任务n放入_current中,把当前任务放入%ecx中切换出来,然后执行一个长跳转到*&_tmp的位置(这是新任务的TSS地址处),此时CPU会把所有寄存器的内容保存到当前任务TR执行的TSS段中,然后把新任务的TSS段中的寄存器信息恢复到CPU的各个寄存器中,这样系统就正式开始执行新的任务了
4.进程管理
这里就不得不提到一个数据结构:进程控制块(PCB),操作系统为每个进程都维护一个PCB,用来保存与该进程有关的各种状态信息。进程可以抽象理解为就是一个PCB,PCB是进程存在的唯一标志,操作系统用PCB来描述进程的基本情况以及运行变化的过程,进程的任何状态变化都会通过PCB来体现。PCB包含进程状态的重要信息,包括程序计数器、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其它在进程由运行态转换到就绪态或阻塞态时必须保存的信息,从而保证该进程随后能再次启动,就像从未中断过一样
这个task_struct 结构体在 头文件/sched,h中看一看到 ,这个结构体很大,存了很多进程相关信息
进程控制块中存储了什么信息?
进程标识信息:如本进程的标识,本进程的父进程标识,用户标识等。
处理机状态信息保护区:用于保存进程的运行现场信息:
用户可见寄存器:用户程序可以使用的数据,地址等寄存器
控制和状态寄存器:程序计数器,程序状态字
栈指针:过程调用、系统调用、中断处理和返回时需要用到它
进程控制信息:
调度和状态信息:用于操作系统调度进程使用
进程间通信信息:为支持进程间与通信相关的各种标识、信号、信件等,这些信息存在接收方的进程控制块中
存储管理信息:包含有指向本进程映像存储空间的数据结构
进程所用资源:说明由进程打开使用的系统资源,如打开的文件等
有关数据结构连接信息:进程可以连接到一个进程队列中,或连接到相关的其他进程的PCB
我们关注以下重点信息即可:加粗的必须记住
1. 进程id;2.进程的状态:;3.进程切换时需要保存和恢复的一些cpu寄存器
4.描述虚拟地址空间信息;5.描述控制终端信息(交互);6.当前工作目录位置;
7.umask掩码;8.文件描述符,包含很多指向file结构体的指针;9.和信号相关的东西;
10.用户id,组id;11.会话(session) 和进程组;12.进程可以使用的资源上限;

- 环境变量:
LD_LIBRARY_PATH :动态链接器使用
PATH:记录可执行文件目录位置
SHELL: 解析命令的,记录当前所使用的环境变量是哪个
TERM:终端,
HOME :当前用户的宿主目录
查看所有环境变量:直接执行 env


3.进程创建
在Linux系统中,一个新的进程一定要由一个已经存在的进程复制出来,而不是创建出来(而所谓的创建就是复制)而这里说的创建其实就是把原来的进程分配的资源、包括属于最低限度的task_struct数据结构和系统空间栈、堆进行共享;还要设置这个进程的系统空间栈,使的这个进程很像新的进程,其实你们都被骗了,以为这个进程是刚刚创建好的,其实这个进程更像是一个“克隆体”。
- 由上述所说,进程是由复制而来,那么到底是怎么复制的呢,具体是怎么实现的呢?
首先讲解进程的创建就像是一个已经存在的“父进程”进行 生物上细胞分裂一样地复制出一个和自己一样的“子进程”,这里的一样指的是几乎一样,一些细节后序 将会做出补充,实际上复制出来的子进程有自己的task_struc结构和系统空间堆栈,与它的父进程共享父进程所拥有的资源。例如父进程打开了五个文件,那么子进程也有五个打开的文件,而且这些文件的当前读写指针也停在相同的地方。所以这些做的就是“复制”的操作
- 父进程把存储空间拷贝给子进程的时机和方式
fork方法并不会直接将父进程的数据空间复制给子进程,而是子进程在修改数据空间上的数据时,才会给子进程分配空间
- 写时拷贝
我们把父进程给子进程拷贝存储空间的方式称为写时拷贝。
写时拷贝是一种可以推迟甚至免除拷贝数据的技术。在父进程创建子进程时,内核此时并不复制整个父进程地址空间给子进程,而是让父进程和子进程共享父进程的地址空间,内核将它们对这块地址空间的权限变为只读的。只有在需要写入修改的时候,内核为修改区域的内存制作一个副本,通常是虚拟存储器系统的一页。从而使父子进程拥有各自的地址空间。也就是说,新的地址空间只有在需要写入修改的时候才开辟,在此之前,父子进程只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。
1.函数fork()
NAME
fork - create a child processSYNOPSIS
#include
#includepid_t fork(void);
RETURN VALUE(返回值)
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure,
-1 is returned in the parent, no child process is created,and errno is set appropriately.1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
-
fork()函数特性
- 父子进程之间的关系
当我们执行fork函数时用fork()函数生成一个进程,调用fork函数的进程为父进程,新生成的进程为子进程,可以理解为复制一份一样的代码;
创建后父子进程是两个独立的进程,各自拥有一份代码(子进程在没有写入操作之前,和父进程共享,前面讲过(写时拷贝))。fork()方法调用之后,父,子进程都从fork()调用之后的代码开始运行。
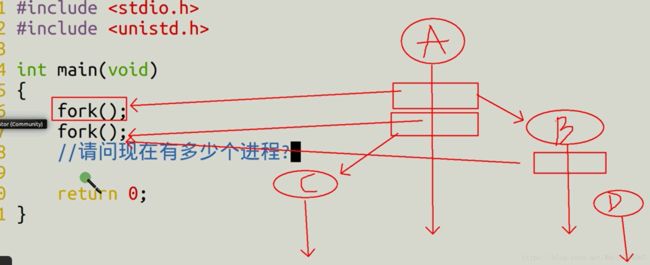
#include#include #include #include int main(int argc, char *argv[]) { fork(); fork(); //请问现在有多少个进程? return 0; }
上面那个图示应该很清楚了,假设第一个父进程称为A,他要执行的代码有:fork();fork(); return 0;
A进程遇到第一个fork() ,就创建进程B,进程B接下来执行的代码就是:fork();return 0;
A进程执行第二个fork(),就创建进程C,进程C接下来执行的代码就是:return 0;
B进程执行接下来的代码fork(),就创建进程D,进程D接下来执行的代码就是:return 0;
所以一共是创建了四个进程。
下面这个两个图示创建了几个进程呢?可以编译测试一下。感受一下。

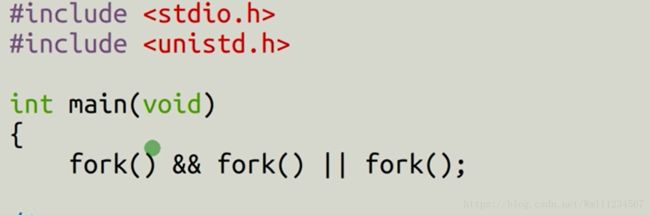
- 父子进程返回情况 (fork()函数为什么返回两次呢?)
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork()函数中,等待返回。因此fork()函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。 fork()调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:1.在父进程中,fork()函数返回新创建子进程的pid;2.在子进程中,fork()函数返回0;3.如果出现错误,则fork()函数返回一个负值。
理解:解释fork()函数返回的值为什么在父子进程中不同。"其实就相当于链表,进程形成了链表,父进程的fork()函数返回的值指向子进程的pid(进程id), 因为子进程没有子进程,所以其fork()函数返回的值为0(类似于与单链表的null)."

- 父子进程执行情况
fork之后是两个独立的进程,所以两个进程会被交给操作系统,然后操作系统进行调度,调度到谁就运行谁,故父子进程并发执行,不是按顺序的,父进程和子进程输出的结果是交替的,随机的。
这就是我们说的fork()之后父子进程并发执行。
- fork 之后,父子进程之间的数据共享问题
全局数据----------------------不共享 (准确来说应该是:读时共享,写时复制)
栈区数据----------------------不共享
堆区数据----------------------不共享这里的不共享,意思是各自拥有独立的一份空间。下面测试一下
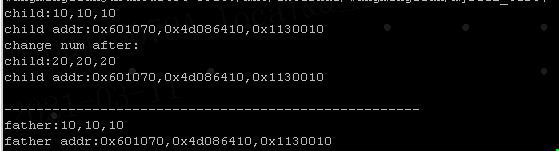
代码定义全局初始化变量,局部初始化变量,动态开辟指针,那么它们分别在==.data段,栈,堆==存储。 子进程对这三个变量修改数值,子进程中输出数值和地址,父进程也输出三个变量的值和地址 我们用sleep来保证父进程在子进程修改数值之后执行,先让父进程睡眠,这样我们就可以根据父进程输出的数值判断子进程的修改是否影响父进程。 进而判断父子进程的三个变量是否存储在一块存储空间中。 # include# include # include # include int gdata=10;//全局初始化 int main() { int ldata=10; int *hdata=(int*)malloc(4); *hdata=10; pid_t pid=fork(); assert(pid!=-1); //子进程 if(pid==0) { printf("child:%d,%d,%d\n",gdata,ldata,*hdata); printf("child addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); gdata=20; ldata=20; *hdata=20; printf("change num after:\n"); printf("child:%d,%d,%d\n",gdata,ldata,*hdata); printf("child addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); printf("\n----------------------------------------------------\n"); sleep(3); } else { sleep(3);//保证子进程先修改了变量值 printf("father:%d,%d,%d\n",gdata,ldata,*hdata); printf("father addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); } free(hdata); }
可以看到,子进程改变的值并未对父进程生效,他们各自拥有自己的存储空间。这里打印的地址一样,是他们的逻辑地址一样,不代表物理地址一样,就像每个进程他们的起始地址都是0x4000000
- 文件描述符问题:子进程能不能使用 fork 之前 open 返回的文件描述符?
父进程对于文件描述符共享,并且共享文件偏移量
- 总结:fork之后,父子进程有何不同
相同处:全局变量、data、text、 栈、 堆、 环境变量 、用户ID、 宿主目录、进程工作目录、 信号处理方式
不同处: 进程ID 、fork返回值 、父进程ID 、进程运行时间、 定时器、 未决信号集
可以共享 : 1.文件描述符 2.mmap 建立的共享映射区 注意:读时共享,写时复制

- 扩充两个函数
1. getpid(); 用于获取调用 getpid 这个函数的进程的 pid;
2. getppid(); 用户获取调用 getppid 这个函数的进程的父进程 pid;
另外:printf为库函数,没有\n,所以先在缓冲区里面
-
实例验证fork()特性
-
僵尸进程:

-
如何处理僵尸进程
- 1, wait函数:
NAME wait, waitpid, waitid - wait for process to change state SYNOPSIS #include#include pid_t wait(int *wstatus); 参数wstatus:进程状态 返回值: 成功返回进程号,失败返回-1 #include#include #include #include #include int main(int argc, char *argv[]) { pid_t pid = -1; pid = fork(); if(pid>0) { pid_t temp = -1; int status = 0; temp = wait(&status);//调用wait函数阻塞等待(对子进程形成的僵尸进程处理,并获得子进程的结束状态) //这个用法不好 //若没有子进程结束,则父进程一直阻塞等待子进程结束 //若有一个子进程结束,则父进程马上对其进行回收,回收之后不再等待,继续往下运行 printf("wait pid = %d\n",temp); printf("child ret = %d\n",WEXITSTATUS(status));WEXITSTATUS 是wait里的宏,可以man以下 if(WIFEXITED(status)) { printf("子进程正常结束\n"); } else { printf("子进程非正常结束\n"); } while(1) { printf("parent:self_id = %d,child_pid = %d\n",getpid(),pid); sleep(1); } } else if(0 == pid) { //子进程获得父进程pid :getppid() int num = 6; //strcpy(camsg,"this is child process!\n"); while(num) { printf("child: parent_pid = %d,self_pid = %d\n",getppid(),getpid()); num--; sleep(1); } } return 0; } 运行结果:
- 2.使其成为孤儿进程,由祖宗进程来接管,编程如下:
#include#include #include #include #include int main(int argc, char *argv[]) { pid_t pid = -1; pid = fork(); if(pid>0)//A { wait(NULL); while(1) { printf("parent:self_id = %d,child_pid = %d\n",getpid(),pid); sleep(1); } } else if(0 == pid) { pid_t pid2 = fork();//b if(0 == pid2)//c { //子进程获得父进程pid :getppid() int num = 6; while(num) { printf("child: parent_pid = %d,self_pid = %d\n",getppid(),getpid()); num--; sleep(1); } return 88; } } return 0; }
由上我们可以看出父子进程都是同时运行的,;
父进程不用等待子进程结束, 比wait()函数好点,能更好的去处理僵尸进程
- 3.通过对子进程结束时自动发出的信号处理方式重定义来处理僵尸进程,同时使用witpid()函数来进行回收
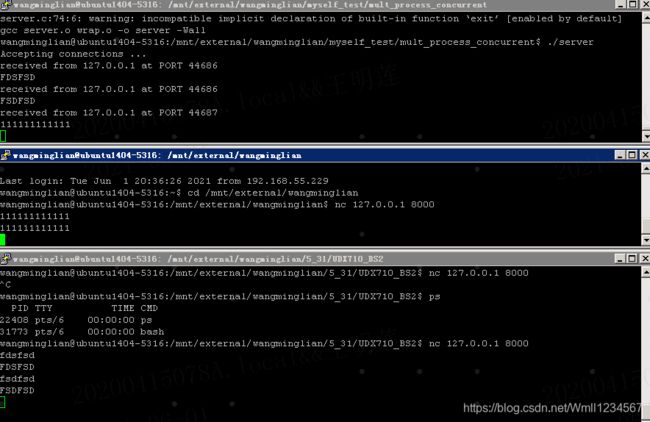
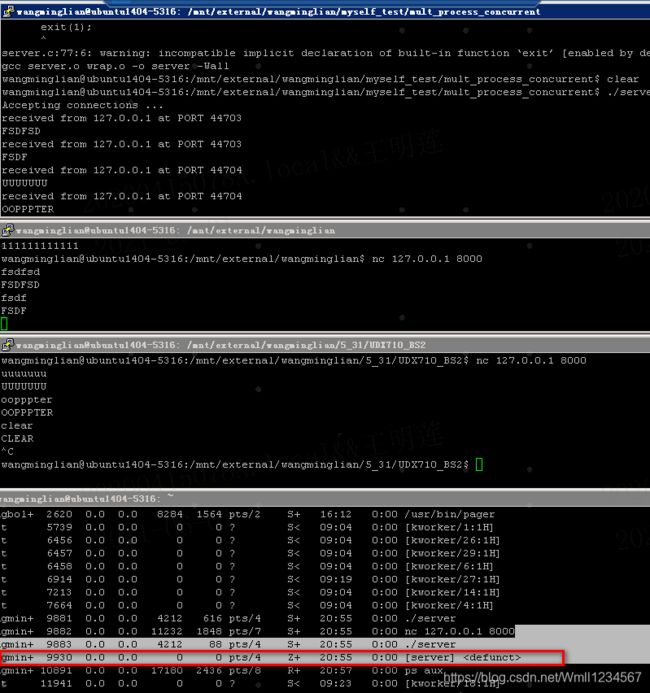
pid_t waitpid(pid_t pid, int *status, in options); 作用同 wait,但可指定 pid 进程清理,可以不阻塞。 特殊参数和返回情况: 参数 pid:> 0 回收指定 ID 的子进程 -1 回 回于 收任意子进程(相当于 wait ) 0 回收和当前调用 waitpid 一个组的所有子进程 < -1 回收指定进程组内的任意子进程 参数status:和wait函数的status一样,判断进程终止原因 参options: 0 :(相当于wait)阻塞回收 WBNIOHANG:非阻塞回收(轮询) 返回值:成功:返回清理掉的子进程 ID;失败:-1(无子进程) 特殊的返回 0:参 3 为 WNOHANG,且子进程正在运行。 注意:次 一次 wait 或 或 waitpid 调用只能清理一个子进程,清理多个子进程应使用循环while#include#include #include #include #include #include #include #include #include "wrap.h" #define MAXLINE 8192 #define SERV_PORT 8000 void do_sigchild(int num) { while (waitpid(0, NULL, WNOHANG) > 0) ; } int main(void) { struct sockaddr_in servaddr, cliaddr; socklen_t cliaddr_len; int listenfd, connfd; char buf[MAXLINE]; char str[INET_ADDRSTRLEN]; int i, n; pid_t pid; #if 1 /* set signal to recall child process */ struct sigaction newact; newact.sa_handler = do_sigchild; sigemptyset(&newact.sa_mask); newact.sa_flags = 0; sigaction(SIGCHLD, &newact, NULL); /* set signal to recall child process */ #endif listenfd = Socket(AF_INET, SOCK_STREAM, 0); int opt = 1; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(SERV_PORT); Bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr)); Listen(listenfd, 20); printf("Accepting connections ...\n"); while (1) { cliaddr_len = sizeof(cliaddr); connfd = Accept(listenfd, (struct sockaddr *)&cliaddr, &cliaddr_len); pid = fork(); if(pid <0){ perror("fork error"); }else if(pid == 0){ close(listenfd); break; }else{ close(connfd); /* also use signal to recall child process resource */ //signal(SIGCHILD,do_sigchild); /* also use signal to recall child process resource */ } } if (pid == 0) { while (1) { n = Read(connfd, buf, MAXLINE); if (n == 0) { close(connfd); return 0; }else if(n== -1){ perror("read error"); exit(1); }else { printf("received from %s at PORT %d\n", inet_ntop(AF_INET, &cliaddr.sin_addr, str, sizeof(str)), ntohs(cliaddr.sin_port)); for (i = 0; i < n; i++) buf[i] = toupper(buf[i]); Write(STDOUT_FILENO, buf, n); Write(connfd, buf, n); } } } return 0; }
如果不去回收,将代码中 #if 1 改为 #if 0,会有如下结果,红色方框就是僵尸进程


4.进程/线程同步的方式和机制、进程间通信
- 先来说说同步和通信?不然会被面试官问住,因为这两个概念他不是那么有清晰的界限,无论他问哪个,我们都统一把这两者都说一遍。哈哈
同步:进程/线程共同完成一项任务时直接发生相互作用的关系(按照一定先后顺序,或某种制约关系来相互协调运行和协同工作)
通信:进程/线程交互数据
其实在我理解,同步就是属于通信这个大概念里。为啥尼?现实意义来看,两个进程/线程不仅仅把数据给彼此就行了,就不管了,各自运行各自的。很多时候是需要彼此有一个执行的先后顺序。我生产数据好了,你才能执行,然后通过某种机制让对方知道,这不也是一种通信么。
进程间通信就是在不同进程之间传播或交换信息,那么不同进程之间存在着什么双方都可以访问的介质呢?进程的用户空间是互相独立的,一般而言是不能互相访问的,唯一的例外是共享内存区。但是,系统空间却是“公共场所”,所以内核显然可以提供这样的条件。除此以外,那就是双方都可以访问的外设了。在这个意义上,两个进程当然也可以通过磁盘上的普通文件交换信息,或者通过“注册表”或其它数据库中的某些表项和记录交换信息。广义上这也是进程间通信的手段,但是一般都不把这算作“进程间通信”。因为那些通信手段的效率太低了,而人们对进程间通信的要求是要有一定的实时性。
进程间通信主要包括管道, 系统IPC(包括消息队列,信号量,共享存储), SOCKET.
1.管道:分为有名管道和无名管道,无名管道只能用于亲属进程之间的通信,而有名管道(FIFO)则可用于无亲属关系的进程之间
2.(IPC)方法主要有以下几种: 管道/FIFO/共享内存/消息队列/信号
*消息队列是用于两个进程之间的通讯,首先在一个进程中创建一个消息队列,然后再往消息队列中写数据,而另一个进程则从那个消息队列中取数据。需要注意的是,消息队列是用创建文件的方式建立的,如果一个进程向某个消息队列中写入了数据之后,另一个进程并没有取出数据,即使向消息队列中写数据的进程已经结束,保存在消息队列中的数据并没有消失,也就是说下次再从这个消息队列读数据的时候,就是上次的数据!!!!
*信号量,这个就是传递信号,也算是通信,不能传递复杂消息,只能用来同步.
*共享内存,类似于WINDOWS下的DLL中的共享变量,但LINUX下的共享内存区不需要像DLL这样的东西,只要首先创建一个共享内存区,其它进程按照一定的步骤就能访问到这个共享内存区中的数据,当然可读可写
3.本地套接字通信并不为Linux所专有,在所有提供了TCP/IP协议栈的操作系统中几乎都提供了socket,而所有这样操作系统,对套接字的编程方法几乎是完全一样的 (这个怎么实现的通信呢,其实就是一个进程做服务器,另一个做服务端,connect之后就能通信啦)
- 以上几种方式的比较:
1.管道:速度慢,容量有限,只有父子进程能通讯
2.FIFO:任何进程间都能通讯,但速度慢
3.消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
4.信号量:不能传递复杂消息,只能用来同步 【开销最小】
5.共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存
6.本地套接字:【最稳定,实现复杂度最高】
进程之间传递信息的各种途径(包括各种IPC机制)总结如下:
- 父进程通过fork可以将打开文件的描述符传递给子进程
- 子进程结束时,父进程调用wait可以得到子进程的终止信息
- 几个进程可以在文件系统中读写某个共享文件,也可以通过给文件加锁来实现进程间同步
- 进程之间互发信号,一般使用SIGUSR1和SIGUSR2实现用户自定义功能
- 管道
- FIFO mmap函数,几个进程可以映射同一内存区
- SYS V IPC,以前的SYS V UNIX系统实现的IPC机制,包括消息队列、信号量和共享内 存,现在已经基本废弃
- UNIX Domain Socket,目前最广泛使用的IPC机制
进程间同步:
四种进程或线程同步互斥的控制方法
1、临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
2、互斥量:为协调共同对一个共享资源的单独访问而设计的。
3、信号量:为控制一个具有有限数量用户资源而设计。
4、事 件:用来通知线程有一些事件已发生,从而启动后继任务的开始。
Linux 下常见的进程同步方法有:
1、信号量
2、管程
3、 互斥量(基于共享内存的快速用户态 )
4、文件锁(通过 fcntl 设定,针对文件)
- 临界区、互斥区、事件、信号量四种方式介绍
临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore)、事件(Event)的区别
1、临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。在任意时刻只允许一个线程对共享资源进行访问,如果有多个线程试图访问公共资源,那么在有一个线程进入后,其他试图访问公共资源的线程将被挂起,并一直等到进入临界区的线程离开,临界区在被释放后,其他线程才可以抢占。
2、互斥量:采用互斥对象机制。 只有拥有互斥对象的线程才有访问公共资源的权限,因为互斥对象只有一个,所以能保证公共资源不会同时被多个线程访问。互斥不仅能实现同一应用程序的公共资源安全共享,还能实现不同应用程序的公共资源安全共享 .互斥量比临界区复杂。因为使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享。
3、信号量:它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目 .信号量对象对线程的同步方式与前面几种方法不同,信号允许多个线程同时使用共享资源,这与操作系统中的PV操作相同。它指出了同时访问共享资源的线程最大数目。它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。PV操作及信号量的概念都是由荷兰科学家E.W.Dijkstra提出的。信号量S是一个整数,S大于等于零时代表可供并发进程使用的资源实体数,但S小于零时则表示正在等待使用共享资源的进程数。
P操作申请资源:
(1)S减1;
(2)若S减1后仍大于等于零,则进程继续执行;
(3)若S减1后小于零,则该进程被阻塞后进入与该信号相对应的队列中,然后转入进程调度。
V操作 释放资源:
(1)S加1;
(2)若相加结果大于零,则进程继续执行;
(3)若相加结果小于等于零,则从该信号的等待队列中唤醒一个等待进程,然后再返回原进程继续执行或转入进程调度。
4、事 件: 通过通知操作的方式来保持线程的同步,还可以方便实现对多个线程的优先级比较的操作 .总结:
1. 互斥量与临界区的作用非常相似,但互斥量是可以命名的,也就是说它可以跨越进程使用。所以创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量。因为互斥量是跨进程的,互斥量一旦被创建,就可以通过名字打开它。
2. 互斥量(Mutex),信号灯(Semaphore),事件(Event)都可以被跨越进程使用来进行同步数据操作,而其他的对象与数据同步操作无关,但对于进程和线程来讲,如果进程和线程在运行状态则为无信号状态,在退出后为有信号状态。所以可以使用WaitForSingleObject来等待进程和线程退出。
3. 通过互斥量可以指定资源被独占的方式使用,但如果有下面一种情况通过互斥量就无法处理,比如现在一位用户购买了一份三个并发访问许可的数据库系统,可以根据用户购买的访问许可数量来决定有多少个线程/进程能同时进行数据库操作,这时候如果利用互斥量就没有办法完成这个要求,信号灯对象可以说是一种资源计数器。
二、进程间通信 —— 管道
1.无名管道
其本质就是内核的一块缓冲区;由两个文件描述符引用,一个表示读端,一个表示写端;规定从管道的写流入管道,从读端流出
管道的原理:管道实为内核中使用环形队列机制,借助内核缓冲区(4K)实现。
管道的局限性:1.数据不能进程自己写,自己读;2.管道中的数据不可反复读取,一旦读走,管道中不在存在;3.采用半双工通信方式,只能在单方向上流动;4.只能在公共祖先的进程间使用管道
- 1.创建并打开管道
#includeint pipe(int pipefd[2]); #define _GNU_SOURCE /* See feature_test_macros(7) */ #include /* Obtain O_* constant definitions */ #include int pipe2(int pipefd[2], int flags); 参数: pipefd:用于返回两个引用管道末端的文件描述符。 pipefd [0]是指管道的读取端。 pipefd [1]指向管 道的写端。写入管道写入端的数据由内核缓冲,直到从管道读取端读取数据为止 flag :0,则pipe2()与pipe()相同。可以对标志中的以下值进行按位或运算,以获取不同的行为: O_NONBLOCK :在两个新的打开文件描述上设置O_NONBLOCK文件状态标志。使用此标志可以节省对 fcntl(2)的额外调用,以实现相同的结果。 O_CLOEXEC :在两个新文件描述符上设置执行关闭(FD_CLOEXEC)标志。有关为什么可能有用的原 因,请参见open(2)中相同标志的描述。 返回值 成功时,返回零。如果出错,则返回-1,并正确设置errno。 错误 EFAULT pipefd无效。 EINVAL(pipe2())标志中的无效值。 EMFILE进程正在使用太多文件描述符。 ENFILE已达到打开文件总数的系统限制 #include#include #include #include int main(int argc, char *argv[]) { int pipefd[2]; pid_t cpid; char buf; if (argc != 2) { fprintf(stderr, "Usage: %s \n", argv[0]); exit(EXIT_FAILURE); } if (pipe(pipefd) == -1) { perror("pipe"); exit(EXIT_FAILURE); } cpid = fork(); if (cpid == -1) { perror("fork"); exit(EXIT_FAILURE); } if (cpid == 0) /* Child reads from pipe */ { close(pipefd[1]); /* Close unused write end */ while (read(pipefd[0], &buf, 1) > 0) write(STDOUT_FILENO, &buf, 1); write(STDOUT_FILENO, "\n", 1); close(pipefd[0]); _exit(EXIT_SUCCESS); } else /* Parent writes argv[1] to pipe */ { close(pipefd[0]); /* Close unused read end */ write(pipefd[1], argv[1], strlen(argv[1])); close(pipefd[1]); /* Reader will see EOF */ wait(NULL); /* Wait for child */ exit(EXIT_SUCCESS); } }

管道传非字符串/字符数据的数据方便吗?比如结构体。
#include#include #include #include typedef struct people { int years; int sex; int weight; char slogen[24]; }people; int main(int argc, char *argv[]) { int pipefd[2]; pid_t cpid; char buf; if (argc != 2) { fprintf(stderr, "Usage: %s \n", argv[0]); exit(EXIT_FAILURE); } if (pipe(pipefd) == -1) { perror("pipe"); exit(EXIT_FAILURE); } cpid = fork(); if (cpid == -1) { perror("fork"); exit(EXIT_FAILURE); } if (cpid == 0) /* Child reads from pipe */ { people p2; close(pipefd[1]); /* Close unused write end */ while (read(pipefd[0], &p2, sizeof(p2)) > 0) printf("%d %d %d %s\n",p2.years,p2.sex,p2.weight,p2.slogen); write(STDOUT_FILENO, "\n", 1); close(pipefd[0]); _exit(EXIT_SUCCESS); } else /* Parent writes argv[1] to pipe */ { people p1; p1.years = 18; p1.sex = 0; p1.weight = 88; p1.slogen[0] = 'A';p1.slogen[1] = 0; close(pipefd[0]); /* Close unused read end */ write(pipefd[1], &p1, sizeof(p1)); close(pipefd[1]); /* Reader will see EOF */ wait(NULL); /* Wait for child */ exit(EXIT_SUCCESS); } }

- 管道的读写行为


- 管道缓冲区大小

- 管道的优劣
优点:简单
缺点:只能单向通信,双向通信需要建立两个管道。
只能用于父子、兄弟进程(有共同祖先)间通信。该问题后来使用fifo有名管道得以解决
2.命名管道fifo
FIFO是linux基础文件的一种,但FIFO文件再磁盘上没有数据块,仅仅用来表示内核中的一条通道,个进程可以打开这个文件进行read/write,实际上是读写内核通道,这样就实现了进程间通信
- 如何创建
1.命令 mkfifo
2. 库函数:
int mkfifo(const char * pathname,mode_t mode) 必须在两端同时打开它,然后才能继续对其进行任何输入或输出操作。打开FIFO以正常读取块,直到其他进程打开相同的FIFO进行写入为止,反之亦然写端:
#include#include #include #include #include #include #include void sys_error(char * str){ perror(str); exit(-1); } int main(int argc, char *argv[]) { int fd,i; char buf[4096] = {0}; if(argc < 2) { printf("enter like this : ./a.out filename\n"); } fd = open(argv[1],O_WRONLY); if(fd < 0){ sys_error("open"); } i = 0; while(1){ sprintf(buf,"helloe lhh %d\n",i++); write(fd,buf,strlen(buf)); sleep(1); } close(fd); return 0; } 读端:
#include#include #include #include #include #include #include void sys_error(char * str){ perror(str); exit(-1); } int main(int argc, char *argv[]) { int fd,i; char buf[4096] = {0}; if(argc < 2) { printf("enter like this : ./a.out filename\n"); } fd = open(argv[1],O_RDONLY); if(fd < 0){ sys_error("open"); } i = 0; while(1){ int len = read(fd,buf,sizeof(buf)); write(STDOUT_FILENO,buf,len); sleep(1); } close(fd); return 0; }
- 如果多个写端,一个读端?什么现象呢?
都可以跑起来。要注意特性。
- 多个读端,一个写端?

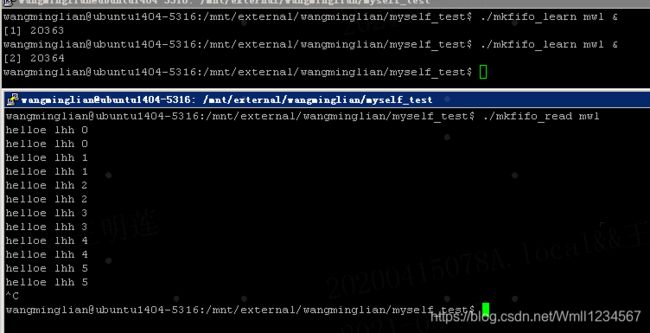

三、进程间通信 —— 共享内存映射
- 共享内存和文件内存映射有什么区别?
-
普通文件进程通信
#include#include #include #include #include int main(int argc, char *argv[]) { int cpid = fork(); char s[] = "---------------hello------------\n"; if (cpid == -1) { perror("fork"); exit(EXIT_FAILURE); } if (cpid == 0) /* Child reads from pipe */ { int fd1 = open("test.txt",O_RDWR); if(fd1<0){ perror("open error"); exit(1); } write(fd1,s,strlen(s)); printf("child wrote over ... \n"); }else /* Parent writes argv[1] to pipe */ { int fd2 = open("test.txt",O_RDWR|O_NONBLOCK); if(fd2<0){ perror("open error"); exit(1); } //sleep(1); char buf[1024] = {0}; int len = read(fd2,buf,sizeof(buf)); printf("------parent read len = %d\n",len); len = write(STDOUT_FILENO,buf,len); printf("------parent write len = %d\n",len); } return 0; }
-
存储I/O映射
存储映射I/O:使一个磁盘文件与存储空间中的一个缓冲区像映射。于是当从缓冲区取数据,就相当于读文件中的相应字节。与此类此,将数据写入缓冲区,则相应的字节就自动写入文件。这样,不用read \wite函数,使用地址(指针)完成I/O操作
使用这种方法得通知内核,将一个指定文件映射到存储区域中。使用 mmap函数来完成。
#includevoid *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); 参数: addr : 建立映射去区的地址,一般传NULL,由内核区指定。也可传入自己指定地址 length : 欲创建映射区的大小 prot :共享内存区的读写权限 它可以是PROT_NONE或以下一个或多个标志的按位或: PROT_EXEC 页面可以被执行。 PROT_READ 页面可能被读取。 PROT_WRITE 页面可以被写入。 PROT_NONE 页面可能无法访问。 flags: 标志共享内存的共享属性:常用于设定更新物理区域,设置共享、创建匿名映射区 MAP_SHARED:共享此映射。映射的更新对其他映射过程可见此文件,并一直传递到基础文件。 在调用msync(2)或munmap()之前,实际上可能不会更新文件。 MAP_PRIVATE:创建一个私有的写时复制映射。映射的更新对于映射同一文件的其他进程不可 见,也不会传递到基础文件。未指定在映射区域中是否可以看到在mmap()调 用之后对文件所做的更改。 这两个标志都在POSIX.1-2001中进行了描述。(一般只使用这两个参数) 此外,可以在标志中对以下值中的零个或多个进行“或”运算:很多,感兴趣用 man 去查看 fd: 要映射的文件的描述符 offset :文件描述符fd所引用的文件(或其他对象)中的偏移位置 如果为0 :全部映射 offset必须是sysconf(_SC_PAGE_SIZE)返回的页面大小的倍数(一般是4k的整数倍)。 返回值: 成功:返回映射区首地址 失败:返回 MAP_FAILED(that is (void *) -1 ) int munmap(void *addr, size_t length); //释放共享映射区 成功 :0 失败: -1 #include#include #include #include #include #include #include #include void sys_err(const char* str) { perror(str); exit(-1); } int main(){ char * p = NULL; int fd; fd = open("resrmap",O_RDWR|O_CREAT|O_TRUNC,0644); if(fd<0) sys_err("open error"); /*// expand file space lseek(fd,10,SEEK_END); write(fd,"\0",1);//expand file space :11 = ftruncate(fd,10); */ ftruncate(fd,10); int file_len = lseek(fd,0,SEEK_END); //get file length p = mmap(NULL,file_len,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0); if(p == MAP_FAILED){ sys_err("mmap error"); } //use p strcpy(p,"hello world"); printf("%s\n", p); return 0; }
思考:
注意事项总结:


- mmap父子进程间通信
要注意:在创建映射区的时候指定对应的标志位参数 :flag
MAP_PRIVATE:(私有映射)父子进程各自独占映射区
MAP_SHARED:(共享映射) 父子进程共享映射区
#include#include #include #include #include #include #include #include void sys_err(const char* str) { perror(str); exit(-1); } int main(){ char * p = NULL; int fd; fd = open("resrmap",O_RDWR|O_CREAT|O_TRUNC,0644); if(fd<0) sys_err("open error"); /*// expand file space lseek(fd,10,SEEK_END); write(fd,"\0",1);//expand file space :11 = ftruncate(fd,10); */ ftruncate(fd,10); int file_len = lseek(fd,0,SEEK_END); //get file length // if file =0 ,inut derect 20 : p = mmap(NULL,file_len,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0); if(p == MAP_FAILED){ sys_err("mmap error"); } //use p strcpy(p,"hello world"); printf("p = %s \n",p); int pid = fork(); if(pid ==0){ p[0] = 'w'; printf("child = %s \n",p); }else{ sleep(1); printf("parent = %s \n",p); } int ret = munmap(p,4); if(ret < 0) { sys_err("munmap error"); exit(1); } return 0; } 运行结果:
- mmap无血缘关系进程间通信
//写端 #include#include #include #include #include #include #include #include struct student { int id; char name[256]; int age; }; void sys_err(const char* str) { perror(str); exit(-1); } int main(){ struct student stu = {10,"wml",18}; struct student *p; int fd; fd = open("resrmap",O_RDWR|O_CREAT|O_TRUNC,0644); if(fd<0) sys_err("open error"); ftruncate(fd,sizeof(stu)); p = mmap(NULL,sizeof(stu),PROT_READ|PROT_WRITE,MAP_SHARED,fd,0); if(p == MAP_FAILED){ sys_err("mmap error"); } while(1){ memcpy(p,&stu,sizeof(stu)); stu.id++; sleep(1); } munmap(p,sizeof(stu)); close(fd); return 0; } //读端 #include#include #include #include #include #include #include #include struct student { int id; char name[256]; int age; }; void sys_err(const char* str) { perror(str); exit(-1); } int main(){ struct student stu; struct student *p; int fd; fd = open("resrmap",O_RDWR|O_CREAT|O_TRUNC,0644); if(fd<0) sys_err("open error"); ftruncate(fd,sizeof(stu)); p = mmap(NULL,sizeof(stu),PROT_READ|PROT_WRITE,MAP_SHARED,fd,0); if(p == MAP_FAILED){ sys_err("mmap error"); } while(1){ printf("id = %d, name =%s age = %d\n",p->id,p->name,p->age); stu.id++; sleep(1); } munmap(p,sizeof(stu)); close(fd); return 0; } 运行结果:
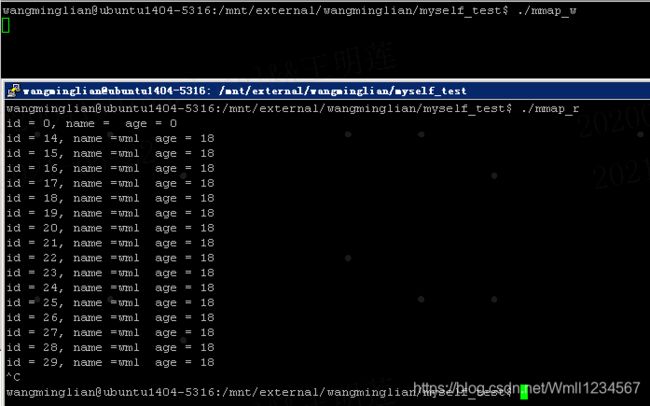
1.如果是多个写端呢,一个读端呢?
1s写1s读
2s写1s读 :以下的打印说明。不像管道,被读走了,下一次读就没了。。。。可以反复读的。
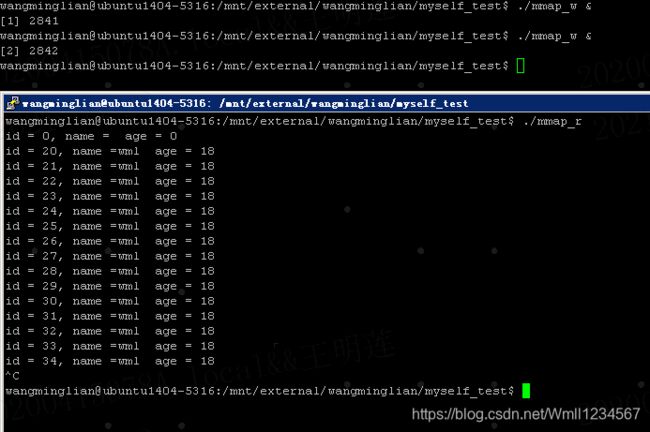
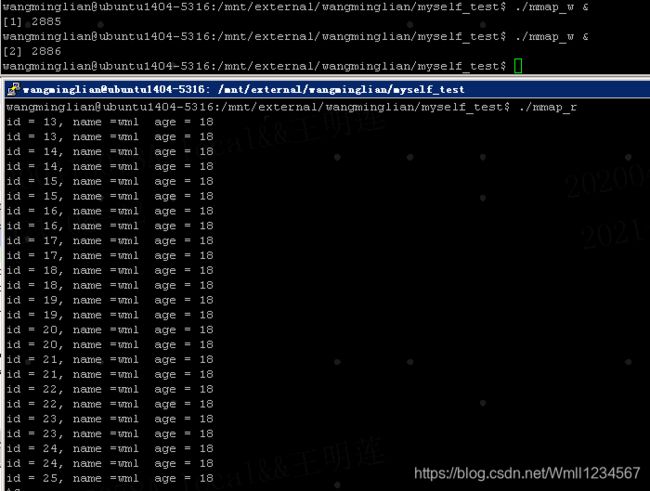
- 匿名映射 只能用于血缘关系进程间(因为没有名字,另一个进程也无法使用。)

四、进程间通信 —— 本地套接字
https://blog.csdn.net/Wmll1234567/article/details/114587876 这篇文章详细讲了socke编程,如何实现?
其实就是socket编程,只不过使用上参数使用不同:见如下
1.socket()函数;参数选择 :本地域套接字 :AF_UNIX/AF_LOCAL (这两个是一个意思。posix为了统一标准才出现 AF_LOCAL)
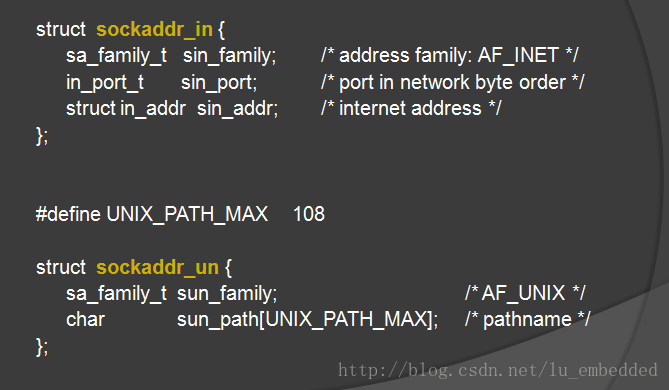
2.地址结构使用: 不再使用sockaddr_in(Internet),而是
sockaddr_un
struct sockaddr_un{ sa_family sun_family; //AF_LOCAL,地址族 char sun_path[104]; //必须以空字符结尾,通过这样一个路径描述地址 }; 位于头文件:sun_family 表示协议族,填 AF_LOCAL 或 AF_UNIX 即可; sun_path 表示一个路径名。 3.从这里面可以很明显得看出 Unix 域套接字与原来的 网络套接字的区别
Unix 域中用于标识客户和服务器的协议地址是普通文件系统中的路径名,而这个文件就称为套接字文件。
这里要强调一下的是,Unix 本地套接字关联的这个路径名应该是一个绝对路径名,而不是一个相对路径名。为什么呢?因为解析相对路径依赖于调用者的当前工作目录,也就是说,要是服务器绑定了一个相对路径名,那么客户端也得在与服务端相同的目录中才能成功调用connect(连接)或者sendto(发送)这样一些函数。显然,这样就会导致程序出现异常情况,所以建议大家最好使用一个绝对路径名。
这个路径名,其实还要分为两种,一种是我们上面所提到的普通路径名,另一种是抽象路径名。普通路径名是一个正常的字符串,也就是说,sun_path 字段是以空字符(’\0’)结尾的。而抽象路径名,sun_path 字段的第一个字节需要设置成 NULL(’\0’),所以在计算抽象路径名的长度的时候就要特别小心了,否则在解析抽象路径名时就有可能出现异常情况,因为抽象路径名不是像解析普通路径名那样,解析到第一个 NULL 就可以停止了。
使用抽象路径名的好处是,因为不会再在文件系统中创建文件了,所以对于抽象路径名来说,就不需要担心与文件系统中已存在的文件产生名字冲突的问题了,也不需要在使用完套接字之后删除附带产生的这个文件了,当套接字被关闭之后会自动删除这个抽象名。
4.3.UNIX域流式套接字connect发现监听队列满时,会立刻返回一个ECONNREFUSED,这和TCP不同,如果监听队列满,会忽略到来的SYN,这导致对方重传SYN

服务端进程
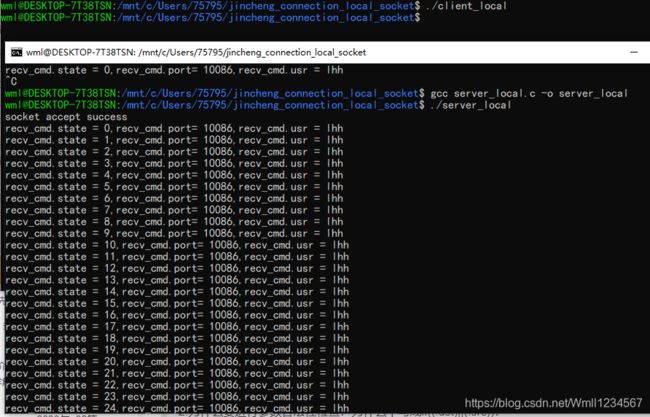
#include#include #include #include #include #include #include #include #define NWY_FOTA_SOCKET "/tmp/nwy_fota_socket" typedef struct{ int state; int mode; char url[1024]; //ftp url int port; //ftp port char usr[128]; //usr char passward[128]; char filename[128]; int size; }msgbuf; int main(void) { int msg_id; int reboot_mode, fd; int result = 0; int mode=0; int fd_ret; int socketfd = -1; int servlen; socklen_t clilen; ssize_t len; msgbuf recv_cmd; struct sockaddr_un cli_addr, serv_addr; struct sockaddr_un addr; struct sockaddr_un* __attribute__((__may_alias__)) addr_ptr; if (access(NWY_FOTA_SOCKET, F_OK) == 0) system("rm -rf /tmp/nwy_fota_socket"); socketfd = socket(AF_UNIX, SOCK_STREAM, 0); if (socketfd < 0) { printf("Create socket fail! \n"); return -1; } memset(&serv_addr, 0, sizeof(serv_addr)); serv_addr.sun_family = AF_UNIX; strncpy(serv_addr.sun_path, NWY_FOTA_SOCKET , sizeof(serv_addr.sun_path)); servlen = (int)(strlen(serv_addr.sun_path) + sizeof(serv_addr.sun_family)); memcpy(&addr, &serv_addr, sizeof(addr)); addr_ptr = &addr; if (bind(socketfd, (struct sockaddr*)addr_ptr, servlen) < 0) { printf("bind failed\n"); return -1; } if (listen(socketfd, 30) < 0) { printf("listen failed\n"); return -1; } clilen = sizeof(struct sockaddr_un); memcpy(&addr, &cli_addr, sizeof(addr)); memset(&recv_cmd, 0x00, sizeof(recv_cmd)); addr_ptr = &addr; int clientfd = accept(socketfd, (struct sockaddr*)addr_ptr, &clilen); if (clientfd < 0) { printf("ERROR: accept error\n"); } printf("socket accept success\n"); while (1){ len = read(clientfd, &recv_cmd, sizeof(recv_cmd)); if (len < sizeof(recv_cmd)){ printf("ERROR: invalid data sent by client\n"); } printf("recv_cmd.state = %d,recv_cmd.port= %d,recv_cmd.usr = %s\n",recv_cmd.state,recv_cmd.port,recv_cmd.usr); } close(socketfd); unlink(NWY_FOTA_SOCKET); sleep(5); return -1; } 客户端进程:
#include#include #include #include #include #include #include #include #define NWY_FOTA_SOCKET "/tmp/nwy_fota_socket" typedef struct{ int state; int mode; char url[1024]; //ftp url int port; //ftp port char usr[128]; //usr char passward[128]; char filename[128]; int size; }msgbuf; int main(){ int sockfd = -1; int servlen; int len = 0; int res = 0; struct sockaddr_un serv_addr; memset(&serv_addr, 0, sizeof(serv_addr)); serv_addr.sun_family = AF_UNIX; strncpy(serv_addr.sun_path, NWY_FOTA_SOCKET, sizeof(serv_addr.sun_path)); servlen = (int)(strlen(serv_addr.sun_path)+sizeof(serv_addr.sun_family)); sockfd = socket(AF_UNIX, SOCK_STREAM, 0); if (sockfd < 0){ printf("Create socket fail! \n"); return -1; } if (connect(sockfd, (struct sockaddr*)&serv_addr, servlen) < 0){ printf("Connect socket fail! \n"); res = -1; close(sockfd); return res; } msgbuf send_data = {0}; send_data.port = 10086; memcpy(send_data.usr,"lhh",sizeof("lhh")); while(1){ len = write(sockfd, &send_data, sizeof(msgbuf) ) ; if (len < 0) { printf("write cmd fail! \n"); res = -1; close(sockfd); return res; } send_data.state++; sleep(1); } } 运行结果:
四、进程间同步
总览:

- Linux多进程同步方式对比
在进行多进程开发的时候,经常会遇到各种进程间同步的场景,Linux多进程同步机制的性能和功能均有较大差异 ,一般使用以下4种方式:
- GCC内建原子操作
- 基于共享内存的mutex(pthread mutex)
- POSIX信号量
- fcntl记录锁
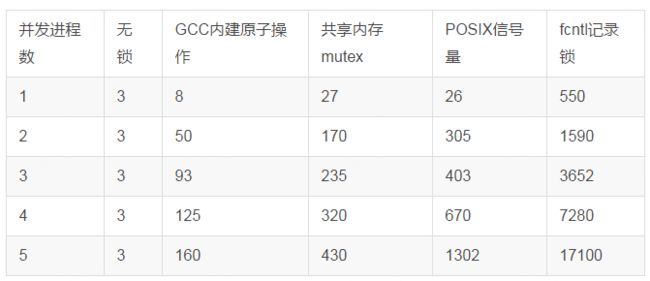
从功能上分析:原子操作< mutex < 信号量 < 记录锁。原子操作只支持有限的几种整数运算;mutex只支持加锁和解锁两种状态;信号量则支持计数;记录锁功能最为丰富,能支持读写锁、区间锁、多次加锁一次释放、进程退出自动释放等功能。
那性能呢?简单的测试方法:程序分别启动1~5个子进程,在共享内存中存放一个int整数,每个子进程对其自增1M次,总计时间,程序运行5次取均值。(时间单位为毫秒),结果性能排名是:原子操作 > mutex > 信号量 > 记录锁。记录锁甚至在单进程的情况下性能都低于mutex在5个进程下的表现,到多进程的时候性能比其它同步操作低了一个数量级以上。结果如下:
2、常见的锁类别
第一类:unix内核级别锁。这类锁经常使用,针对于多进程或者多线程的程序在运行的过程中,有时会出现公共资源抢占使用的情况就会使用到这类锁,这类锁常用的分以下4类:
- 互斥锁:mutex;获取锁失败后会休眠,释放cpu。
- 自旋锁:spinlock;遇到锁时,占用cpu空等。
- 读写锁:rwlock;同一时刻只有一个线程可以获得写锁,可 以有多线程获得读锁。
- 顺序锁:seqlock; 本质上是一个自旋锁+一个计数器。
互斥锁实际上是一种变量,在使用互斥锁时,实际上是对这个变量进行置0置1操作并进行判断使得线程能够获得锁或释放锁。 提供两种获得锁方法,常用的是pthread_mutex_lock:
pthread_mutex_lock:如果此时已经有另一个线程已经获得了锁,那么当前线程调用该函数后就会被挂起等待,直到有另一个线程释放了锁,该线程会被唤醒。
pthread_mutex_trylock:如果此时有另一个贤臣已经获得了锁,那么当前线程调用该函数后会立即返回并返回设置出错码为EBUSY,即它不会使当前线程挂起等待
而互斥锁的底层实现,一般使用swap或exchange指令,这个指令的含义是将寄存器和内存单元中的数据进行交换,这条指令保证了操作lock和unlock的原子性。
第二类:文件锁:FileLock;防止多进程并发;是一种文件读写机制,在任何特定的时间只允许一个进程访问一个文件。
第三类:Mysql锁。根据锁类型:共享锁(读锁),排他锁(写锁);根据锁策略:表锁,行锁,间隙锁 ;根据锁方法:悲观锁,乐观锁
3、互斥锁和Mysql锁的使用场景
针对互斥锁,主要在以下三个常见场景经常使用:
- 数据共享:主写,子读 主线程定时加载DB/文件/队列内的数据,子线程读取数据。
DB句柄:主读,子读 DB句柄在主线程/全局变量内定义,子线程需要更句柄来更新数据
非线程安全的API使用: SHA256签名,Rsa256 Localtime ->localtime_r
针对Mysql锁,主要分事务内和事务外:
事务中,使用排他锁 select...for update 只有指定主键,MySQL 才会执行Row lock
非事务,乐观锁 where 前置条件